|
|
- 数据库简介
- 数据:用来保存信息的符号
- 数据库:用来保存数据的仓库,在计算机里面就是一个文件夹,硬盘上是使用文件来存放数据
- 数据库管理系统:用来管理数据库的软件系统,如:MySql,Oracle等
- 数据库应用系统:基于数据库研发的应用软件。
- 数据库的三范式
第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列)
例如:一张学生表里面,将学生姓名和学号写在一起。违反了第一范式属性列中不能有可以再分的列
第二范式(2NF):满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键;完全依赖是针对于联合主键的情况,非主键列不能只依赖于主键的一部分)
例如:第二范式主要是针对联合索引
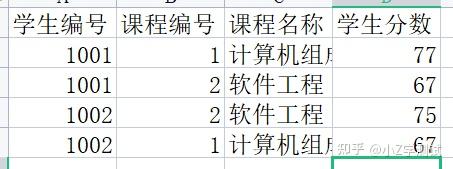
比如这个表里,学生编号和课程编号建立联合索引,学生分数依赖于这两个索引才能查出,而课程名称只依赖于课程编号就可以查出,这样是不符合第二范式的。
第三范式(3NF):满足第二范式;且不存在传递依赖,即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。(A -> B, B ->C, A -> C)
简单来说表中不能有循环依赖:即B列依赖于A列,而C列依赖与B列
- 操作数据库
- 连接数据库
- 使用navicat来连接数据库#官网上下载有14天免费试用,或者网上找破解版的
--连接本地的mysql数据库:mysql -uroot -p
--连接本地的非默认端口的Mysql数据库如:mysql -uroot -p -P3307
--连接远程服务器上面的mysql数据库如:mysql -uroot -p -h192.168.1.1
--连接远程服务器上面的非默认端口的MySQL数据库如:mysql -uroot -p -h192.168.1.1 -P3307
- 库操作
- 建库:CREATE DATABASE 数据库名charset = ‘utf-8’
- 模糊查询:show DATABASE like ‘%a%’
- 查看创建了哪些数据库:show databases
- 删除数据库:drop database 数据库名;
- 查看数据库的版本和状态select VERSION();
- 查看mysql实例当前进程:show processlist;
- 表操作
- 创建表
Create table 表名(
列名1 char(32),
列名2 varchar(64)
)
例如:
CREATE TABLE class1(
name CHAR(32), #字符类型、字符长度
age INT(3)
);
#mysql数据类型:
#现在是讲一些基础的mysql知识。这一块主要是了解,mysql不同的类型存储不同的数据。因为在测试过程中测试工程师基本没有权限去建表的,做接口测试的时候
字符长度和字符类型都会在接口文档中标记清楚。后面会再出一期对字符类型数据类型进行深入研究。现在先凑合看吧。
1、 数值类型
整数类型包括 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,浮点数类型包括 FLOAT 和 DOUBLE,定点数类型为 DECIMAL。
2、日期/时间类型
包括 YEAR、TIME、DATE、DATETIME 和 TIMESTAMP。
3、字符串类型
包括 CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET 等。
4、二进制类型
包括 BIT、BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。
#约束
约束就是在建表的时候对每一列填入的数据做出规定。比如不能为空、必须唯一等等。
1、非空约束(not null):约束的字段不能为null
2、唯一约束(unique):约束的字段不能重复
3、唯一且非空(unique not null)
例子:
CREATE TABLE student3(
num int(11) UNIQUE not null ,#列的唯一约束,学号不能重复
name VARCHAR(255) not null,#非空约束
age int,
birth char(10)
);
4、主键约束(primary key):约束的字段既不能为null,也不能重复。
主键特点:主键字段中的数据不能为null,也不能重复。
例子:
CREATE TABLE student4(
num int(11)PRIMARY KEY,#主键约束唯一且不重复
name VARCHAR(255) not null,#非空约束
age int,
birth char(10)
);
5、主键自增长(auto_increment):
填入数据的时候主键栏可以不用填写,自动增长
例子:
CREATE TABLE student5(
num int(11)PRIMARY KEY auto_increment,#主键约束唯一且不重复,主键自增长
name VARCHAR(255) not null,#非空约束
age int,
birth char(10)
);
6、外键约束(foreign key):
将本表的某个字段与外表的某个字段相关联,外键不一定是主键,且可以为空,但一定要有unique约束
语法:foreign key(本表的值) references 外表名(外表的值)
