|
|
据说刷完这70个 LeetCode 精选题的人,都找到心仪的实习了。
官方介绍:最早的时候,SQL 作为一门查询数据库的语言,是程序员的必备技能,毕竟只有查询到正确的数据,才能有后面的数据加工、分析。在面试中,SQL 的考察也是一道必不可少的坎儿。通过这 70 题的专项练习,可以帮你打下坚实的「数据库」基础。题源: LeetCode 精选数据库 70 题 - 力扣(LeetCode)
在开始刷题之前,前先复习 3个重要基础知识点:
- MySQL 执行顺序
- 各种 JOIN
- 排序函数:rank, dense_rank, row_number
MySQL 语句的执行顺序

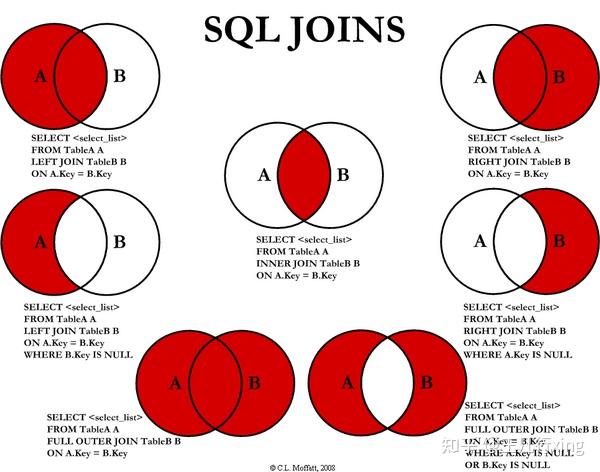
MySQL 各种 JOIN
排序:row_number/rank/dense_rank 的区别。
- 如果没有出现值相等的元素,三种排序相同;
- 如果有值相等的元素,三种排序结果则有异:rank() 排序相同时会重复,总数不变,排成:1->1-3>;dense_rank()排序相同时会重复,总数会减少,排成:1->1->2;row_number()排序相同时不会重复,会排成:1->2->3。
查询最值的几种思路
- 1,窗口函数 rank,排序且 rank = 1
- 2,聚合函数 min/max/count, order by,limit=1
- 3,聚合函数min (max/count) <= all ()
<hr/> 1- 1527E - Patient with a condition 患某种疾病的患者
此题考查 正则表达式 regular expression:
- ^DIAB1中的“^” 表示以某些字符串开头
- |表示或
- \\s 转义+空格
select *
from Patients
where conditions REGEXP &#39;^DIAB1|\\sDIAB1&#39;;2 - 511E Game Play Analysis I - 游戏玩法分析 I - 首次登录日期
联合主键:player_id + event_date
解法一:GROUP BY + IN(错误解法)
- GROUP BY 按照玩家 id 分组
- + IN 来选定某个玩家(组内)最早的登录日期
# Write your MySQL query statement below
select player_id, event_date first_login
from Activity
where event_date in (select min(event_date))
group by player_id;以上解法是有缺陷的,有时能提交成功,有时失败。
原因:where 先于 GROUP BY 执行,选出的 min(event_date) 是全局最小日期,而不是组内最小。
解法二:直接 SELECT min(event_date)
既然 select 是在分组之后,那我们就直接 select 最小的(组内)日期。
# Write your MySQL query statement below
select player_id, min(event_date) first_login
from Activity
group by player_id;注意:group by 或者 order by 的变量,还可以用数字 “1”、&#34;2&#34;等数字替代,表示 SELECT 后面的变量顺序。
# Write your MySQL query statement below
select player_id, min(event_date) first_login
from Activity
group by 1 ## 1 表示变量player_id
order by 1;解法三:DISTINCT + 窗口函数 + FIRST_VALUE
SELECT DISTINCT player_id,
FIRST_VALUE(event_date) OVER (
PARTITION BY player_id
ORDER BY event_date) AS first_login
FROM
Activity;这个解法中的first_value 还可以换成 last_value:
SELECT DISTINCT
player_id,
LAST_VALUE(event_date) OVER (
PARTITION BY
player_id
ORDER BY
event_date DESC RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS first_login
FROM
Activity;2 - 1069E Product Sales II -产品分析 II-每个产品的销售总量
此题比较简单,就是一个 group by + sum 函数。
select product_id, sum(quantity) total_quantity
from Sales
group by product_id;3 - 577E Employee Bonus 员工奖金
考点:left join,并且考虑字段为 NULL 的情况
select Employee.name, Bonus.bonus
from Employee
left join Bonus on Employee.empId = Bonus.empId
where Bonus.bonus < 1000 or Bonus.bonus is NULL;Btw, 两表合并的话,如果 ON 的字段名字一样,我们还可以用 USING
# Write your MySQL query statement below
select Employee.name, Bonus.bonus
from Employee
left join Bonus using(empId)
where Bonus.bonus < 1000 or Bonus.bonus is NULL;此外,这里我们还可以先把 NULL 转换为 0,就需要 or 第二个条件。
# Write your MySQL query statement below
select Employee.name, Bonus.bonus
from Employee
left join Bonus using(empId)
where IFNULL(Bonus, 0) < 1000;
4 - 584E Find Customer Referee 寻找用户推荐人
本题考查的是空值 NULL 的处理。
# Write your MySQL query statement below
select name
from Customer
where referee_id != 2 or referee_id is NULL;和上题类似,我们还可以使用 IFNULL函数,以及<>表示不等于。
# Write your MySQL query statement below
#select name
#from Customer
#where referee_id != 2 or referee_id is NULL; # 482 ms
select name ## 543 ms
from Customer
where IFNULL(referee_id, 0) <> 2; 不过这么写之后,运行速度下降了。
6 - 512E 游戏玩法分析 II Game Play Analysis II
此题是在 511E 的基础上,要求返回的不是第一次登录的日期,而是设备ID。
基于 511 的写法,我们可以改进为 (可以执行但无法提交成功,因为有漏洞):
# Write your MySQL query statement below
select player_id, device_id
from
(select player_id, min(event_date), device_id
from Activity
group by player_id) t; 我们还可以用 with t as (select ...) 的写法,来完成嵌套查询:
(本写法和上面写法等价,同样运行成功,但提交失败)
# Write your MySQL query statement below
with t as
( select player_id, min(event_date), device_id
from Activity
group by player_id)
select player_id, device_id
from t;两个解法提交失败的原因在于,player_id 和 device_id 无法构成主键唯一识别。
我们可以用 where in 来进行限制。
# Write your MySQL query statement below
select player_id, device_id
from Activity
where (player_id, event_date) in
(select player_id, min(event_date)
from Activity
group by player_id); # in 之后不需要表名字 t 此时提交可以通过。
7 - 534M 游戏玩法分析 Ⅲ Game Plays Analysis Ⅲ
此题难度是中等,需要用到列的累加。
在 Python 中,我们可以通过 numpy.cumsum 或者 df.cumsum 来完成累加。
在MySQL 中就稍微麻烦一点,而且做法比较特别: sum over(partition by order by)。特别地,这里不能用 group by player_id,因为一旦分组再求和,最后得到每一组一个总,而不是多个结果的累加求和。
select player_id, event_date,
sum(games_played) over(partition by player_id order by event_date) as games_played_so_far
from Activity;
#order by player_id, event_date;8 - 550M 游戏玩法分析 Ⅳ Game Plays Analysis Ⅳ
此题很有技术含量,非常值得重视。
首先,我们先简单算出总的游戏人数。
select count(distinct player_id) from Activity;
[Out: ]
3然后我们再来求首次登录且第二天登录的人数。
这里第二天登录的日期,我们可以用 Date(min(event_date) + 1) 来算,然后参考第六题,我们选出这个第二天在我们原来日期列的那些记录;当然,以上运算以 player_id 分组。完了,count 选到的结果,看有几个选手符合要求。
在默认的示范案例中,符合条件的人数是1,总人数是3,所以最后答案是0.33 (round(x, 2) 保留2位小数)。
select round(count(player_id) / (select count(distinct player_id) from Activity), 2) fraction
from Activity
where (player_id, event_date)
in
(select player_id, Date(min(event_date+1))
from Activity
group by player_id
)解法二:self join
WITH t AS (
SELECT
player_id, min(event_date) as event_start_date
from
Activity
group by player_id )
SELECT
round((count(distinct c.player_id) / (select count(distinct player_id) from activity)),2)as fraction
FROM
t
JOIN Activity a
on t.player_id = a.player_id
and datediff(t.event_start_date, a.event_date) = -19 - 570M 至少有5名直接下属的经理 Managers with At Least 5 Reports
此题的难度是M,但是相对不难。
# Write your MySQL query statement below
select name
from Employee
where id in
(
select managerId from Employee
group by managerId
having count(*) >= 5
)10 - 569H 员工薪水中位数 Median Employee Salary
此题难度为 Hard,除了考查 IN、窗口函数,还考查了中位数的计算公式。
这里按公司分组的计数,如果为偶数,那么基于 row_number() 的排序会返回 两个结果,如果是奇数则返回一个结果。这两个或一个的结果,是基于中位数的计算公式。
Btw,这里说一下 row_number/rank/dense_rank 的区别。
- 如果没有出现值相等的元素,三种排序相同;
- 如果有值相等的元素,三种排序结果则有异:rank() 排序相同时会重复,总数不变,排成:1->1-3>;dense_rank()排序相同时会重复,总数会减少,排成:1->1->2;row_number()排序相同时不会重复,会排成:1->2->3。
如果组内个数 n 为奇数,则中位数是 (n+1) / 2;
如果组内个数 n 为偶数,则中位数是 n/2 和 n/2 +1
# Write your MySQL query statement below
select id, company, salary
from
(
select Employee.*,
row_number() over(partition by company order by salary) as rnk,
count(company) over(partition by company) as n
from Employee
) t
where rnk in (n/2, n/2+1, (n+1)/2)解法二:不使用窗口函数
with c as (
select
player_id, min(event_date) as event_start_date
from
Activity
group by player_id )
select
round((count(distinct c.player_id) / (select count(distinct player_id) from activity)),2)as fraction
from
c
join Activity a
using(player_id)
where datediff(c.event_start_date, a.event_date) = -1
## Ref: https://lifewithdata.com/2021/08/03/sql-interview-questions-leetcode-550-game-play-analysis-iv/<hr/>11 - 571H 给定数字的频率查询中位数 Find Median Given Frenquency of Numbers

