|
|
本文写于 2021 年 2 月 9 日. 重写于 5 月 16 日 (这半年来我对 module 的理解进一步加深). 12 月 27 日加入了倒数第二节.
modules 试图解决的痛点
能最大的痛点就是编译慢, 头文件的重复替换, 比如你有多个翻译单元, 每一个都调用了 iostream, 就得都处理一遍. 预处理完的源文件就会立刻膨胀. 真的会很慢.
有了 modules 以后, 我们可以模块化的处理. 已经编译好的 modules 直接变成编译器的中间表示进行保存, 需要什么就取出什么, 这就非常地快速了.
比如你只是用了 cout 的函数, 那么编译器下次就不需要处理几万行, 直接找 cout 相关函数用就行了. 太快了, 太快了! Google 使用 modules 的经验表明, 编译速度飞快.
除此之外, 封装什么的也可以做得很好, 可以控制 modules 的哪些部分可以暴露于外界. 这些也是非常不错的地方.
可以看倒数第二节, C++ 之父介绍了 modules 的发展进程.
modules 的痛点
modules 目前没有构建系统.
modules 的构建必须是按照依赖关系进行构建的. 也就是说子模块必须提前构建, 这就对传统的并行构建系统提出了挑战. 手工写编译命令是权宜之计, 想用上像 cmake 这样的构建工具, 得等到未来才有了.
关于 modules 的技术细节
1. 为什么会变快?
modules 编译出来会有两个部分:
- 编译器缓存, 基本上代表了全部源代码信息. 编译器已经处理好了源代码, 并且把内部缓存留了下来. 下次读取的时候会更快. 主流三大编译器都有 lazy loading 的功能, 可以只取出需要的部分. 这不就快了?
- 编译出来的 object, 这个 object 只有链接的时候需要了, 不需要特别处理, 也不需要再次编译.
所以啊, 就是有了这个缓存, 才会让它更快. 各个编译器不能通用哦. 而且编译选项不同的时候, 内部的表示不一样, 所以也不能通用.
这个缓存文件:
- 在 Clang 那里, 叫 BMI, 后缀名是 .pcm.
- 在 GCC 那里, 叫 CMI, 后缀名是 .gcm.
- 在 MSVC 那里, 叫 IFC, 后缀名是 .ifc.
对于这个缓存文件, 这三家编译器还使用了 lazy loading 的技术. 也就是说需要哪些定义/声明就加载哪些. 编译器的这种 lazy loading 进一步提升了速度.
2. 如何做到接口隔离?
C++ 标准中新提出了一种 module linkage, 意味着只有同一个 module 内部可见. 之前的 C++ 标准中只有 external linkage (全局可见) 和 internal linkage (同一个翻译单元可见).
为了实现这个 module linkage 功能, GCC 和 Clang 共同使用了一种新的 name mangling 技术. 具体地说, 如果
- modules 对外 export 的名称, 按照平时方式进行 name mangling.
- 对于 modules 内部, 需要 module linkage 的名称, 使用一种全新的 _ZW 开头的 name mangling.
这两个技术一结合, 编译器就能分辨出啥是好的, 啥是坏的了. 编译器编译的时候, 就知道 _ZW 开头的函数只能同一个 module 内互相调用, 就在编译的时候进行隔离了.
这样做有一个巨大利好, 不用改动链接器了. 在链接器的角度看来 module linkage 和 external linkage 是一回事.
但 MSVC 希望能更进一步. 比如在 A, B 两个 module 同时 export 一个函数的时候, MSVC 希望能够区分出这俩函数是不同的. 为此, 他们既改了编译器, 又改了链接器. 具体可以看看下面这篇博客.
为了历史兼容性, 我们希望在 module 文件里面仍然插入一些 external linkage 的函数. 为此我们引入了 global module fragment 的语义, 下面的章节有具体介绍.
3. 可以给客户分发缓存文件和 object 文件, 但不分发源代码吗?
应该是不行的. 编译器的内部表示受到多种原因影响, 比如不同的标准, 比如有没有启用异常功能, 有没有启用 PIC, 有没有启用 RTTI. 而且还和编译器版本相关. 还和平台相关 (比如 sizeof(int) 的大小)
太多因素了影响了. 而且你看三个编译器的实现都不一样. 除非你能保证你客户的环境和你一模一样, 你只有靠源代码进行分发, 或者传统实践中的 "头文件+object file" 的方案进行分发.
