2
5
8
新手上路
羿阁 萧箫 发自 凹非寺 量子位 | 公众号 QbitAI
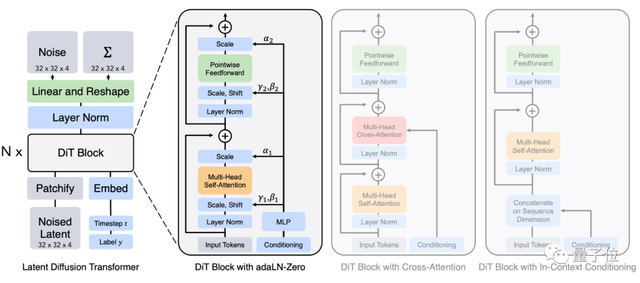
All we need is U-Transformer 希望他们没有错过Transffusion这个名字。
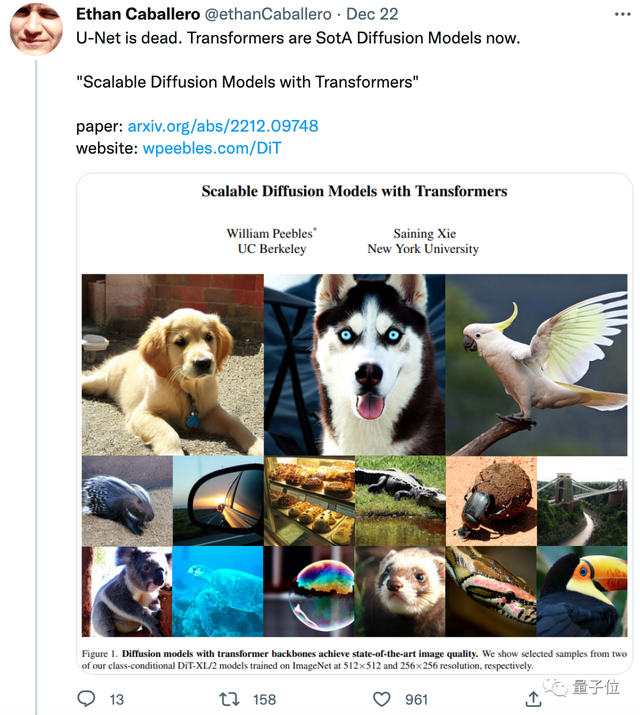
Stable-DiT马上就要来了!
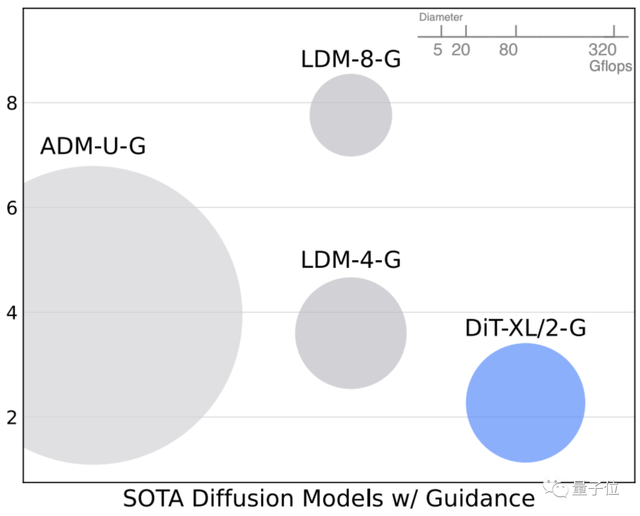
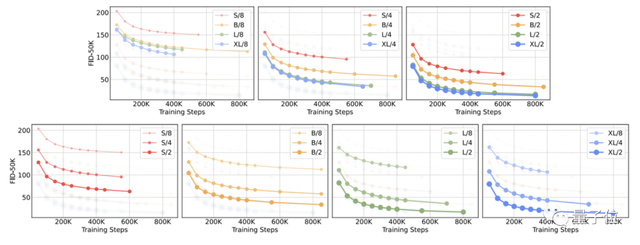
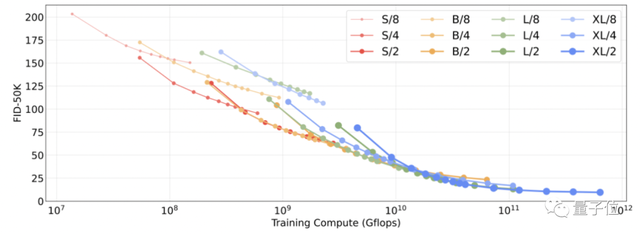
FID是计算真实图像和生成图像的特征向量之间距离的一种度量,越小越好。
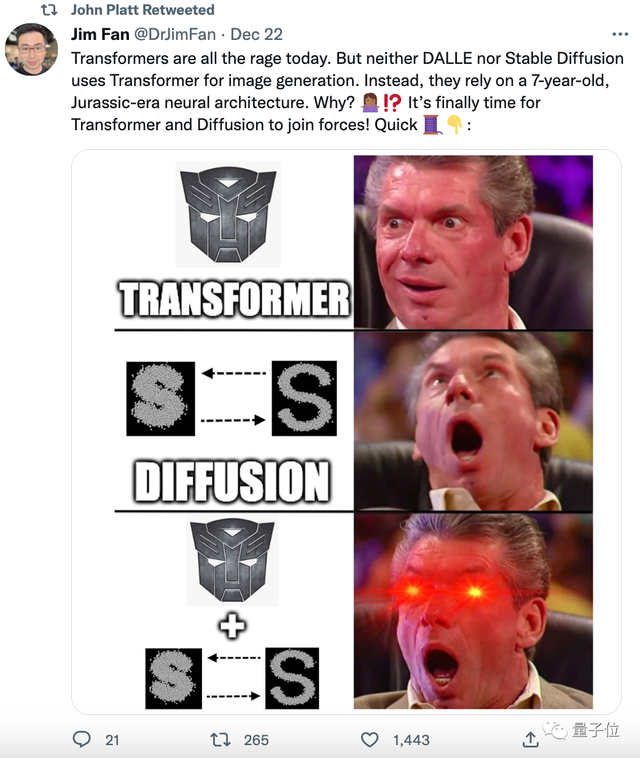
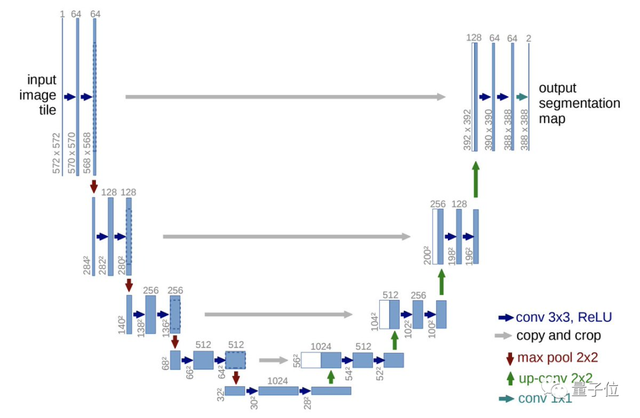
U-Net仍然充满生机,我相信只需要经过细小调整,有人能将它做得比Transformer更好。
使用道具 举报
0
10
16
4
9
3
7
11
19
1
15
6
本版积分规则 发表回复 回帖后跳转到最后一页


 发表于 2023-1-18 19:08:55
发表于 2023-1-18 19:08:55