此题的一个经典解法是,找出那些不管是正序累积频数求和,还是逆序累积频数求和的数字,进行平均即可得出中位数。
对于题中的案例:
- 数字之和是12,12/2=6;
- 正序累积且逆序累积频数。
符合这个条件的只有数字0, 0的平均还是0。因此答案是 0.
至于要求出累积求和的数字,比较简单的方法是基于窗口函数 sum() OVER()。
第一步,先求出频数总和,结果是一个数字 12,作为判断的条件:
select sum(frequency) total from Numbers第二步,求出正序和逆序的累计频数表:
select num,
sum(frequency) over(order by num) asc_accumu,
sum(frequency) over(order by num desc) desc_accumu
from Numbers;
[Out: ]
{&#34;headers&#34;: [&#34;num&#34;, &#34;asc_accumu&#34;, &#34;desc_accumu&#34;], &#34;values&#34;: [[3, 12, 1], [2, 11, 4], [1, 8, 5], [0, 7, 12]]}第三步,从第二步的结果中,基于第一步结构构造的条件,来选出符合条件的1-2个数字,然后求平均,并保留一位小数:
select round(avg(num), 1) median
from
(select num,
sum(frequency) over(order by num) asc_accum,
sum(frequency) over(order by num desc) desc_accum
from Numbers) t1,
(select sum(frequency) total from Numbers) t2
where asc_accum >= total/2 and desc_accum >=total/212 - 586E Customer Placing the Largest Number of Orders 订单最多的客户
select customer_number
from Orders
group by customer_number
order by count(*) desc
limit 1;除了count(*),也可以count另外两个字段,比如order_number:
# Write your MySQL query statement below
select customer_number
from Orders
group by customer_number
order by count(order_number) desc
limit 1;13 - 619E 只出现一次的最大数字 Biggest Single Number
# Write your MySQL query statement below
select max(num) num
from (
select num
from MyNumbers
group by num
having count(num) = 1
) t;14 - 1075E 项目员工 I Project Employees Ⅰ
# Write your MySQL query statement below
select project_id, round(avg(experience_years), 2) average_years
from Project, Employee
where Project.employee_id = Employee.employee_id
group by project_id;15 - 1076 项目员工II Project Employees Ⅱ
先尝试一下一种不完整的做法,即分组统计排序后输出第一个结果。
当同时有大于1个项目员工的数量相等且最多,正确结果应该返回两个项目的id,而以下解法只能返回一个,所以不完整。
# Write your MySQL query statement below
select project_id
from Project
group by project_id
order by count(employee_id) desc
limit 1;改进:如果项目的员工数量大于等于其它项目,那么返回本项目的 id。
这里用 all 函数,返回其它项目的员工数。
select project_id
from Project
group by project_id
having count(employee_id) >=
all(
select count(project_id)
from Project
group by project_id
);另外,也可以基于窗口函数:
select project_id
from
(select project_id, dense_rank() over(order by count(employee_id) desc) as rnk
from Project
group by project_id) t
where rnk=1;注意,这里 rnk = 1,不能写入子查询当中的 having。
16 - 1077E 项目员工 III Project Employees III
先尝试使用 dense_rank + over()
第一步,考量将两表进行 left join,合并成一张大表
select Project.project_id, Project.employee_id, Employee.experience_years
from Project
join Employee
using(employee_id);两表合并也可以写成这样,不过这个是 INNER JOIN:
select Project.project_id, Project.employee_id, Employee.experience_years
from Project, Employee
where Project.employee_id = Employee.employee_id;第二步,基于 project_id 进行分组窗口函数 + dense_rank + experience_years 进行降序排序:
with cte as
(select Project.project_id, Project.employee_id, Employee.experience_years
from Project, Employee
where Project.employee_id = Employee.employee_id)
select project_id, employee_id,
rank() over(partition by project_id order by experience_years desc) as rnk
from cte;这里 rank() 和 dense_rank() 效果一致,因为我们最后都只保留 rnk=1 的员工。
第三步,选出 rnk=1 的员工:
with cte as
(select Project.project_id, Project.employee_id, Employee.experience_years
from Project, Employee
where Project.employee_id = Employee.employee_id)
select project_id, employee_id
from
( select project_id, employee_id,
rank() over(partition by project_id order by experience_years desc) as rnk
from cte) t
where t.rnk = 1;
# dense_rank = rank 或者换一种做法,使用 IN 来选出某个项目中 experience_years = manx(experience_years) 的那些员工。
with cte as
(select Project.project_id, Project.employee_id, Employee.experience_years
from Project, Employee
where Project.employee_id = Employee.employee_id)
# select project_id, employee_id
# from
# ( select project_id, employee_id,
# rank() over(partition by project_id order by experience_years desc) as rnk
# from cte) t
# where t.rnk = 1;
select project_id, employee_id
from cte
where (project_id, experience_years) in
(select project_id, max(experience_years)
from cte
group by project_id);17 - 1141E User Activity for the Past 30 Days I 查询近30天活跃用户数
对于时间范围,使用 datediff 计算较快:datediff(&#34;2019-07-27&#34;, activity_date) < 30.
datediff 函数中,返回的是第一个日期 - 第二个日期 的相隔天数。
select activity_date as day,
count(distinct user_id) as active_users
from Activity
group by activity_date
having 0<= datediff(&#34;2019-07-27&#34;, activity_date)
and datediff(&#34;2019-07-27&#34;, activity_date) < 30;18 - 1107M New Users Daily Count 每日新用户统计
第一步,对于某个用户,我们先找出其第一次登录的日期。
select user_id, min(activity_date) first_date
from Traffic
where activity = &#39;login&#39;
group by user_id然后,再在限定时间段内,以登录日期分组,计数首次登录的用户数量。
# Write your MySQL query statement below
select first_date login_date, count(distinct user_id) user_count
from
(select user_id, min(activity_date) first_date
from Traffic
where activity = &#39;login&#39;
group by user_id) t
where datediff(&#39;2019-06-30&#39;, first_date) <= 90
and datediff(&#39;2019-06-30&#39;, first_date) >= 0
group by login_date;注意:这里日期范围,写在了外层的查询。另外,如果最后加上 count > 0 和 日期降序的条件,运行速度会变得非常慢。
19 - 574M Winning Candidate 当选者
由于题目已经声明,获选者只有一个,所以我们可以统计选票并排序,选出得票最多的一个候选者,并输出ta的名字。
# Write your MySQL query statement below
select Candidate.name
from
(select candidateId, count(id) cnt
from Vote
group by candidateId
order by cnt desc
limit 1) t, Candidate
where Candidate.id = t.candidateId;这种方法逻辑简单,但运行速度一般。
而且本方法还可以进一步简化:先合并两表,把票的id信息,补充到 Candidate 表格,然后再分组计数、排序。
## 候选人2有两张选票,所以有2行;候选人1有0张选票,0行
select name
from Candidate
inner join Vote on Candidate.id = Vote.candidateId
group by Candidate.id
order by count(Vote.id) desc
limit 1;如果想避开 limit 1 我们可以尝试两次匹配的方法。
<hr/>20 - 578E - Get Highest Answer Rate Question 查询回答率最高的问题
首先,尝试一种比较投机的做法。
这里 cont 的 answer_id,如果不回答则是Null,计数为0,如果回答之后会存在 answer_id, 可以计数。
并且所有的题目只出现一次,要么被回答,要么不被回答。提交通过也意味着,全部题目只有一道题被回答,其它题目都没有被回答。
select question_id as survey_log
from SurveyLog
group by question_id
order by count(answer_id) desc, question_id asc
limit 1如果考虑到 answer 和 show 的次数为多次,我们可以先计数两个频数,然后再相除就出比率。
# Write your MySQL query statement below
select question_id as survey_log
from SurveyLog
group by question_id
order by sum(if(action=&#39;answer&#39;, 1, 0)) / sum(if(action=&#39;show&#39;, 1, 0)) desc, question_id
limit 121 - 579H - 查询员工的累计薪水 Find Cumulative Salary of an Employee
此题有个关键细节在于,某个月份与前两个月份一起求和(共3个月的工资总和)中,前两个月份的求法:
- rows 2 preceding ,表示数据中的前2行,而不是本题要求的是按月份顺序的前两个月,所以这里应该用
- range 2 preceding, 表示月份上的前2期
此外,排除最大月份可以在总表中完成:
- where (id, month) not in (select id, max(month) from employee group by id)。这里 id 和 month 还要进行组合,以排除 id 组内的最大月份
# Write your MySQL query statement below
select id, month,
sum(salary) over(partition by id order by month range 2 preceding) Salary
from employee
where (id, month) not in (select id, max(month) from employee group by id)
order by id, month desc;
22 - 1083 销售分析 II Sales Analysis II
Write an SQL query that reports the buyers who have bought S8 but not iPhone. Note that S8 and iPhone are products present in the Product table. 题目要求:找出买了 S8 但是没有买 IPhone 的顾客 id。
# Write your MySQL query statement below
select buyer_id
from product
left join Sales using(product_id)
group by buyer_id
having sum(if(product_name=&#39;S8&#39;, 1, 0)) > 0
and sum(if(product_name=&#39;iPhone&#39;, 1, 0)) = 0;这里用 if(expression, 1, 0) 函数来返回结果 1 或 0,然后进行 sum 函数的加总。
23 - 1084 销售分析 Ⅲ Sales Analysis III
题目要求:查询仅在2019年春季销售的产品。如果一个产品在一季度出售,也在其它季度出售,那么依然不符合条件。
# Write your MySQL query statement below
select distinct product_id, product_name
from Product
left join Sales using(product_id)
group by product_name
having sum(sale_date < &#39;2019-01-01&#39;) = 0 and ## 不在 2019-01-01 之前
sum(sale_date > &#39;2019-03-31&#39;) = 0 ## 且不在 2019-03-31 之后24 - 580E 统计各专业学生人数 Count Student Number in Departments
# Write your MySQL query statement below
select dept_name, count(distinct student_id) student_number
from Department
left join Student using(dept_id)
group by dept_id
order by student_number desc, dept_name;这里如果担心 count 一个没有学生的部分的人数不返回结果,可以加上 IFNULL(FIELD, 0):
select dept_name, ifnull(count(distinct student_id), 0) student_number
from Department
left join Student using(dept_id)
group by dept_id
order by student_number desc, dept_name;25 - 613 直线上的最近距离 Shortest Distance in a Line
考点:笛卡尔积,用来比较自己和其它同列的元素进行对比或运算
几个关键函数:
- 求差的绝对值,abs()
- 不等于,<>
- min() 求组内最小值。这里全部数据为一个组
# Write your MySQL query statement below
select min(abs(p1.x-p2.x)) as shortest
from point p1, point p2
where p1.x <> p2.x 26 - 612M 平面上的最近距离 Shortest Distance in a Plane
考点:笛卡尔积 - 表和自身的无条件合并
select
round(min(sqrt(pow((p1.x-p2.x), 2) + pow((p1.y-p2.y), 2))), 2) shortest
from Point2D p1, Point2D p2
where (p1.x, p1.y) <> (p2.x, p2.y); 这里 pow 函数可以考虑用两个相乘替代;sqrt 函数用 pow(expression, 0.5) 替代。
select
round(min(pow( (((p1.x-p2.x)*(p1.x-p2.x)) + (p1.y-p2.y)*(p1.y-p2.y)), 0.5)), 2) shortest
from Point2D p1, Point2D p2
where (p1.x, p1.y) <> (p2.x, p2.y); 27 - 610E 判断三角形 Triangle Judgement
# Write your MySQL query statement below
select x, y, z,
case when
(x+y>z and x+z>y and y+z>x) then &#39;Yes&#39;
else &#39;No&#39;
end as triangle
from Triangle;28 - 603E 连续空余座位 Consecutive Available Seats
这是个简单题?
题目要求:要找“所有连续可用的座位” - all the consecutive available seats in the cinema
这里其实原始数据中有一点非常关键:所有的位置分为两类,一类是连续的位置(我们的目标),另外一类是不连续的位置,在我们找的过程中被排除,最后剩下的就是连续的位置。
由于涉及到的数据一共有2列 x 2列,我们看下笛卡尔积的结果如何。
先看下原始表格:

笛卡尔积之后的结果:
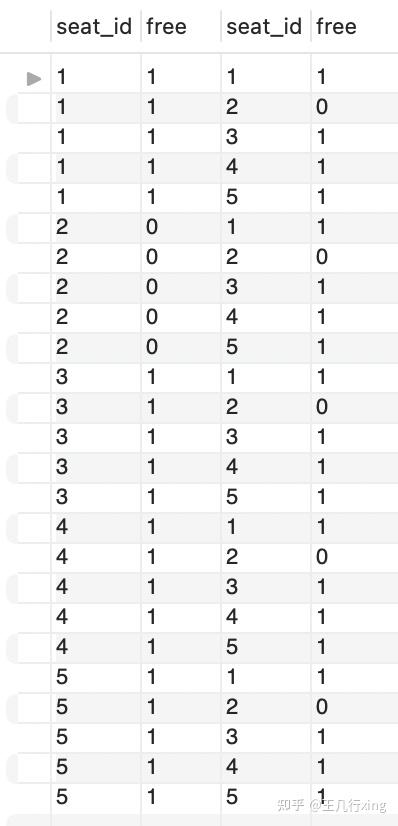
可以看到:
- 表 a 表示左边的 Cinema 表,表 b 表示右边的 Cinema 表,a 和 b 是同一张表;
- 笛卡尔积的匹配方式是两个表都有的主键 id;
- 表 a id 和 表 b id 的乘积结果是,所有可能的组合 -- 1和1-5进行匹配组合,2和1-5进行匹配组合,。。。
- 表 a 中 id 和 free 的对应关系不变,表 b 同理
接下来的解题思路:
- 用第三列 seat_id - 第一列 seat_id,如果他们绝对值=1,那么就是我们想要的相邻位置;
- 在条件中选出 a.free and b.free 都等于 1 的行,不要那些 free=0 的行;意思是只要某个位置不 free,那么它就出局;
- 在通过 distinct 把第一列的 seat_id 选出来,然后排序
# Write your MySQL query statement below
# 这里其实原始数据中有一点非常关键:所有的位置分为两类,一类是连续的位置(我们的目标),
# 另外一类是不连续的位置,在我们找的过程中被排除,最后剩下的就是连续的位置。
select distinct a.seat_id
from
Cinema a, Cinema b
where a.free=1
and b.free=1
and abs(a.seat_id - b.seat_id)=1
order by a.seat_id;29 - 1285M - 找到连续区间的开始和结束数字 Find the Start and End Number of Continuous Ranges
很巧妙的解题思路:
- 利用 id - row_number = diff,以 diff 分组,可以得出某组连续的 id;
- 从这组id中,可以选出最小的 id,和最大的 id返回;
- 排序函数:row_number() over(order by log_id)
# Write your MySQL query statement below
select min(log_id) as start_id,
max(log_id) as end_id
from
(
select log_id, (log_id - row_number() over(order by log_id)) as diff
from Logs
) t
group by diff;30 - 180M 连续出现的数字 Consecutive Numbers
看题:1 是唯一一个连续出现至少 3 次的数字。
<hr/>31 - 607E 销售员 Sales Person
题目要求:找出和 RED 公司没有业务来往的销售员名单
思路:
- 先找出和RED公司有业务来往的员工ID;
- 从 SalesPerson 表中选出剩下的其他员工姓名
## 607E 销售员 - 没有和RED公司相关的销售人员名字
select name
from SalesPerson
where sales_id not in
(
select Orders.sales_id
from Orders, Company ## 这里量表合并就够了,不需要3表合并
where Company.com_id = Orders.com_id
and Company.name = &#39;RED&#39; )32 - 597E 好友申请 Ⅰ:总体通过率
题目要求:求出好友的通过率,即通过的申请(不管该通过表中的申请是否在申请表中)/申请总数
思路:
- count(distinct requester_id, accepter_id)
- 最后加上 ifnull, 来处理分母为零的特殊情况
## 597E 好友通过率
select
round(
ifnull((select count(distinct requester_id, accepter_id) from RequestAccepted)/
(select count(distinct sender_id, send_to_id) from FriendRequest), 0)
, 2) accept_rate
33 - 602M 好友申请 II :谁有最多的好友
题目要求:找出拥有最多的好友的人和他拥有的好友数目
思路:
- self join,把好友列表第二列转变到第一列,然后 union all;
- group by id,然后count(*) ,选出最大的那个;
- 选出最大那个:having count() >= all(select count() from t group by id)
## 602M 好友申请 II :谁有最多的好友
with t as (
select requester_id as id from RequestAccepted
union all
select accepter_id from RequestAccepted)
select id, count(*) as num
from t
group by id
having count(*) >= all(select count(*) from t group by id);34 - 1173E 即时食物配送 I I Immediate Food Delivery I
题目要求:计算即时订单的比例
思路:
- 找出当天送达的订单总数,除以全部订单总数
- 注意用 ifnull,考虑分母为空的情况,赋值为零
## 1173E 即时食物配送 I I Immediate Food Delivery I
select
ifnull(
round(
100*count(distinct delivery_id) /
(select count(*) from Delivery), 2
),
0) immediate_percentage
from Delivery
where order_date=customer_pref_delivery_date;35 - 1174M 即时实物配送 II Immediate Food Delivery II
题目要求:计算当天送达的订单,在首次订单的比例
思路:
- 先找出当天送达的订单;
- (customer_id, order_date) in (select customer, min(order_date) from Delivery) 来选出首次订单;
- 用 sum(order_Date = customer_pref_delivery_date) 来计算当天送达的订单。注意,这里是 sum
## 1174E 即时食物配送 II
## 即时订单在所有用户的首次订单中的比例
select
ifnull(
round(
100*sum(order_date=customer_pref_delivery_date) /
count(distinct delivery_id),
2),
0) immediate_percentage
from Delivery
where (customer_id, order_date)
in
(select customer_id, min(order_date)
from Delivery
group by customer_id)36 - 1113E 报告的记录 Reported Posts
题目要求:查询每种 报告理由(report reason)在昨天(20119.7.4)的不同报告数量(post_id)
思路:
- 计算 post id 的时候,记得 加上 distinct,因为同一个 post id 可能有多种不同的 action;
- datediff(&#39;2019-07-15&#39;, action_date) = 1 来指定日期为前一天;
## 1113. 报告的记录
## 编写一条SQL,查询每种 报告理由(report reason)在昨天的不同报告数量(post_id)。假设今天是 2019-07-05。
select extra report_reason,
count(distinct post_id) report_count
from Actions
where datediff(&#34;2019-07-05&#34;, action_date) = 1
and action = &#39;report&#39;
group by extra ;37 - 1132M - 报告的记录 Reported Posts