4. modules 最重要的功能是什么
个人观点:
我原来感觉, 不引入多余的符号会是一个很大的亮点, 但是 modules 需要使用源代码进行分发. 所以这个 modules 做的隔离只是防止意外引入重名的符号罢了, 因为如果人家硬要链接上, 你也拦不住他.
但如果只是防意外引入的话, 以前我们也有 static 函数 (internal linkage) 可以做到, 或者我们可以使用 namespace 进行包装, 效果都是很好的.
现在的我感觉, modules 的 lazy loading 大大加快了编译速度, 这一点是远好于传统方式的. modules 可以用什么就取什么, 对于高频出现的文件 (比如标准库) 会很好. 这样, 你不用为你不使用的函数花编译时间.
所以, 以前的我感觉 modules 带来的隔离是最棒的 (也是最初设计它的原因之一), 但现在的我认为: 只取出代码中我们需要的部分, 大大提升编译速度才是 modules 最大的利好.
我认为正是基于这个考虑, 三个编译器选择了最利于编译速度的 modules 实现方案, 也没有把缓存文件设计成适合分发的样子.
编译器支持状态
Clang
目前 Clang 12 已经可以用上对 modules 的支持. 比如下面这个示例 1
// A.cc
export module A;
export int foo();
// A.cpp
module;
#include <iostream>
module A;
int foo()
{
std::cout << 1;
return 1;
}
// main.cpp
import A;
int main(){
foo();
}
A.cc 这里是 module interface 规定了接口. A.cpp 是 module implementation, 给出了实现.
编译的时候需要先把这个 module interface unit A.cc 变成 BMI 文件, 比如这样
clang++ -std=c++20 -c A.cc -Xclang -emit-module-interface -o A.pcm然后利用这个 A.pcm 再编译链接剩下三个翻译单元即可.
clang++ -std=c++20 -fimplicit-modules -fimplicit-module-maps -fprebuilt-module-path=. A.cc A.cpp main.cpp -o main这里 A.pcm 是隐式被使用的. Clang 对文件名有一些隐式的要求, 建议使用之前阅读一下官方文档.[1]
实际上, A.cc 之中的所有的源代码信息已经完全清楚地存在于 A.pcm 之中了. Clang 更详细的用法可以查看这篇文章, 但有点老了.
GCC
GCC 11 引入了对 modules 的支持.
用 modules 要记得严格遵守 modules 之间的依赖关系, 被依赖的一定要放在前面编译.
GCC 的设计比较自动化, 他会自动生成缓存. 比如你在 build/ 目录下运行 g++ 进行编译, 那他会把缓存文件放在 build/gcm.cache 目录下. 之后的编译过程中, 他也会在这个地方进行查找.
对于上面的示例 1, 需要先编译 A.cc, 因为是 A.cpp 的依赖.
然后 main.cpp 需要 import A, 所以 A.cpp 需要先于 main.cpp编译.
编译 A.cpp 也需要读取 build/gcm.cache/ 下的 A.gcm, 才能编译 main.cpp. 所以我们得这样写代码.
g++ -fmodules-ts -std=c++20 A.cc A.cpp main.cpp -o main按照设计, GCC 会按照你给定的文件顺序进行编译, 而你顺序错了必定编译失败.
我们来看下面的例子, 修改自 C++20 的标准文件. 称为示例 2.
// 1.cc
export module A; // 对外暴露一个叫 A 的 module
export import :Foo; // 对外暴露 A:Foo 这个模块
export int baz(); // 对外暴露 int baz();
// 2.cc
export module A:Foo; // 对外暴露 A:Foo 这个模块
import :Internals; // 引入 A:Internals 这个模块
// 给出函数 int foo() 的实现, 并且对外暴露
export int foo() { return 2 * (bar() + 1); }
// 3.cc
module A:Internals; // 表明我就是 A:Internals 这个模块
int bar(); // 表明本模块里面有一个 int bar() 函数.
// 4.cc
module; // 表明现在我是 global module fragment
#include <iostream>
module A; // 表明现在我是模块 A 的 module implementation unit
import :Internals; // 引入 A:Internals 这个模块
// 给出了 A:Internals 之中 int bar() 的定义 (具有 module linkage)
int bar() { return baz() - 10; }
// 给出了 1.cc 中 int baz() 的定义 (具有 external linkage)
int baz()
{
std::cout << 30;
return 30;
}
// main.cpp
import A;
int main(){
foo();
}
1.cc 是 module A 的 interface unit.
