|
|
贝叶斯神经网络,简单来说可以理解为通过为神经网络的权重引入不确定性进行正则化(regularization),也相当于集成(ensemble)某权重分布上的无穷多组神经网络进行预测。
本文主要基于 Charles et al. 2015[1]。
FBI WARNING:本文讨论的是贝叶斯神经网络,而非贝叶斯网络。
FBI WARNING:鉴于近期知乎上一些睿智发言,本文将所有术语翻译成了中文,请谨慎食用。 题图来源
0. 神经网络的概率模型
众所周知,一个神经网络模型可以视为一个条件分布模型 P(\mathbf{y}|\mathbf{x},\mathbf{w}) :输入 \mathbf{x} ,输出预测值 \mathbf{y} 的分布, \mathbf{w} 为神经网络中的权重。在分类问题中这个分布对应各类的概率,在回归问题中一般认为是(标准差固定的)高斯(Gaussian)分布并取均值作为预测结果。相应地,神经网络的学习可以视作是一个最大似然估计(Maximum Likelihood Estimation, MLE):
\begin{align} \mathbf{w}^\mathrm{MLE}&=\arg\max_\mathbf{w}\log P(\mathcal{D}|\mathbf{w})\\ &=\arg\max_\mathbf{w}\sum_i\log P(\mathbf{y}_i|\mathbf{x}_i,\mathbf{w}) \end{align}
其中 \mathcal{D} 对应我们用来训练的数据集(dataset)。回归问题中我们代入高斯分布就可以得到平均平方误差(Mean Squared Error, MSE),分类问题则代入逻辑函数(logistic)可以推出交叉熵(cross-entropy)。求神经网络的极小值点一般使用梯度下降,基于反向传播(back-propagation, BP)实现。
MLE 中不对 \mathbf{w} 的先验概率作假设,也就是认为 \mathbf{w} 取什么值的机会都均等。如果为 \mathbf{w} 引入先验,那就变成了最大后验估计(Maximum Posteriori, MAP):
\begin{align} \mathbf{w}^\mathrm{MAP}&=\arg\max_\mathbf{w}\log P(\mathbf{w}|\mathcal{D})\\ &=\arg\max_\mathbf{w}\log P(\mathcal{D}|\mathbf{w}) + \log P(\mathbf{w}) \end{align}
代入高斯分布可以推出 L2 正则化(倾向于取小值),代入拉普拉斯分布(Laplace)可以推出 L1 正则化(倾向于取 0 使权重稀疏)。
1. 贝叶斯起来了!
贝叶斯估计(bayesian estimation)同样引入先验假设,与 MAP 的区别是贝叶斯估计求出 \mathbf{w} 的后验分布 P(\mathbf{w}|\mathcal{D}) ,而不限于 argmax 值,这样我们就可以为神经网络的预测引入不确定性。由于我们求得的是分布,基于 \mathbf{w} 由输入 \hat{\mathbf{x}} 预测 \hat{\mathbf{y}} 的概率模型就变成了:
P(\hat{\mathbf{y}}|\hat{\mathbf{x}})=\mathbb{E}_{P(\mathbf{w}|\mathcal{D})}[P(\hat{\mathbf{y}}|\hat{\mathbf{x}},\mathbf{w})]
这样我们每次预测 \hat{\mathbf{y}} 都得求个期望,问题是这个期望我们并不可能真的算出来,因为这就相当于要计算在 P(\mathbf{w}|\mathcal{D}) 上的所有可能的神经网络的预测值。
另一方面,求后验分布 P(\mathbf{w}|\mathcal{D}) 也是件麻烦的事情。众所周知,根据贝叶斯理论,求 P(\mathbf{w}|\mathcal{D}) 需要通过:
