|
|
再也不怕面试官问知道哪些新特性了!
《精进STL》预告篇
https://www.zhihu.com/video/1588636536324726785
语言可用性的强化
c语言兼容
/*
C++兼容C时,注意使用 extern "C",将C和C++代码进行分离编译,再统一链接
*/ //foo.h
#ifdef __cplusplus
extern "C"{
#endif
int add(int x,int y);
#ifdef __cplusplus
}
#endif
//foo.c
int add(int x,int y){
return x+y;
}
//foo.cpp
#include "foo.h"
#include <iostream>
#include <functional>
int main(){
[out = std::ref(std::cout<<&#34;Result from C code:: &#34;<<add(1,2))](){
out.get()<<&#34;.\n&#34;;
}();
return 0;
}
nullptr的真面目
/*
1, nullptr关键字专门用来区分空指针,0 . 其类型为nullptr_t,能够隐式的转换为任何指针或成员指针的类型
也能和他们进行相等或者不等的比较
2,decltype和std::is_same分别是用来类型推导和比较两个类型是否相同
*/ #include <iostream>
#include <type_traits>
void foo(char *){
std::cout << &#34;foo(char*) is called&#34;<<std::endl;
}
void foo(int){
std::cout << &#34;foo(int) is called&#34;<<std::endl;
}
int main(){
if (std::is_same<decltype(NULL),decltype(0)>::value)
std::cout<<&#34;NULL == 0&#34;<<std::endl;
if (std::is_same<decltype(NULL),decltype((void*)0)>::value)
std::cout<< &#34;NULL == (void*)0 &#34;<<std::endl;
if (std::is_same<decltype(NULL),std::nullptr_t>::value)
std::cout<< &#34;NULL == nullptr &#34;<<std::endl;
foo(0); //调用foo(int)
//foo(NULL);// 该行不能通过编译
foo(nullptr);//调用foo(char*)
return 0;
}
constexpr常量表达式
/*
如果编译器能够再编译时把常量表达式直接优化并植入到程序运行时,将能增加程序的性能
C++ 标准数组的长度必须是一个常量表达式,而不仅仅是一个 const 常数,相反,constexpr 让用户显式的声明函数
或对象构造函数再编译期会成为常量表达式。
注意:c++14开始,constexpr函数可以再内部使用局部变量,循环和分支等简单语句, 在C++11里多分支是不能够通过编译的
*/ #include <iostream>
#define LEN 10
int len_foo(){
int i =2;
return i;
}
constexpr int len_foo_constexpr(){
return 5;
}
constexpr int fibonacci(const int n){
return n == 1 || n == 2 ? 1:fibonacci(n-1) + fibonacci(n-2);
}
int main()
{
char arr_1[10];//合法
char arr_2[LEN];//合法
int len = 10;
// char arr_3[len];//非法
const int len_2 = len+1;
constexpr int len_2_constexpr = 1 + 2 + 3;
// char arr_4[len_2]; // 非法
char arr_4[len_2_constexpr]; // 合法
// char arr_5[len_foo()+5]; // 非法
char arr_6[len_foo_constexpr() + 1]; // 合法
std::cout << fibonacci(10) << std::endl;
// 1, 1, 2, 3, 5, 8, 13, 21, 34, 55
std::cout << fibonacci(10) << std::endl;
return 0;
}
if/swicth中定义变量
/**
C++17之前,if/switch语句中不能声明一个临时的变量,导致我们需要再次遍历整个 std::vector时,需要重新命名另一个变量
*/ #include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4};
// 在 c++17 之前
const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 2);
if (itr != vec.end()) {
*itr = 3;
}
// 需要重新定义一个新的变量
const std::vector<int>::iterator itr2 = std::find(vec.begin(), vec.end(), 3);
if (itr2 != vec.end()) {
*itr2 = 4;
}
for (std::vector<int>::iterator element = vec.begin(); element != vec.end();
++element)
std::cout << *element << std::endl;
//C++17
// 将临时变量放到 if 语句内
if (const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3);
itr != vec.end()) {
*itr = 4;
}
}
std::initializer_list初始化列表
/*
初始化列表
c++11把初始化列表绑定到类型上,称其为 std::initializer_list,允许构造函数或其他函数像参数一样使用
初始化列表,这为类对象的初始化与普通数组的初始化方法提供了统一的桥梁
*/ #include <initializer_list>
#include <vector>
#include <iostream>
class MagicFoo {
public:
std::vector<int> vec;
//初始化列表构造函数,用在对象构造上
MagicFoo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
//普通函数的形参
void foo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
};
int main() {
// after C++11
MagicFoo magicFoo = {1, 2, 3, 4, 5};
std::cout << &#34;magicFoo: &#34;;
for (std::vector<int>::iterator it = magicFoo.vec.begin();
it != magicFoo.vec.end(); ++it)
std::cout << *it << std::endl;
//函数
magicFoo.foo({6,7,8,9});
for (std::vector<int>::iterator it = magicFoo.vec.begin();
it != magicFoo.vec.end(); ++it)
std::cout << *it << std::endl;
//统一语法初始化任意的对象
MagicFoo foo2 {3, 4};
for (std::vector<int>::iterator it = magicFoo.vec.begin();
it != magicFoo.vec.end(); ++it)
std::cout << *it << std::endl;
}
std::tuple结构化绑定返回多值
/*
结构化绑定
std::tuple容器用于构造一个元组,可以囊括多个返回值
但是 C++11/14并没有提供一种简单的方法直接从元组中拿到并定义元组中的元素,尽管我们可以使用std::tie
对元组进行拆包,但是我们依然必须非常清楚这个元组中包含多少个对象,各个对象是什么类型,非常麻烦
C++17给出了结构化绑定的代码
*/ #include <iostream>
#include <tuple>
std::tuple<int, double, std::string> f() {
return std::make_tuple(1, 2.3, &#34;456&#34;);
}
int main() {
auto [x, y, z] = f();
std::cout << x << &#34;, &#34; << y << &#34;, &#34; << z << std::endl;
return 0;
}
尾部返回类型推导
/*
类型推导
decltype关键字是为了解决 auto 关键字只能对变量进行类型推导的缺陷而出现的
计算某个表达式的类型
auto x = 1;
auto y = 2;
decltype(x+y) z;
尾返回类型推导
auto 不能用于函数形参进行类型推导,auto能不能用于推戴函数的返回类型呢?
