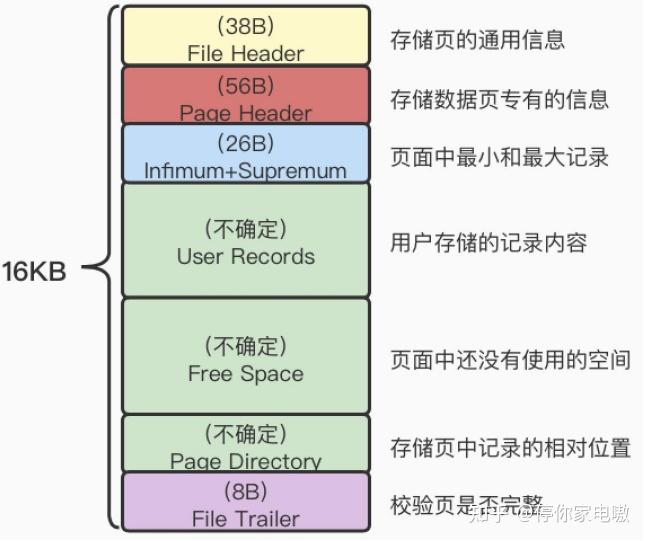
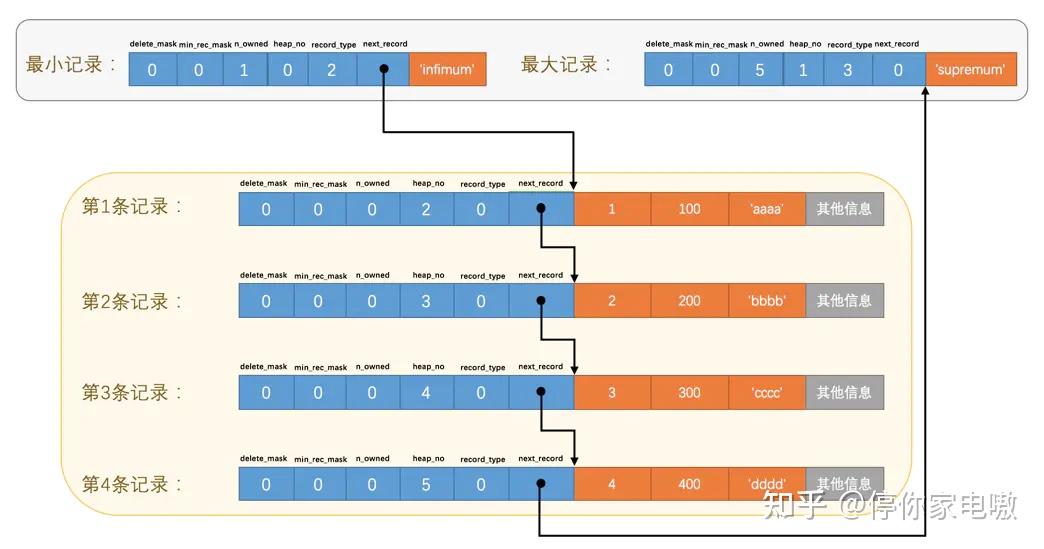
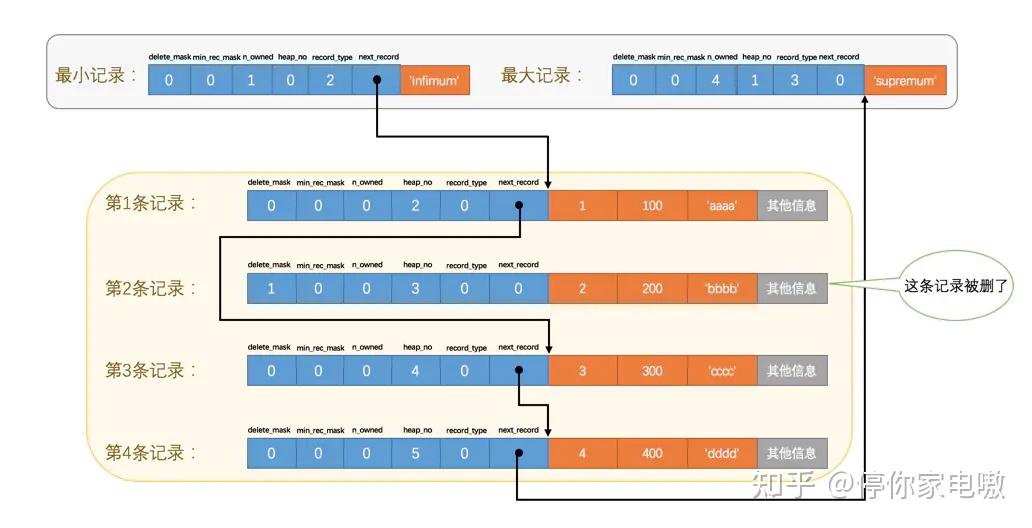
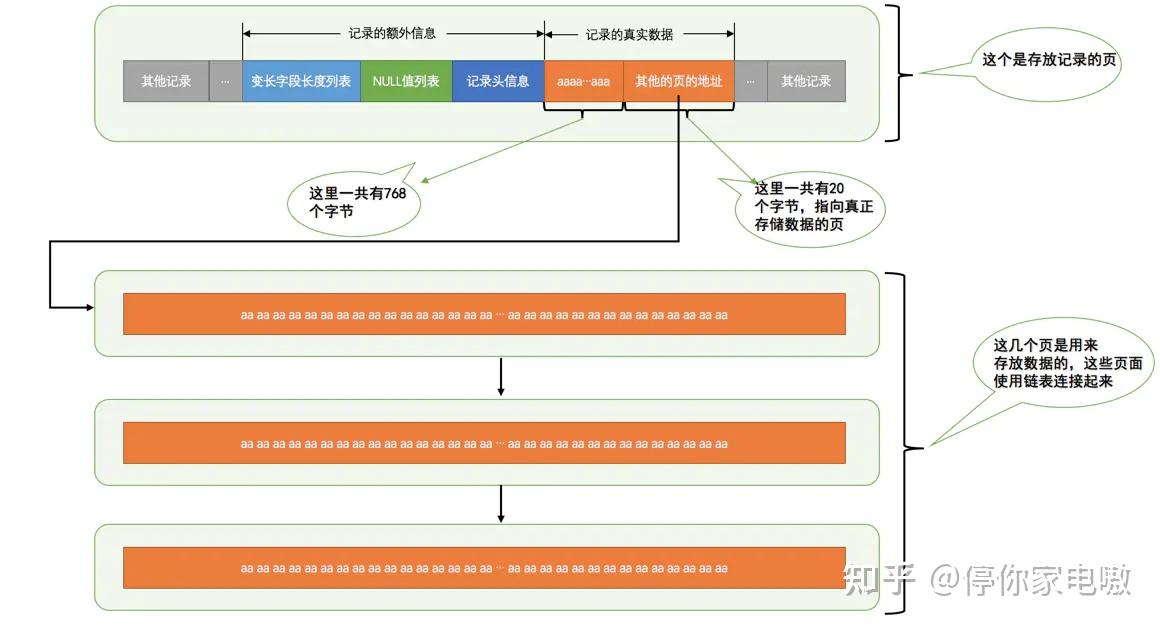
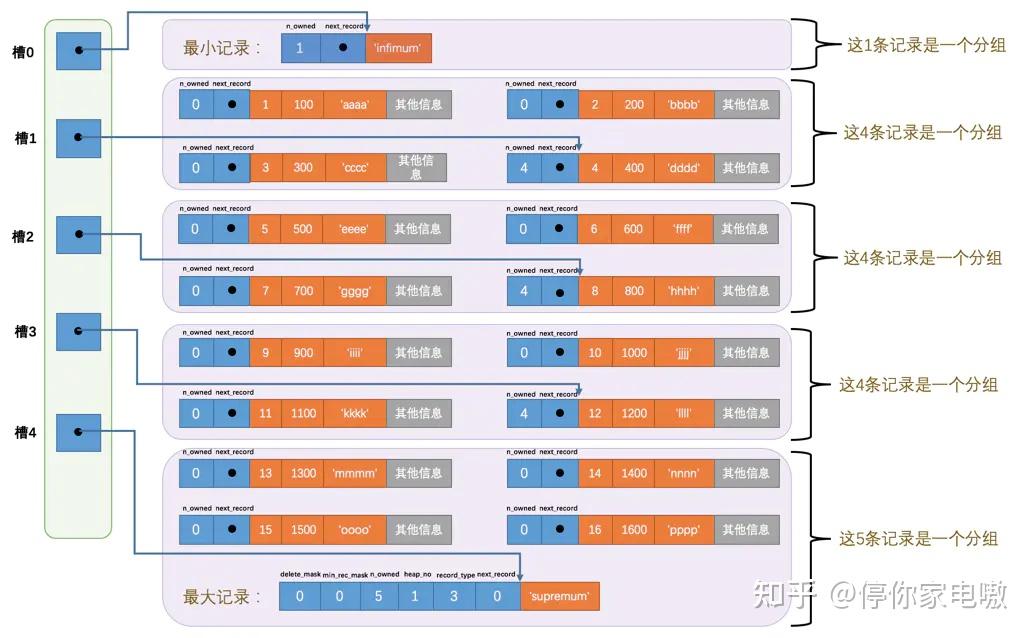
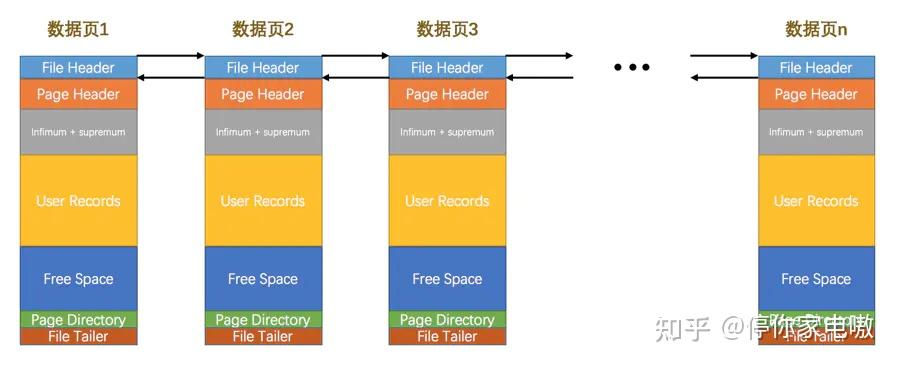
| 名称 | 占用空间大小 | 描述 |
| PAGE_N_DIR_SLOTS | 2字节 | 在页目录中的槽数量 |
| PAGE_HEAP_TOP | 2字节 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
| PAGE_N_HEAP | 2字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE | 2字节 | 第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
| PAGE_GARBAGE | 2字节 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2字节 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2字节 | 最后一条记录插入的方向 |
| PAGE_N_DIRECTION | 2字节 | 一个方向连续插入的记录数量,如果最后一条记录的插入方向改变了的话,这个状态的值会被清零重新统计。 |
| PAGE_N_RECS | 2字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2字节 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8字节 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |


 发表于 2023-1-18 02:47:45
发表于 2023-1-18 02:47:45