\begin{align} P(\mathbf{w}|\mathcal{D})= \frac{P(\mathbf{w},\mathcal{D})}{P(\mathcal{D})} =\frac{P(\mathcal{D}|\mathbf{w})P(\mathbf{w})}{P(\mathcal{D})} \end{align}
这东西也是难解(intractable)的。
所以,为了在神经网络中引入贝叶斯估计,需要找到方法近似这些东西,并且最好能转化成为求解优化(optimization)问题的形式,这样比较符合我们炼丹师的追求。
2. 变分估计
利用变分(variational)的方法,我们可以使用一个由一组参数 \theta 控制的分布 q(\mathbf{w}|\theta) 去逼近真正的后验 P(\mathbf{w}|\mathcal{D}) ,比如用高斯来近似的话 \theta 就是 (\mu,\sigma),这样就把求后验分布的问题转化成了求最好的 \theta 这样的优化问题。这个过程可以通过最小化两个分布的 KL 散度(Kullback-Leibler divergence)实现:
\begin{align} \theta^*&=\arg\min_\theta D_\mathrm{KL}[q(\mathbf{w}|\theta)||P(\mathbf{w}|\mathcal{D})]\\ &=\arg\min_\theta \int q(\mathbf{w}|\theta)\log \frac{q(\mathbf{w}|\theta)}{P(\mathbf{w})P(\mathcal{D}|\mathbf{w})} d\mathbf{w}\\ &=\arg\min_\theta D_\mathrm{KL}[q(\mathbf{w}|\theta)||P(\mathbf{w})] - \mathbb{E}_{q(\mathbf{w}|\theta)}[\log P(\mathcal{D}|\mathbf{w})] \end{align}
这样看起来比前式好多了。写成目标函数(objective function)的形式就是:
\mathcal{F}(\mathcal{D},\theta)=D_\mathrm{KL}[q(\mathbf{w}|\theta)||P(\mathbf{w})]-\mathbb{E}_{q(\mathbf{w}|\theta)}[\log P(\mathcal{D}|\mathbf{w})] (1)
这个其实仍然没法算出来,但是至少长得更像能算出来的东西。第一项就是我们的变分后验与先验的 KL 散度;第二项的取值依赖了训练数据。[1]把第一项叫作复杂性代价(complexity cost),描述的是权重和先验的契合程度;把第二项叫作似然代价(likelihood cost),描述对样本的拟合程度。优化这个目标函数可以看作是炼丹师们最熟悉的正则化,在两种代价中取平衡。
对于 P(\mathbf{w}) 的形式,[1]给出了一个混合尺度高斯先验(scale mixture gaussian prior):
P(\mathbf{w})=\prod_{j} \pi \mathcal{N}\left(\mathbf{w}_{j} | 0, \sigma_{1}^{2}\right)+(1-\pi) \mathcal{N}\left(\mathbf{w}_{j} | 0, \sigma_{2}^{2}\right)
即每个权重其分布的先验都是两种相同均值、不同标准差的高斯分布的叠加。
下一步要做的就是继续对目标函数取近似,直到能求出来为止。
3. 遇事不决,蒙特卡罗
蒙特卡罗方法(Monte Carlo method)是刻在炼丹师 DNA 里的方法。(1) 中有一个期望不好求,可以使用这种喜闻乐见的办法弄出来。
众所周知,同样利用贝叶斯估计推导出来的变分自编码器(Variational Auto-Encoder, VAE)[2]引入了一个妙不可言的重参数化(reparameterize)操作:对于 z\sim \mathcal{N}(\mu,\sigma^2) ,直接从 \mathcal{N}(\mu,\sigma^2) 采样(sample)会使得 \mu 和 \sigma 变得不可微;为了得到它们的梯度,将 z 重写为 z=\sigma \epsilon+\mu ,其中 \epsilon\sim \mathcal{N}(0,1) ,这样便可以先从标准高斯分布采样出随机量,然后可导地引入 \mu 和 \sigma 。
