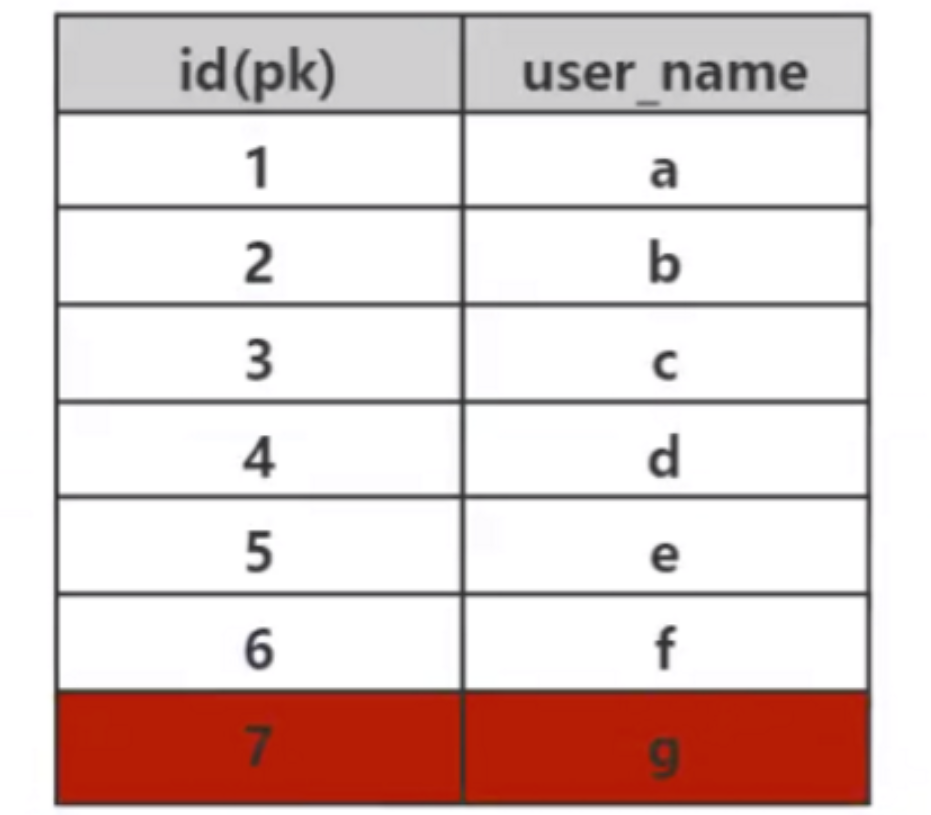
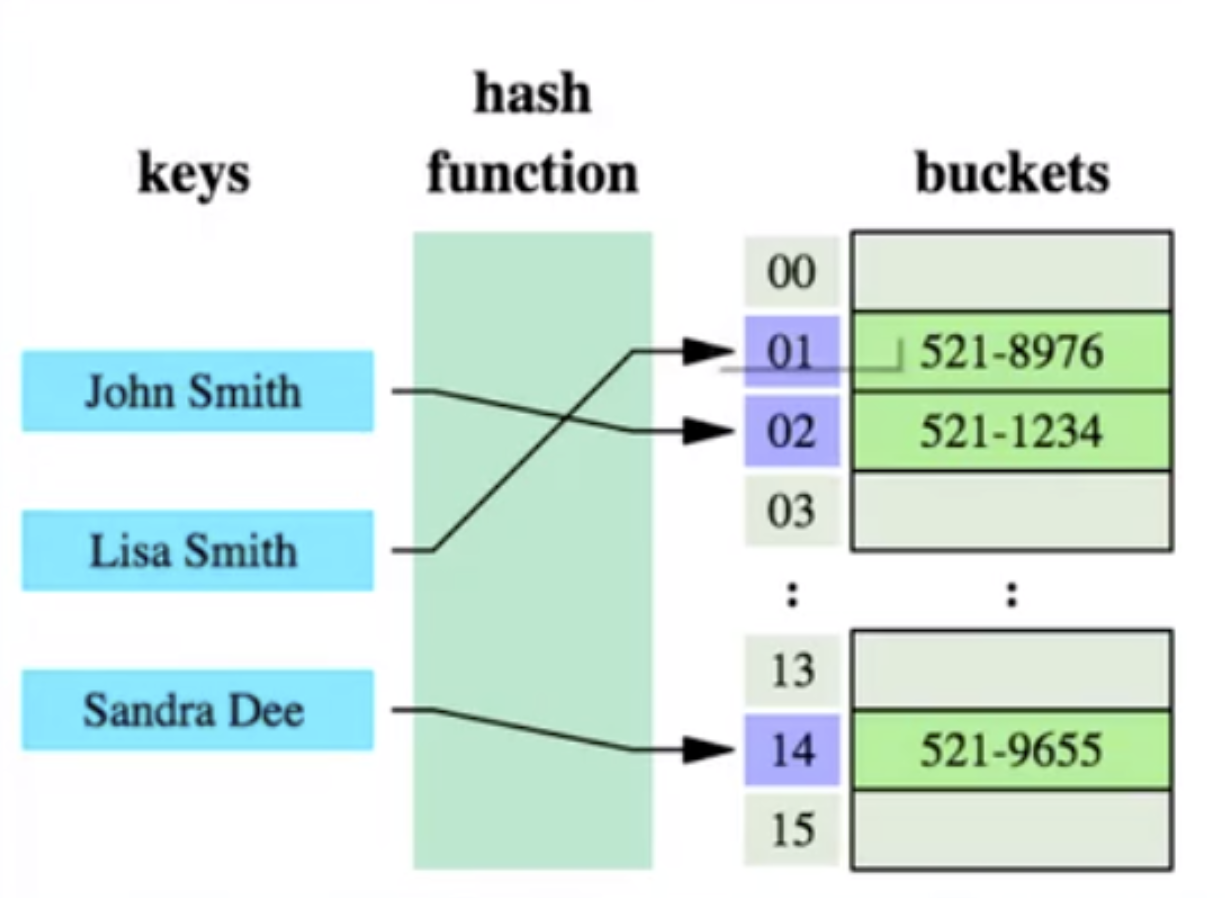
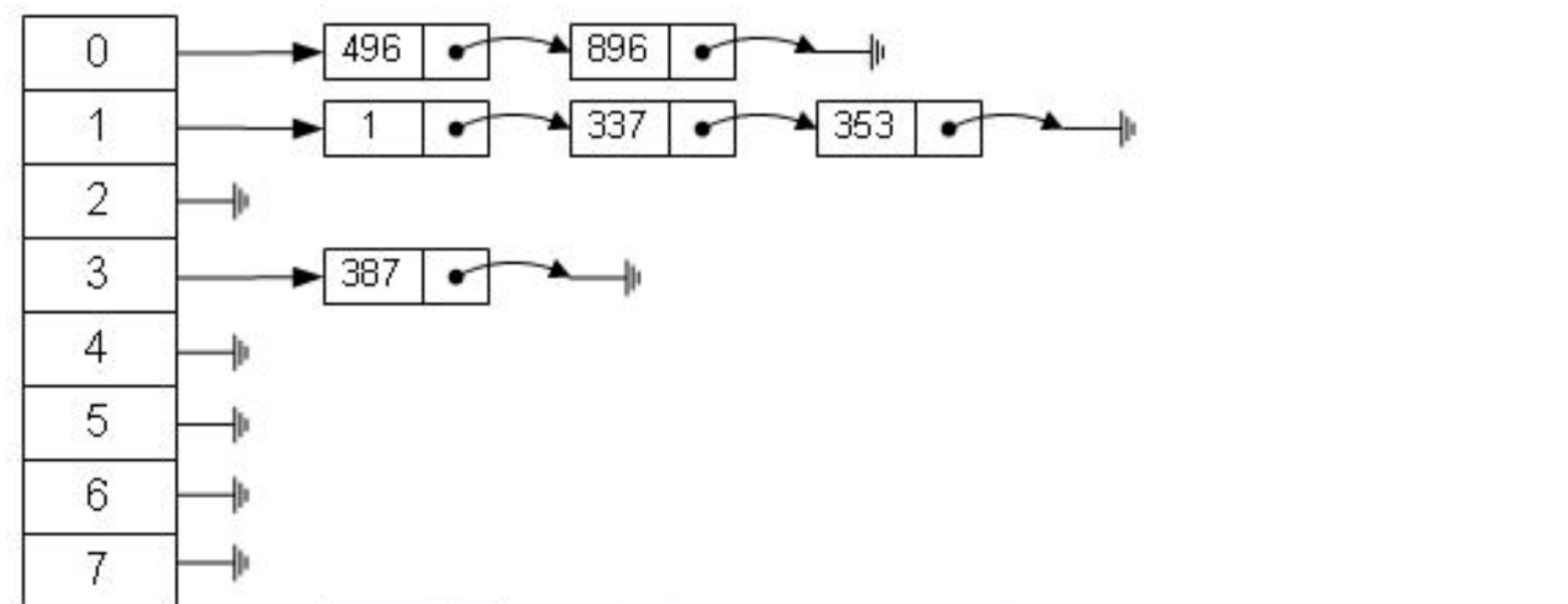
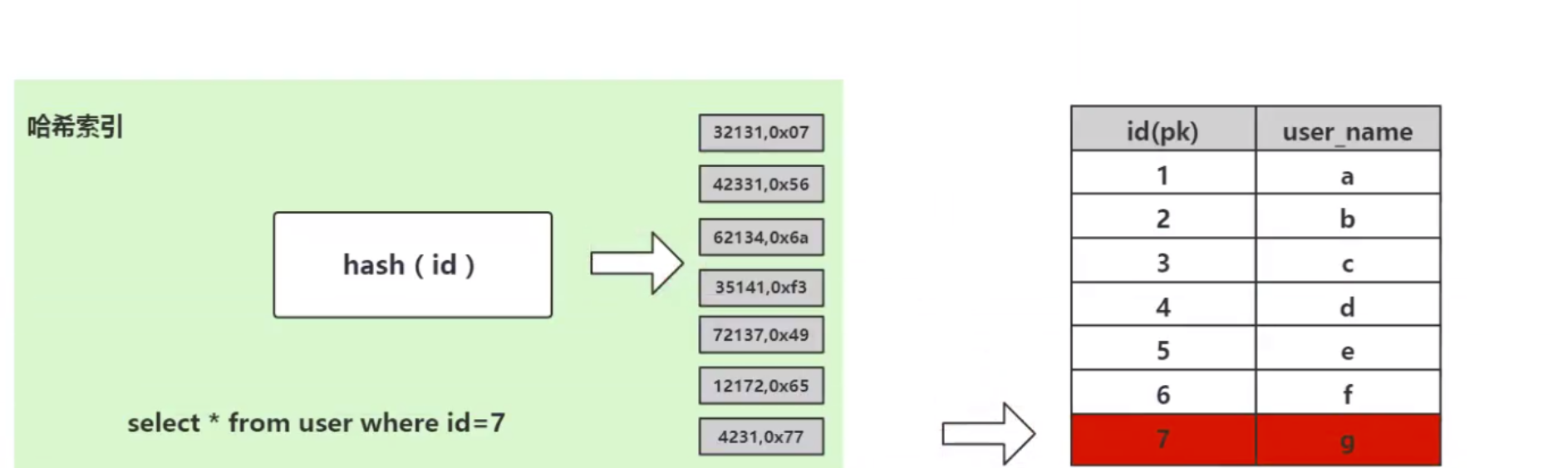
从算法时间复杂度分析来看,哈希算法时间复杂度为 O(1),检索速度非常快。比如查找 id=7 的数据,哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢?
因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句:
select \* from user where id \>3;
针对以上这个语句,我们希望做的是找出 id>3 的数据,这是很典型的范围查找。如果使用哈希算法实现的索引,范围查找怎么做呢?一个简单的思路就是一次把所有数据找出来加载到内存,然后再在内存里筛选筛选目标范围内的数据。但是这个范围查找的方法也太笨重了,没有一点效率而言。
所以,使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 Mysql 的底层索引的数据结构。


 发表于 2022-9-24 02:15:15
发表于 2022-9-24 02:15:15