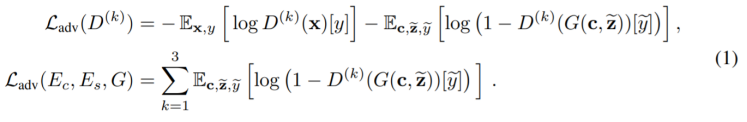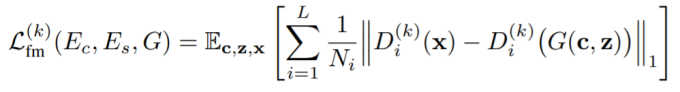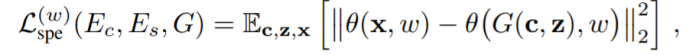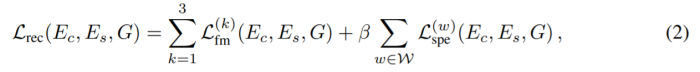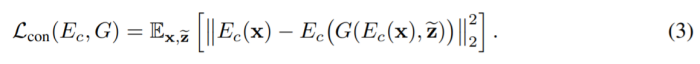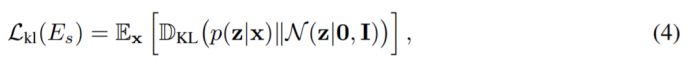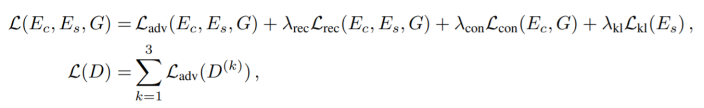设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
NET
›
NVC-Net——基于GAN的端到端Voice Conversion
返回列表
发帖
查看:
125
|
回复:
1
NVC-Net——基于GAN的端到端Voice Conversion
[复制链接]
空仓静定
空仓静定
当前离线
积分
3
1
主题
3
帖子
3
积分
新手上路
新手上路, 积分 3, 距离下一级还需 47 积分
新手上路, 积分 3, 距离下一级还需 47 积分
积分
3
发消息
发表于 2023-1-7 20:23:06
|
显示全部楼层
|
阅读模式
本文未经允许禁止转载,谢谢合作。作者:Light Sea@知乎
本文我将介绍一篇来自索尼的工作:NVC-Net,一个近期比较好的voice conversion的工作,实验证明它可以以较少的参数量和较高的推论速度实现和AutoVC类似的表现。
原论文标题:<NVC-Net: End-to-End Adversarial Voice Conversion>
1.Introduction
作者提出NVC-Net,一个基于对抗训练的end-to-end的voice conversion模型 。NVC-Net的优势包括:(1)直接在waveform上进行训练,因此不需要依赖vocoder;(2)不需要平行语料;(3)完全基于CNN,因此可以进行高速voice conversion;(4)使用了KL regularization,因此提升了zero-shot VC的表现。 实验证明NVC-Net相比之前的方法实现了高质量且高速的VC。
2.Method
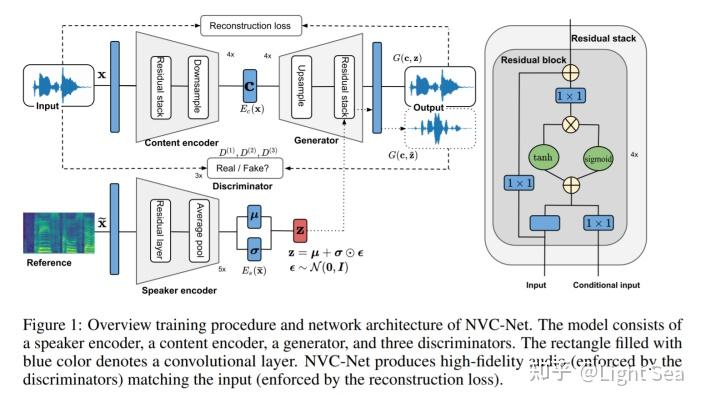
NVC-Net的architecture如下图所示:
它包含下面几个部分:
content encoder E_{c}
speaker encoder E_{s}
generator G
discriminator D^{(k)}, k=1,2,3
设输入的语音为x,作者假设x=G(z, c)由两个latent embedding生成,第一个z是speaker embedding,第二个c是content embedding。从直觉上来说content embedding中应该包含所有和speaker无关的信息,比如语音的内容。
2.1 Objectives
我们首先来看模型的损失函数,你将会看到,NVC-Net的loss和笔者之前介绍的HiFi-GAN有很多类似之处。 由于用了对抗训练,因此第一个loss为GAN的loss:
第二个loss为reconstruction loss。作者首先使用了HiFi-GAN中的feature matching loss:
这个loss计算了真实和合成语音在判别器的不同layer的feature map输出之间的L1 loss。 然后是spectral loss,同样也和HiFi-GAN类似:
\theta(x, w)计算了FFT size为w时x的梅尔频谱。 最终的reconstruction loss为:
第三个loss为content preservation loss:
也就说不同speaker embedding但相同content embedding生成的语音的content embedding应该是相同的。这里\widetilde{z}是一个和x的speaker不同的speaker的embedding。 另外为了避免content embedding的值的影响,作者还对其进行了l2-norm。
第四个loss为Kullback-Leibler loss,这个loss的目的在于减少speaker embedding deviation对speaker embedding space的影响。作者最小化了speaker embedding的分布和一个标准高斯之间的KLD:
理解这个loss很简单,因为我们希望即使说话内容不同,但只要speaker相同,则两个输入得到的speaker embedding应该一样,上面的loss就能达到这样的效果。另外这也让sample新的speaker embedding变得更简单。
结合上述所有loss,我们就得到了NVC-Net的最终loss:
2.2 Architecture
原文中作者详述了网络的架构,这里笔者不多赘述,只说明大致的结构,感兴趣的读者可以参考原论文。
content encoder:使用了类似WaveNet的架构,基于dilated convolution。
speaker encoder:speaker encoder用梅尔频谱作为输入,然后使用一个residual CNN得到speaker embedding
generator:generator使用了和MelGAN类似的结构,包括4个上采样模块和4个residual blocks。
discriminator:使用了和HiFi-GAN中MSD类似的架构,这东西其实来自于MelGAN。
2.3 Data augmentation
作者使用了一系列不改变speaker信息的数据增强的方法,包括:
phase shifting
amplitude scaling
jitter
另外在将waveform输入到speaker encoder之前,作者会把waveform分成很多段,然后进行shuffle,作者发现这个方法可以增强speaker和content embedding之间的解耦。
3. Experiments
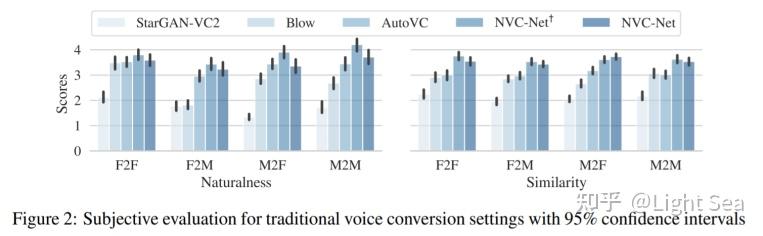
作者使用VCTK进行实验。 首先作者评价了seen speaker上的表现,结果如下图所示:
这里NVC-Net^{\dagger}是使用了one-hot speaker embedding的模型。 可以看到不论是naturalness还是similarity NVC-Net都有比之前的工作更好的表现。 作者还训练了一个speaker classifier来评价VC的效果,结果如下表所示:
可以看到NVC-Net的表现是最好的。
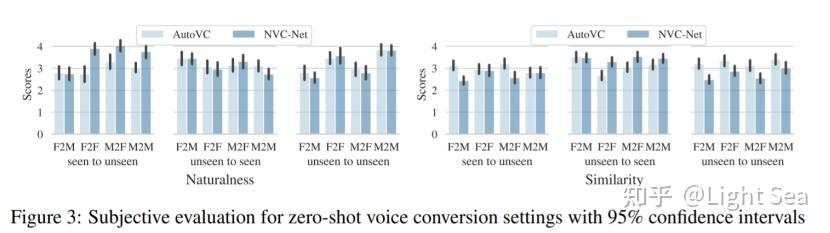
之后作者评价了zero-shot VC的表现,结果如下图所示:
可以看到在naturalness上NVC-Net和AutoVC的表现类似,但在similarity上仍然略逊一筹,作者认为这是因为AutoVC使用了在大规模数据集上训练的speaker encoder。
