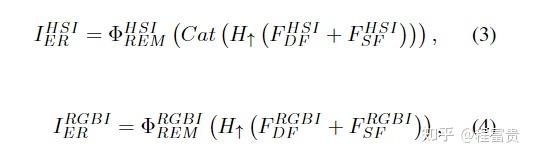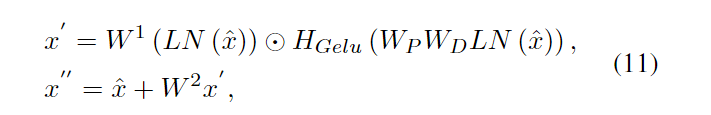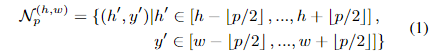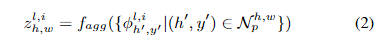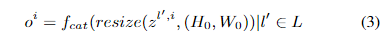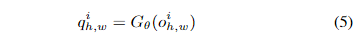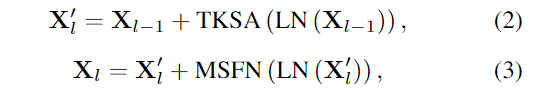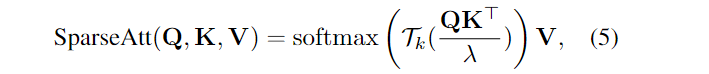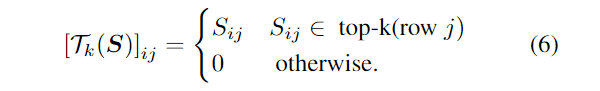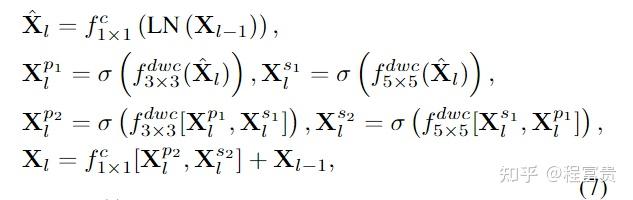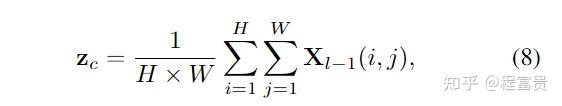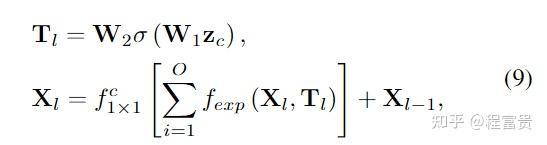设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
NET