*/ #include <iostream>
template<typename R, typename T, typename U>
R add(T x, U y) {
return x+y;
}
//以上在使用这个模板函数时,必须明确指出返回类型
//如下改进是否可以
//decltype(x+y) add(T x, U y)
//不能通过编译,编译器在读到 decltype(x+y)时,x和y尚未被定义 //因此引入了尾返回类型
template<typename T, typename U>
auto add2(T x, U y) -> decltype(x+y){
return x + y;
}
//C++14中可以直接让普通函数具备返回值推导
template<typename T, typename U>
auto add3(T x, U y){
return x + y;
}
//decltype(auto) c++14提供的用法
//主要用来对转发函数或封装的返回类型进行推导,无需显式的指定 deltyp的参数表达式
//对下面两个函数进行封装 std::string lookup1();
std::string& lookup2();
std::string look_up_a_string_1() {
return lookup1();
}
std::string& look_up_a_string_2() {
return lookup2();
}
//有了 decltype(auto),我们可以让编译器完成这一件烦人的参数转发
decltype(auto) look_up_a_string_1() {
return lookup1();
}
decltype(auto) look_up_a_string_2() {
return lookup2();
}
int main()
{
// after c++11
auto w = add2<int, double>(1, 2.0);
if (std::is_same<decltype(w), double>::value) {
std::cout << &#34;w is double: &#34;;
}
std::cout << w << std::endl;
// after c++14
auto q = add3<double, int>(1.0, 2);
std::cout << &#34;q: &#34; << q << std::endl;
}
if constexpr控制流
/*
控制流 if constexpr
constexpr关键是将表达式或函数编译为常量结果,如果把这一特性引入到条件判断中去,
让代码在编译时就完成分支判断,提高程序的效率
因此,c++17将 constexpr关键字引入到if语句中,允许在代码中声明常量表达式的判断条件
*/ #include <iostream>
#include <vector>
template<typename T>
auto print_type_info(const T& t) {
if constexpr (std::is_integral<T>::value) {
return t + 1;
} else {
return t + 0.001;
}
}
//在编译时,时间代码表现如下
// int print_type_info(const int& t) {
// return t + 1;
// }
// double print_type_info(const double& t) {
// return t + 0.001;
// }
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
std::vector<int> vec = {1, 2, 3, 4};
if (auto itr = std::find(vec.begin(), vec.end(), 3); itr != vec.end()) *itr = 4;
for (auto element : vec)
std::cout << element << std::endl; // read only
for (auto &element : vec) {
element += 1; // writeable
}
for (auto element : vec)
std::cout << element << std::endl; // read only
}
如何对变长参数模板进行解包
/*
模板
传统C++,模板只有在使用的时候才会被编译器实例化,只要在每个编译单元(文件)中编译的代码中遇到了被完整定义的模板,
都会实例化。这就产生了重复实例化而导致的编译时间的增加。并且,我们没有办法通知编译器不要触发模板的实例化
C++引入了外部模板,扩充了原本的强制编译器在特定位置实例化模板的语法,使我们能够显式的通知编译器何时进行模板的实例化
*/ template class std::vector<bool>; // 强行实例化
extern template class std::vector<double>; // 不在该当前编译文件中实例化模板
/*
类型别名模板
模式式用来产生类型的,传统 C++中,typedef可以定义一个新的名称,但却没有办法为模板定义一个新的名称。
因为,模板不是类型
*/ template<typename T, typename U>
class MagicType {
public:
T dark;
U magic;
};
// 不合法
template<typename T>
typedef MagicType<std::vector<T>, std::string> FakeDarkMagic;
//using
typedef int (*process)(void *);
using NewProcess = int(*)(void *);
template<typename T>
using TrueDarkMagic = MagicType<std::vector<T>, std::string>;
int main() {
TrueDarkMagic<bool> you;
}
//变长参数模板
//允许任意个数、任意类别的模板参数,同时也不需要在定义时将参数的个数固定 template<typename... Ts> class Magic;
//模板类 Magic 的对象,能够接受不受限制个数的 typename 作为模板的形式参数,例如下面的定义
class Magic<int,
std::vector<int>,
std::map<std::string,
std::vector<int>>> darkMagic;
//既然是任意形式,所以个数为 0 的模板参数也是可以的
class Magic<> nothing;
//如果不希望产生的模板参数个数为 0,可以手动的定义至少一个模板参数:
template<typename Require, typename... Args> class Magic;
//除了在模板参数中能使用 ... 表示不定长模板参数外,
//函数参数也使用同样的表示法代表不定长参数,这也就为我们简单编写变长参数函数提供了便捷的手段
template<typename... Args> void printf(const std::string &str, Args... args);
//我们定义了变长的模板参数,如何对参数进行解包呢? //1,,我们可以使用 sizeof... 来计算参数的个数
template<typename... Ts>
void magic(Ts... args) {
std::cout << sizeof...(args) << std::endl;
}
//我们可以传递任意个参数给 magic 函数:
magic(); // 输出 0
magic(1); // 输出 1
magic(1, &#34;&#34;); // 输出 2
//2,对参数进行解包,到目前为止还没有一种简单的方法能够处理参数包,但有两种经典的处理手法:
//1. 递归模板函数
//递归是非常容易想到的一种手段,也是最经典的处理方法。这种方法不断递归地向函数传递模板参
//数,进而达到递归遍历所有模板参数的目的: #include <iostream>
template<typename T0>
void printf1(T0 value) {
std::cout << value << std::endl;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, &#34;123&#34;, 1.1);
return 0;
}
//2. 变参模板展开
//C++17 中增加了变参模板展开的支持,于是你可以在一个函数中完成 printf 的编写 template<typename T0, typename... T>
void printf2(T0 t0, T... t) {
std::cout << t0 << std::endl;
if constexpr (sizeof...(t) > 0) printf2(t...);
}
//3. 初始化列表展开
//递归模板函数是一种标准的做法,但缺点显而易见的在于必须定义一个终止递归的函数。 template<typename T, typename... Ts>
auto printf3(T value, Ts... args) {
std::cout << value << std::endl;
(void) std::initializer_list<T>{([&args] {
std::cout << args << std::endl;
}(), value)...};
}
折叠表达式
//C++ 17 中将变长参数这种特性进一步带给了表达式
#include <iostream>
template<typename ... T>
auto sum(T ... t) {
return (t + ...);
}
int main() {
std::cout << sum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) << std::endl;
}
非模板类型参数推导
/非类型模板参数推导
//前面我们主要提及的是模板参数的一种形式:类型模板参数
template <typename T, typename U>
auto add(T t, U u) {
return t+u;
}
//其中模板的参数 T 和 U 为具体的类型。但还有一种常见模板参数形式可以让不同字面量成为模板参数,即非类型模板参数
template <typename T, int BufSize>
class buffer_t {
public:
T& alloc();
void free(T& item);
private:
T data[BufSize];
}
buffer_t<int, 100> buf; // 100 作为模板参数
//既然此处的模板参数以具体的字面量进行传递,能否让编译器辅助我们进行类型推导,通过使用占位符 auto 从而不再需要明确指明类型?幸运的是,C++17 引入了这一特性,
//我们的确可以 auto 关键字,让编译器辅助完成具体类型的推导
template <auto value> void foo() {
std::cout << value << std::endl;
return;
}
int main() {
foo<10>(); // value 被推导为 int 类型
}
委托和继承构造
/*
委托构造
委托构造使得构造函数可以在同一个类中一个构造函数调用另一个构造函数,从而简化代码
*/ #include <iostream>
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() { // 委托 Base() 构造函数
value2 = value;
}
};
//继承构造
//在传统 C++ 中,构造函数如果需要继承是需要将参数一一传递的,这将导致效率低下。C++11 利
//用关键字 using 引入了继承构造函数的概念 class Subclass : public Base {
public:
using Base::Base; // 继承构造
};
//显式虚函数重载
/*
SubClass::foo 可能并不是程序员尝试重载虚函数,只是恰好加入了一个具有相同名字的函数。另
一个可能的情形是,当基类的虚函数被删除后,子类拥有旧的函数就不再重载该虚拟函数并摇身一变成
为了一个普通的类方法,这将造成灾难性的后果。
*/ struct Base {
virtual void foo();
};
struct SubClass: Base {
void foo();
};
//C++11 引入了 override 和 final 这两个关键字来防止上述情形的发生
/*
override 当重载虚函数时,引入 override 关键字将显式的告知编译器进行重载,编译器将检查基函
数是否存在这样的虚函数,否则将无法通过编译
*/ struct Base {
virtual void foo(int);
};
struct SubClass: Base {
virtual void foo(int) override; // 合法
virtual void foo(float) override; // 非法, 父类没有此虚函数
};
//final final 则是为了防止类被继续继承以及终止虚函数继续重载引入的
struct Base {
virtual void foo() final;
};
struct SubClass1 final: Base {
}; // 合法
struct SubClass2 : SubClass1 {
}; // 非法, SubClass1 已 final
struct SubClass3: Base {
void foo(); // 非法, foo 已 final
};
为什么会出现禁用默认函数
//显式禁用默认函数
/*
无法精确控制默认函数的生成行为。例如禁止类的拷贝时,必须将复制构造
函数与赋值算符声明为 private。尝试使用这些未定义的函数将导致编译或链接错误,则是一种非常不
优雅的方式。
并且,编译器产生的默认构造函数与用户定义的构造函数无法同时存在。若用户定义了任何构造函
数,编译器将不再生成默认构造函数,但有时候我们却希望同时拥有这两种构造函数,这就造成了尴尬。
C++11 提供了上述需求的解决方案,允许显式的声明采用或拒绝编译器自带的函数。
*/ class Magic {
public:
Magic() = default; // 显式声明使用编译器生成的构造
Magic& operator=(const Magic&) = delete; // 显式声明拒绝编译器生成构造
Magic(int magic_number);
};
int main() {
Base b(2);
std::cout << b.value1 << std::endl;
std::cout << b.value2 << std::endl;
Subclass s(3);
std::cout << s.value1 << std::endl;
std::cout << s.value2 << std::endl;
}
语言运行期得强化
lambda的三种捕获列表
/*
lambda表达式的捕获列表
参数的一种类型,lambda内部函数体在默认情况下是不能够使用函数体外部的变量的,捕获列表可以起到
传递外部数据的作用,根据传递的行为,捕获列表分为:
*/
/*
1,值捕获
与参数传值类似,值捕获的前提是变量可以拷贝,不同之处在于,被捕获的变量在lambda被创建时拷贝,而非调用时才拷贝
*/ #include <iostream>
void lambda_value_capture() {
int value = 1;
auto copy_value = [value] {
return value;
};
value = 100;
auto stored_value = copy_value();
std::cout << &#34;stored_value = &#34; << stored_value << std::endl;
// 这时, stored_value == 1, 而 value == 100.
// 因为 copy_value 在创建时就保存了一份 value 的拷贝
}
/*
2,引用捕获
与引用参数类似,引用捕获保存的是引用,值会发生变化
*/ void lambda_value_capture() {
int value = 1;
auto copy_value = [value] {
return value;
};
value = 100;
auto stored_value = copy_value();
std::cout << &#34;stored_value = &#34; << stored_value << std::endl;
// 这时, stored_value == 100, value == 100.