2.cc 是一个 module partition, 叫做 A:Foo, 同时也是 module A 的 interface 一部分.
3.cc 也是一个 module partition, 叫做 A:Internals, 但是不是 module A 的 interface 一部分.
4.cc 是一个 module implementation unit. 给之前这些 interface 提供实现. 但是无法被外部 import.
从上面的代码中, 我们看到 3 被 2 and 4 需要, 1 被 4 需要, 2 被 1 需要, 于是我们的编译顺序就是.
所以必须先编译 3.cc, 然后是 2.cc 必须在 1.cc 之前, 1.cc 必须在 4.cc 之前, 他们都必须在 main.cpp 之前, 所以编译的顺序为
g++ -fmodules-ts -std=c++20 3.cc 2.cc 1.cc 4.cc main.cpp -o main换句话说, 想要生成 A.gcm, 必须先生成 A-Internals.gcm, 再生成 A-Foo.gcm.
你也可以分开编译
g++ -fmodules-ts -std=c++20 -c 3.cc -o 3.o # 生成 A-Internals.gcm
g++ -fmodules-ts -std=c++20 -c 2.cc -o 2.o # 读取 A-Internals.gcm, 生成 A-Foo.gcm
g++ -fmodules-ts -std=c++20 -c 1.cc -o 1.o # 读取 A-Foo.gcm, 生成 A.gcm
g++ -fmodules-ts -std=c++20 -c 4.cc -o 4.o # 读取 A.gcm, A-Internals.gcm, 写入 A.gcm
g++ -fmodules-ts -std=c++20 -c main.cpp -o main.o # 读取 A.gcm
g++ 1.o 2.o 3.o 4.o main.o -o main # 链接阶段就不需要了特殊处理了Clang 目前还不支持 module partition. 为了生成 A.pcm, 你得先生成 A-Internals.pcm 和 A-Foo.pcm. Clang 还没做这种功能.
目前来说, 使用 g++ 编译, 必须使用 -fmodules-ts 参数.
只编译头文件也是可以做到的, 那样也不会有 object file 生成了. 我们可以使用 -fmodule-header 参数.
GCC 做出的设计选择是, 不支持新的拓展名, 只支持原来的 .cc, .cxx, .cpp 等等拓展名. 更多信息可以参考手册.
Global module fragment
在介绍 MSVC 之前, 上面的 4.cc 有一个有点奇怪的地方需要介绍.
module;
#include <iostream>
module A;
我们希望 #include <iostream> 里面的东西的 linkage/name mangling 都是和非 module 部分一样的, 千万不能经过 module 的特殊处理.
所以我们搞出了个 global module fragment 的语法. 用 module; 代表 global module. 这样到 module A; 之前的东西就和以前一样了, 非常好用.
MSVC
对于示例 2, MSVC 也必须按照顺序编译, 而且需要指定清楚每个文件是哪一种类型的文档.
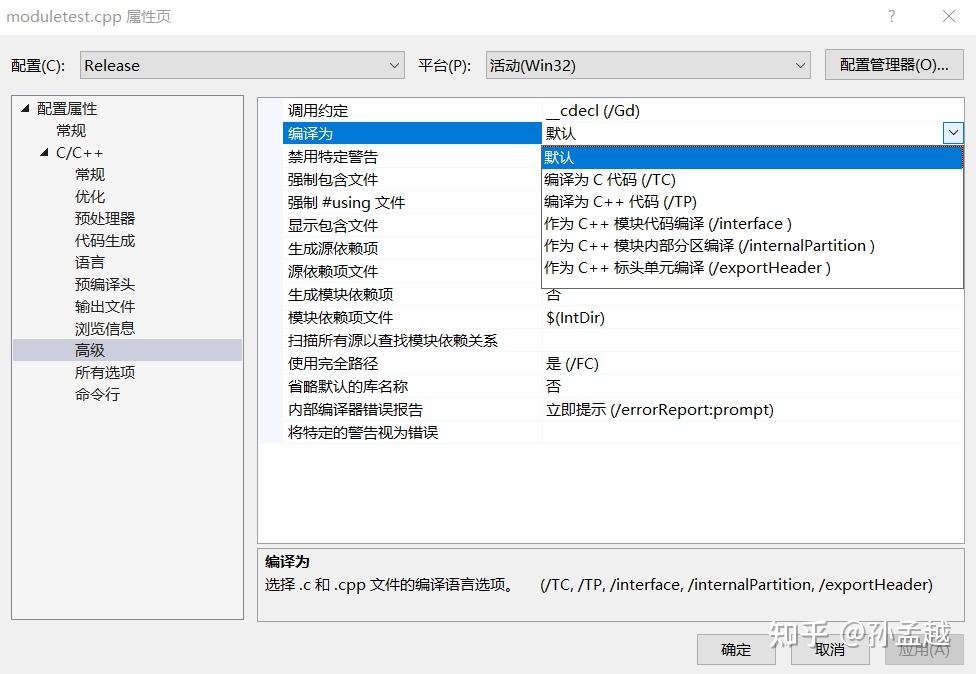
然后也是通过这样的方式进行编译.