题目要求:查找在被报告为垃圾广告的帖子中,被移除的帖子的每日平均占比
思路:
- 先算出每一天被报告为”spam“ 被删除帖子占比;
- 然后全部数据进行平均
## 1132M - 查找在被报告为垃圾广告的帖子中,被移除的帖子的每日平均占比
with cte as
(
select count(distinct b.post_id) / count(distinct a.post_id) rate
from actions a
left join removals b
using(post_id)
where extra = &#39;spam&#39;
group by action_date
)
select
ifnull(round(100*avg(rate), 2), 0) average_daily_percent
from cte;
38 - 1142E 过去30天的用户活动 II User Activity for the Past 30 Days
题目要求:查询 30 天内的每个用户的,平均会话数;只统计会话期间至少进行一项活动的有效会话 (计数 session,不过不是每个会话都是有效的嘛?)
## 1142E - 过去30天的用户活动 II
select
ifnull(round(
count(distinct session_id) / count(distinct user_id)
, 2), 0) average_sessions_per_user
from Activity
where datediff(&#39;2019-07-27&#39;, activity_date) < 30;39 - 1098E 小众书籍 Unpopular Books
题目要求:筛选出过去一年中订单总量 少于10本 的 书籍 。不考虑 available from 距离今天(2019.6.23)不满一个月的书籍
思路:
- 表1:先找出上架超过一个月的书籍;
- 表2:找出过去一年内的订单;
- 表1 left join 表2,group by book_id, having 销量 < 10
## 1098M 小众书籍
with t1 as
(
select * from Books
where available_from < &#39;2019-05-23&#39; -- 上架满一个月
),
t2 as
(
select * from Orders
where dispatch_date > &#39;2018-06-23&#39; -- 过去一年
)
select t1.book_id, t1.name
from t1
left join t2 using(book_id)
group by t1.book_id
having sum(ifnull(t2.quantity, 0)) < 10;40 - 1148E 文章浏览 I Article Views I
这题是真的比较简单,只需要找出 author_id=viewer_id的记录,并且用 distinct 关键字选出不重复的 aothor_id 即可。
# Write your MySQL query statement below
select distinct author_id id
from Views
where author_id=viewer_id
order by id; 41 - 1148M 文章浏览 II Article Views II
题目要求:找出同一天至少浏览2篇文章的人
思路:
- 通过 viewer_id + view_date 进行分组;
- 组内再 count(distinct article_id) >= 2;
select distinct viewer_id id
from Views
group by viewer_id, view_date
having count(distinct article_id) >=2;<hr/>42 - 1211E 查询结果的质量和占比 Queries Quality and Percentage
题目要求:求某个查询的平均质量,以及 poor 查询的比例
思路
- 先按照 query_name 进行分组;
- 组内用 avg(rating/position) 来求 查询质量;
- sum(rating<3) / count(*) 来求 poor 查询的比例
# Write your MySQL query statement below
select query_name,
ifnull(round(avg(rating/position), 2), 0) quality,
ifnull(round(100*sum(rating<3) / count(*), 2), 0) poor_query_percentage
from Queries
group by query_name43 - 1241E 每个帖子的评论数 Number of Comments Per Post
题目要求:求出子帖子(子节点)的数量,即评论的数量
思路
- 1,2, 12 三个为根节点;
- 其它为子节点,即题目要求的 回复的帖子数量
44 - 1251E 平均售价 Average Selling Price
题目要求:求出产品的平均价格
解题思路:
- 所谓产品是基于产品的 id 区分,虽然 id 不是单独的主键;
- 本题有个非常特别的地方在于,在进行 left join 的时候,需要加上 where UnisSold.purchase_date BETWEEN Prices.start_date AND Prices.end_date,来限定匹配的结果。如果不加上此条件,那么匹配出来的结果非常多,因为 Prices 中 product_id 并不是唯一的主键
- 在 left join 的 where 中加上这个条件,相当于利用了全部 Prices 联合主键的信息
# Write your MySQL query statement below
select a.product_id,
ifnull(round(sum(price*units) / sum(units), 2), 0) average_price
from Prices a
left join UnitsSold b
using(product_id)
where purchase_date between start_date and end_date
group by product_id
order by product_id45 - 1280E 学生们参加各测试的次数 Stduents and Examinations
这个题目难度至少 M 起步,而不是 LeetCode 说的E。
要求:输出一个完整的考试表,查看所有学生、在所有科目的考试情况,如果该科目没有考试记录,那么考试次数为0
特别之处:本题涉及到3表合并,而且在某个合并中,还用上了基于两个字段要同时相等的条件。
解题思路:
- Student 和 Subject 笛卡尔积,构造每个学生 id 匹配每一门课程的所有记录;
- Student-Subject 再 left join Examinations 表合并,这里关键是基于两个条件相等,即 student_id 和 student_name;
- 匹配结束之后,group by student_id, count subject_name;
- group by 是 by 前 3 个字段;
- 对于 count =0的结果,还可以用 ifnull 进行转换
# Write your MySQL query statement below
with t1 as
(select * from Students, Subjects)
select
t1.student_id,
t1.student_name,
t1.subject_name,
count(t2.subject_name) attended_exams
from t1
left join Examinations t2
on t1.student_id = t2.student_id
and t1.subject_name = t2.subject_name
group by 1, 2, 3
order by 1, 2, 3;46 - 1094E - 不同国家的天气类型 Weather Type in Each Country
题目要求: 求出所有国家 2019 年 11月份的平均气温,然后分类输出
## 1294. 不同国家的天气类型
select country_name,
case
when avg(weather_state) <= 15 then &#39;Cold&#39;
when avg(weather_state) >= 25 then &#39;Hot&#39;
else &#39;Warm&#39; end weather_type
from Countries
left join Weather using(country_id)
where day between &#39;2019-11-01&#39; and &#39;2019-11-30&#39;
group by country_name47 - 585M - 2016年的投资 - Investments in 2016
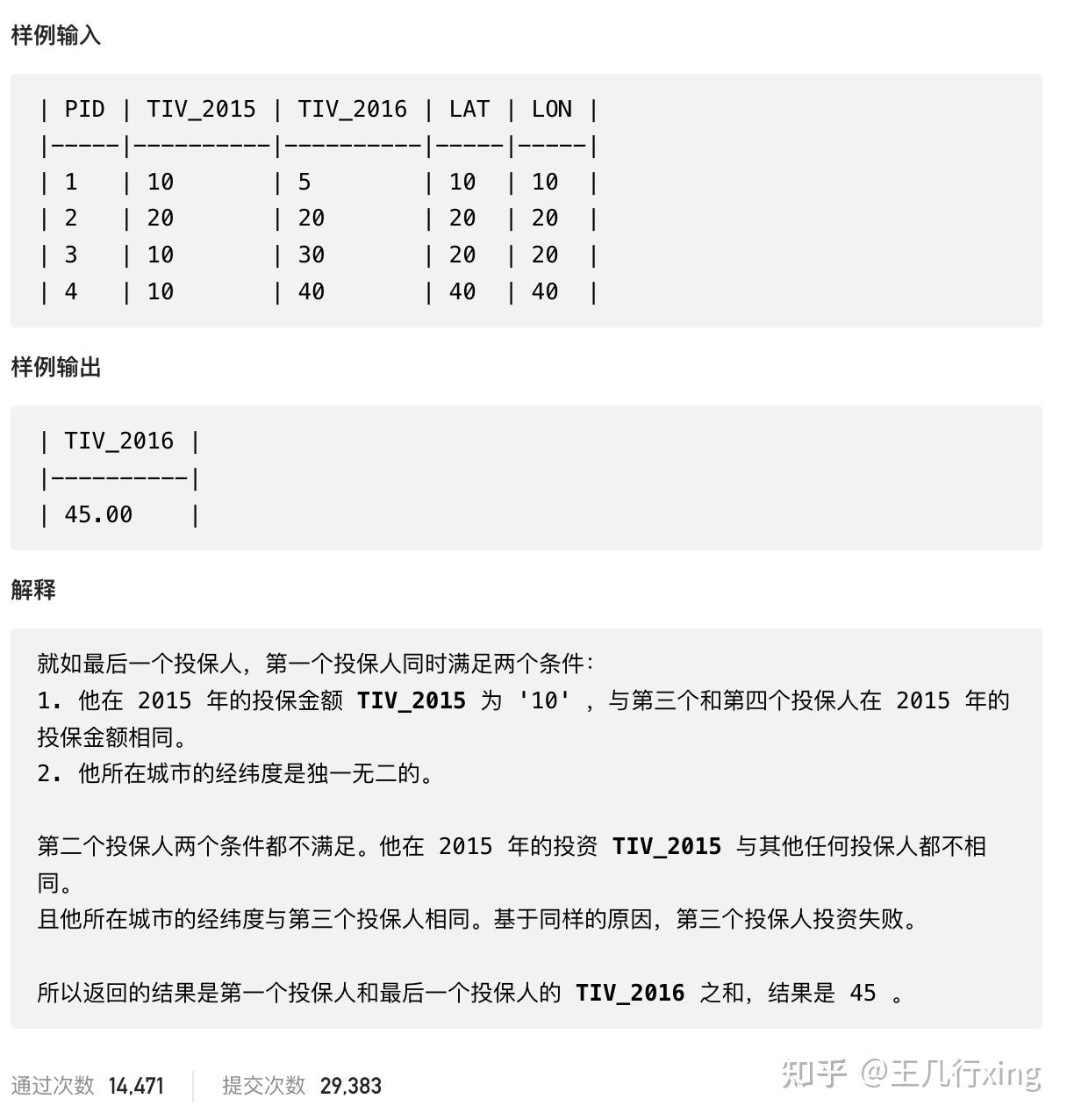
题目要求:加总2016 年 (TIV_2016) 所有成功投资的金额;对于一个投保人,他在 2016 年成功投资的条件是:
在 2015 年的投保额 (TIV_2015) 至少跟一个其他投保人在 2015 年的投保额相同;他所在的城市必须与其他投保人都不同(经纬度不能跟其他任何一个投保人完全相同)
## 585M 2016年的投资 - 非常巧妙的一道题
select
ifnull(round(sum(TIV_2016), 2), 0) TIV_2016 -- 总投资额
from
(
select i.*,
count(PID) over(partition by LAT, LON) cnt_loc, ## 地点的数量
count(PID) over(partition by TIV_2015) cnt_TIV_2015 ## 15年的投资额相同的人数
FROM Insurance i) tmp
where cnt_loc=1 ## 地点数量唯一
and cnt_TIV_2015 > 1 ## 15年至少和一个人的投资额相同48 - 608M - Tree Node 树节点


此题的难度应该不足以成为 M。
考点:
- 熟悉 node 类型的定义
- not in 后面不能 有 null,in 则可以?
# Write your MySQL query statement below
select id,
case
when p_id IS NULL then &#39;Root&#39; # 先取值的为准
when id in (select p_id from tree) then &#39;Inner&#39;
else &#39;Leaf&#39; # id not in (select p_id from tree) then &#39;Leaf&#39; 不可以:因为全部返回的 False
end as &#39;Type&#39;
from tree;49 - 1097 游戏分析 V Game Play Analysis V


题目要求:题目要求计算第二天的流失率。假设第一天登录认为是游戏安装,第二天登录则认为还在,第二天不登录则为流失。
思路:
- 先算出首次登录;
- 然后是第二天登录(如果登录则有日期,不然就是 Null);
- 第二天登录的分组计数求平均值
50 - 1303E - 求团队人数 Find the Team Size


题目要求:计算团队的成员数量
关键知识点:count(employee_id) over(partition by team_id)
select Employee_id,
count(Employee_id) over(partition by team_id) as team_size
from Employee51 - 614M - 二级关注者 Second Degree Follower
题目要求:寻找粉丝自己的粉丝数量,即 follower 的 follower 数量。
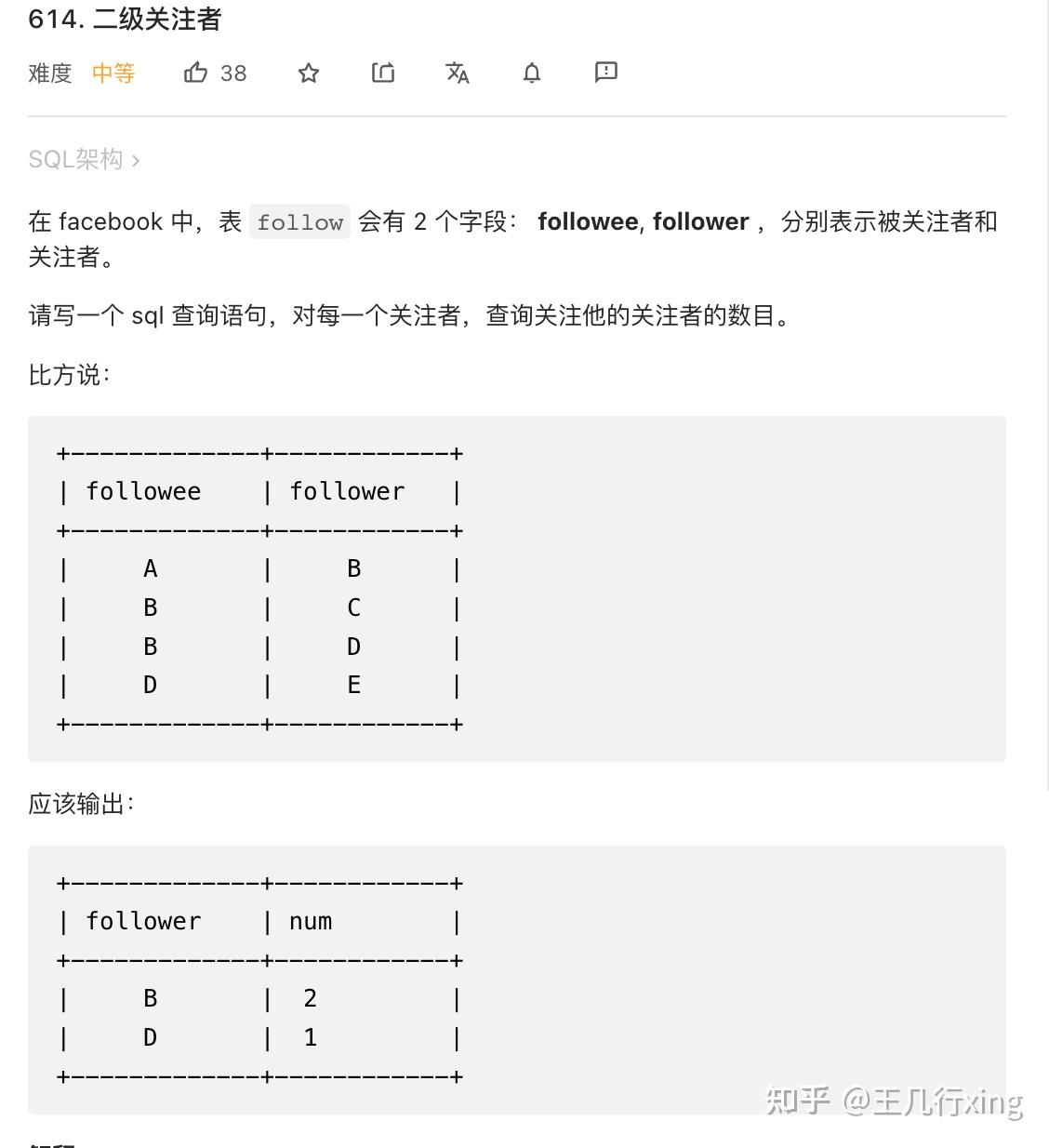

