设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
NET
›
图像分割之U-Net
1
2
3
/ 3 页
下一页
返回列表
发帖
查看:
289
|
回复:
21
图像分割之U-Net
[复制链接]
角落里的白鸽子
角落里的白鸽子
当前离线
积分
46
4
主题
22
帖子
46
积分
新手上路
新手上路, 积分 46, 距离下一级还需 4 积分
新手上路, 积分 46, 距离下一级还需 4 积分
积分
46
发消息
发表于 2022-9-26 06:44:26
|
显示全部楼层
|
阅读模式
U-Net: Convolutional Networks for Biomedical Image Segmentation
tags: U-Net, Semantic Segmentation
前言
U-Net是比较早的使用全卷积网络进行语义分割的算法之一,论文中使用包含压缩路径和扩展路径的对称U形结构在当时非常具有创新性,且一定程度上影响了后面若干个分割网络的设计,该网络的名字也是取自其U形形状。
U-Net的实验是一个比较简单的ISBI cell tracking数据集,由于本身的任务比较简单,U-Net紧紧通过30张图片并辅以数据扩充策略便达到非常低的错误率,拿了当届比赛的冠军。
论文源码已开源,可惜是基于MATLAB的Caffe版本。虽然已有各种开源工具的实现版本的U-Net算法陆续开源,但是它们绝大多数都刻意回避了U-Net论文中的细节,虽然这些细节现在看起来已无关紧要甚至已被淘汰,但是为了充分理解这个算法,笔者还是建议去阅读作者的源码,地址如下:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
1. 算法详解
1.1 U-Net的网络结构
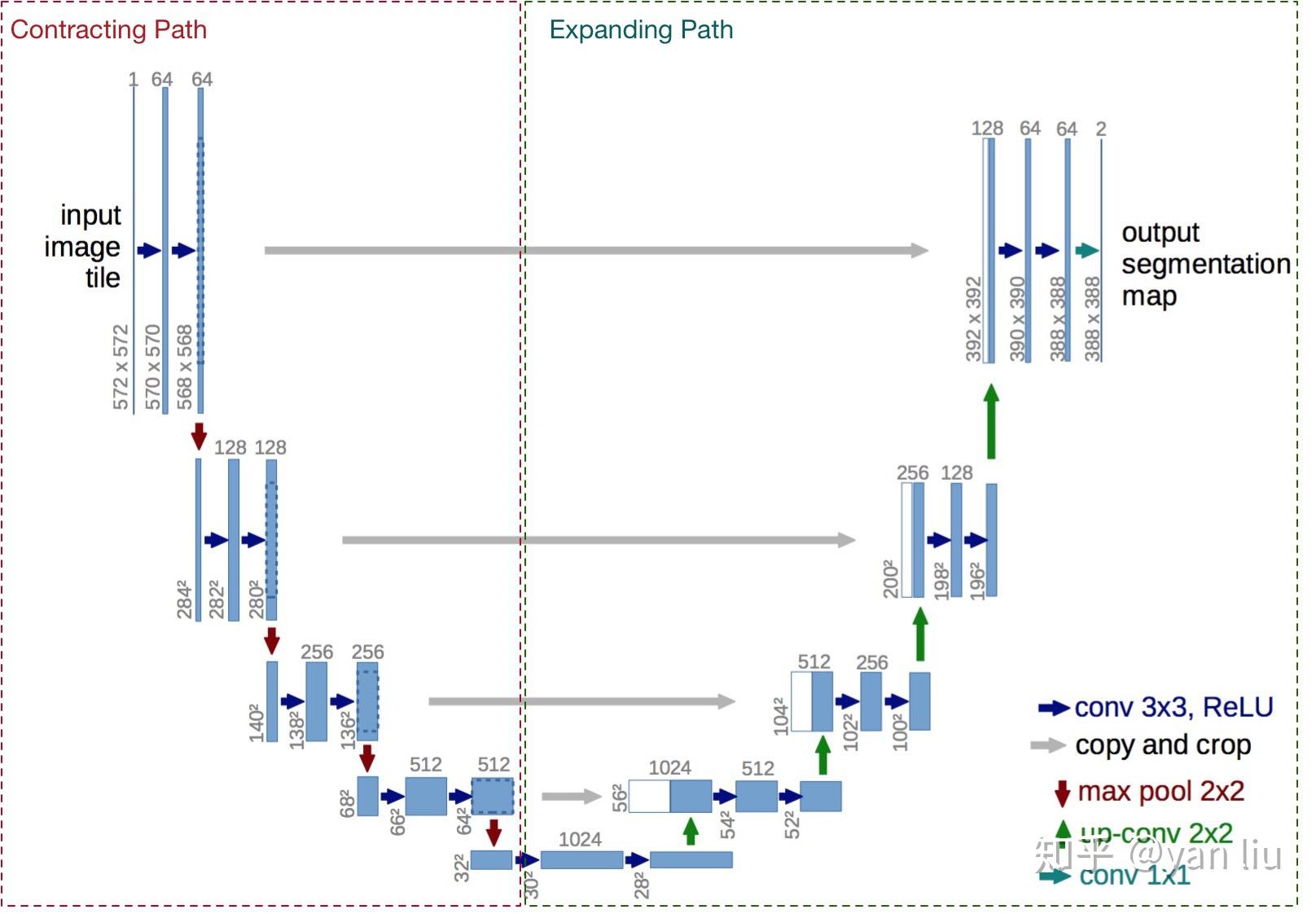
直入主题,U-Net的U形结构如图1所示。网络是一个经典的全卷积网络(即网络中没有全连接操作)。网络的输入是一张 572\times572 的边缘经过镜像操作的图片(input image tile),关于“镜像操作“会在1.2节进行详细分析,网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,论文中将这一部分叫做压缩路径(contracting path)。压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为 32\times32 的Feature Map。
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图1中左侧虚线部分)。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是 388\times388 。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