来自 @Berrysoft
MSVC 还有个好的地方, 它已经提供了编译好的标准库头文件 (module 形式的). 在 GCC 上只能自行手工编译一份,
总结
整体判断
新的大型项目可以用, 速度会很快, 但还不太成熟. 老项目要移植过来可能会很麻烦, 要改构建系统, 并且要改掉很多代码.
目前看来, 最缺乏的是构建系统的支持. 这个搞好了, 前途还是不错的啊.
使用的一些问题
- 编译变麻烦了. 未来有希望改善.
- 缓存文件在不同的编译环境下无法复用.
- 代码格式化工具不能正确格式化. 当然未来会改善.
- 对于新手而言, 可能难以理解. 比如 module 可以向外返回一个内部结构. 像
export module A;
class Secret
{
public:
Secret(int a) : _a(a) {}
int _a;
};
export Secret getSecret()
{
return Secret{1};
}
那么这个 Secret 类对于外部来说就是一个匿名类型. 使用起来需要一些技巧.
import A;
int main()
{
auto sec1 = getSecret(); // 移动构造, 可行
// Secret sec2{1}; // 会编译失败, 找不到 Secret 这个类
using secretType = decltype(getSecret()); // 先获取类型
secretType sec3{1}; // 再进行使用
// 可以找到 _ZW1AEN6SecretC2Ei 这个构造函数
}
Bjarne Stroustrup 的介绍
Bjarne 是 C++ 之父, 下面这段是他对 modules 的介绍. (下面链接为中译版, 中译版协议不明, 原文 CC4.0 协议共享.)
在委员会的鼓励下(并得到了我的支持), David Vandevoorde 在二十一世纪产出了一系列模块设计 [Vandevoorde 2007, 2012], 但进展非常缓慢. 委员会的首要任务是完成 C++0x, 而不是在模块上取得进展. David 主要靠自己奋斗, 此外基本就只得到一些精神支持了. 在 2012 年, Doug Gregor 从苹果提交了一个完全不同的模块系统设计 [Gregor 2012]. 在 Clang 编译器基础设施中, 这一设计已经针对 C 和 Objective C 实现 [Clang 2014]. 它依赖于语言之外的文件映射指令, 而不是 C++ 语言里的构造. 该设计还强调了不需要对头文件进行修改.
在 2014 年, 由 Gabriel Dos Reis 领导的微软团队成员根据他们的工作提出了一项提案 [Dos Reis et al. 2014]. 从精神层面上讲, 它更接近于 David Vandevoorde 的设计, 而不是 Clang/苹果的提议, 并且很大程度上是基于 Gabriel Dos Reis 和 Bjarne Stroustrup 在得州农工大学所做的关于 C++ 源代码的最优图表示的研究 (于 2007 年发布并开源 [Dos Reis 2009; Dos Reis and Stroustrup 2009, 2011]).
这为在模块方面取得重大进展奠定了基, 但同时也为苹果/谷歌/Clang 方式(和实现)及微软方式(和实现)之间的一系列冲突埋下了伏笔.
为此一个模块研究小组被创建. 3 年后, 该小组主要基于 Gabriel Dos Reis 的设计 [Dos Reis 2018] 制订了 TS.