思路
- 找出有粉丝的 follower。意思是作为粉丝,有些人有粉丝,有些人没有。比如案例中的 B和D是有粉丝的,因为 B和D 出现在了 followee 那一列。这里可以用 where followee in distinct follower 来实现
- 然后以 followee 分组,来计算它的 follower 的数量。不过要注意,这里的 followee 在结果中,被重命名为 follower
# Write your MySQL query statement below
# 614M 二级关注者 Second Degree Follower
select followee as follower,
count(distinct follower) num
from follow
where followee in
(select distinct follower from follow)
group by 1;<hr/>52 - 1045M - 买下所有产品的客户 Customers Who Bought All Products
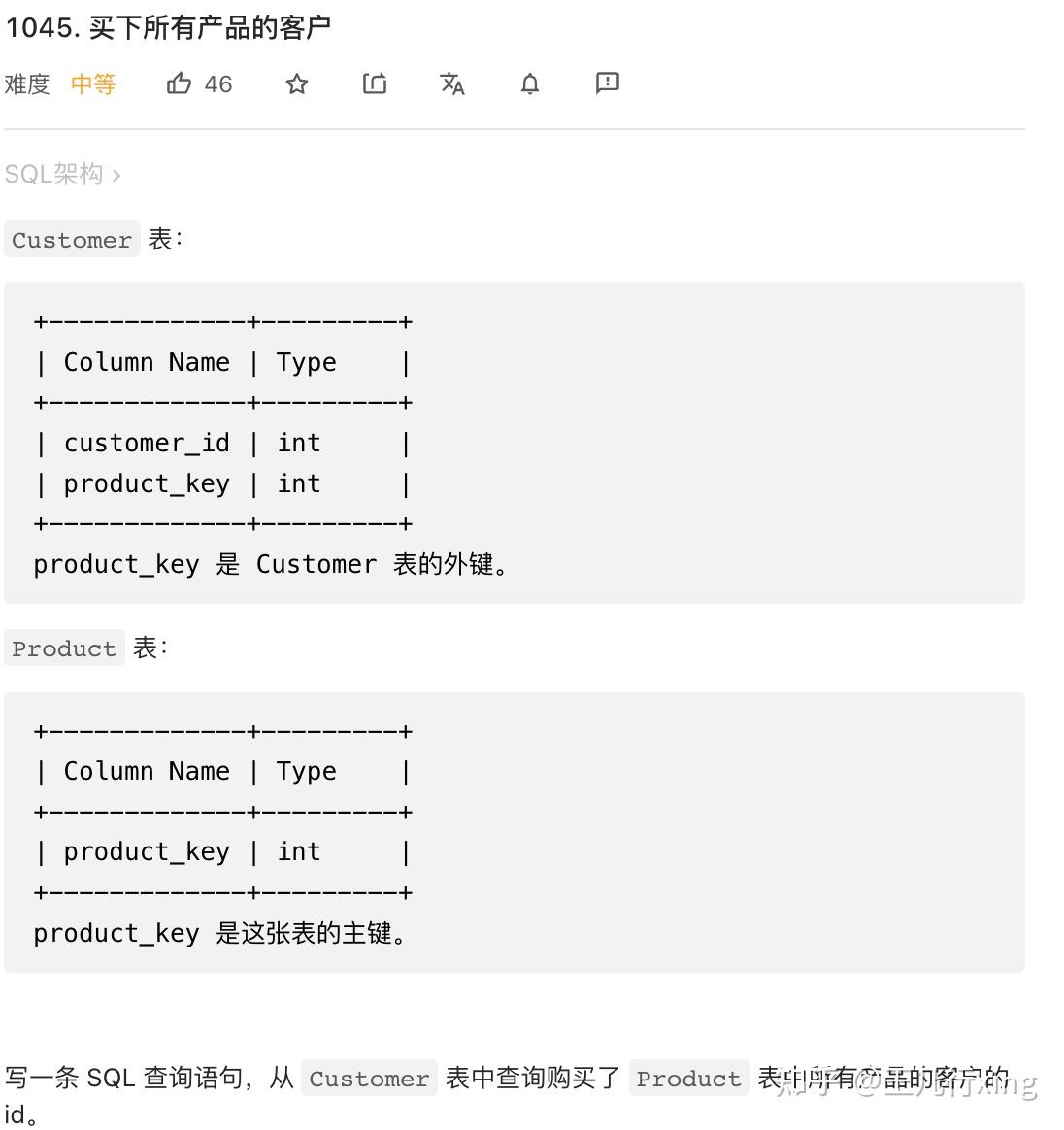

要求:找出那些,买过产品列表中所有产品的顾客
思路
- 以客户 id 分组;
- 计算该客户曾经购买的 产品类型数量,和 Product 表中全部产品的数量相等
# 1045M
# Write your MySQL query statement below
select Customer.customer_id
from Customer
group by customer_id
having count(distinct Customer.product_key) =
(select count(distinct Product.product_key) from Product);如果为了提高速度,我们还可以加上 in 的条件,只考虑那些属于 Product 列表的产品:
where product_key in (select product_id from Product)
53 - 1070M - 产品销售分析 III Product Sales Analysis III - 产品的首年销售情况
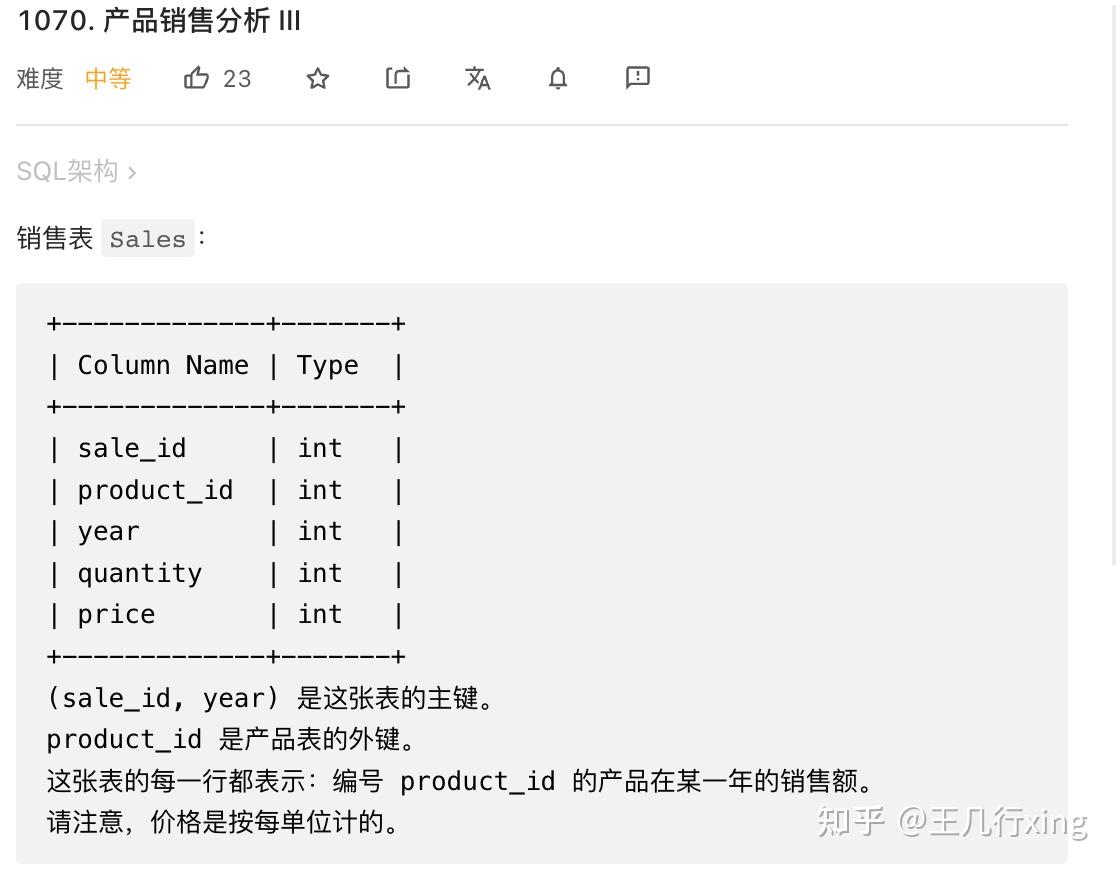


要求:选出每个销售产品 第一年销售的产品 id、年份、数量 和价格。
思路:
- 某些产品可能在多年销售,所以关键是找出第一年:min(year)
- group by product_id
- 因为是两个字段的联合主键,所以用 (product_id, year) in (product_id, min(year)) 来限定第一年的产品,这也是本题的关键考点
## 1070M 产品的首年销售情况 - 产品销售分析 III
select product_id, year first_year, quantity, price
from Sales
where (product_id, year) in
(select product_id, min(year) from Sales group by product_id)
54 - 1112M - 每位学生的最高成绩 Highest Grade for Each Student
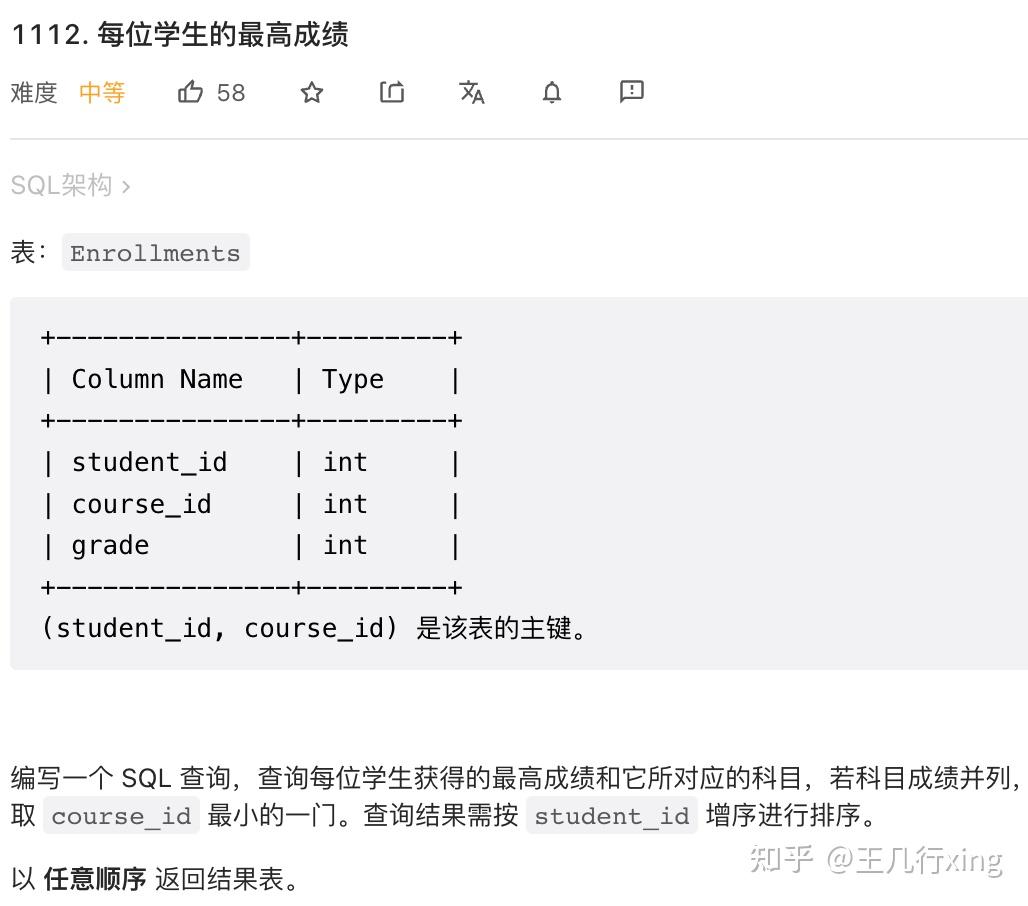
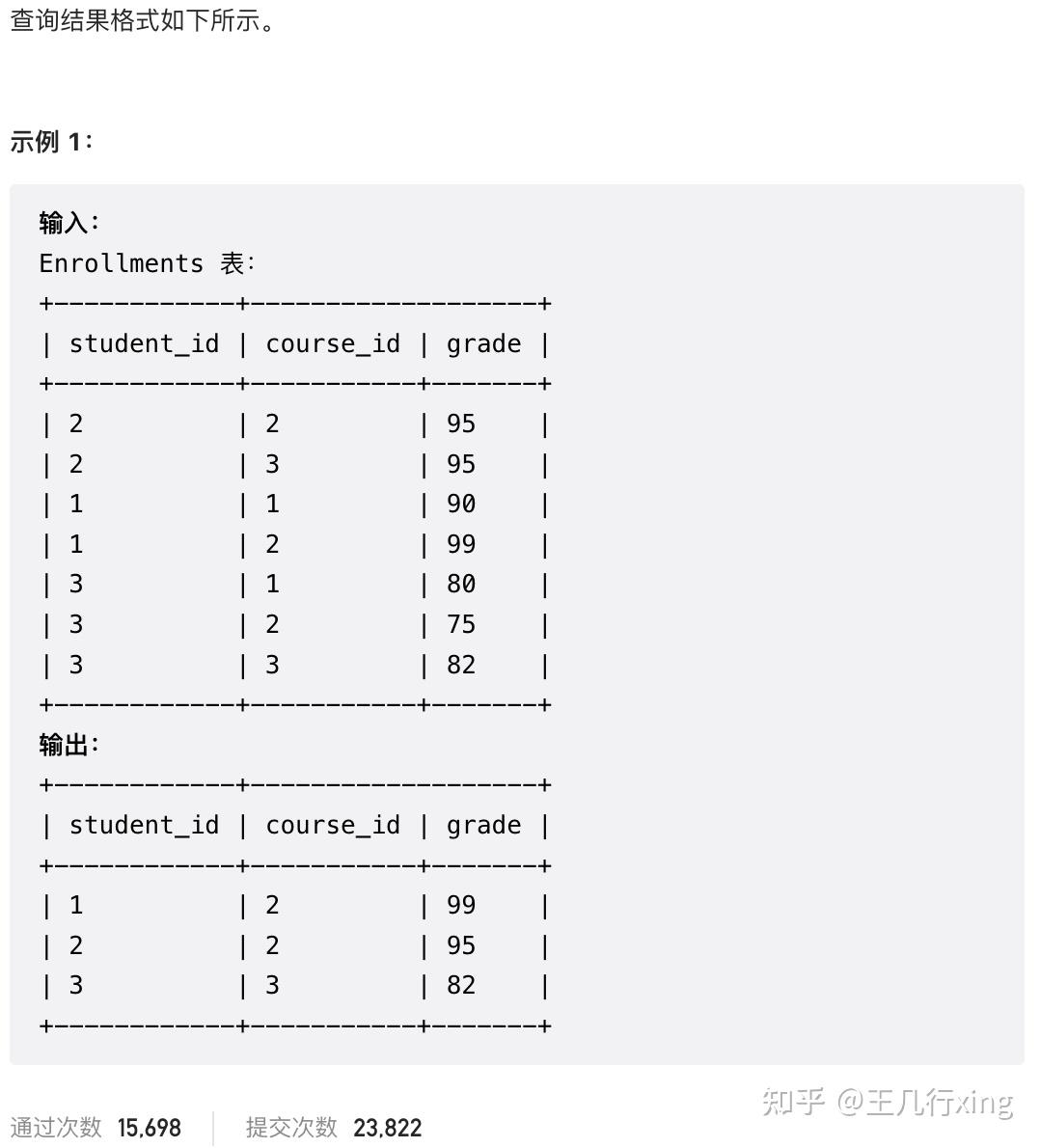
要求:求出每位学生所有科目考试的最高成绩
思路:
- 窗口函数,partition by student_id, 然后求出最大的成绩
- 或者使用 rank 函数,排出第一个成绩
## 1112M - 每位学生的最高成绩
## rnk 在第一层查询不能当成条件,在外层的查询才可以
select student_id, course_id, grade
from
(select *,
dense_rank() over(partition by student_id order by grade desc, course_id) rnk
from Enrollments) t
where rnk = 1;
55 - 1126M - 查询活跃业务 Active Business
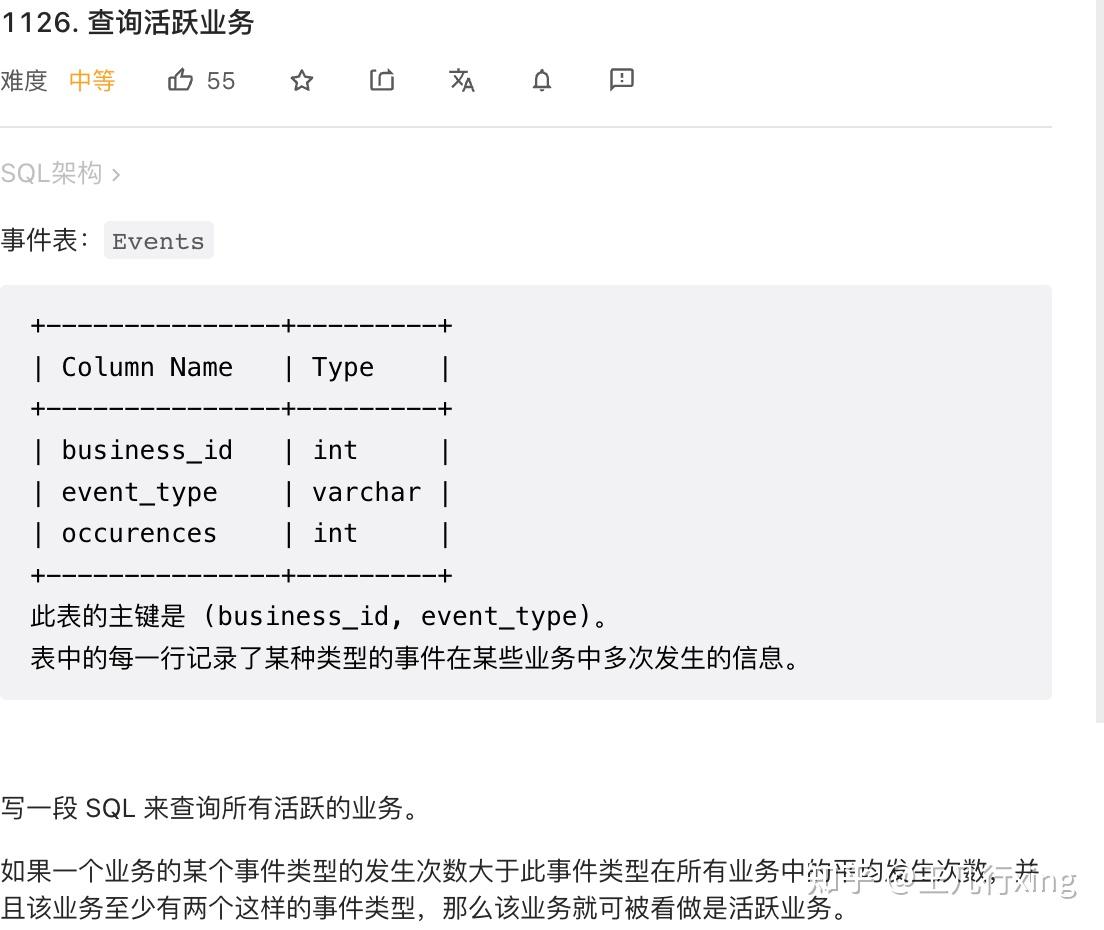