例如以学生表和班级表为例:
CREATE TABLE student_1(
num int(11) PRIMARY KEY auto_increment,#主键约束唯一且不重复,主键自增长
name VARCHAR(255) not null,#非空约束
s_cno int,
foreign key(s_cno) references class_1(cno),
age int
);
CREATE TABLE class_1(
cno int PRIMARY KEY,
cname VARCHAR(255)
)
- 显示所有表
show tables;
- 查看表结构
desc 表名;
- 给表新增一列
ALTER TABLE 表名 ADD 新列名 数据类型 约束条件
- 给表删除一列
ALTER TABLE 表名 DROP 列名
- 删除表
#删除表
drop table student1
- 表数据的增删改查(CRUD)
- 新增数据
Insert into 表名(列1,列2,列3)values(值1,值2,值3)
例如:INSERT INTO student5(num,name,age) VALUES(3,'李小狼',12);
- 删除数据
- 清空表数据
#清空表数据
truncate table 表名
- 清空表数据
DELETE FROM 表名
- 按条件删除表数据
DELETE FROM 表名 where 条件
DELETE FROM student5 where num = 3
- 修改表数据
UPDATE 表名 set 列名=值where 条件
UPDATE student5 set num=1 where num=3
- 查询表数据
- 全表查询
Select * from 表名
- 查询固定的字段
Select 列名1,列名2... from 表名
- 查询表里有多少条数据
Select count(1) from 表名
- 排序
Select * from 表名 order by 列名1 desc(降序)#根据列名1进行排序后面可以继续接列名二,第一遍排序之后再进行第二遍排序
Select * from 表名 order by 列名 asc(升序)#不写asc和desc默认升序
- 区间查询
Select * from 表名 limit 5,3 #从第6列开始查,查询3行
Select * from 表名 age betwee 0 and 100 #年龄从0到100岁之间的人
- 条件查询
Select * from 表名 where 条件
例如 select * from student where name =‘张三’
=等于 < ,>,<=,>=,!=不等于
- 去重
Select distinct 列名 from 表名
Select distinct name from student5
- 模糊查询
Select * from 表名 where 列名 like ‘%字符%”
%三 匹配 张三、张四三等
三% 匹配 三千、三万
%三% 匹配 张三风 刘三姐姐 等
- In
例如查询表中年龄为12、24、33的人
Select * from 表名 where age in(12,24,33)
- 数据库中的函数使用
- 取绝对值ABS
Select ABS(列名) from 表名
- 取整foolr、ceil
- 取比原值小的整数
Select foolr(列名) from 表名; 例如3.9->3 ,-3.9->-4
- 取比原值大的整数
Select ceil(列名) from 表名; 例如:3.9->3,-3.9->-3
- 取四舍五入ROUND、TRUNCATE
ROUND(列名) #取四舍五入值
例如:SELECT ROUND(birth) from student5;
ROUND(列名,2)#取字段后的2位小数,但要四舍五入
例如:SELECT ROUND(birth,2) from student5;
TRUNCATE(列名,2))#取字段后的2位小数,不会四舍五入
- 查询字符=x的字段,LENGTH
select * from 表名 where length(字段名)=x
例如:
SELECT * from student5 where LENGTH(name)=9;#查询字符长度为9的数据
SELECT LENGTH(name) from student5;#查询字符长度
- 字符串长度截取substring、substr
Substring(列名,x,y)莫列从第x位截取长度为y的字段
- 时间查询
SELECT CURDATE();#查询当前时间
#计算两段时间相差多少天TIMESTAMPDIFF
SELECT TIMESTAMPDIFF(day,&#39;2023-12-11&#39;,&#39;2023-12-01&#39;);
- MD5加密
SELECT MD5(name) FROM student5;
只能在select中出现
- 基础
- COUNT(X) 统计个数
- Max(x)取最大值
- Min(x)取最小值
- Sum(x)求和x只能为数字型
- Avg(x) 求平均值
- 分组
Group by 根据表中的某个元素进行分组
SELECT * FROM student5 GROUP BY age;
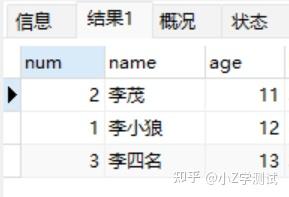
这样我们只能知道年龄包含有11,12,13但是这些年龄具体都有谁就不知道了这就要用到下面的函数