图1:U-Net网络结构图
如图1中所示,网络的输入图片的尺寸是 572\times572 ,而输出Feature Map的尺寸是 388\times388 ,这两个图像的大小是不同的,无法直接计算损失函数,那么U-Net是怎么操作的呢?
1.2 U-Net究竟输入了什么
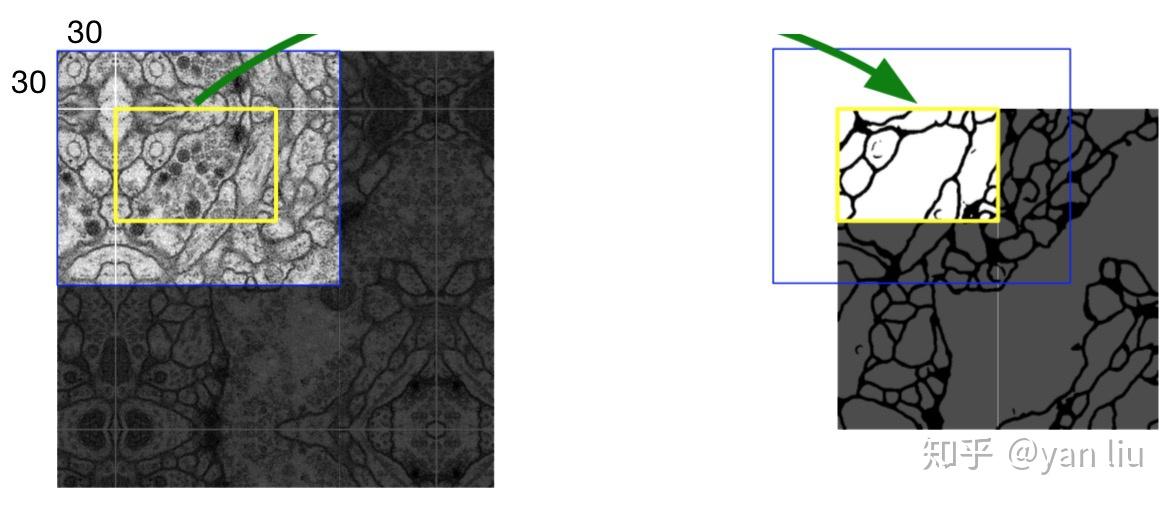
首先,数据集我们的原始图像的尺寸都是 512\times512 的。为了能更好的处理图像的边界像素,U-Net使用了镜像操作(Overlay-tile Strategy)来解决该问题。镜像操作即是给输入图像加入一个对称的边(图2),那么边的宽度是多少呢?一个比较好的策略是通过感受野确定。因为有效卷积是会降低Feature Map分辨率的,但是我们希望 512\times512 的图像的边界点能够保留到最后一层Feature Map。所以我们需要通过加边的操作增加图像的分辨率,增加的尺寸即是感受野的大小,也就是说每条边界增加感受野的一半作为镜像边。
图2:U-Net镜像操作
根据图1中所示的压缩路径的网络架构,我们可以计算其感受野:
\text{rf} = (((0 \times2 +2 +2)\times2 +2 +2)\times2 +2 +2)\times2 +2 +2 = 60 \tag{1}
这也就是为什么U-Net的输入数据是 572\times572 的。572的卷积的另外一个好处是每次降采样操作的Feature Map的尺寸都是偶数,这个值也是和网络结构密切相关的。
1.3 U-Net的损失函数
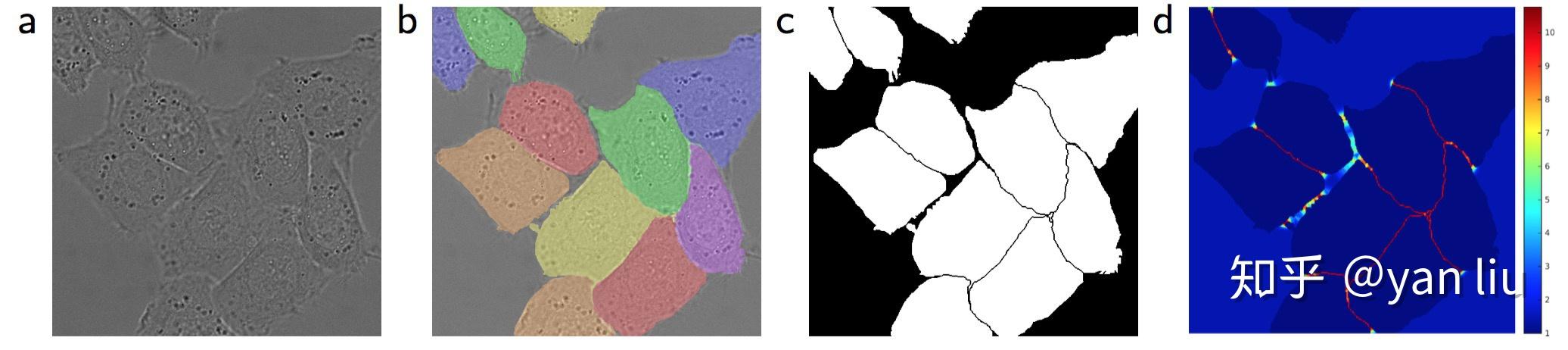
ISBI数据集的一个非常严峻的挑战是紧密相邻的物体之间的分割问题。如图3所示,(a)是输入数据,(b)是Ground Truth,(c)是基于Ground Truth生成的分割掩码,(d)是U-Net使用的用于分离边界的损失权值。
图3:ISBI数据集样本示例
那么该怎样设计损失函数来让模型有分离边界的能力呢?U-Net使用的是带边界权值的损失函数:
E = \sum_{\mathbf{x}\in \Omega} w(\mathbf{x}) \text{log}(p_{\ell(\mathbf{x})}(\mathbf{x})) \tag{2}
其中 p_{\ell(\mathbf{x})}(\mathbf{x}) 是 softmax 损失函数, \ell: \Omega \rightarrow \{1,...,K\} 是像素点的标签值, w: \Omega \in \mathbb{R} 是像素点的权值,目的是为了给图像中贴近边界点的像素更高的权值。
w(\mathbf{x}) = w_c(\mathbf{x}) + w_0 \cdot \text{exp}(-\frac{(d_1(\mathbf{x})+ d_2(\mathbf{x}))^2}{2\sigma^2}) \tag{3}