题目要求,所谓活跃业务,符合两个条件:
- 有大于等于 2 个业务,group by bunissess_id having count(distinct event_type) >= 2;
- 某个 event 发生的频率,要大于该类 event 的平均频率。这里需要用到窗口函数:avg(occurences) over(partition by event_type) as avg_occurence
- 窗口函数生成的新字段不能直接当成条件,所以我们要先生成使用窗口函数的子查询
## 1126M - 查询活跃业务
select business_id from
(select *,
avg(occurences) over(partition by event_type) avg_occ
from Events) t1
where occurences > avg_occ
group by business_id
having count(distinct event_type) >= 256- 1193M - Monthly Transactions I 每月交易 I


题目要求:查找每个月和每个国家/地区的事务数及其总金额,已批准的事务数及其总金额
思路
- date_format(trans_date, &#39;%Y-%m&#39;) 将日期转换为月份;
- sum(state = &#39;approved&#39;) 计数 approved 的事务数量;
- sum(amount) 计算全部事务的总额;
- sum(if(state = &#39;approved&#39;, amount, 0)) 计算被批准的事务的总额
# Write your MySQL query statement below
# 1193M 每月交易
select date_format(trans_date, &#39;%Y-%m&#39;) month, country,
count(*) trans_count,
sum(if(state=&#39;approved&#39;, 1, 0)) approved_count,
sum(amount) trans_total_amount,
sum(if(state=&#39;approved&#39;, amount, 0)) approved_total_amount
from Transactions
group by month, country57 - 1212M - 查询球队积分 Team Scores in Football Tournament

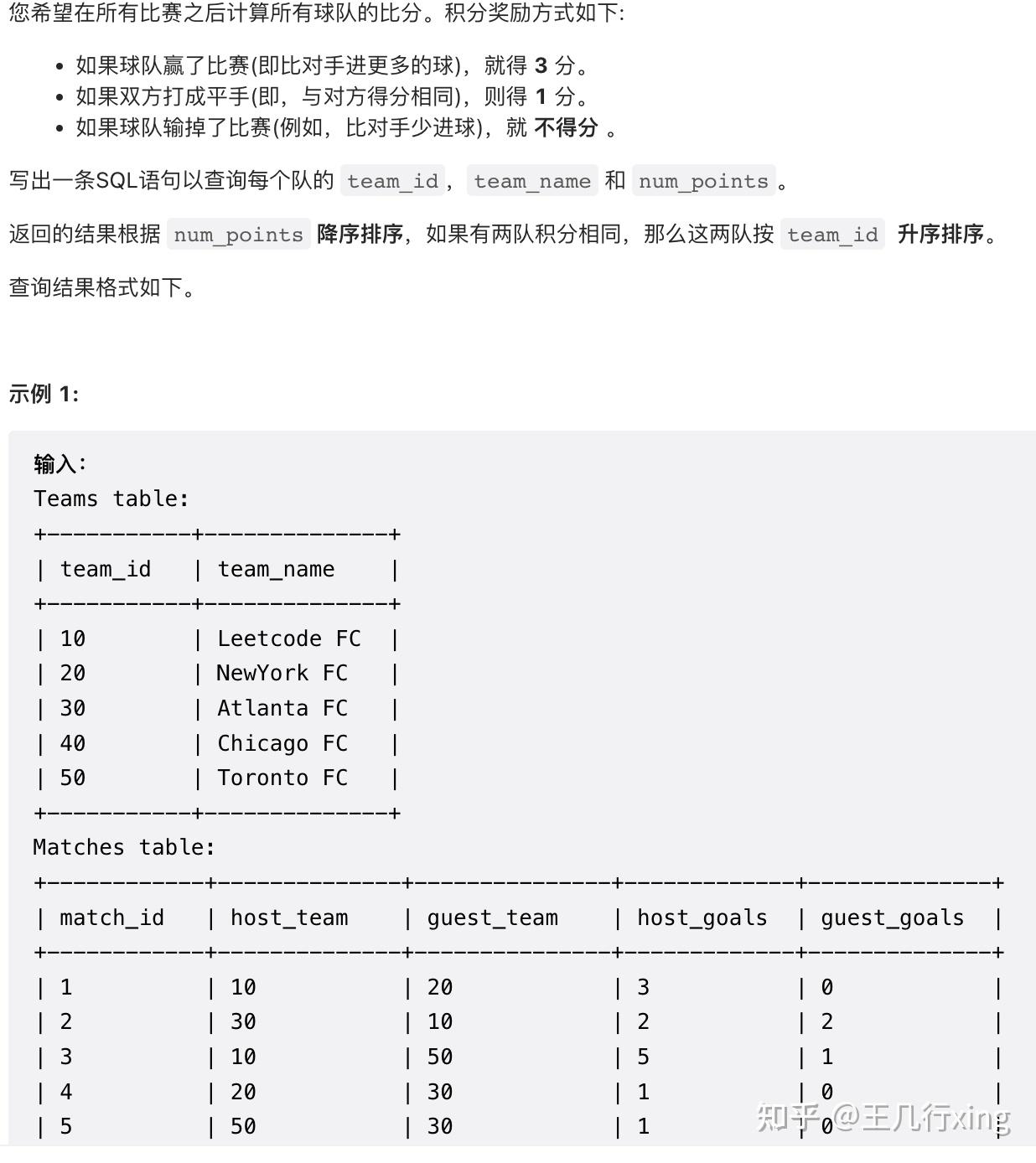

要求:根据规则和比较进球记录,计算各队积分
思路:
- 用 union all 来计算客队的积分 - 把客队的各列调整为和主表的计分方式差不多(主客调换,以主队的身份来计算积分),然后上下 concat
- group by team 表,然后用 case when 算分;
- group by team, sum(每场得分) = 某个队的总分
## 1212M 查询球队积分
# with 里面,没有 select match_id
with t1 as
(
select host_team, guest_team, host_goals, guest_goals from Matches
union all
select guest_team, host_team, guest_goals, host_goals from Matches
)
select t2.team_id, t2.team_name,
sum(case when t1.host_goals > t1.guest_goals then 3
when t1.host_goals = t1.guest_goals then 1
else 0 end) num_points
from Teams t2
left join t1
on t1.host_team = t2.team_id
group by t2.team_id
order by num_points desc, team_id 58 - 1264 - 页面推导

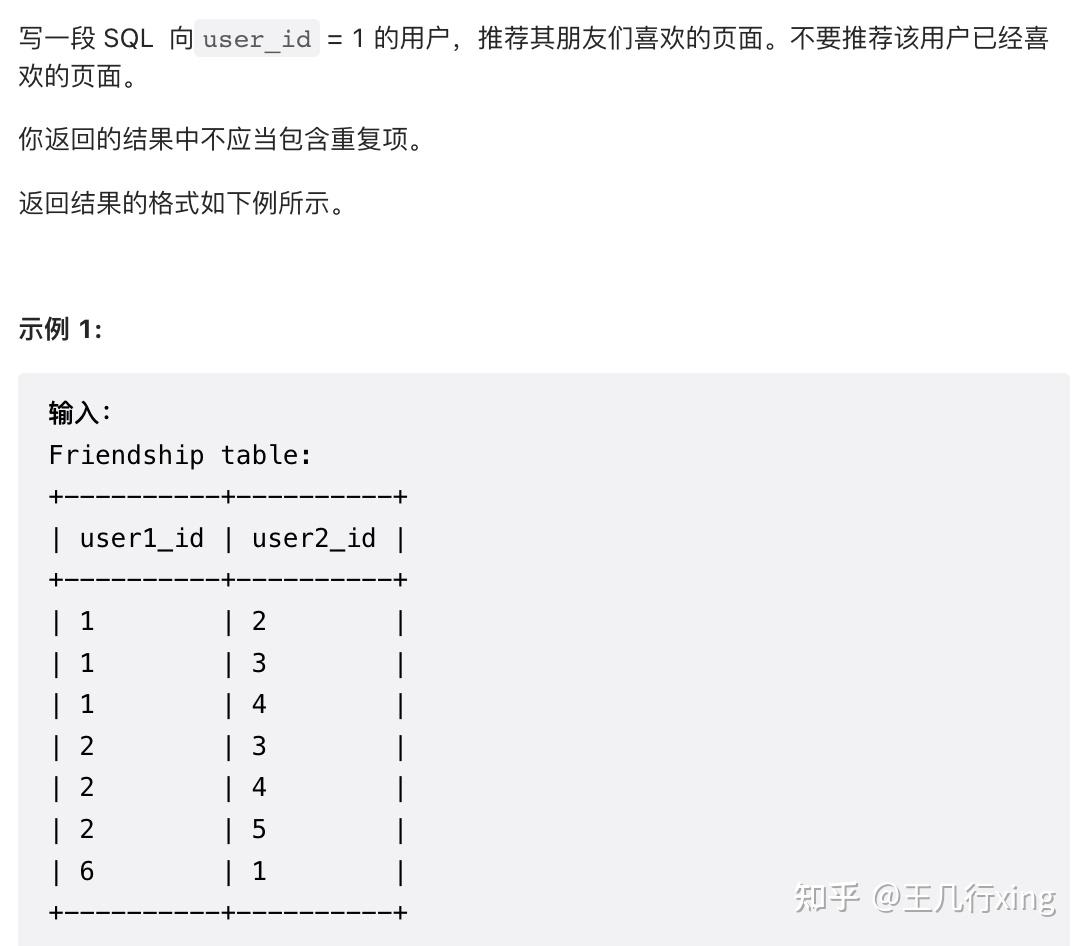

要求:向 user_id = 1 推荐他所有朋友喜欢的页面,但是排出他自己已经喜欢的页面
思路:
- 因为朋友是相互的,所以把 user2 换到 user1,再和原来的 friendship union 之后,可以得到 user_id = 1 的全部朋友列表;
- Union 之后,和 Likes left join,但注意 1 的朋友可能没有任何喜欢的页面。这里也可以用 inner join,就不用考虑朋友喜欢页面为空的情况
- 用 page_id not in (select page_id from likes where user_id=1) 来排出 1 自己喜欢的页面;
## 1264M 页面推荐
with t1 as
(
select user2_id user_id from Friendship where user1_id = 1
union
select user1_id user_id from Friendship where user2_id = 1
)
select distinct page_id recommended_page
from t1
left join Likes using(user_id)
where page_id not in (select page_id from Likes where user_id = 1)
and page_id is not null;Inner join:
## 1264M 页面推荐
with t1 as
(
select user2_id user_id from Friendship where user1_id = 1
union
select user1_id user_id from Friendship where user2_id = 1
)
select distinct page_id recommended_page
from t1
join Likes using(user_id)
where page_id not in (select page_id from Likes where user_id = 1);59 - 618H - 学生地理信息报告 Students Report by Geography
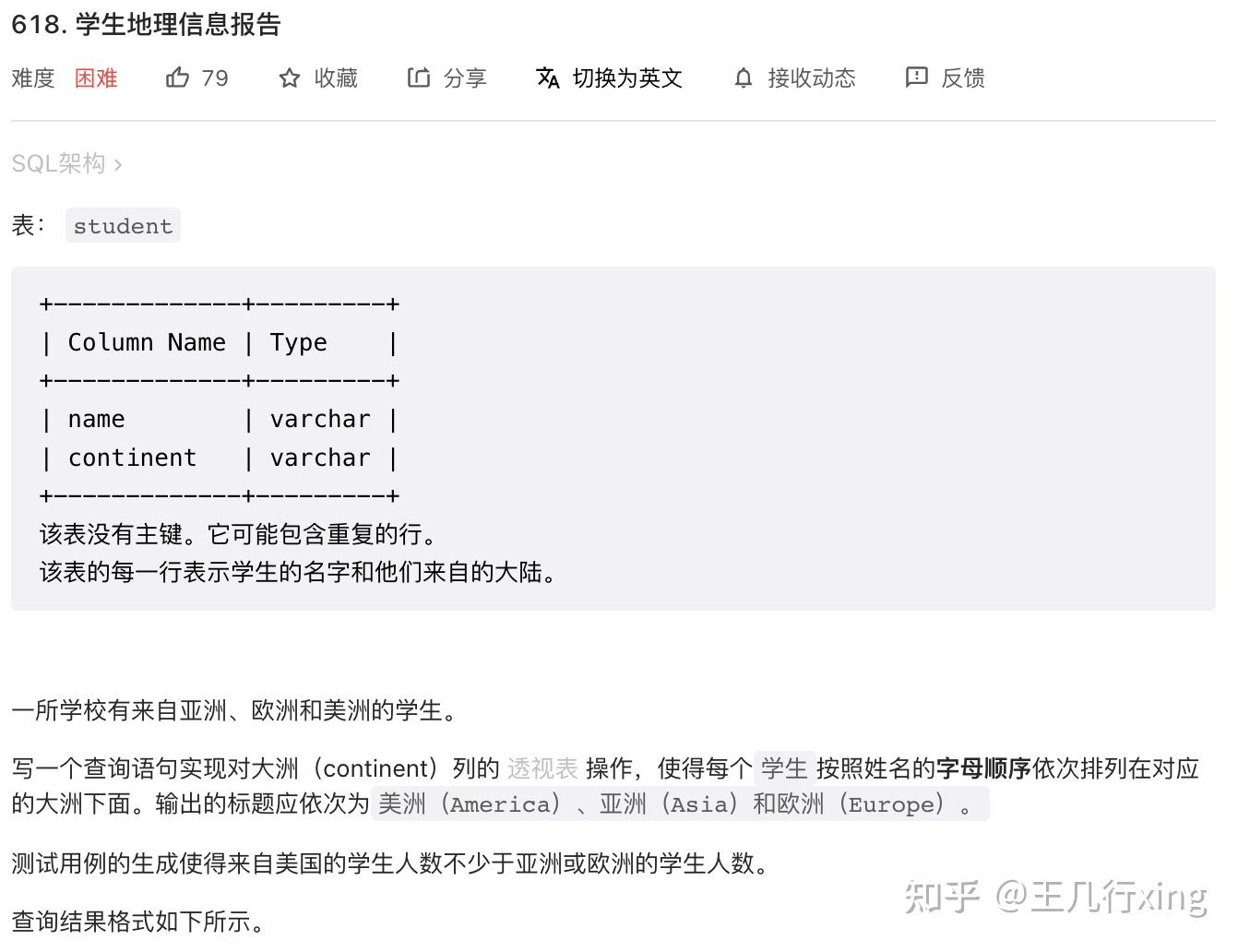