在 2017 年, 然后在 2018 年又发生了一次, 将 Modules TS 纳入 C++20 标准的建议受阻, 就因为谷歌提出了不同的设计 [Smith 2018a, b]. 争论的主要焦点是在 Gabriel Dos Reis 的设计中宏无法导出. 谷歌的人认为这是一个致命缺陷, 而 Gabriel Dos Reis (和我)认为这对于模块化至关重要 [Stroustrup 2018c]:
模块化是什么意思? 顺序独立性: import X; import Y; 应该与 import Y; import X; 相同. 换句话说, 任何东西都不能隐式地从一个模块&#34;泄漏&#34;到另一个模块. 这是 #include 文件的一个关键问题. #include 中的任何内容都会影响所有后续的 #include .
我认为顺序独立性是“代码卫生”和性能的关键. 通过坚持这种做法, Gabriel Dos Reis 的模块实现也比使用头文件在编译时间上得到了 10 倍量级的性能提升——即使在旧式编译中使用了预编译头文件也是如此. 迎合传统头文件和宏的常规使用的方式很难做到这一点, 因为需要将模块单元保持为允许宏替换(“标记汤”)的形式, 而不是 C++ 逻辑实体的图.
经过精心设计的一系列折中, 我们最终达成了一个被广泛接受的解决方案. 这一多年努力的关键人物有 Richard Smith(谷歌)和 Gabriel Dos Reis(微软), 以及 GCC 的模块实现者 Nathan Sidwell(Facebook), 还有其他贡献者 [Dos Reis and Smith 2018a, b; Smith and Dos Reis 2018]. 从 2018 年年中开始, 大多数讨论都集中在需要精确规范的技术细节上, 以确保实现之间的可移植性 [Sidwell 2018; Sidwell and Herring 2019].
关键思想:
* export 指令使实体可以被 import 到另一个模块中.
* import 指令使从另一个模块 export 出来的的实体能够被使用.
* import 的实体不会被隐式地再 export 出去.
* import 不会将实体添加到上下文中;它只会使实体能被使用 (因此, 未使用的 import 基本上是无开销的).
最后两点不同于 #include , 并且它们对于模块化和编译期性能至关重要.
这个简单的例子纯粹是基于模块的;这是理想情况. 但是, 已经部署的 C++ 代码也许有五千亿行, 而头文件和 #include 并不会在一夜之间被淘汰, 可能再过几十年都不会. 好几个人和组织指出, 我们需要一些过渡机制, 使得头文件和模块可以在程序中共存, 并让库为不同代码成熟度的用户同时提供头文件和模块的接口. 请记住, 在任何给定的时刻, 都有用户依赖 10 年前的编译器.
考虑在无法修改 iostream 和 container 头文件的约束下实现 map_printer:
export module map_printer; // 定义一个模块
import <iostream> // 使用 iostream 头文件
import &#34;containers&#34; // 使用我自己的 containers 头文件
using namespace std;
export // 让 print_map() 对 map_printer 的用户可用
template<Sequence S>
requires Printable<Key_type<S>> && Printable<Value_type<S>>
void print_map(const S& m){
for (const auto& [key,val] : m) // 分离“键”和“值”
cout << key << &#34; -> &#34; << val << &#39;\n&#39;;
}
指名某个头文件的 import 指令工作起来几乎与 #include 完全一样——宏、实现细节以及递归地 #include 到的头文件. 但是, 编译器确保 import 导入的“旧头文件”不具有相互依赖关系. 也就是说, 头文件的 import 是顺序无关的, 因此提供了部分、但并非全部的模块化的好处. 例如, 像 import <iostream> 这样导入单个头文件, 程序员就需要去决定该导入哪些头文件, 也因为与文件系统进行不必要的多次交互而降低编译速度, 还限制了来自不同头文件的标准库组件的预编译. 我个人希望看到颗粒度更粗的模块, 例如, 标准的 import std 表示让整个标准库都可用. 然而, 更有雄心的标准库重构 [Clow et al. 2018] 必须要推迟到 C++23 了.
像 import 头文件这样的功能是谷歌/Clang 提案的重要组成部分. 这样做的一个原因是有些库的主要接口就是一堆宏.