[1]对此进行了推广,证明了对一个随机变量 \epsilon 和概率密度 q(\epsilon) ,只要能满足 q(\epsilon)d\epsilon=q(\mathbf{w}|\theta)d\mathbf{w} ,则对于期望也可以使用类似操作得到可导的对期望偏导的无偏估计:
\frac{\partial}{\partial \theta} \mathbb{E}_{q(\mathbf{w} | \theta)}[f(\mathbf{w}, \theta)]=\mathbb{E}_{q(\epsilon)}\left[\frac{\partial f(\mathbf{w}, \theta)}{\partial \mathbf{w}} \frac{\partial \mathbf{w}}{\partial \theta}+\frac{\partial f(\mathbf{w}, \theta)}{\partial \theta}\right]
利用这一点可以得到 (1) 的蒙特卡罗近似:
\begin{align} \mathcal{F}(\mathcal{D}, \theta) \approx \sum_{i=1}^{n} \log q\left(\mathbf{w}^{(i)} | \theta\right)-\log P\left(\mathbf{w}^{(i)}\right) -\log P\left(\mathcal{D} | \mathbf{w}^{(i)}\right) \end{align} (2)
其中 \mathbf{w}^{(i)} 是处理第 i 个数据点时的权重采样。
[1]中提出的这个近似把 \mathcal{F}(\mathcal{D}|\theta) 的 KL 项也给蒙特卡罗了,而其实对于很多先验形式这个 KL 项是可以有解析解的。[1]这么做的理由是为了配适更复杂的先验/后验形式。另一篇文章[3]只考虑高斯先验,于是在同样的证据下界中取了 KL 项的解析解。实践中可以根据使用的先验不同来取不同的近似。
4. 贝叶斯小批梯度下降
(1) 中的目标函数及 (2) 中的近似都是模型在整个数据集上的下界。实践中的现代炼丹都是采用的小批梯度下降(mini-batch gradient descent),所以需要相应地缩放复杂性代价。假设整个数据集被分为 M 批,最简单的形式就是对每个小批作平均:
\begin{aligned} \mathcal{F}_{i}^{\mathrm{EQ}}\left(\mathcal{D}_{i}, \theta\right)=\frac{1}{M} \mathrm{KL}[q(\mathbf{w} | \theta) \| P(\mathbf{w})] -\mathbb{E}_{q(\mathbf{w} | \theta)}\left[\log P\left(\mathcal{D}_{i} | \mathbf{w}\right)\right] \end{aligned}
这样可以使得 \sum_{i} \mathcal{F}_{i}^{\mathrm{EQ}}\left(\mathcal{D}_{i}, \theta\right)=\mathcal{F}(\mathcal{D}, \theta) 成立。在此基础上[1]还提出了另一种缩放:
\begin{aligned} \mathcal{F}_{i}^{\pi}\left(\mathcal{D}_{i}, \theta\right)=\pi_{i} \mathrm{KL}[q(\mathbf{w} | \theta)\| P(\mathbf{w})] -\mathbb{E}_{q(\mathbf{w} | \theta)} &\left[\log P\left(\mathcal{D}_{i} | \mathbf{w}\right)\right] \end{aligned}