要求:制作透视表,用列的取值,来命名几个列,然后把姓名分到各个列下面
思路:
- 先用窗口函数,通过 continent order by name 用 row number 函数排序;
- if (contininent = &#39;America&#39;, name, null) America 然后 group by rnk,这里就是在同一个 rnk 中,依次去检索第一个、第二个元素...如果一直到 n(某个组内数量最多的那个值);
- min 函数来提取出来那个组(rnk分组)内最小的?因为可以消除 null 的问题(消除每一列的 null,所以不止是 min 函数,max 函数也可以。如果是数值型可以用 sum);
- case when 的功能是行转列,不过之前需要 row number 按 continent 排序;
重新理一下:
- 第一步,row_number() over(partition by continent order by name) 排序
- 第二步,case when 实现行转列;
- 第三步,按照 rnk 分组,然后 min/max 去掉 NULL。
## 618H 学生地理信息报告
select
min(if(continent=&#39;America&#39;, name, null)) America,
min(if(continent=&#39;Asia&#39;, name, null)) Asia,
min(if(continent=&#39;Europe&#39;, name, null)) Europe
from
(select student.*,
row_number() over(partition by continent order by name) as rnk
from student) t
group by rnk 60 - 176M - Second Highest Salary 第二高的薪水


题目要求:查询第二高的薪水,如果没有则返回 NULL
思路:
- 第一种方法 - 选出 distinct 的工资,并进行排序,然后
- 第二种方法 - 使用 dense_rank + over() 进行排序;如果没有结果,则返回 null
- 第三种方法 - 第一次 max,删除最高工资记录;第二次用 max,返回第二高工资
我们逐步来实现第一种方法。
# Write your MySQL query statement below
select salary SecondHighestSalary
from Employee
order by salary desc
limit 1 offset 1; ## 上面的结果不能处理结果为 NULL 的情况,需要改进。
SELECT
IFNULL(
(select salary
from Employee
order by salary desc
limit 1 offset 1), NULL )
as SecondHighestSalary; ## 字段重命名必须放在最后但是,还不能处理一种特殊情况:假如只有2个员工,他们的工资相等,那么也应该返回空。
所以我们加入 DISTINCT 关键字。
## 176M 第二稿薪水
SELECT
IFNULL(
(select DISTINCT salary
from Employee
order by salary desc
limit 1 offset 1), NULL )
as SecondHighestSalary; ## 字段重命名必须放在最后
第二种方法:
## 第二种方法
select salary SecondHighestSalary
from
(
select *,
dense_rank() over(order by salary desc) as rnk
from Employee
) t
where rnk=2不过这里依然不能处理 null 的问题,所以我们加上(如果只存在第一高工资,那第二高 = null)
## 第二种方法
select ifnull(
(select salary
from
(
select *,
dense_rank() over(order by salary desc) as rnk
from Employee
) t
where rnk=2), null) SecondHighestSalary ## 重命名放到最后但是,这里不能处理的是同是存在两个第二高工资的问题。因为此时最终返回的结果是两行,因此我们还需要加上 distinct。
## 第二种方法
select ifnull(
(select distinct salary # Distinct
from
(
select *,
dense_rank() over(order by salary desc) as rnk
from Employee
) t
where rnk=2), null) SecondHighestSalary ## 重命名放到最后61 - 1164M - 指定日期的产品价格 Price at A Given Day


要求:查找 2019-08-16 全部产品价格,假设所有产品在修改前的价格都是 10。
思路
- 巧妙的处理方法 -- 把 8.16 以后修改的价格全部改成10,因为之后修改的价格对于 8.16 当天来说是无效的,所以就会变成默认的价格 10
- 先选出一个 distinct 的Product_id;
- 如果通过 product id 分组,结合窗口函数将日期往 8.16 之前倒序排序,找出当天之前的最近一个日期(包括8.16),其对应的价格就是目前价格
- 对于 8.16 当天或者之前没有记录的 product id,那么匹配之后就为空,可以用 ifnull(new_price, 10) 替换成 10
## 1164M 8.16 指定日期的产品价格
with cte1 as
(select distinct product_id from products),
cte2 as
(
select product_id, new_price
from
(
select product_id, new_price,
dense_rank() over(partition by product_id order by change_date desc) rnk
from products
where change_date <= &#39;2019-08-16&#39;
) t
where rnk = 1 ## 离8.16当天最近的一天(包括当天也可能最近一天)
)
select cte1.product_id, ifnull(new_price, 10) price ## 如果之前没有记录就为null,改成10
from cte1
left join cte2 using(product_id)<hr/>62- 1204M - 最后一个能进入电梯的人 Last Person to fit in the Bus
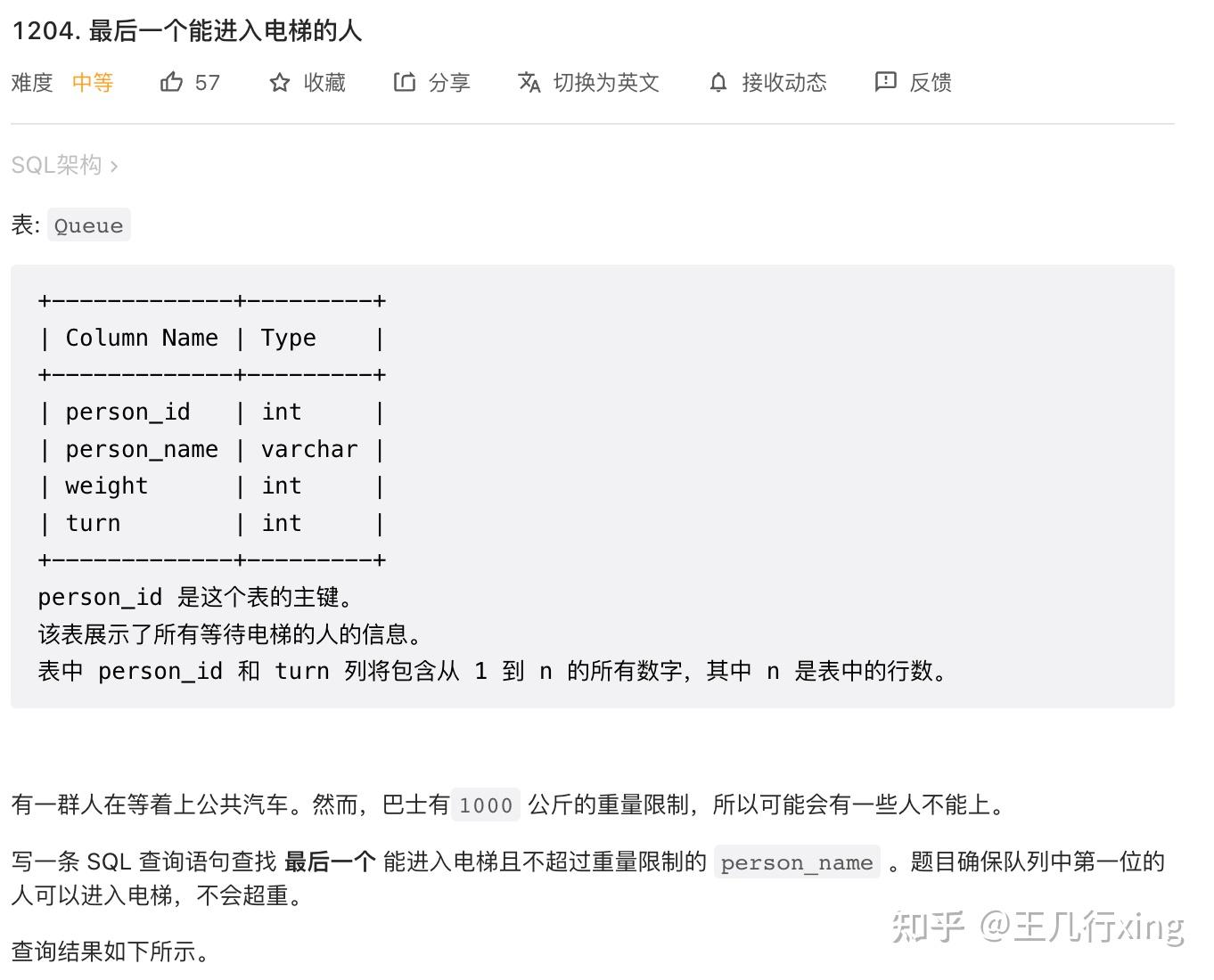

要求:找出最后一个能进入电梯的人(不超重, 1000)
思路:
- 利用 cumsum 函数根据顺序求出全部能进入电梯的人的名单;
- 基于 person id,降序排序并返回第一个
# Write your MySQL query statement below
select person_name
from
(
select *,
sum(weight) over(order by turn) cumsum_weight
from Queue
) t
where cumsum_weight <= 1000
order by turn desc
limit 163- 1205M - 每月交易 II Monthly Transactions II



要求:返回某个国家在某个月份的,approved_count, approved_amount, chargeback_count, chargeback_amount。这里 chargeback 相当于一种特殊的状态(和 approved,decline 平行)。
思路:
- 把Chargeback 表的信息和主表合并;
- 利用 outer join (left join UNION right join)
MySQL 的Outer join:
## Outer Join in MySQL
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id
UNION
SELECT * FROM t1
RIGHT JOIN t2 ON t1.id = t2.id第一步,先通过 left join,将 transactions 的信息,匹配给 Chargeback 表格的那些交易记录,并和 transactions 表 union all(必须是all,因为 id 有重复):
#with cte as
#(
select * from Transactions
union all
select c.trans_id, t.country, &#39;chargeback&#39; state, t.amount, c.trans_date ## 将 amount 的信息,匹配给 chargeback
from Chargebacks c
left join Transactions t
on t.id = c.trans_id
#)第二步,从表选出并计算 approved count,approved amount,Chargeback count,chargeback amount:
# Write your MySQL query statement below
with cte as
(
select * from Transactions
union all
select c.trans_id, t.country, &#39;chargeback&#39; state, t.amount, c.trans_date ## 将 amount 的信息,匹配给 chargeback
from Chargebacks c
left join Transactions t
on t.id = c.trans_id
)
select date_format(trans_date, &#39;%Y-%m&#39;) month, country,
sum(state=&#39;approved&#39;) approved_count,
sum(if(state=&#39;approved&#39;, amount, 0)) approved_amount,
sum(state=&#39;chargeback&#39;) chargeback_count,
sum(if(state=&#39;chargeback&#39;, amount, 0)) chargeback_amount
from cte
group by month, country
having approved_count <> 0 or chargeback_count <> 0; 64 - 1270M - 向公司CEO汇报工作的所有人 all people Report to the Given Manager

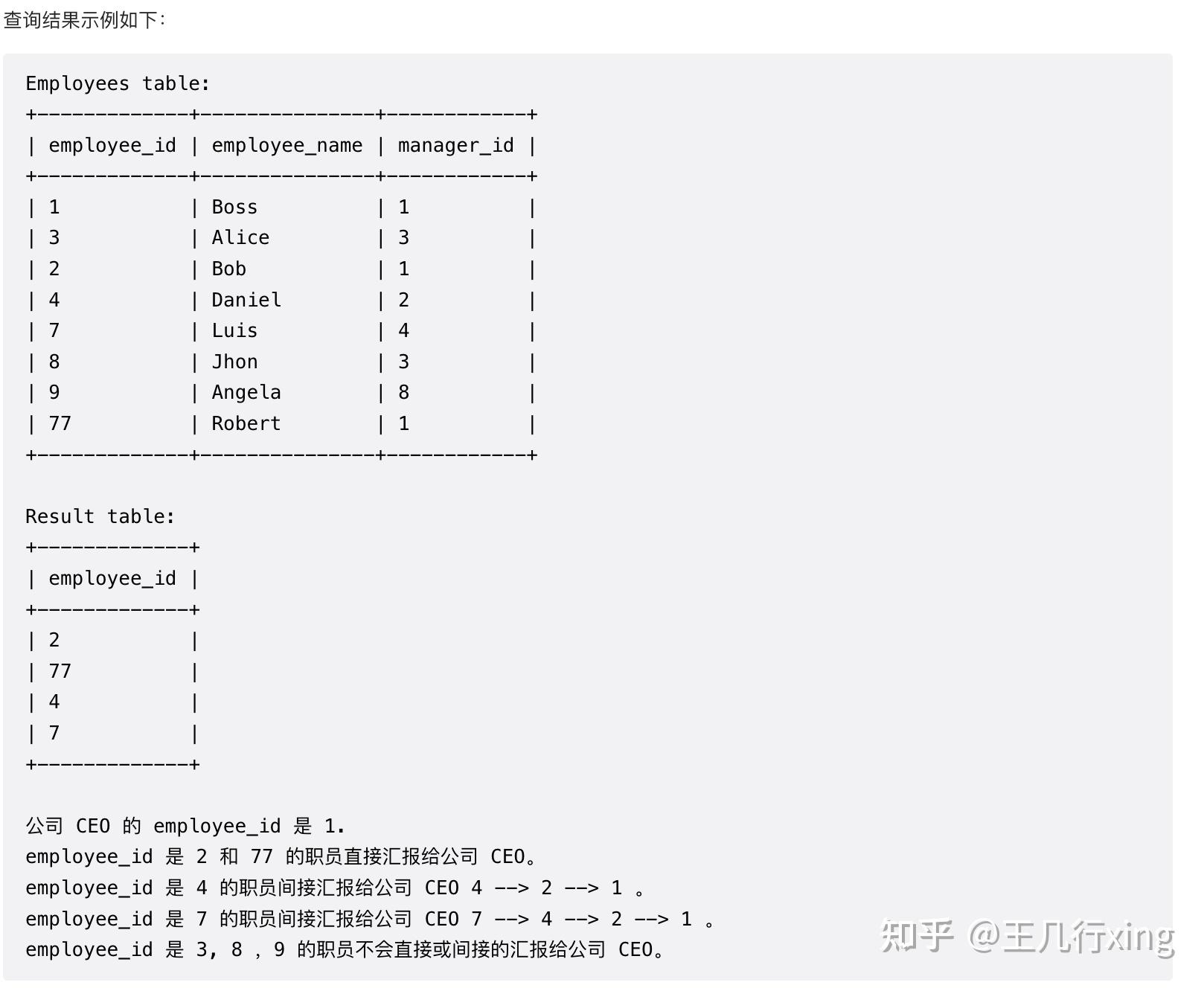
要求:找所有直接或间接向公司 CEO 汇报工作的employee_id
思路:
- 表格的自我合并2次,实现3层关系的全部映射
- 第一层是 CEO1,第二层是他的直接下属,第三次是他直接下属的直接下属
## 1270 M 找出直接向CEO 汇报的员工
select distinct a.employee_id
from Employees a
join Employees b on a.manager_id = b.employee_id
join Employees c on b.manager_id = c.employee_id
where a.employee_id <> 1
and c.manager_id = 165 - 1308M - 不同性别每日分数总计 Running Total for Different Genders