// 因为 copy_value 保存的是引用
}
/*
3,隐式捕获
• [] 空捕获列表
• [name1, name2, . . . ] 捕获一系列变量
• [&] 引用捕获, 让编译器自行推导引用列表
• [=] 值捕获, 让编译器自行推导值捕获列表
*/
/*
4,表示式捕获
C++14中,允许捕获的成员用任意的表达式进行初始化,允许右值得捕获,被声明得捕获变量类似会根据表达式进行判断,
判断方式与使用auto本质上是相同的
*/ void lambda_expression_capture() {
auto important = std::make_unique<int>(1);
//important 是一个独占指针,是不能够被 “=” 值捕获到,这时候我们可以将其转
//移为右值,在表达式中初始化
auto add = [v1 = 1, v2 = std::move(important)](int x, int y) -> int {
return x+y+v1+(*v2);
};
std::cout << add(3,4) << std::endl;
}
泛型lambda
/*
泛型lambda
c++14中,lambda函数的形参可以使用auto关键字进行泛型
*/
auto add = [](auto x, auto y) {
return x+y;
};
add(1, 2);
add(1.1, 2.2);
std::function函数对象包装器
/*
函数对象包装器
lambda表达式的本质是一个和函数对象类型相似的类类型的对象,当lambda表达式的捕获列表为空时,
闭包对象还能够转换为函数指针值进行传递
*/ using foo = void(int); // 定义函数类型, using 的使用见上一节中的别名语法
void functional(foo f) { // 参数列表中定义的函数类型 foo 被视为退化后的函数指针类型 foo*
f(1); // 通过函数指针调用函数
}
int main() {
auto f = [](int value) {
std::cout << value << std::endl;
};
//一种是将 Lambda 作为函数类型传递进行调用
functional(f); // 传递闭包对象,隐式转换为 foo* 类型的函数指针值
//另一种则是直接调用 Lambda 表达式
f(1); // lambda 表达式调用
return 0;
}
/*
std::function
一种通用,多态的函数封装,它的实例可以对任何调用的目标实体进行存储,复制和调用操作,也是对C++
中现有的可调用实体的一种类型安全的包裹。
可以将其理解为函数的容器,有了函数的容器之后便能够更加方便的将函数,函数指针作为对象进行处理
*/ #include <functional>
#include <iostream>
int foo(int para) {
return para;
}
int main() {
// std::function 包装了一个返回值为 int, 参数为 int 的函数
std::function<int(int)> func = foo;
int important = 10;
std::function<int(int)> func2 = [&](int value) -> int {
return 1+value+important;
};
std::cout << func(10) << std::endl;
std::cout << func2(10) << std::endl;
}
std::bing和std::placeholder
/*
std::bing和std::placeholder
std::bind用来绑定函数调用的参数的,解决的是我们有时候可能并不一定能够一次性获得调用某个函数的全部参数,
通过这个函数,我们可以将部分调用参数提前绑定到函数身上成为一个新的对象,然后在参数齐全后,完成调用
*/ int foo(int a, int b, int c) {
;
}
int main() {
// 将参数 1,2 绑定到函数 foo 上,
// 但使用 std::placeholders::_1 来对第一个参数进行占位
auto bindFoo = std::bind(foo, std::placeholders::_1, 1,2);
// 这时调用 bindFoo 时,只需要提供第一个参数即可
bindFoo(1);
}
右值分为纯右值和将亡值
/*
右值引用
消除了如 std::vector和std::string之类的额外开销,才使得函数对象容器 std::function成为了可能
左值 (lvalue, left value),顾名思义就是赋值符号左边的值。准确来说,左值是表达式(不一定是赋
值表达式)后依然存在的持久对象。
右值 (rvalue, right value),右边的值,是指表达式结束后就不再存在的临时对象。
右值分为:
*/
/*
1,纯右值
纯粹的字面量,例如 10,true,求值结果相当于字面量或匿名临时对象,例如1+2,非引用返回的临时变量,
运算表达式产生的临时变量,原始字面量,lambda表达式都属于纯右值。
注意:字符串字面量是一个左值,类型为const char数组,其余均为纯右值
*/ #include <type_traits>
int main() {
// 正确,&#34;01234&#34; 类型为 const char [6],因此是左值
const char (&left)[6] = &#34;01234&#34;;
// 断言正确,确实是 const char [6] 类型,注意 decltype(expr) 在 expr 是左值
// 且非无括号包裹的 id 表达式与类成员表达式时,会返回左值引用
static_assert(std::is_same<decltype(&#34;01234&#34;), const char(&)[6]>::value, &#34;&#34;);
// 错误,&#34;01234&#34; 是左值,不可被右值引用
// const char (&&right)[6] = &#34;01234&#34;;
}
/*
2,将亡值
即将被销毁,却能够被移动的值
传统的理解而言,函数 foo 的返回值 temp 在内部创建然后被赋值给 v,然而 v
获得这个对象时,会将整个 temp 拷贝一份,然后把 temp 销毁,如果这个 temp 非常大,这将造成大量
额外的开销(这也就是传统 C++ 一直被诟病的问题)。在最后一行中,v 是左值、foo() 返回的值就是
右值(也是纯右值)。但是,v 可以被别的变量捕获到,而 foo() 产生的那个返回值作为一个临时值,一
旦被 v 复制后,将立即被销毁,无法获取、也不能修改
*/ std::vector<int> foo() {
std::vector<int> temp = {1, 2, 3, 4};
return temp;
}
std::vector<int> v = foo();
右值引用对将亡值的拿捏
/*
右值引用和左值引用
要拿到一个将亡值,就需要用到右值引用:T &&,其中 T 是类型。右值引用的声明让这个临时值的
生命周期得以延长、只要变量还活着,那么将亡值将继续存活。
C++11 提供了 std::move 这个方法将左值参数无条件的转换为右值,有了它我们就能够方便的获
得一个右值临时对象。
*/ #include <iostream>
#include <string>
void reference(std::string& str) {
std::cout << &#34; 左值&#34; << std::endl;
}
void reference(std::string&& str) {
std::cout << &#34; 右值&#34; << std::endl;
}
int main()
{
std::string lv1 = &#34;string,&#34;; // lv1 是一个左值
// std::string&& r1 = lv1; // 非法, 右值引用不能引用左值
std::string&& rv1 = std::move(lv1); // 合法, std::move 可以将左值转移为右值
std::cout << rv1 << std::endl; // string,
const std::string& lv2 = lv1 + lv1; // 合法, 常量左值引用能够延长临时变量的生命周期
// lv2 += &#34;Test&#34;; // 非法, 常量引用无法被修改
std::cout << lv2 << std::endl; // string,string,
std::string&& rv2 = lv1 + lv2; // 合法, 右值引用延长临时对象生命周期
rv2 += &#34;Test&#34;; // 合法, 非常量引用能够修改临时变量
std::cout << rv2 << std::endl; // string,string,string,Test
reference(rv2); // 输出左值
//rv2 虽然引用了一个右值,但由于它是一个引用,所以 rv2 依然是一个左值
return 0;
}
//为什么不允许非常量引用绑定到非左值? #include <iostream>
int main() {
// int &a = std::move(1); // 不合法,非常量左引用无法引用右值
const int &b = std::move(1); // 合法, 常量左引用允许引用右值
std::cout << a << b << std::endl;
}
void increase(int & v) {
v++;
}
void foo() {
double s = 1;
//int& 不能引用 double 类型的参数,因此必须产生一个临时值来保存 s 的值,从而当
//increase() 修改这个临时值时,调用完成后 s 本身并没有被修改
increase(s);
}
移动语义的通俗理解
/*
移动语义
试想,搬家的时候是把家里的东西直接搬到新家去,而不是将所有东西复制一份(重买)再放到新家、再把原来的东
西全部扔掉(销毁),这是非常反人类的一件事情。
传统 C++ 通过拷贝构造函数和赋值操作符为类对象设计了拷贝/复制的概念,但为了实现对资源的
移动操作,调用者必须使用先复制、再析构的方式,否则就需要自己实现移动对象的接口
传统的 C++ 没有区分『移动』和『拷贝』的概念,造成了大量的数据拷贝,浪费时间和空间。右值
引用的出现恰好就解决了这两个概念的混淆问题
*/ #include <iostream>
class A {
public:
int *pointer;
A():pointer(new int(1)) {
std::cout << &#34; 构造&#34; << pointer << std::endl;
}
A(A& a):pointer(new int(*a.pointer)) {
std::cout << &#34; 拷贝&#34; << pointer << std::endl;
} // 无意义的对象拷贝
A(A&& a):pointer(a.pointer) {
a.pointer = nullptr;
std::cout << &#34; 移动&#34; << pointer << std::endl;
}
~A(){
std::cout << &#34; 析构&#34; << pointer << std::endl;
delete pointer;
}
};
// 防止编译器优化
A return_rvalue(bool test) {
A a,b;
if(test) return a; // 等价于 static_cast<A&&>(a);
else return b; // 等价于 static_cast<A&&>(b);
}
int main() {
A obj = return_rvalue(false);
std::cout << &#34;obj:&#34; << std::endl;
std::cout << obj.pointer << std::endl;
std::cout << *obj.pointer << std::endl;
return 0;
}
/*
\1. 首先会在 return_rvalue 内部构造两个 A 对象,于是获得两个构造函数的输出;
\2. 函数返回后,产生一个将亡值,被 A 的移动构造(A(A&&))引用,从而延长生命周期,并将这个右
值中的指针拿到,保存到了 obj 中,而将亡值的指针被设置为 nullptr,防止了这块内存区域被销
毁。
*/ //从而避免了无意义的拷贝构造,加强了性能。再来看看涉及标准库的例子
#include <iostream> // std::cout
#include <utility> // std::move
#include <vector> // std::vector
#include <string> // std::string
int main() {
std::string str = &#34;Hello world.&#34;;
std::vector<std::string> v;
// 将使用 push_back(const T&), 即产生拷贝行为
v.push_back(str);
// 将输出 &#34;str: Hello world.&#34;
std::cout << &#34;str: &#34; << str << std::endl;
// 将使用 push_back(const T&&), 不会出现拷贝行为
// 而整个字符串会被移动到 vector 中,所以有时候 std::move 会用来减少拷贝出现的开销
// 这步操作后, str 中的值会变为空
v.push_back(std::move(str));
// 将输出 &#34;str: &#34;
std::cout << &#34;str: &#34; << str << std::endl;
return 0;
}
std::forward为何同时支持左值和右值
/*
完美转发
一个声明的右值引用其实是一个左值
对于 pass(1) 来说,虽然传递的是右值,但由于 v 是一个引用,所以同时也是左值。因此
reference(v) 会调用 reference(int&),输出『左值』。而对于 pass(l) 而言,l 是一个左值,为什么
会成功传递给 pass(T&&) 呢?