在设计/实现/标准化工作的后期, 反对意见集中在模块对构建系统的可能影响上. 当前 C 和 C++ 的构建系统对处理头文件已经做了大量优化. 数十年的工作已经花费在优化这一点上, 一些与传统构建系统相关的人表示怀疑, 是否可以不经重大重新设计就顺利引入模块, 而使用模块的构建会不允许并行编译(因为当前要导入的模块依赖于某个先前已导入模块的编译结果)[Bindels et al. 2018; Lopes et al. 2019; Rivera 2019a]. 幸运的是, 早期印象过于悲观了 [Rivera 2019b], build2 系统已经为处理模块进行了修改, 微软和谷歌报告说他们的构建系统在处理模块方面显示出良好的效果, 最后 Nathan Sidwell 报告说他在仅两周的业余时间里修改了 GNU 的构建系统来处理模块 [Sidwell 2019]. 这些经验的最终演示及关键模块实现者(Gabriel Dos Reis、Nathan Sidwell、Richard Smith 和 David Vandevoorde)的联署论文打动了几乎所有反对者 [Dos Reis et al. 2019].
在 2019 年 2 月, 模块得到了 46 比 6 的多数票, 进入了 C++20;投票者中包含了所有的实现者 [Smith 2019]. 在那时, 主要的 C++ 实现已经接近 C++20 标准. 模块有望成为 C++20 提供的最重要的单项改进.
Nathan 的观点
Nathan Sidwell 是 GCC module 实现者. 他在上面这篇文章中介绍了他的看法. 对于我上面没提到的部分, 我摘录了一些作为补充.
CMI 文件:
标准没有规定过 module 如何实施, 也没有在 object 文件上做规定. 不同的编译器采用了不同的方案. 举例而言, Clang 的 CMI 文件中包含了源代码的所有信息, 并且是编译过程中的另一个阶段. GCC 生成的 CMI 之中只包含必需的信息. CMI 是编译器中间表示的一个序列化. 新关键词:
export 是已经被弃用但是仍然保留的关键词. import 和 module 是新的关键词.
为了不影响, 我们把标准设计为仅在特定情况下才会触发关键词, 会尽可能地不影响老的代码. 注: 比如一个叫 import 的类仍然是有效的. 除了一些极端情况, 比如
template<typename> class import {};
import<int> f(); // ill-formed; previously well-formed
其他编译器实现:
MSVC: 基本上做完了. 模块部分的主要设计者是微软的 Gabriel dos Reis. 我认为这是最完整的实现了.
Clang: Clang 前段提供了一个 implicit module 的方案. 那里的经验用作了 header units 的设计. 谷歌的 Richard Smith 领导了设计.
GCC: 我领导了设计. 目前是开发分支, 还没有发布. 我尽量确保设计不退化, 并且尽快 merge 进主分支.
这三个实现都有 lazy loading 的机制. 只有在用户代码提到名称时, 才会导入相关的部分, 所以会比传统的 include 头文件方式更快.
我认为 MSVC 完成度最高, 其次是我们, 最后是 Clang. 注: 文章写于 2020 年 10 月.
会如何影响 build system
build system 需要重新设计. 最难的是重零构建的时候, 因为那时候还不知道模块的依赖关系.
预扫描:
预扫描阶段将处理所有源文件. 如果人们对高估依赖关系无所谓, 那么这种扫描相对简单. 模块声明和导入声明必须自己出现在单独的行上, 而宏不会掩盖模块, 导出或导入关键字. 它们非常类似于没有前导#的预处理器指令. 如果忽略所有其他内容 (包括 #if 行), 则将获得最大的依赖集. 为了进一步简化, 模块的所有导入必须在模块声明之后立即显示——您以后不能将其放置在模块中间. 为了获得更准确的依赖关系, 必须跟踪 #if 和宏. 计算出此信息后, 构建可以以正确的顺序启动编译, 并告知所需的每个 CMI 的位置。
动态依赖图:
编译器可以跟 build system 配合. 遇到新的 module 的时候, build system 指导编译器去编译新的模块. build system 维持一个动态的依赖图. 相对地, 预扫描就会得到一个静态的依赖图.
所以我们在大型项目上的预期是, 第一次编译会比传统方案更慢, 但是之后的增量编译都会非常快. Google 用上了 Clang 的 implicit module 的经验表明, 这是一个巨大的成功. 注: Clang 的 implicit module 是 Google 的 Richard Smith 领导设计的, 所以会拿来做做实验.
参考
- ^https://clang.llvm.org/docs/Modules.html#command-line-parameters
|
|


 发表于 2022-11-28 14:55:30
发表于 2022-11-28 14:55:30