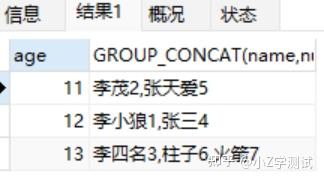
Group_concat
SELECT age,GROUP_CONCAT(name,num) FROM student5 GROUP BY age;
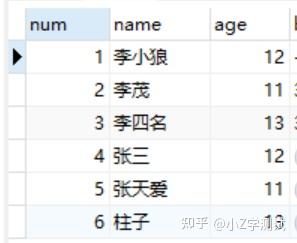
筛选出不同年龄姓李的同学
Select * from student5 group by age having name like ‘李%’
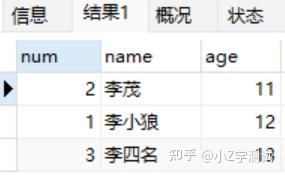
#having在mysql中也是可以单独使用的,用法作用和where一样
Select * from student5 having name like &#39;张%&#39;
- 多表查询
- 简单连表查询
Select * from A表,B表 where A.字段=B.字段
- 连接查询
- 内连接
Select * from 表A inner join表B on A.字段=B.字段 where 条件
- 左外连接
以A表为基础
Select * from 表A left join 表B on A.字段=B.字段 where 条件
- 右外连接
以B表为基础
Select * from 表A right join 表B on A.字段=B.字段 where 条件
- 直连
Select * from 表A join 表B on A.字段=B.字段 where 条件
- 自连接
Select * from A as a ,A as b where a.n=b.n
- 非等值连接
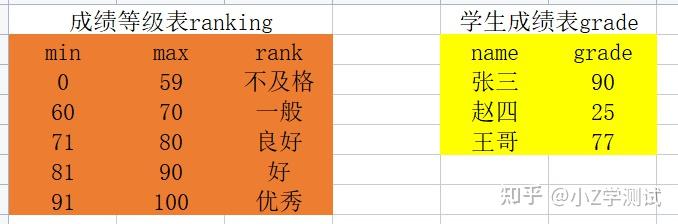
Select * from ranking a,grade b where b.grade between a.min and a.max
- 全连接
A 表有,B 表没有的数据(显示为 null),同样 B 表有,A 表没有的显示为 null。
select * from 表A full join 表B on 判断条件;
- 交叉连接笛卡尔积(cross join)
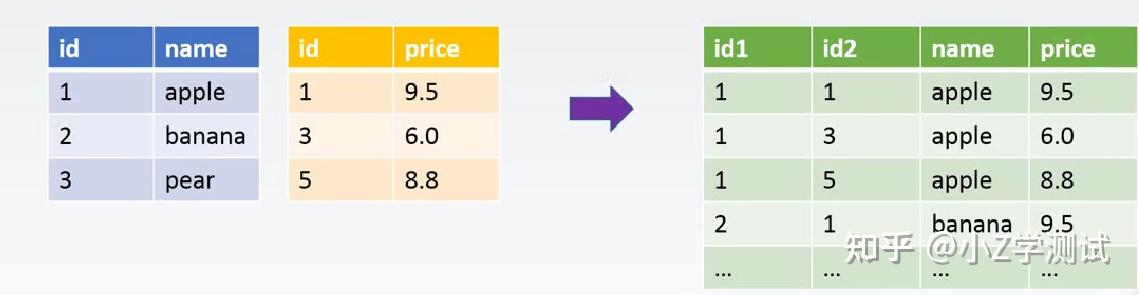
Select * from 表a cross join 表b
将你sql执行的结果生成一张虚拟的表
- 创建视图
Create view 视图名 as sql语句
- 查询
Select * from 视图名
- 修改
Alter view 视图名 as 修改后的sql语句
- 删除
Drop view 视图名
#mysql线上编辑:http://mysql.jsrun.net
- 常见面试题
- sql语句执行顺序
SQL语句执行顺序:FROM、ON 、JOIN、WHERE、GROUP BY、AGG_FUNC、WITH、HAVING、SELECT、UNION、DISTINCT 、ORDER BY、LIMIT。
1、FROM:选择FROM后面跟的表,产生虚拟表1。
2、ON:ON是JOIN的连接条件,符合连接条件的行会被记录在虚拟表2中。
3、JOIN:如果指定了LEFT JOIN,那么保留表中未匹配的行就会作为外部行添加到虚拟表2中,产生虚拟表3。如果有多个JOIN链接,会重复执行步骤1~3,直到处理完所有表。
4、WHERE:对虚拟表3进行WHERE条件过滤,符合条件的记录会被插入到虚拟表4中。
5、GROUP BY:根据GROUP BY子句中的列,对虚拟表4中的记录进行分组操作,产生虚拟表5。
6、AGG_FUNC:常用的 Aggregate 函数包涵以下几种:(AVG:返回平均值)、(COUNT:返回行数)、(FIRST:返回第一个记录的值)、(LAST:返回最后一个记录的值)、(MAX: 返回最大值)、(MIN:返回最小值)、(SUM: 返回总和)。
7、WITH 对虚拟表5应用ROLLUP或CUBE选项,生成虚拟表 6。
8、HAVING:对虚拟表6进行HAVING过滤,符合条件的记录会被插入到虚拟表7中。
9、SELECT:SELECT到一步才执行,选择指定的列,插入到虚拟表8中。
10、UNION:UNION连接的两个SELECT查询语句,会重复执行步骤1~9,产生两个虚拟表9,UNION会将这些记录合并到虚拟表10中。
11、DISTINCT 将重复的行从虚拟表10中移除,产生虚拟表 11。DISTINCT用来删除重复行,只保留唯一的。
12、ORDER BY: 将虚拟表11中的记录进行排序,虚拟表12。
13、LIMIT:取出指定行的记录,返回结果集。
2、数据库的三范式
详见文章开头
3、sql优化
1、查询的时候避免全表扫描,考虑在where以及order by 设计的列上建立索引。
#索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。这里先记住就是提高检索效率的一种方式就好了,这块涉及到数据结构比如hash,b+树,后面有时间再出这块笔记。Java面试问到数据库这块也会问道索引失效怎么解决。
- 应尽量避免在where子句中使用!=或<>,or连接,模糊查询,in和not in(能用between就少用in)否则将视为放弃索引,进行全表扫描
- 尽量避免select * 这种操作,最好具体到字段
#后面面试了对与这块的面试题再补充 |
|


 发表于 2023-1-17 11:52:56
发表于 2023-1-17 11:52:56