*/ void reference(int& v) {
std::cout << &#34; 左值&#34; << std::endl;
}
void reference(int&& v) {
std::cout << &#34; 右值&#34; << std::endl;
}
template <typename T>
void pass(T&& v) {
std::cout << &#34; 普通传参:&#34;;
reference(v); // 始终调用 reference(int&)
}
int main() {
std::cout << &#34; 传递右值:&#34; << std::endl;
pass(1); // 1 是右值, 但输出是左值
std::cout << &#34; 传递左值:&#34; << std::endl;
int l = 1;
pass(l); // l 是左值, 输出左值
return 0;
}
/*
模板函数中使用 T&& 不一定能进行右值引用,当传入左值时,此函数的引用将被推导为左值。
更准确的讲,无论模板参数是什么类型的引用,当且仅当实参类型为右引用时,模板参数才能被推导为
右引用类型。
所谓完美转发,就是为了让我们在传递参数的时候,保持原来的参数类型(左引用保持左引用,右引用保持右引用)。
为了解决这个问题,我们应该使用 std::forward来进行参数的转发(传递):
*/ #include <iostream>
#include <utility>
void reference(int& v) {
std::cout << &#34; 左值引用&#34; << std::endl;
}
void reference(int&& v) {
std::cout << &#34; 右值引用&#34; << std::endl;
}
template <typename T>
void pass(T&& v) {
std::cout << &#34; 普通传参: &#34;;
reference(v);
std::cout << &#34; std::move 传参: &#34;;
reference(std::move(v));
std::cout << &#34; std::forward 传参: &#34;;
reference(std::forward<T>(v));
std::cout << &#34;static_cast<T&&> 传参: &#34;;
reference(static_cast<T&&>(v));
}
int main() {
std::cout << &#34; 传递右值:&#34; << std::endl;
pass(1);
std::cout << &#34; 传递左值:&#34; << std::endl;
int v = 1;
pass(v);
return 0;
}
传递右值:
普通传参: 左值引用
std::move 传参: 右值引用
std::forward 传参: 右值引用
static_cast<T&&> 传参: 右值引用
传递左值:
普通传参: 左值引用
std::move 传参: 右值引用
std::forward 传参: 左值引用
static_cast<T&&> 传参: 左值引用
无论传递参数为左值还是右值,普通传参都会将参数作为左值进行转发,所以 std::move 总会接受
到一个左值,从而转发调用了 reference(int&&) 输出右值引用
std::forward 和 std::move 一样,没有做任何事情,std::move 单纯的将左值转化为右值,
std::forward 也只是单纯的将参数做了一个类型的转换,从现象上来看,std::forward(v) 和
static_cast<T&&>(v) 是完全一样的。
为何一条语句能够针对两种类型的返回对应的值,我们再简单看一看 std::forward的具体实现机制,std::forward 包含两个重载: template<typename _Tp>
constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type& __t) noexcept
{ return static_cast<_Tp&&>(__t); }
template<typename _Tp>
constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type&& __t) noexcept
{
static_assert(!std::is_lvalue_reference<_Tp>::value, &#34;template argument&#34;
&#34; substituting _Tp is an lvalue reference type&#34;);
return static_cast<_Tp&&>(__t);
}
在这份实现中,std::remove_reference 的功能是消除类型中的引用,std::is_lvalue_reference
则用于检查类型推导是否正确,在 std::forward 的第二个实现中检查了接收到的值确实是一个左值,进
而体现了坍缩规则。
当 std::forward 接受左值时,_Tp 被推导为左值,所以返回值为左值;而当其接受右值时,_Tp 被
推导为右值引用,则基于坍缩规则,返回值便成为了 && + && 的右值。可见 std::forward 的原理在于
巧妙的利用了模板类型推导中产生的差异 关于容器的新用法
std::array不同于传统数组和当代vector
/*
std::array
\1. 为什么要引入 std::array 而不是直接使用 std::vector?
\2. 已经有了传统数组,为什么要用 std::array?
*/
/*
1,与 std::vector 不同,std::array 对象的大小是固定的,如果容器大小是固定的,
那么可以优先考虑使用 std::array 容器。另外由于 std::vector 是自动扩容的,当存入大量的
数据后,并且对容器进行了删除操作,容器并不会自动归还被删除元素相应的内存,这时候就需要手动
运行 shrink_to_fit() 释放这部分内存。
*/ std::vector<int> v;
std::cout << &#34;size:&#34; << v.size() << std::endl; // 输出 0
std::cout << &#34;capacity:&#34; << v.capacity() << std::endl; // 输出 0
// 如下可看出 std::vector 的存储是自动管理的,按需自动扩张
// 但是如果空间不足,需要重新分配更多内存,而重分配内存通常是性能上有开销的操作
v.push_back(1);
v.push_back(2);
v.push_back(3);
std::cout << &#34;size:&#34; << v.size() << std::endl; // 输出 3
std::cout << &#34;capacity:&#34; << v.capacity() << std::endl; // 输出 4
v.push_back(4);
v.push_back(5);
std::cout << &#34;size:&#34; << v.size() << std::endl; // 输出 5
std::cout << &#34;capacity:&#34; << v.capacity() << std::endl; // 输出 8
// 如下可看出容器虽然清空了元素,但是被清空元素的内存并没有归还
v.clear();
std::cout << &#34;size:&#34; << v.size() << std::endl; // 输出 0
std::cout << &#34;capacity:&#34; << v.capacity() << std::endl; // 输出 8
// 额外内存可通过 shrink_to_fit() 调用返回给系统
v.shrink_to_fit();
std::cout << &#34;size:&#34; << v.size() << std::endl; // 输出 0
std::cout << &#34;capacity:&#34; << v.capacity() << std::endl; // 输出 0
/*
2,使用 std::array 能够让代码变得更加 ‘‘现代化’’,而且封装了一些操作函数,
比如获取数组大小以及检查是否非空,同时还能够友好的使用标准库中的容器算法,比如 std::sort
*/ std::array<int, 4> arr = {1, 2, 3, 4};
arr.empty(); // 检查容器是否为空
arr.size(); // 返回容纳的元素数
// 迭代器支持
for (auto &i : arr)
{
// ...