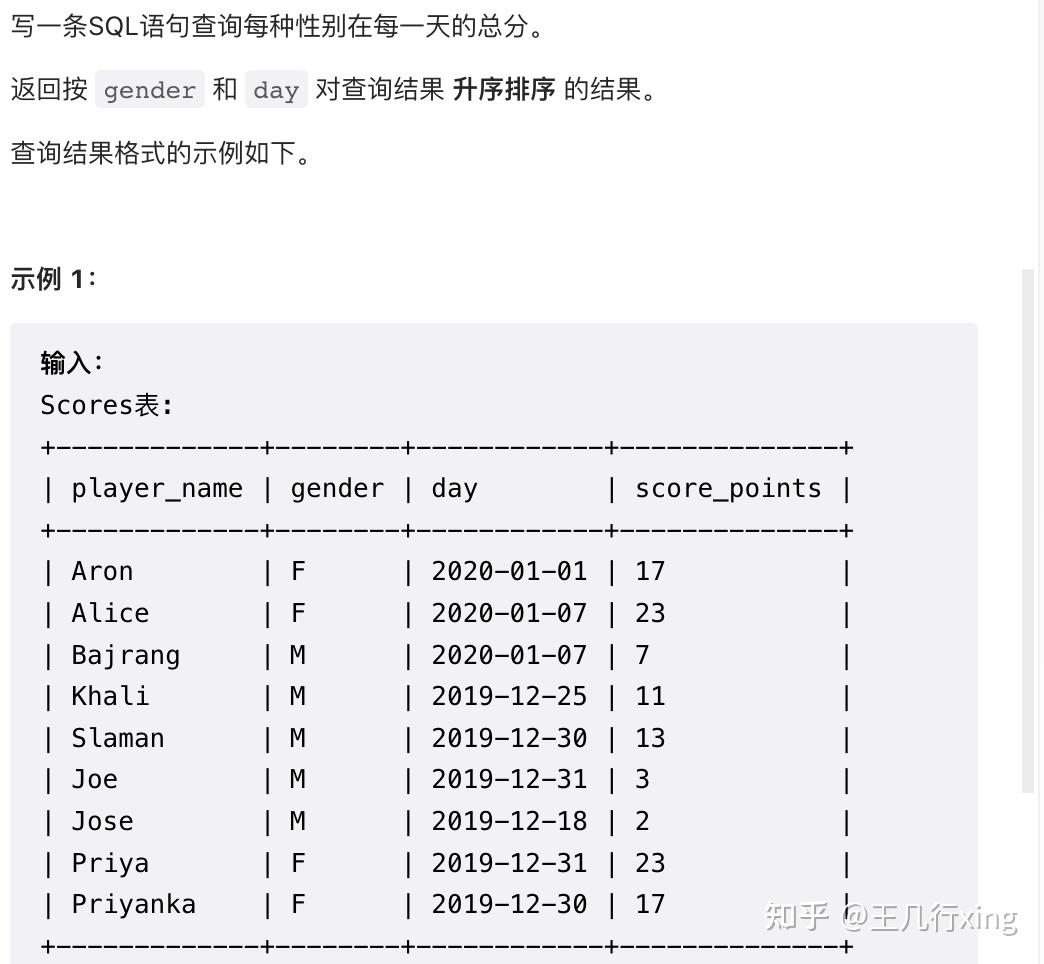
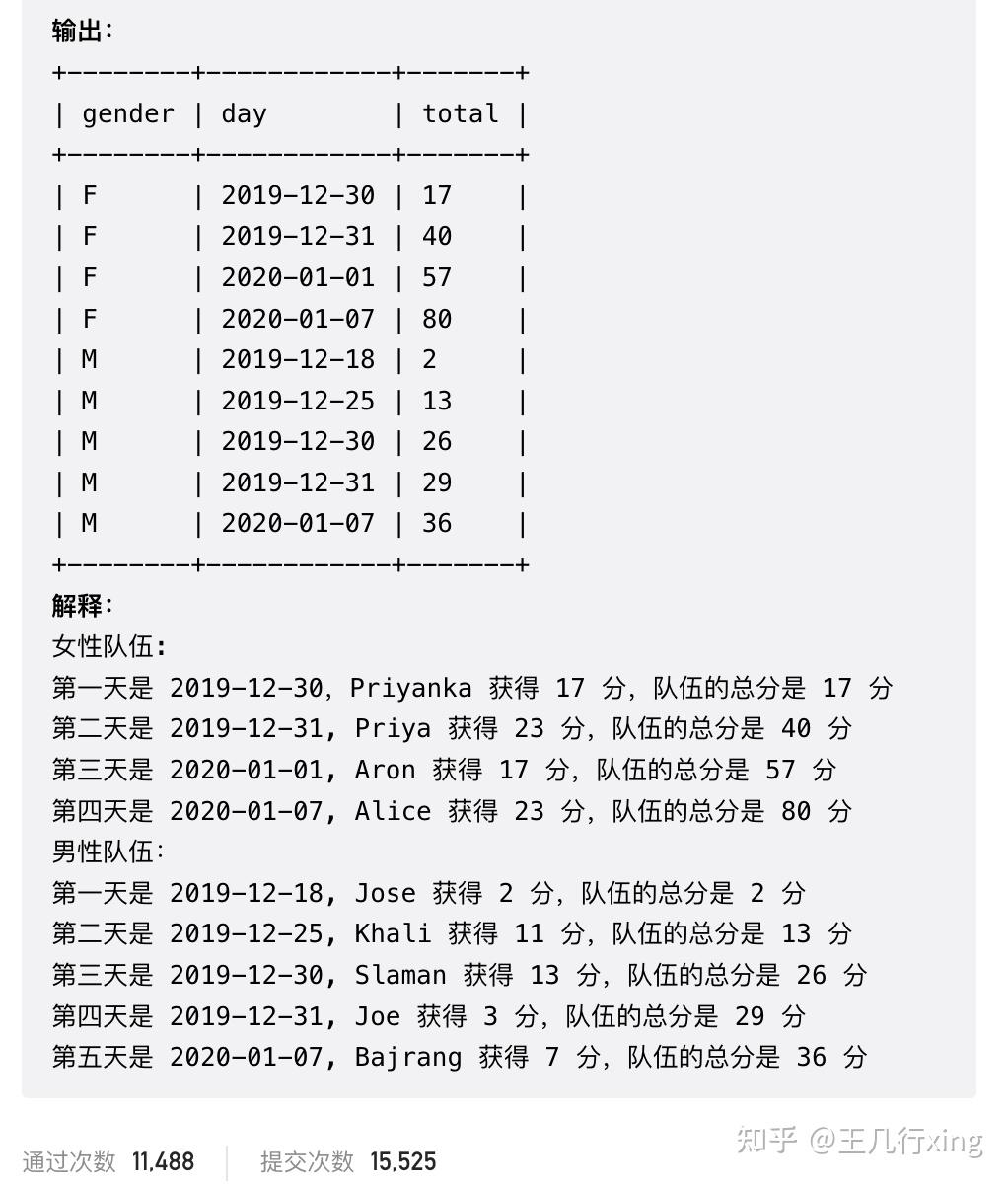
要求:查询每种性别在每一天的总分,按写别和日期升序排序
解法一:按窗口函数加总
## 1308M - 不同性别每日分数总计
## 解法一:按窗口函数加总
SELECT gender, day,
sum(score_points) over(PARTITION by gender order by day) total
from Scores
解法二:self join
通过 self join + a.day>=b.day 把后面日期的记录放到了右边,从而对 points 进行分组加总。
## 1308M - 不同性别每日分数总计
## 解法二:self join
select a.gender, a.day, sum(b.score_points) total
from Scores a, Scores b
where a.gender=b.gender and a.day >= b.day
group by a.gender, a.day
order by a.gender, a.day
66 - 1321M - 餐馆营业额变化增长 Restaurant Growth

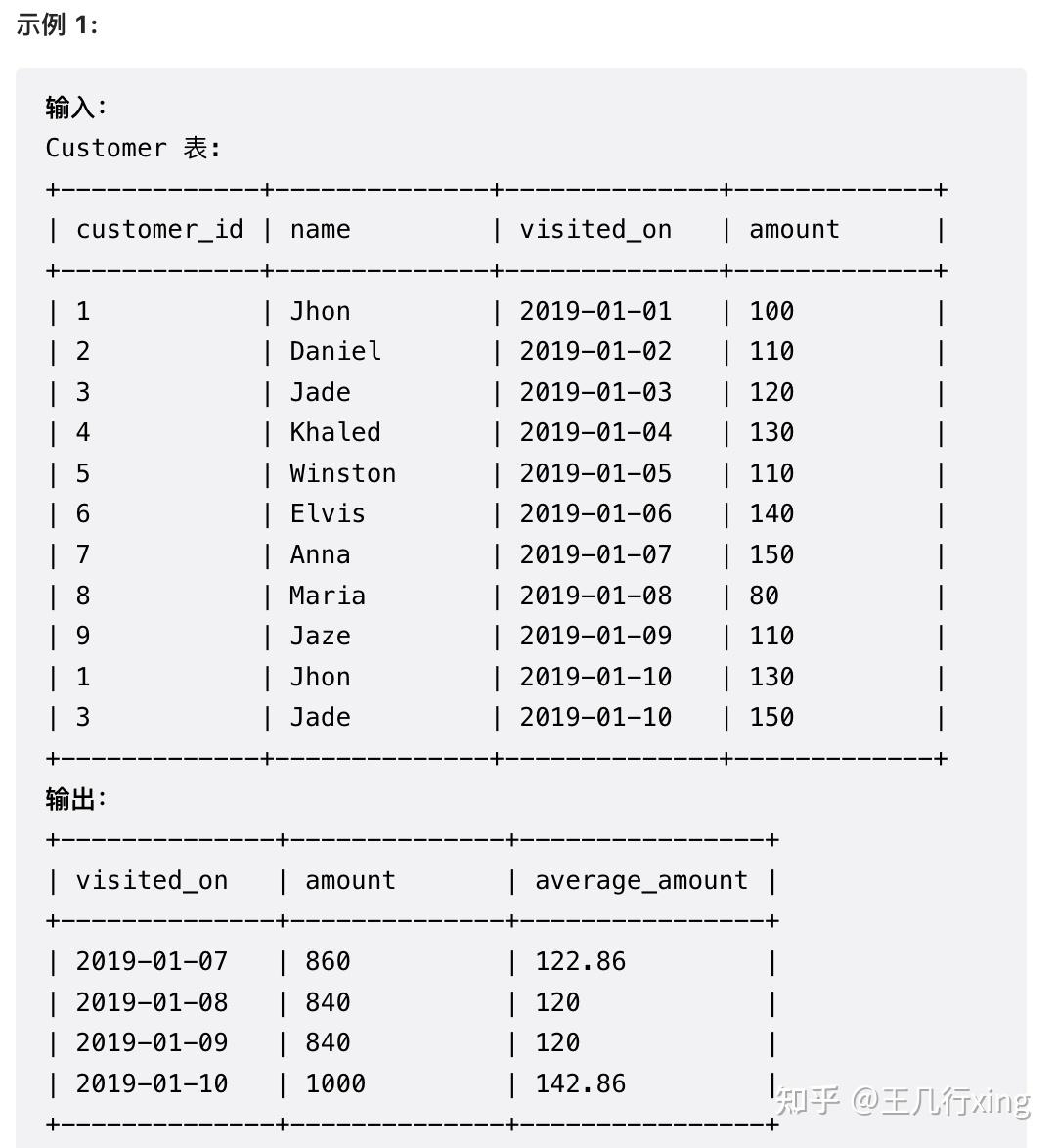
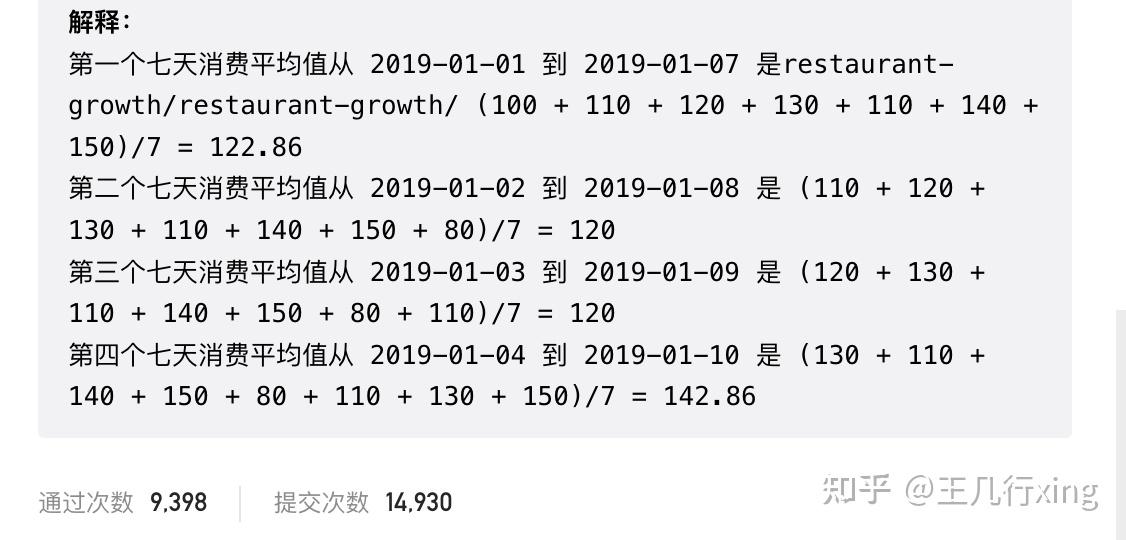
要求:计算前七天的顾客移动平均消费额
思路:
第一步,先按天汇总营业额
with t1 as
( select visited_on, sum(amount) amount from Customer
group by visited_on) 第二步,窗口函数计算移动消费总额,和移动平均消费额
## 1321M - 移动平均消费额
with t1 as
( select visited_on, sum(amount) amount from Customer
group by visited_on)
select visited_on,
sum(amount) over(order by visited_on rows 6 preceding) amount,
round(avg(amount) over(order by visited_on rows 6 preceding), 2) average_amount
from t1此时,我们还应该在最后加一个起始日期条件——这个日期,必须满足前面至少有6天。正如默认案例中,从1.1 - 1.7, 1.7才是第一个开始计算移动平均的日期:
## 1321M - 移动平均消费额
with t1 as
( select visited_on, sum(amount) amount from Customer
group by visited_on)
select * from
(select visited_on,
sum(amount) over(order by visited_on rows 6 preceding) amount,
round(avg(amount) over(order by visited_on rows 6 preceding), 2) average_amount
from t1) t2
where datediff(visited_on, (select min(visited_on) from Customer)) >=6;67 - 615M - 平均工资:部门与公司比较 Average Salary Department vs Company