其中 w_c: \Omega \in \mathbb{R} 是平衡类别比例的权值, d_1: \Omega \in \mathbb{R} 是像素点到距离其最近的细胞的距离, d_2: \Omega \in \mathbb{R} 则是像素点到距离其第二近的细胞的距离。 w_0 和 \sigma 是常数值,在实验中 w_0 = 10 , \sigma\approx 5 。
2. 数据扩充
由于训练集只有30张训练样本,作者使用了数据扩充的方法增加了样本数量。并且作者指出任意的弹性形变对训练非常有帮助。
3. 总结
U-Net是比较早的使用多尺度特征进行语义分割任务的算法之一,其U形结构也启发了后面很多算法。但其也有几个缺点:
有效卷积增加了模型设计的难度和普适性;目前很多算法直接采用了same卷积,这样也可以免去Feature Map合并之前的裁边操作
其通过裁边的形式和Feature Map并不是对称的,个人感觉采用双线性插值的效果应该会更好。
Reference
[1] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
回复
使用道具
举报
反嘴鹬
反嘴鹬
当前离线
积分
10
2
主题
6
帖子
10
积分
新手上路
新手上路, 积分 10, 距离下一级还需 40 积分
新手上路, 积分 10, 距离下一级还需 40 积分
积分
10
发消息
发表于 2022-9-26 06:45:08
|
显示全部楼层
你好,请问输入572怎么来的?我看不明白你的算法?请指教。
回复
使用道具
举报
葡桃
葡桃
当前离线
积分
6
1
主题
5
帖子
6
积分
新手上路
新手上路, 积分 6, 距离下一级还需 44 积分
新手上路, 积分 6, 距离下一级还需 44 积分
积分
6
发消息
发表于 2022-9-26 06:45:24
|
显示全部楼层
U-Net可以看做一个Encoder-Decoder模型,其中压缩路径对应的是编码器,32*32*512可以看做特征向量。那么特征向量两头的值需要通过加边的方式计算得到,加的边的大小便是其感受野的一半(另一半在原图中)。原文中给出感受野的大小是60,也就是要计算左侧的特征值需要添加一个30的镜像映射,同理右侧的特征值也需要添加一个大小为30的镜像映射。由于原图的大小是512,所以输入扩充到了512+30+30=572。
更好的方法是通过same卷积来代替论文中使用的valid卷积,也就不存在这些问题了。
回复
使用道具
举报
我心宁静
我心宁静
当前离线
积分
0
0
主题
4
帖子
0
积分
新手上路
新手上路, 积分 0, 距离下一级还需 50 积分
新手上路, 积分 0, 距离下一级还需 50 积分
积分
0
发消息
发表于 2022-9-26 06:45:48
|
显示全部楼层
那原文中的一长串计算是怎么回事?直接加两个30不就好了?