}
// 用 lambda 表达式排序
std::sort(arr.begin(), arr.end(), [](int a, int b) {
return b < a;
});
// 数组大小参数必须是常量表达式
constexpr int len = 4;
std::array<int, len> arr = {1, 2, 3, 4};
void foo(int *p, int len) {
return;
}
std::array<int, 4> arr = {1,2,3,4};
// C 风格接口传参
// foo(arr, arr.size()); // 非法, 无法隐式转换
foo(&arr[0], arr.size());
foo(arr.data(), arr.size());
// 使用 ‘std::sort‘
std::sort(arr.begin(), arr.end());
无序关联容器是随机的
/*
无序容器
有序容器 std::map/std::set,这些元素内部通过红黑树进行实现,
插入和搜索的平均复杂度均为 O(log(size))。
无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为
O(constant),在不关心容器内部元素顺序时,能够获得显著的性能提升。
*/ int main() {
// 两组结构按同样的顺序初始化
std::unordered_map<int, std::string> u = {
{1, &#34;1&#34;},
{3, &#34;3&#34;},
{2, &#34;2&#34;}
};
std::map<int, std::string> v = {
{1, &#34;1&#34;},
{3, &#34;3&#34;},
{2, &#34;2&#34;}
};
// 分别对两组结构进行遍历
std::cout << &#34;std::unordered_map&#34; << std::endl;
for( const auto & n : u)
std::cout << &#34;Key:[&#34; << n.first << &#34;] Value:[&#34; << n.second << &#34;]\n&#34;;
std::cout << std::endl;
std::cout << &#34;std::map&#34; << std::endl;
for( const auto & n : v)
std::cout << &#34;Key:[&#34; << n.first << &#34;] Value:[&#34; << n.second << &#34;]\n&#34;;
}
最终的输出结果为:
std::unordered_map
Key:[2] Value:[2]
Key:[3] Value:[3]
Key:[1] Value:[1]
std::map
Key:[1] Value:[1]
Key:[2] Value:[2]
Key:[3] Value:[3] 元组常用的三个函数
/*
元组
\1. std::make_tuple: 构造元组
\2. std::get: 获得元组某个位置的值
\3. std::tie: 元组拆包
*/ #include <tuple>
#include <iostream>
#include <variant>
auto get_student(int id)
{
// 返回类型被推断为 std::tuple<double, char, std::string>
if (id == 0)
return std::make_tuple(3.8, &#39;A&#39;, &#34; 张三&#34;);
if (id == 1)
return std::make_tuple(2.9,&#39;A&#39;, &#34; 李四&#34;);
if (id == 2)
return std::make_tuple(1.7, &#39;A&#39;, &#34; 王五&#34;);
return std::make_tuple(0.0,&#39;A&#39;, &#34;null&#34;);
// 如果只写 0 会出现推断错误, 编译失败
}
int main()
{
auto student = get_student(0);
std::cout << &#34;ID: 0, &#34;
<< &#34;GPA: &#34; << std::get<0>(student) << &#34;, &#34;
<< &#34; 成绩: &#34; << std::get<1>(student) << &#34;, &#34;
<< &#34; 姓名: &#34; << std::get<2>(student) << &#39;\n&#39;;
double gpa;
char grade;
std::string name;
// 元组进行拆包
std::tie(gpa, grade, name) = get_student(1);
std::cout << &#34;ID: 1, &#34;
<< &#34;GPA: &#34; << gpa << &#34;, &#34;
<< &#34; 成绩: &#34; << grade << &#34;, &#34;
<< &#34; 姓名: &#34; << name << &#39;\n&#39;;
//std::get 除了使用常量获取元组对象外,C++14 增加了使用类型来获取元组中的对象:
std::tuple<std::string, double, double, int> t(&#34;123&#34;, 4.5, 6.7, 8);
std::cout << std::get<std::string>(t) << std::endl;
// std::cout << std::get<double>(t) << std::endl; // 非法, 引发编译期错误
std::cout << std::get<3>(t) << std::endl;
}
元组的合并与遍历
/*
运行期索引
*/ template <size_t n, typename... T>
constexpr std::variant<T...> _tuple_index(const std::tuple<T...>& tpl, size_t i) {
if constexpr (n >= sizeof...(T))
throw std::out_of_range(&#34; 越界.&#34;);
if (i == n)
return std::variant<T...>{ std::in_place_index<n>, std::get<n>(tpl) };
return _tuple_index<(n < sizeof...(T)-1 ? n+1 : 0)>(tpl, i);
}
template <typename... T>
constexpr std::variant<T...> tuple_index(const std::tuple<T...>& tpl, size_t i) {
return _tuple_index<0>(tpl, i);
}
template <typename T0, typename ... Ts>
std::ostream & operator<< (std::ostream & s, std::variant<T0, Ts...> const & v) {
std::visit([&](auto && x){ s << x;}, v);
return s;
}
int main(){
int i = 1;
std::cout << tuple_index(t, i) << std::endl;
}
/*
元组合并与遍历
*/ /*
需要知道一个元组的长度
*/
template <typename T>
auto tuple_len(T &tpl) {
return std::tuple_size<T>::value;
}
int main(){
auto new_tuple = std::tuple_cat(get_student(1), std::move(t));
// 迭代
for(int i = 0; i != tuple_len(new_tuple); ++i)
// 运行期索引
std::cout << tuple_index(new_tuple, i) << std::endl;
}
快速上手智能指针
引用计数存在的意义
/*
引用计数
这种计数是为了防止内存泄露而产生的。基本想法是对于动态分配的对象,进行引用计数,每当增加一次对同一个对象的引用,那
么引用对象的引用计数就会增加一次,每删除一次引用,引用计数就会减一,当一个对象的引用计数减为零时,就自动删除指向的堆内存。
传统 C++
通常的做法是对于一个对象而言,我们在构造函数的时候申请空间,而在析构函数(在离开作用域时调用)的时候释放空间,
也就是我们常说的 RAII 资源获取即初始化技术。
C++11
引入了智能指针的概念,使用了引用计数的想法,让程序员不再需要关心手动释放内存。这些智能指针包括 std::shared_ptr/std::unique_ptr/std::weak_ptr,
使用它们需要包含头文件。 多个std::shared_ptr共同指向一个对象
/*
std::shared_ptr
记录多少个 shared_ptr 共同指向一个对象,从而消除显式的调用 delete,当引用计数变为零的时候就会将对象自动删除。
使用 std::shared_ptr 仍然需要使用 new 来调用,这使得代码出现了某种程度上的不对称。
std::make_shared 就能够用来消除显式的使用 new,所以 std::make_shared 会分配创建传入参数中的对象,并返回这个对象类型的 std::shared_ptr 指针
*/ #include <iostream>
#include <memory>
void foo(std::shared_ptr<int> i) {
(*i)++;
}
int main() {
// auto pointer = new int(10); // illegal, no direct assignment
// Constructed a std::shared_ptr
auto pointer = std::make_shared<int>(10);
foo(pointer);
std::cout << *pointer << std::endl; // 11
// The shared_ptr will be destructed before leaving the scope