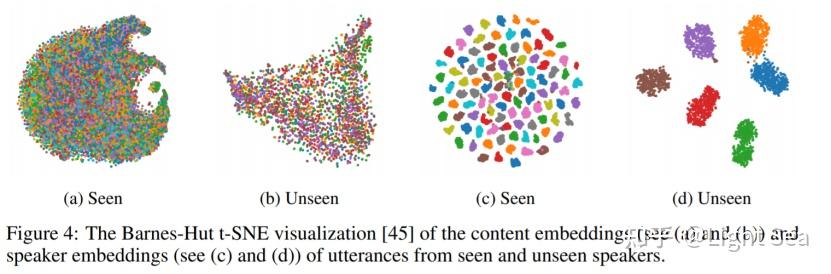
为了评价speaker和content解耦的表现,作者使用content和speaker embedding进行speaker classification,结果如下表所示:
可以看到效果是不错的。 作者也可视化了speaker和content embedding,如下图所示:
可以看到content embedding混在一起,而speaker embdding则分成了不同的cluster,这同样也证明了解耦的表现不错。
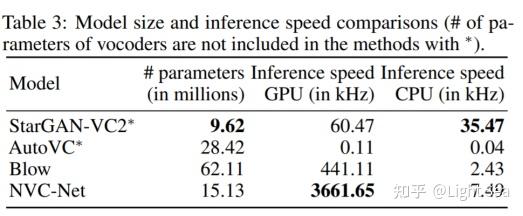
最后是推论的速度,如下表所示:
可以看到在GPU中NVC-Net有最快的速度,且相对AutoVC而言NVC-Net的参数更少,证明NVC-Net能以较少的参数量实现不错的表现。
4. Conclusions
本文我介绍了NVC-Net,一个基于对抗训练的end-to-end VC模型。NVC-Net直接在waveform上进行VC,因此不需要vocoder,且设计了多种loss来提升speaker和content的解耦。实验结果证明NVC-Net可以用较少的参数和更快的推论速度实现和AutoVC类似的表现。
创作不易,如果大家觉得有收获的话还请点赞喜欢收藏支持一下,你的支持就是我创作的动力。
回复
使用道具
举报
徐到徐学
徐到徐学
当前离线
积分
29
3
主题
15
帖子
29
积分
新手上路
新手上路, 积分 29, 距离下一级还需 21 积分
新手上路, 积分 29, 距离下一级还需 21 积分
积分
29
发消息
发表于 2023-1-7 20:23:25
|
显示全部楼层
占坑不开源斯基+1
回复
使用道具
举报
老六九弓长众
老六九弓长众
当前离线
积分
30
2
主题
14
帖子
30
积分
新手上路
新手上路, 积分 30, 距离下一级还需 20 积分
新手上路, 积分 30, 距离下一级还需 20 积分
积分
30
发消息
发表于 2025-12-15 14:57:50
|
显示全部楼层
OMG!介是啥东东!!!
回复
使用道具
举报
朕心甚慰
朕心甚慰
当前离线
积分
25
3
主题
12
帖子
25
积分
新手上路
新手上路, 积分 25, 距离下一级还需 25 积分
新手上路, 积分 25, 距离下一级还需 25 积分
积分
25
发消息
发表于 2025-12-15 15:40:52
|
显示全部楼层
在撸一遍。。。
回复
使用道具
举报
玲珑耳朵
玲珑耳朵
当前离线
积分
23
4
主题
11
帖子
23
积分
新手上路
新手上路, 积分 23, 距离下一级还需 27 积分
新手上路, 积分 23, 距离下一级还需 27 积分
积分
23
发消息
发表于 2025-12-15 18:30:35
|
显示全部楼层
我也顶起出售广告位
回复
使用道具
举报
任蛟龙
任蛟龙
当前离线
积分
21
2
主题
12
帖子
21
积分
新手上路
新手上路, 积分 21, 距离下一级还需 29 积分
新手上路, 积分 21, 距离下一级还需 29 积分
积分
21
发消息
发表于 2026-3-19 05:20:26
|
显示全部楼层
为毛老子总也抢不到沙发?!!
回复
使用道具
举报
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
PHP
易语言
C语言
JAVA
数据库
C++
快速回复
返回顶部
返回列表


 发表于 2023-1-7 20:23:06
发表于 2023-1-7 20:23:06