›
2023.4.6组会总结
返回列表
发帖
查看:
135
|
回复:
1
2023.4.6组会总结
[复制链接]
短发二三年
短发二三年
当前离线
积分
4
1
主题
2
帖子
4
积分
新手上路
新手上路, 积分 4, 距离下一级还需 46 积分
新手上路, 积分 4, 距离下一级还需 46 积分
积分
4
发消息
发表于 2023-6-5 12:20:29
|
显示全部楼层
|
阅读模式
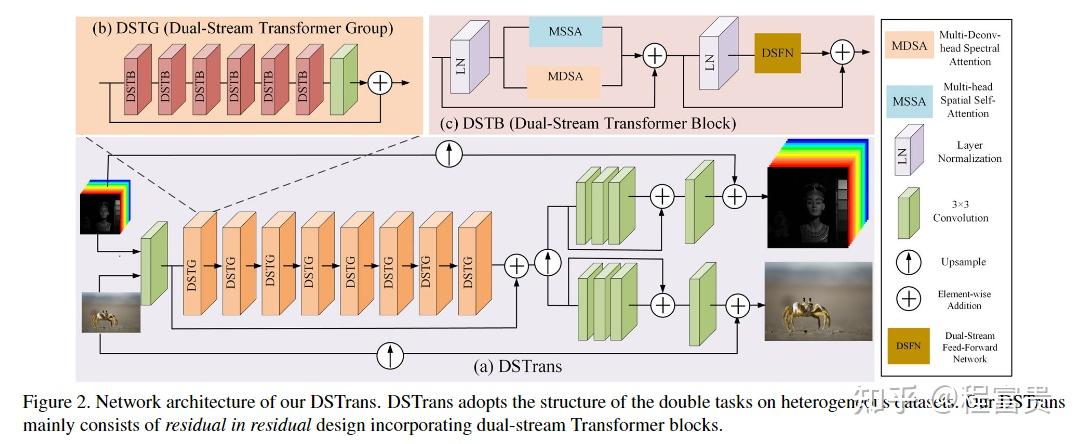
DSTrans: Dual-Stream Transformer for Hyperspectral Image Restoration
基于cnn的图像修复技术存在缺乏全局信息的缺点,基于Transformers的方法虽然可以通过自注意力对全局信息进行建模,但是其在应用方面存在一下几个问题:
1.缺乏高光谱图像的数据集,而Transformer需要大量的数据进行训练学习。
2.Transformer提供了长距离的空间建模能力,但是不能对高光谱图像的光谱间相关性进行建模。
DSTrans在异构数据集上一起学习两个相同的恢复任务,用RGB图像数据集作为辅助数据集,输入HSI和RGB都含有退化图像和高质量图像,因为我们希望从RGB图像中获取信息,所以RGB图像中高质量图像数目要大于HSI。