return 0;
}
/*
std::shared_ptr 可以通过 get() 方法来获取原始指针,通过 reset() 来减少一个引用计数,并通过 use_count() 来查看一个对象的引用计数
*/ auto pointer = std::make_shared<int>(10);
auto pointer2 = pointer; // 引用计数 +1
auto pointer3 = pointer; // 引用计数 +1
int *p = pointer.get(); // 这样不会增加引用计数
std::cout << &#34;pointer.use_count() = &#34; << pointer.use_count() << std::endl; // 3
std::cout << &#34;pointer2.use_count() = &#34; << pointer2.use_count() << std::endl; // 3
std::cout << &#34;pointer3.use_count() = &#34; << pointer3.use_count() << std::endl; // 3
pointer2.reset();
std::cout << &#34;reset pointer2:&#34; << std::endl;
std::cout << &#34;pointer.use_count() = &#34; << pointer.use_count() << std::endl; // 2
std::cout << &#34;pointer2.use_count() = &#34;
<< pointer2.use_count() << std::endl; // pointer2 已 reset; 0
std::cout << &#34;pointer3.use_count() = &#34; << pointer3.use_count() << std::endl; // 2
pointer3.reset();
std::cout << &#34;reset pointer3:&#34; << std::endl;
std::cout << &#34;pointer.use_count() = &#34; << pointer.use_count() << std::endl; // 1
std::cout << &#34;pointer2.use_count() = &#34; << pointer2.use_count() << std::endl; // 0
std::cout << &#34;pointer3.use_count() = &#34;
<< pointer3.use_count() << std::endl; // pointer3 已 reset; 0
禁止其他智能指针与std::unique_ptr共享同一个对象
/*
std::unique_ptr
std::unique_ptr 是一种独占的智能指针,它禁止其他智能指针与其共享同一个对象,从而保证代码的安全
*/ std::unique_ptr<int> pointer = std::make_unique<int>(10); // make_unique 从 C++14 引入
std::unique_ptr<int> pointer2 = pointer; // 非法
//make_unique 并不复杂,C++11 没有提供 std::make_unique,可以自行实现: template<typename T, typename ...Args>
std::unique_ptr<T> make_unique( Args&& ...args ) {
return std::unique_ptr<T>( new T( std::forward<Args>(args)... ) );
}
//既然是独占,换句话说就是不可复制。但是,我们可以利用 std::move 将其转移给其他的unique_ptr #include <iostream>
#include <memory>
struct Foo {
Foo() { std::cout << &#34;Foo::Foo&#34; << std::endl; }
~Foo() { std::cout << &#34;Foo::~Foo&#34; << std::endl; }
void foo() { std::cout << &#34;Foo::foo&#34; << std::endl; }
};
void f(const Foo &) {
std::cout << &#34;f(const Foo&)&#34; << std::endl;
}
int main() {
std::unique_ptr<Foo> p1(std::make_unique<Foo>());
// p1 不空, 输出
if (p1)
p1->foo();
{
std::unique_ptr<Foo> p2(std::move(p1));
// p2 不空, 输出
f(*p2);
// p2 不空, 输出
if(p2)
p2->foo();
// p1 为空, 无输出
if(p1)
p1->foo();
p1 = std::move(p2);
// p2 为空, 无输出
if(p2)
p2->foo();
std::cout << &#34;p2 被销毁&#34; << std::endl;
}
// p1 不空, 输出
if (p1)
p1->foo();
// Foo 的实例会在离开作用域时被销毁
}
std::weak_ptr解决std::shared_ptr资源无法释放的情况
/*
std::weak_ptr
如果你仔细思考 std::shared_ptr 就会发现依然存在着资源无法释放的问题
*/ struct A;
struct B;
struct A {
std::shared_ptr<B> pointer;
~A() {
std::cout << &#34;A 被销毁&#34; << std::endl;
}
};
struct B {
std::shared_ptr<A> pointer;
~B() {
std::cout << &#34;B 被销毁&#34; << std::endl;
}
};
int main() {
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->pointer = b;
b->pointer = a;
}
/*
运行结果是 A, B 都不会被销毁,这是因为 a,b 内部的 pointer 同时又引用了 a,b,这使得 a,b 的引
用计数均变为了 2,而离开作用域时,a,b 智能指针被析构,却只能造成这块区域的引用计数减一,这样
就导致了 a,b 对象指向的内存区域引用计数不为零,而外部已经没有办法找到这块区域了,也就造成了
内存泄露
*/
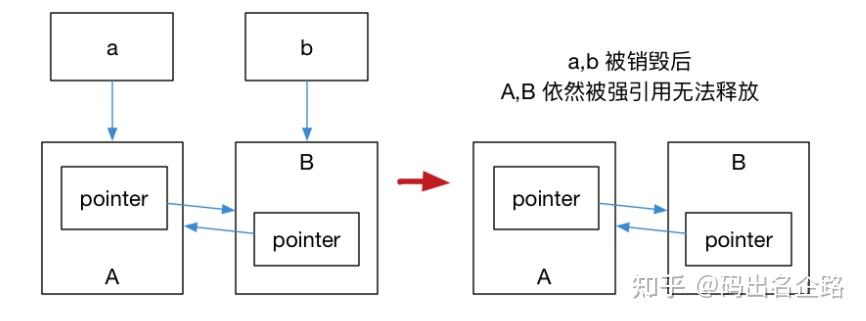
解决这个问题的办法就是使用弱引用指针 std::weak_ptr,std::weak_ptr 是一种弱引用(相比较
而言 std::shared_ptr 就是一种强引用)。弱引用不会引起引用计数增加,当换用弱引用时候,最终的
释放流程
最后一步只剩下 B,而 B 并没有任何智能指针引用它,因此这块内存资源也会被释放
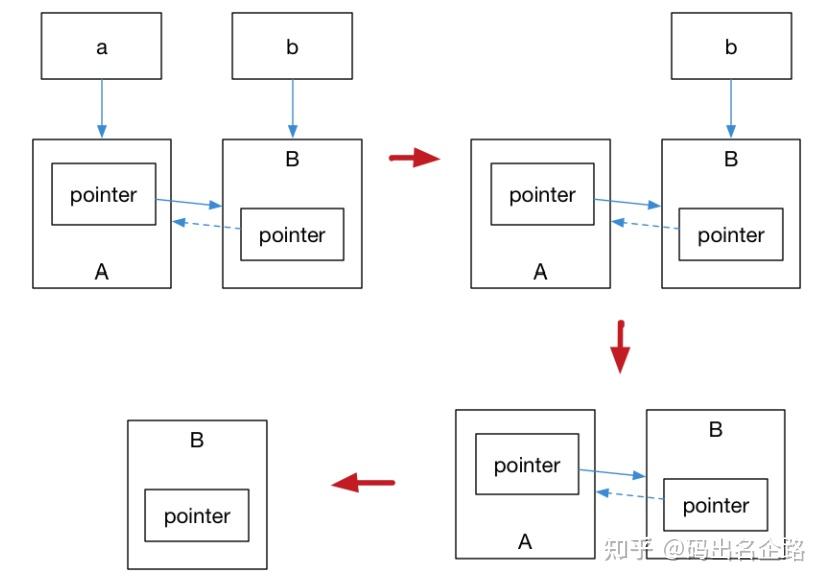
/*
std::weak_ptr 没有 * 运算符和 -> 运算符,所以不能够对资源进行操作,它可以用于检查
std::shared_ptr 是否存在,其 expired() 方法能在资源未被释放时,会返回 false,否则返回 true;
除此之外,它也可以用于获取指向原始对象的 std::shared_ptr 指针,其 lock() 方法在原始对象未
被释放时,返回一个指向原始对象的 std::shared_ptr 指针,进而访问原始对象的资源,否则返回
nullptr
*/ 简介正则表达式
正则表达式的字符组成
/*
正则表达式
\1. 检查一个串是否包含某种形式的子串;
\2. 将匹配的子串替换;
\3. 从某个串中取出符合条件的子串。
正则表达式是由普通字符(例如 a 到 z)以及特殊字符组成的文字模式。模式描述在搜索文本时要
匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配
*/
/*
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所
有数字、所有标点符号和一些其他符号。
*/
/*
特殊字符
特殊字符是正则表达式里有特殊含义的字符,也是正则表达式的核心匹配语法。参见下表:
*/

/*
限定符
限定符用来指定正则表达式的一个给定的组件必须要出现多少次才能满足匹配。见下表:
*/
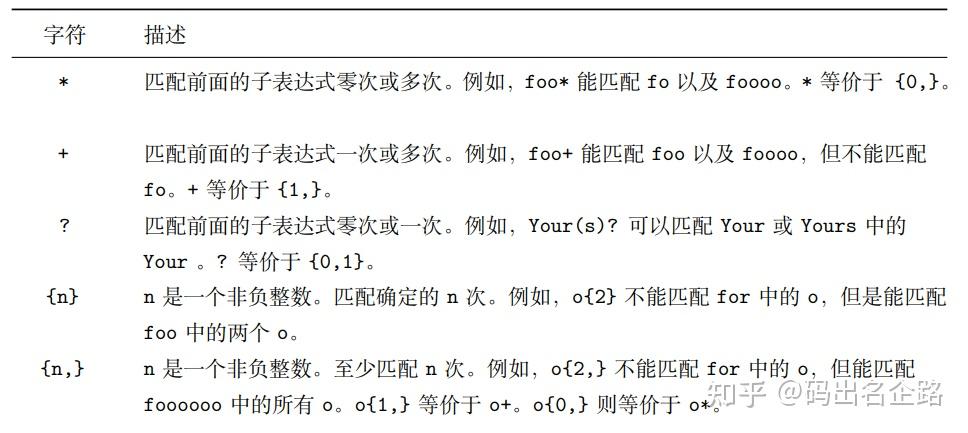

找出纯小写字母组成的文本文件
/*
C++11 提供的正则表达式库操作 std::string 对象,模式 std::regex (本质是 std::basic_regex)
进行初始化,通过 std::regex_match 进行匹配,从而产生 std::smatch(本质是 std::match_results
对象)。
• [a-z]+.txt: 在这个正则表达式中, [a-z] 表示匹配一个小写字母, + 可以使前面的表达式匹配多
次,因此 [a-z]+ 能够匹配一个小写字母组成的字符串。在正则表达式中一个 . 表示匹配任意字
符,而 . 则表示匹配字符 .,最后的 txt 表示严格匹配 txt 则三个字母。因此这个正则表达式的
所要匹配的内容就是由纯小写字母组成的文本文件。
std::regex_match 用于匹配字符串和正则表达式,有很多不同的重载形式。最简单的一个形式就是
传入 std::string 以及一个 std::regex 进行匹配,当匹配成功时,会返回 true,否则返回 false。例
如:
*/ #include <iostream>
#include <string>
#include <regex>
int main() {
std::string fnames[] = {&#34;foo.txt&#34;, &#34;bar.txt&#34;, &#34;test&#34;, &#34;a0.txt&#34;, &#34;AAA.txt&#34;};
// 在 C++ 中 \ 会被作为字符串内的转义符,
// 为使 \. 作为正则表达式传递进去生效,需要对 \ 进行二次转义,从而有 \\.