要求:部门的平均工资 vs 公司的平均工资
思路:
- 利用case when 来生成 ”higher“等;
- distinct paymont, deparment_id;
- salary left join t2,salary 表中的 Employee 可能没有department 信息(经测试,inner join 也通过)
# 615M 平均工资:部门与公司比较
select distinct date_format(pay_date, &#34;%Y-%m&#34;) pay_month, department_id,
case when avg(amount) over(partition by department_id, pay_date)
> avg(amount) over(partition by pay_date) then &#34;higher&#34;
when avg(amount) over(partition by department_id, pay_date)
< avg(amount) over(partition by pay_date) then &#34;lower&#34;
else &#34;same&#34; end comparison
from salary t1
left join employee t2 using(employee_id)
order by pay_month desc, department_id ## 可以不排序68 - 1127H - 用户购买平台 User Purchase Platform
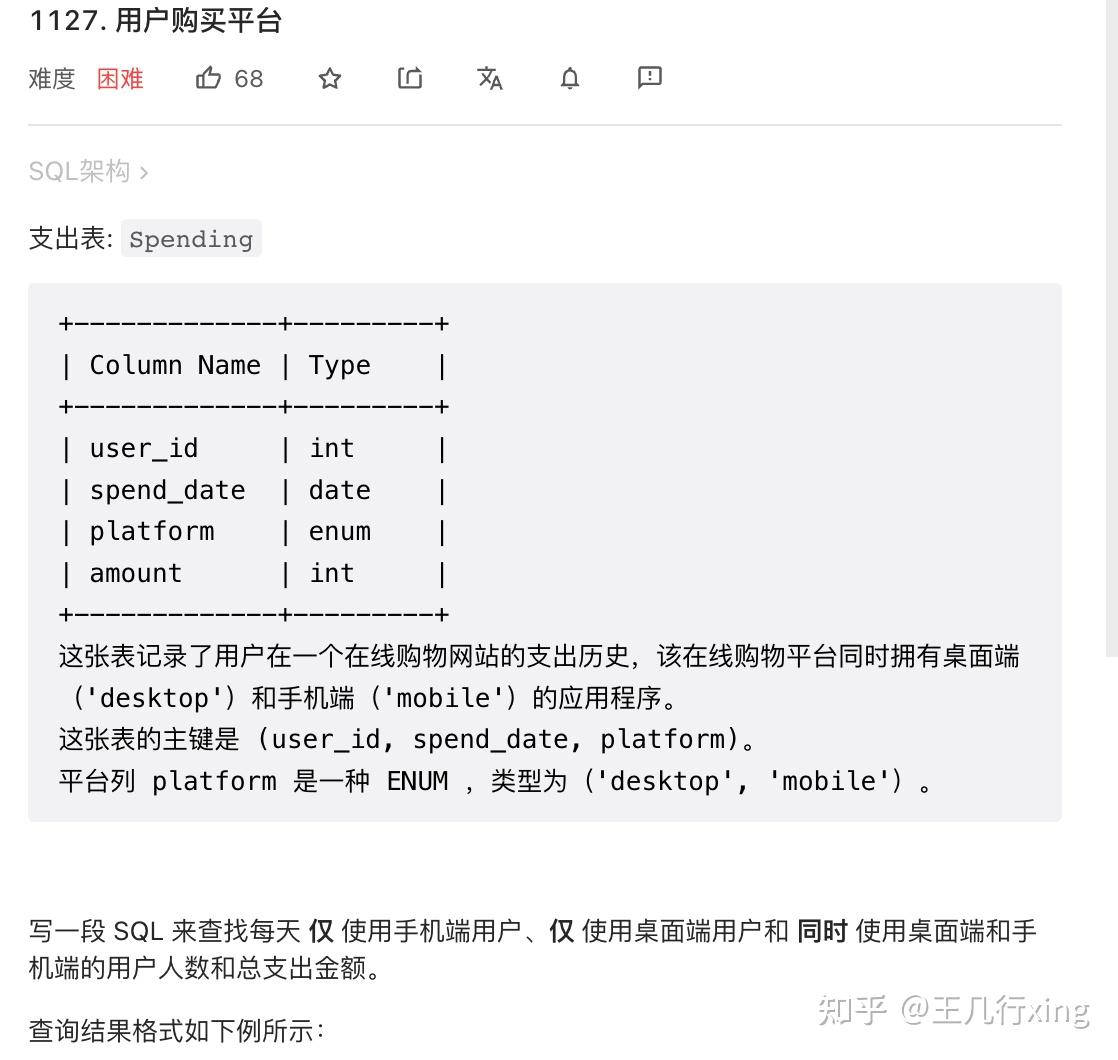
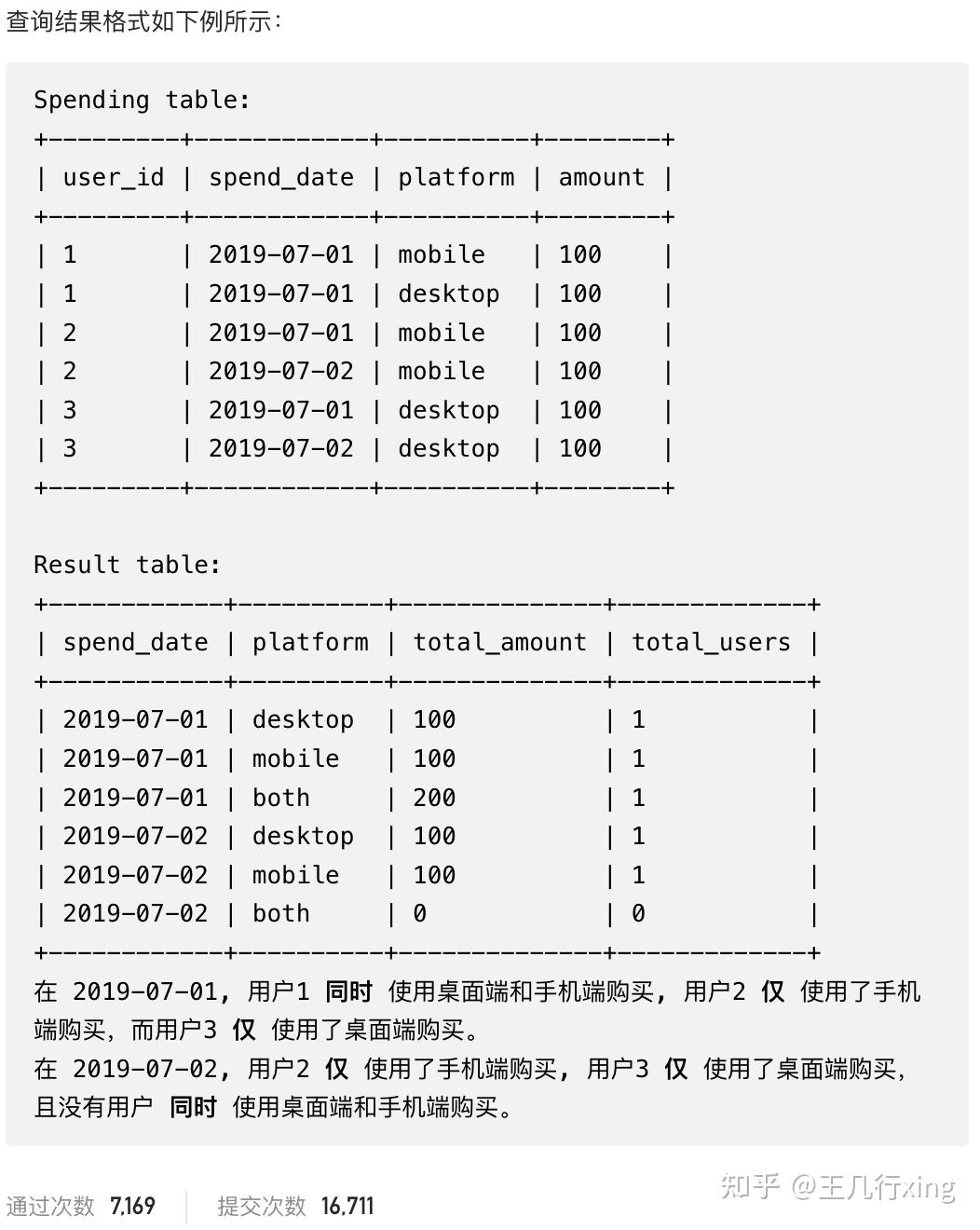
要求:查找每天仅手机、仅桌面端、两者同时购买的客户人数和总支出金额
思路:
第一步,构造完整的各种可能情况的表格:
select distinct spend_date, &#39;desktop&#39; platform from spending
union
select distinct spend_date, &#39;mobile&#39; from spending
union
select distinct spend_date, &#39;both&#39; from spending 得到的结果如下:
[&#34;spend_date&#34;, &#34;platform&#34;],
[[&#34;2019-07-01&#34;, &#34;desktop&#34;],
[&#34;2019-07-02&#34;, &#34;desktop&#34;],
[&#34;2019-07-01&#34;, &#34;mobile&#34;],
[&#34;2019-07-02&#34;, &#34;mobile&#34;],
[&#34;2019-07-01&#34;, &#34;both&#34;],
[&#34;2019-07-02&#34;, &#34;both&#34;]]第二步,以 id 和 日期分组,如果组内有2中不同的购买平台,就更改为”both“:
select user_id, spend_date,
if(count(distinct platform) = 2, &#39;both&#39;, platform) platform, -- 符合这种情况的才叫 both
sum(amount) amount
from Spending
group by user_id, spend_date 得到结果如下:
[&#34;user_id&#34;, &#34;spend_date&#34;, &#34;platform&#34;, &#34;amount&#34;],
[[1, &#34;2019-07-01&#34;, &#34;both&#34;, 200],
[2, &#34;2019-07-01&#34;, &#34;mobile&#34;, 100],
[2, &#34;2019-07-02&#34;, &#34;mobile&#34;, 100],
[3, &#34;2019-07-01&#34;, &#34;desktop&#34;, 100],
[3, &#34;2019-07-02&#34;, &#34;desktop&#34;, 100]]}第三步,将 cte1 和 cte2 基于(spend_date, platform) left join,
# 1127H - 用户购买平台
with cte1 as (
select distinct spend_date, &#39;desktop&#39; platform from spending
union
select distinct spend_date, &#39;mobile&#39; from spending
union
select distinct spend_date, &#39;both&#39; from spending),
cte2 as
(
select user_id, spend_date,
if(count(distinct platform) = 2, &#39;both&#39;, platform) platform, -- 符合这种情况的才叫 both
sum(amount) amount
from Spending
group by user_id, spend_date)
select cte1.spend_date, cte1.platform,
ifnull(sum(cte2.amount), 0) total_amount,
ifnull(count(cte2.user_id),0) as total_users -- 7.2 哪天没有 both 的情况
from cte1
left join cte2 using(spend_date, platform)
group by cte1.spend_date, cte1.platform
# order by cte1.spend_date, cte1.platform结果如下:
[&#34;spend_date&#34;, &#34;platform&#34;, &#34;total_amount&#34;, &#34;total_users&#34;],
[[&#34;2019-07-01&#34;, &#34;desktop&#34;, 100, 1],
[&#34;2019-07-02&#34;, &#34;desktop&#34;, 100, 1],
[&#34;2019-07-01&#34;, &#34;mobile&#34;, 100, 1],
[&#34;2019-07-02&#34;, &#34;mobile&#34;, 100, 1],
[&#34;2019-07-01&#34;, &#34;both&#34;, 200, 1],
[&#34;2019-07-02&#34;, &#34;both&#34;, 0, 0]]}
69 - 601M 体育馆的人流量 Human Traffic of Stadium
要求:查询每行的人数大于或等于100且id连续的三行或更多行记录
思路:
- 组序 - 组间序,然后分组,个数>=3 即可
- 第一步,构造分组的 rnk;
- 第二步,基于 rnk 相同的分组,进行窗口函数计数 id (people > 99);
- 第三步,选出 cnt >= 3 的记录,即连续天数大于等于3的记录
## 601M 体育馆的人流量
## 连续三行人数大于等于 100
select id, visit_date, people
from (
select *, count(*) over(partition by rnk) cnt
from(
select *, id - row_number() over(order by id) rnk
from Stadium
where people >= 100
) t1
) t2
where t2.cnt >= 3
order by visit_date
70 - 595E Big Countries 大的国家
这个题目是真的容易。
# Write your MySQL query statement below
select name, population, area
from World
where population >= 25000000 or area >= 3000000; 71 - 1757E Recyclable and Low Fat Products 可回收且低脂的产品
# Write your MySQL query statement below
select product_id
from Products
where recyclable = &#39;Y&#39; and low_fats = &#39;Y&#39;;<hr/> 72 - 183E Customers Who Never Order 从不订购的客户
# Write your MySQL query statement below
select Name as Customers
from Customers
where Customers.Id not IN
(
select Customers.Id
from Customers, Orders
where Customers.Id = Orders.CustomerId
)
# 551 ms我们试着写简洁一点,时间缩短了一些。
# Write your MySQL query statement below
select Name as Customers
from Customers
where Id not in (
select CustomerId
from Orders
)
# 523 msAnyway,in 后面的嵌套查询本就不需要进行量表的合并。
73 - 1873E - Calculate Special Bonus 计算特殊奖金
判断奇数:mod(employee_id, 2) = 1
# Write your MySQL query statement below
select employee_id,
case when mod(employee_id,2) = 1 and name not like &#39;M%&#39; then salary
else 0
end as bonus
from Employees
order by employee_id;
# 585 ms这里 name not like &#39;M%&#39;我们还可以换个写法LEFT(name,1)!=&#39;M&#39;:
# Write your MySQL query statement below
select employee_id,
case when mod(employee_id,2) = 1 and LEFT(name,1)!= &#39;M&#39; then salary
else 0
end as bonus
from Employees
order by employee_id;
# 665 ms可惜运行时间变长了一点。
74 - 627E - Swap Salary 交换性别
这个题英文版本的标题起的有点奇怪了。
# Write your MySQL query statement below
update Salary
set sex =
case
when sex=&#39;m&#39; then &#39;f&#39;
when sex=&#39;f&#39; then &#39;m&#39;
end 75 - 196E Delete Duplicate Emails 删除重复的电子邮箱
在Stata或者Excel等统计软件中,删除重复是个很常规的操作。而 SQL 实现这个功能,通常依赖表与本身的合并。
思路是比较奇特,可惜空间复杂度就得翻倍了?
delete p1
from Person p1, Person p2
where p1.email = p2.email and p1.id > p2.id; 76 - 1787E - Fix Name in a Table 修复表中的名字
此题考查的是字符串的处理:
- 取出姓名的首字母:left(name, 1)
- 转换为大写:upper()
- 转换为小写:lower()
- 截取字符串,从第二位开始:substr(name, 2)
# Write your MySQL query statement below
select user_id, concat(upper(left(name, 1)), lower(substr(name, 2))) as name
from Users
order by user_id;77 - 1484E - Group Sold Product by The Day 按日期分组销售产品
考点:多列转行,逗号隔开。MySQL 中 用:
- group_concat() 函数实现;
- 加上 DISTINCT 去重
# Write your MySQL query statement below
select user_id, concat(upper(left(name, 1)), lower(substr(name, 2))) as name
from Users
order by user_id;78 - 1965E -Employees with Missing Information 丢失信息的雇员
解题思路:
- 选择两个表的 employee_id 列进行合并:UNION ALL
- 然后计数该列,输出 count=1 的 employee_id
select employee_id
from
(
select employee_id from Employees
UNION ALL
select employee_id from Salaries
) as tmp
group by employee_id
having count(*) = 1
order by employee_id; 79 - 1795E Rearrange Products Table 每个产品在不同商店的价格
考点:宽数据 -> 长数据
这里如果该价格为空,那么该条记录不存在。
思路:将store1/store2/store3 逐一转换,并进行直接合并 UNION。
select product_id, &#39;store1&#39; store, store1 as price
from products
where store1 is not NULL
UNION
select product_id, &#39;store2&#39; store, store2 as price
from products
where store2 is not NULL
UNION
select product_id, &#39;store3&#39; store, store3 as price
from products
where store3 is not NULL;
写在最后
- 有空就多复习,每题尽量做 4遍以上,以达到熟悉的程度;
- 刷完LeetCode 的70个精选题,就可以正式开始面试了,至于其它题可以边找边刷;
- 如果能熟悉做完 LeetCode 上面的数据库题,相比你的SQL查询能力,肯定能超越 99% 的同行。
=====全文结束===== |
|


 发表于 2023-1-18 15:22:02
发表于 2023-1-18 15:22:02