只要取 \pi \in[0,1]^{M} 并保证 \sum_{i=1}^{M} \pi_{i}=1 ,那么 \sum_{i=1}^{M} \mathcal{F}_{i}^{\pi}\left(\mathcal{D}_{i}, \theta\right) 就是 \mathcal{F}(\mathcal{D}, \theta) 的无偏估计。特别地,取 \pi_{i}=\frac{2^{M-i}}{2^{M}-1} ,可以使在一轮(epoch)训练的初期着重于契合先验、后期着重于拟合数据,带来(玄学的)性能提升。
5. 局部重参数化
至此为止的在神经网络权重中引入的不确定性可以看作是全局的(global)不确定性。在神经网络中引入全局不确定性意味着在推理计算(inference)过程中要对全局所有参数进行采样操作,这个代价其实要比想象中高昂——比如一个 1000\times1000 的全连接层(fully connected layer),对于 M\times1000 的输入需要 M\times1000\times1000 个不同的采样,并且更致命的是,一般的神经网络中这样的全连接层,由于参数是同一个矩阵,可以转换为一个 (M,1000) 矩阵和 (1000,1000) 矩阵之间的乘法;而引入了不确定性后,需要采样 M 组不同的 (1000,1000) 参数,进行 M 次 (1,1000) 与 (1000,1000) 的矩阵乘法,对于一般的矩阵并行库而言这是两件完全不同的事情。
针对这个问题,[3]观察到,如果所有参数都是独立高斯分布,那么进行矩阵乘法后的结果也都会是独立高斯分布。也就是说,对于 \mathbf{Y}=\mathbf{X}\mathbf{W} ,若有
q\left(w_{i, j}\right)=N\left(\mu_{i, j}, \sigma_{i, j}^{2}\right) \forall w_{i, j} \in \mathbf{W}
那么对于 \mathbf{Y} 就会有
q\left(y_{m, j} | \mathbf{X}\right)=N\left(\gamma_{m, j}, \delta_{m, j}\right)
其中 \gamma_{m, j}=\sum_{i} x_{m, i} \mu_{i, j} 且 \delta_{m, j}=\sum_{i} x_{m, i}^{2} \sigma_{i, j}^{2} 。
有了这个结论,我们就没有必要每次都采样参数 \mathbf{W} 了,可以直接计算出结果 \mathbf{Y} 的均值和方差进行采样,然后反向传播到 \mathbf{W} 上。这样每次计算进行的采样都是相应数据点的局部(local)采样,[3]将这个技巧称为局部重参数化(local reparameterization)。
效果
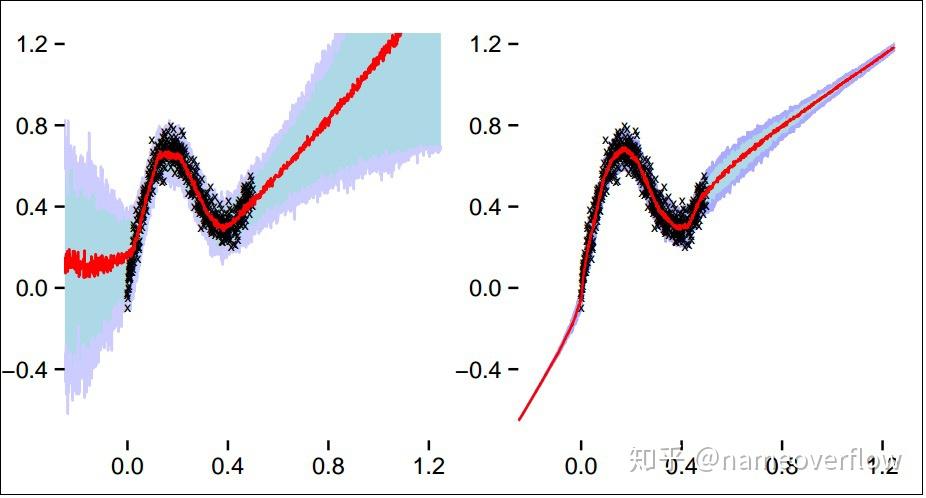
[1]中的噪声数据回归结果。左图为贝叶斯神经网络,右图为普通神经网络。红色标记表示预测值中位数;蓝色紫色区域为四分位区域。
[1]中给出了一个玩具级噪声数据回归任务的示意图。图中可以看出贝叶斯神经网络的不确定性特点:在数据较多的区域可以做到准确拟合,而在数据稀疏的区域会保留较大的不确定性。
Gayhub 上有一个 PyTorch 实现多种贝叶斯神经网络的仓库,如果对其实现有兴趣可以参考。
参考
- ^abcdefghWeight Uncertainty in Neural Networks https://arxiv.org/abs/1505.05424
- ^Auto-Encoding Variational Bayes https://arxiv.org/abs/1312.6114
- ^abcVariational Dropout and the Local Reparameterization Trick https://arxiv.org/abs/1506.02557
|
|


 发表于 2023-3-29 21:42:57
发表于 2023-3-29 21:42:57