回复
使用道具
举报
东山风雨起苍黄
东山风雨起苍黄
当前离线
积分
31
2
主题
17
帖子
31
积分
新手上路
新手上路, 积分 31, 距离下一级还需 19 积分
新手上路, 积分 31, 距离下一级还需 19 积分
积分
31
发消息
发表于 2022-9-26 06:46:05
|
显示全部楼层
还有一个疑问,感受器不是卷积核的大小吗?不是3*3?
回复
使用道具
举报
张什么
张什么
当前离线
积分
8
1
主题
6
帖子
8
积分
新手上路
新手上路, 积分 8, 距离下一级还需 42 积分
新手上路, 积分 8, 距离下一级还需 42 积分
积分
8
发消息
发表于 2022-9-26 06:47:02
|
显示全部楼层
感受野不是卷积核,感受野可以理解为计算Feature Map上一点需要的输入图像中那一部分的大小。原文中的公式便是根据压缩路径计算感受野的公式,也就是30怎么来的。
回复
使用道具
举报
花不丸
花不丸
当前离线
积分
13
3
主题
7
帖子
13
积分
新手上路
新手上路, 积分 13, 距离下一级还需 37 积分
新手上路, 积分 13, 距离下一级还需 37 积分
积分
13
发消息
发表于 2022-9-26 06:48:00
|
显示全部楼层
还是感受野计算的问题。就是 你是从后往前计算的吧。那么最后一层的感受野应该是1 不是0?
回复
使用道具
举报
刘术新
刘术新
当前离线
积分
27
2
主题
14
帖子
27
积分
新手上路
新手上路, 积分 27, 距离下一级还需 23 积分
新手上路, 积分 27, 距离下一级还需 23 积分
积分
27
发消息
发表于 2022-9-26 06:48:38
|
显示全部楼层
作者在论文中并没有指出tile30的原因,只能推断。按照valid卷积的边长的丢失过程计算来看(依次是30-29-28-14-13-12-6-5-4-2-1-0),也就是在开始融合的那一层所有加的边已经全部丢失完毕,进而推断是从那一层开始计算感受野的,也就有了上面的公式。
说一些个人的观点:如果保证每次降采样的都是偶数边,可以推算出输入图像的尺寸需要满足16k+44,572是一个比较理想的值。小16个像素尺度丢失太严重,大16个像素浪费计算资源,另外最后一层了差点影响不大,会通过U-Net的拼接机制弥补回来。
你也可以发邮件和作者讨论一下原由,到时候欢迎回来指导纠正。
回复
使用道具
举报
蝴蝶舞仙客来
蝴蝶舞仙客来
当前离线
积分
11
2
主题
7
帖子
11
积分
新手上路
新手上路, 积分 11, 距离下一级还需 39 积分
新手上路, 积分 11, 距离下一级还需 39 积分
积分
11
发消息
发表于 2022-9-26 06:49:32
|
显示全部楼层
好的,谢谢您的详细解答,万分感谢!
回复
使用道具
举报
清茶清肠胃
清茶清肠胃
当前离线
积分
16
4
主题
8
帖子
16
积分
新手上路
新手上路, 积分 16, 距离下一级还需 34 积分
新手上路, 积分 16, 距离下一级还需 34 积分
积分
16
发消息
发表于 2022-9-26 06:50:30
|
显示全部楼层
你好,想问一下解码过程中为什么要使用卷积呢,使用卷积时会不会改变感受野
回复
使用道具
举报
下一页 »
1
2
3
/ 3 页
下一页
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
PHP
JAVA
C语言
易语言
C++
数据库
快速回复
返回顶部
返回列表


 发表于 2022-9-26 06:44:26
发表于 2022-9-26 06:44:26