对于输入HSI对其brands进行划分,将其D个brands划分成S组,对于RGB通过插值策略将其channel增加至S,使HSI和RGB的shape相同。
对于输入的退化图像,先经过一个卷积层来获取浅层特征图,然后经过encoder(若干个DSTG),然后
以上表示residual enhancing modules,包含3个3×3卷积层和一个残差连接。
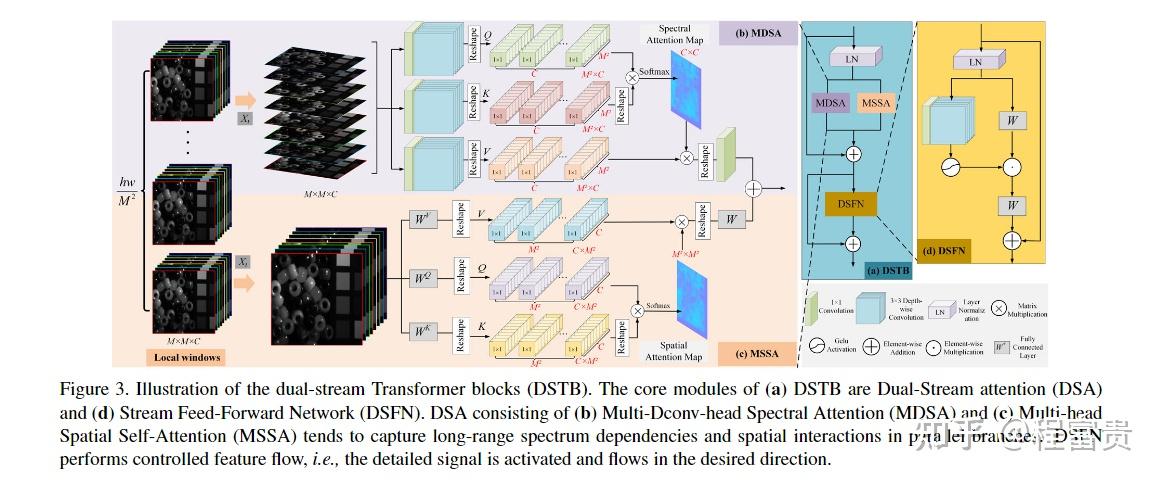
获取长程光谱相关性和建模全球空间相互作用同样至关重要。因此,我们提出了由多头空间自注意(MSSA)和多头光谱注意(MDSA)组成的双流注意,分别在空间和光谱维度上对长程依赖性进行建模。
DSFN:
3D UX-NET: A LARGE KERNEL VOLUMETRIC CON-VNET MODERNIZING HIERARCHICAL TRANSFORMER FOR MEDICAL IMAGE SEGMENTATION
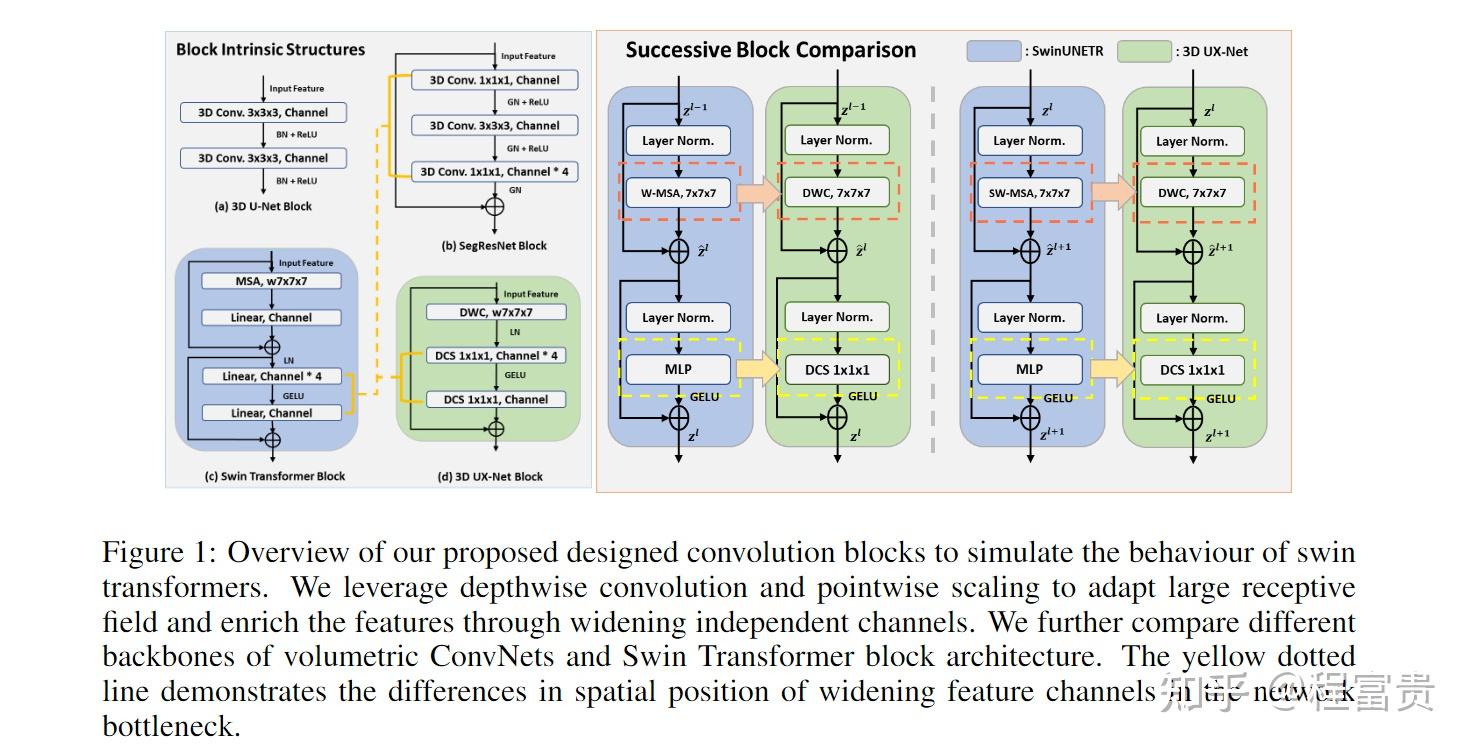