std::regex txt_regex(&#34;[a-z]+\\.txt&#34;);
for (const auto &fname: fnames)
std::cout << fname << &#34;: &#34; << std::regex_match(fname, txt_regex) << std::endl;
}
/*
另一种常用的形式就是依次传入 std::string/std::smatch/std::regex 三个参数,其中
std::smatch 的本质其实是 std::match_results。故而在标准库的实现中,std::smatch 被定
义 为 了 std::match_resultsstd::string::const_iterator,也 就 是 一 个 子 串 迭 代 器 类 型 的
match_results。使用 std::smatch 可以方便的对匹配的结果进行获取,例如:
*/ std::regex base_regex(&#34;([a-z]+)\\.txt&#34;);
std::smatch base_match;
for(const auto &fname: fnames) {
if (std::regex_match(fname, base_match, base_regex)) {
// std::smatch 的第一个元素匹配整个字符串
// std::smatch 的第二个元素匹配了第一个括号表达式
if (base_match.size() == 2) {
std::string base = base_match[1].str();
std::cout << &#34;sub-match[0]: &#34; << base_match[0].str() << std::endl;
std::cout << fname << &#34; sub-match[1]: &#34; << base << std::endl;
}
}
}
foo.txt: 1
bar.txt: 1
test: 0
a0.txt: 0
AAA.txt: 0
sub-match[0]: foo.txt
foo.txt sub-match[1]: foo
sub-match[0]: bar.txt
bar.txt sub-match[1]: bar 并行与并发
并行基础初中篇
/*
并行基础
std::thread 用于创建一个执行的线程实例,所以它是一切并发编程的基础,使用时需要包含
头文件,它提供了很多基本的线程操作,例如 get_id() 来获取所创建线程的线程 ID,使用
join() 来加入一个线程等等。
*/ #include <iostream>
#include <thread>
int main() {
std::thread t([](){
std::cout << &#34;hello world.&#34; << std::endl;
});
t.join();
return 0;
}
/*
互斥量与临界区
C++11 引入了 mutex 相关的类,其所有相关的函数都放在头文件中
std::mutex 是 C++11 中最基本的 mutex 类,通过实例化 std::mutex 可以创建互斥量,而通过其
成员函数 lock() 可以进行上锁,unlock() 可以进行解锁。但是在实际编写代码的过程中,最好不去直
接调用成员函数,因为调用成员函数就需要在每个临界区的出口处调用 unlock(),当然,还包括异常。
这时候 C++11 还为互斥量提供了一个 RAII 语法的模板类 std::lock_guard。RAII 在不失代码简洁性
的同时,很好的保证了代码的异常安全性
在 RAII 用法下,对于临界区的互斥量的创建只需要在作用域的开始部分
*/ #include <iostream>
#include <mutex>
#include <thread>
int v = 1;
void critical_section(int change_v) {
static std::mutex mtx;
std::lock_guard<std::mutex> lock(mtx);
// 执行竞争操作
v = change_v;
// 离开此作用域后 mtx 会被释放
}
int main() {
std::thread t1(critical_section, 2), t2(critical_section, 3);
t1.join();
t2.join();
std::cout << v << std::endl;
return 0;
}
/*
由于 C++ 保证了所有栈对象在生命周期结束时会被销毁,所以这样的代码也是异常安全的。无论
critical_section() 正常返回、还是在中途抛出异常,都会引发堆栈回退,也就自动调用了 unlock()。
*/
/*
std::unique_lock 则是相对于 std::lock_guard 出现的,std::unique_lock 更加灵活,
std::unique_lock 的对象会以独占所有权(没有其他的 unique_lock 对象同时拥有某个 mutex
对象的所有权)的方式管理 mutex 对象上的上锁和解锁的操作。所以在并发编程中,推荐使用
std::unique_lock。
std::lock_guard 不能显式的调用 lock 和 unlock,而 std::unique_lock 可以在声明后的任意位
置调用,可以缩小锁的作用范围,提供更高的并发度。
如果你用到了条件变量 std::condition_variable::wait 则必须使用 std::unique_lock 作为参
数
*/ #include <iostream>
#include <mutex>
#include <thread>
int v = 1;
void critical_section(int change_v) {
static std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx);
// 执行竞争操作
v = change_v;
std::cout << v << std::endl;
// 将锁进行释放
lock.unlock();
// 在此期间,任何人都可以抢夺 v 的持有权
// 开始另一组竞争操作,再次加锁
lock.lock();
v += 1;
std::cout << v << std::endl;
}
int main() {
std::thread t1(critical_section, 2), t2(critical_section, 3);
t1.join();
t2.join();
return 0;
}
并行增长高中篇
/*
期物(Future)
期物(Future)表现为 std::future,它提供了一个访问异步操作结果的途径,先理解一下在 C++11 之前的多线程行为
试想,如果我们的主线程 A 希望新开辟一个线程 B 去执行某个我们预期的任务,并返回我一个结
果。而这时候,线程 A 可能正在忙其他的事情,无暇顾及 B 的结果,所以我们会很自然的希望能够在某
个特定的时间获得线程 B 的结果。
在 C++11 的 std::future 被引入之前,通常的做法是:创建一个线程 A,在线程 A 里启动任务
B,当准备完毕后发送一个事件,并将结果保存在全局变量中。而主函数线程 A 里正在做其他的事情,当
需要结果的时候,调用一个线程等待函数来获得执行的结果。
而 C++11 提供的 std::future 简化了这个流程,可以用来获取异步任务的结果。自然地,我们很
容易能够想象到把它作为一种简单的线程同步手段,即屏障(barrier)。
*/
/*
使用 std::packaged_task,它可以用来封装任何可以调用的目标,从而用于实现异步的调用
*/ #include <iostream>
#include <future>
#include <thread>
int main() {
// 将一个返回值为 7 的 lambda 表达式封装到 task 中
// std::packaged_task 的模板参数为要封装函数的类型
std::packaged_task<int()> task([](){return 7;});
// 获得 task 的期物
std::future<int> result = task.get_future(); // 在一个线程中执行 task
std::thread(std::move(task)).detach();
std::cout << &#34;waiting...&#34;;
result.wait(); // 在此设置屏障,阻塞到期物的完成
// 输出执行结果
std::cout << &#34;done!&#34; << std:: endl << &#34;future result is &#34;
<< result.get() << std::endl;
return 0;
}
/*
条件变量 std::condition_variable
条件变量 std::condition_variable 是为了解决死锁而生,当互斥操作不够用而引入的。比如,线程
可能需要等待某个条件为真才能继续执行,而一个忙等待循环中可能会导致所有其他线程都无法进入临
界区使得条件为真时,就会发生死锁。所以,condition_variable 实例被创建出现主要就是用于唤醒等
待线程从而避免死锁。std::condition_variable 的 notify_one() 用于唤醒一个线程;notify_all()
则是通知所有线程
*/ #include <queue>
#include <chrono>
#include <mutex>
#include <thread>
#include <iostream>
#include <condition_variable>
int main() {
std::queue<int> produced_nums;
std::mutex mtx;
std::condition_variable cv;
bool notified = false; // 通知信号
// 生产者
auto producer = [&]() {
for (int i = 0; ; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(900));
std::unique_lock<std::mutex> lock(mtx);
std::cout << &#34;producing &#34; << i << std::endl;
produced_nums.push(i);
notified = true;
cv.notify_all(); // 此处也可以使用 notify_one
}
};
// 消费者
auto consumer = [&]() {
while (true) {
std::unique_lock<std::mutex> lock(mtx);
while (!notified) { // 避免虚假唤醒
cv.wait(lock);
}
// 短暂取消锁,使得生产者有机会在消费者消费空前继续生产
lock.unlock();
// 消费者慢于生产者
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
lock.lock();
while (!produced_nums.empty()) {
std::cout << &#34;consuming &#34; << produced_nums.front() << std::endl;
produced_nums.pop();
}
notified = false;
}
};
// 分别在不同的线程中运行
std::thread p(producer);
std::thread cs[2];
for (int i = 0; i < 2; ++i) {
cs = std::thread(consumer);
}
p.join();
for (int i = 0; i < 2; ++i) {
cs.join();
}
return 0;
}
/*
值得一提的是,在生产者中我们虽然可以使用 notify_one(),但实际上并不建议在此处使用,因为
在多消费者的情况下,我们的消费者实现中简单放弃了锁的持有,这使得可能让其他消费者争夺此锁,从
而更好的利用多个消费者之间的并发。话虽如此,但实际上因为 std::mutex 的排他性,我们根本无法
期待多个消费者能真正意义上的并行消费队列的中生产的内容,我们仍需要粒度更细的手段。
*/ 原子操作
/*
原子操作
std::mutex 可以解决上面出现的并发读写的问题,但互斥锁是操作系统级的功能,这是因为一个互
斥锁的实现通常包含两条基本原理:
\1. 提供线程间自动的状态转换,即『锁住』这个状态
\2. 保障在互斥锁操作期间,所操作变量的内存与临界区外进行隔离
这是一组非常强的同步条件,换句话说当最终编译为 CPU 指令时会表现为非常多的指令(我们之
后再来看如何实现一个简单的互斥锁)。这对于一个仅需原子级操作(没有中间态)的变量,似乎太苛刻
了。
*/
/*
关于同步条件的研究有着非常久远的历史,我们在这里不进行赘述。读者应该明白,现代 CPU 体系
结构提供了 CPU 指令级的原子操作,因此在 C++11 中多线程下共享变量的读写这一问题上,还引入了
std::atomic 模板,使得我们实例化一个原子类型,将一个原子类型读写操作从一组指令,最小化到单
个 CPU 指令。例如:
*/ std::atomic<int> counter;
/*
并为整数或浮点数的原子类型提供了基本的数值成员函数,举例来说,包括 fetch_add, fetch_sub
等,同时通过重载方便的提供了对应的 +,- 版本。
*/ #include <atomic>
#include <thread>
#include <iostream>
std::atomic<int> count = {0};
int main() {
std::thread t1([](){
count.fetch_add(1);
});
std::thread t2([](){
count++; // 等价于 fetch_add
count += 1; // 等价于 fetch_add
});
t1.join();
t2.join();
std::cout << count << std::endl;
return 0;
}
/*
当然,并非所有的类型都能提供原子操作,这是因为原子操作的可行性取决于具体的 CPU 架构,
以及所实例化的类型结构是否能够满足该 CPU 架构对内存对齐条件的要求,因而我们总是可以通过
std::atomic::is_lock_free 来检查该原子类型是否需支持原子操作,例如
*/ #include <atomic>
#include <iostream>
struct A {
float x;
int y;
long long z;
};
int main() {
std::atomic<A> a;
std::cout << std::boolalpha << a.is_lock_free() << std::endl;
return 0;
}
内存模型
/*
内存顺序
为了追求极致的性能,实现各种强度要求的一致性,C++11 为原子操作定义了六种不同的内存顺序
std::memory_order 的选项,表达了四种多线程间的同步模型:
*/
/*
\1. 宽松模型:在此模型下,单个线程内的原子操作都是顺序执行的,不允许指令重排,但不同线程间
原子操作的顺序是任意的。类型通过 std::memory_order_relaxed 指定。我们来看一个例子:
*/ std::atomic<int> counter = {0};
std::vector<std::thread> vt;
for (int i = 0; i < 100; ++i) {
vt.emplace_back([&](){
counter.fetch_add(1, std::memory_order_relaxed);
});
}
for (auto& t : vt) {
t.join();
}
std::cout << &#34;current counter:&#34; << counter << std::endl;
/*
\2. 释放/消费模型:在此模型中,我们开始限制进程间的操作顺序,如果某个线程需要修改某个值,但
另一个线程会对该值的某次操作产生依赖,即后者依赖前者。具体而言,线程 A 完成了三次对 x 的
写操作,线程 B 仅依赖其中第三次 x 的写操作,与 x 的前两次写行为无关,则当 A 主动 x.release()
时候(即使用 std::memory_order_release),选项 std::memory_order_consume 能够确保 B 在
调用 x.load() 时候观察到 A 中第三次对 x 的写操作。我们来看一个例子:
*/ // 初始化为 nullptr 防止 consumer 线程从野指针进行读取
std::atomic<int*> ptr(nullptr);
int v;
std::thread producer([&]() {
int* p = new int(42);
v = 1024;
ptr.store(p, std::memory_order_release);
});
std::thread consumer([&]() {
int* p;
while(!(p = ptr.load(std::memory_order_consume)));
std::cout << &#34;p: &#34; << *p << std::endl;
std::cout << &#34;v: &#34; << v << std::endl;
});
producer.join();
consumer.join();
/*
\3. 释放/获取模型:在此模型下,我们可以进一步加紧对不同线程间原子操作的顺序的限制,在释放
std::memory_order_release 和获取 std::memory_order_acquire 之间规定时序,即发生在释放
(release)操作之前的所有写操作,对其他线程的任何获取(acquire)操作都是可见的,亦即发生顺
序(happens-before)。
可以看到,std::memory_order_release 确保了它之前的写操作不会发生在释放操作之后,是一
个向后的屏障(backward),而 std::memory_order_acquire 确保了它之前的写行为不会发生在
该获取操作之后,是一个向前的屏障(forward)。对于选项 std::memory_order_acq_rel 而言,则
结合了这两者的特点,唯一确定了一个内存屏障,使得当前线程对内存的读写不会被重排并越过此
操作的前后:
我们来看一个例子:
*/ std::vector<int> v;
std::atomic<int> flag = {0};
std::thread release([&]() {
v.push_back(42);
flag.store(1, std::memory_order_release);
});
std::thread acqrel([&]() {
int expected = 1; // must before compare_exchange_strong
while(!flag.compare_exchange_strong(expected, 2, std::memory_order_acq_rel))
expected = 1; // must after compare_exchange_strong
// flag has changed to 2
});
std::thread acquire([&]() {
while(flag.load(std::memory_order_acquire) < 2);
std::cout << v.at(0) << std::endl; // must be 42
});
release.join();
acqrel.join();
acquire.join();
/*
\4. 顺序一致模型:在此模型下,原子操作满足顺序一致性,进而可能对性能产生损耗。可显式的通过
std::memory_order_seq_cst 进行指定。最后来看一个例子:
*/ std::atomic<int> counter = {0};
std::vector<std::thread> vt;
for (int i = 0; i < 100; ++i) {
vt.emplace_back([&](){
counter.fetch_add(1, std::memory_order_seq_cst);
});
}
for (auto& t : vt) {
t.join();
}
std::cout << &#34;current counter:&#34; << counter << std::endl;
其余关键点
noexcept的修饰和操作
/*
noexcept 的修饰和操作
C++11 将异常的声明简化为以下两种情况:
\1. 函数可能抛出任何异常
\2. 函数不能抛出任何异常
并使用 noexcept 对这两种行为进行限制,例如:
*/ void may_throw(); // 可能抛出异常
void no_throw() noexcept; // 不可能抛出异常
/*
使用 noexcept 修饰过的函数如果抛出异常,编译器会使用 std::terminate() 来立即终止程序运行。
noexcept 还能够做操作符,用于操作一个表达式,当表达式无异常时,返回 true,否则返回 false。
*/ #include <iostream>
void may_throw() {
throw true;
}
auto non_block_throw = []{
may_throw();
};
void no_throw() noexcept {
return;
}
auto block_throw = []() noexcept {
no_throw();
};
int main()
{
std::cout << std::boolalpha
<< &#34;may_throw() noexcept? &#34; << noexcept(may_throw()) << std::endl
<< &#34;no_throw() noexcept? &#34; << noexcept(no_throw()) << std::endl
<< &#34;lmay_throw() noexcept? &#34; << noexcept(non_block_throw()) << std::endl
<< &#34;lno_throw() noexcept? &#34; << noexcept(block_throw()) << std::endl;
return 0;
}
/*
noexcept 修饰完一个函数之后能够起到封锁异常扩散的功效,如果内部产生异常,外部也不会触发。
例如:
*/ try {
may_throw();
} catch (...) {
std::cout << &#34; 捕获异常, 来自 may_throw()&#34; << std::endl;
}
try {
non_block_throw();
} catch (...) {
std::cout << &#34; 捕获异常, 来自 non_block_throw()&#34; << std::endl;
}
try {
block_throw();
} catch (...) {
std::cout << &#34; 捕获异常, 来自 block_throw()&#34; << std::endl;
}
最终输出为:
捕获异常, 来自 may_throw()
捕获异常, 来自 non_block_throw() 内存对齐alignas
/*
内存对齐
C++ 11 引入了两个新的关键字 alignof 和 alignas 来支持对内存对齐进行控制。alignof 关键字
能够获得一个与平台相关的 std::size_t 类型的值,用于查询该平台的对齐方式。当然我们有时候并不
满足于此,甚至希望自定定义结构的对齐方式,同样,C++ 11 还引入了 alignas 来重新修饰某个结构
的对齐方式。我们来看两个例子:
*/ #include <iostream>
struct Storage {
char a;
int b;
double c;
long long d;
};
struct alignas(std::max_align_t) AlignasStorage {
char a;
int b;
double c;
long long d;
};
int main() {
std::cout << alignof(Storage) << std::endl;
std::cout << alignof(AlignasStorage) << std::endl;
return 0;
}
/*
其中 std::max_align_t 要求每个标量类型的对齐方式严格一样,因此它几乎是最大标量没有差异,
进而大部分平台上得到的结果为 long double,因此我们这里得到的 AlignasStorage 的对齐要求是 8
或 16。
*/ <hr/>相关文章:
万字长文【C++】高质量编程指南
万字长文【C++】函数式编程【上】
https://www.zhihu.com/video/1588636621209022464
认识一个人就是开了一扇窗户,就能看到不一样的东西,听到不一样的声音,能让你思考,觉悟,这已经够了。其他还有很多,比如机会,帮助,我不确定。这个在一般人看来可能不重要,但是我知道这个很重要。 我是小阳哥,一个喜欢码字和交流的程序员:告别2021,再回首这一年 ,希望用身边的人,身边的事,让我们少走一些弯路,一点点就好。欢迎扫码交流,多一点沟通,多一个朋友~ |
|


 发表于 2023-1-7 21:58:22
发表于 2023-1-7 21:58:22