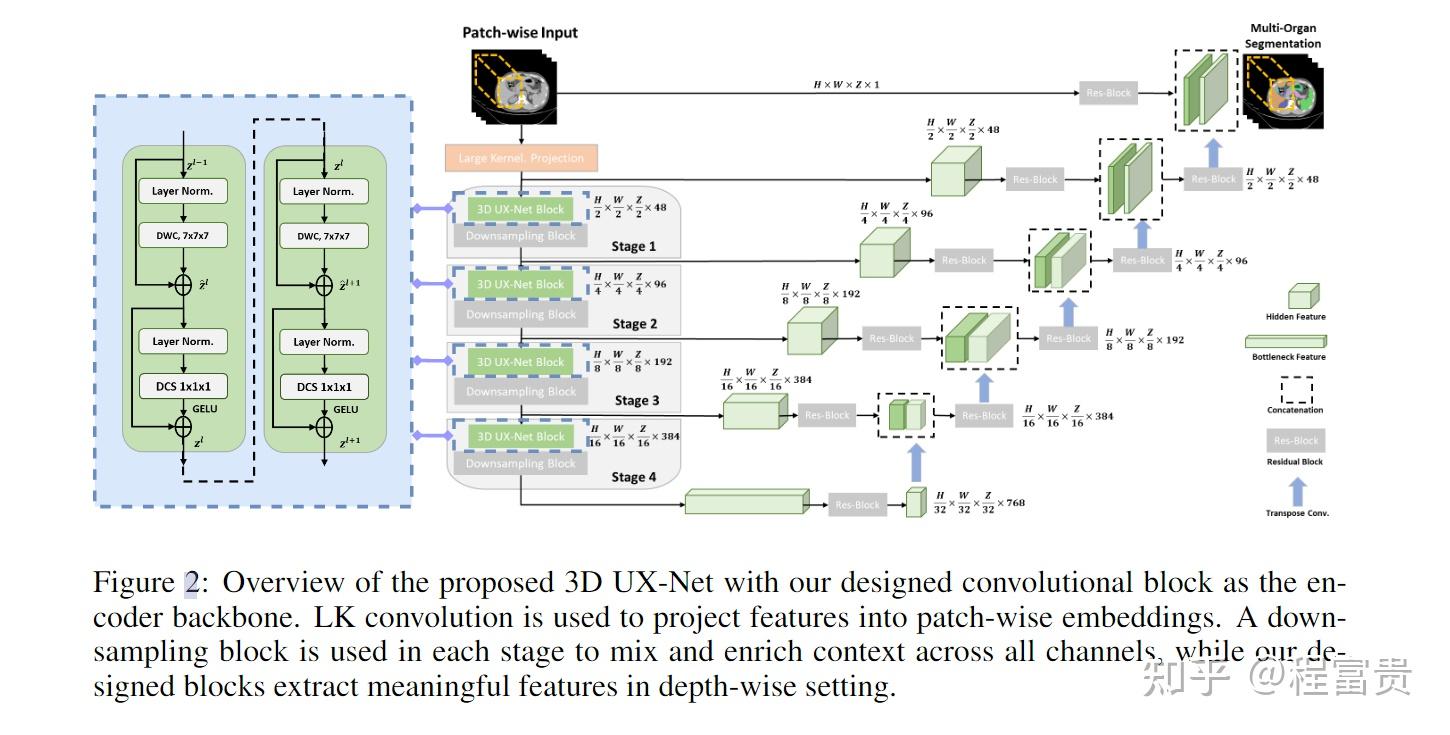
3D医学ViT在几个3D体积数据基准上实现了最先进的性能。基于ViT和ConvNet的混合方法具有很强的有效性,其具有非局部注意力的大感受野和大量的模型参数。假设使用深度卷积可以来模拟大感受野效果,本文提出了一种轻量级的体积ConvNet,称为3D UX-Net,它使用ConvNet模块对分层变换器进行自适应,以实现稳健的体积分割。受Swin Transformer的启发,本文重新审视了具有大内核(LK)大小(例如,从7×7×7开始)的体积深度卷积,以实现更大的全局感受野。我们进一步用逐点深度卷积取代了Swin Transformer块中的多层感知器(MLP),并用更少的归一化和激活层来增强模型性能,从而减少了模型参数的数量。
本文的贡献:
1.提出了3D UX-Net,在体积设置中纯粹利用ConvNet模块来适应transformer行为。
2.我们利用具有LK大小的深度卷积作为通用特征提取主干,并引入逐点深度卷积,以较少的参数有效地缩放提取的表示。
SimpleNet: A Simple Network for Image Anomaly Detection and Localization
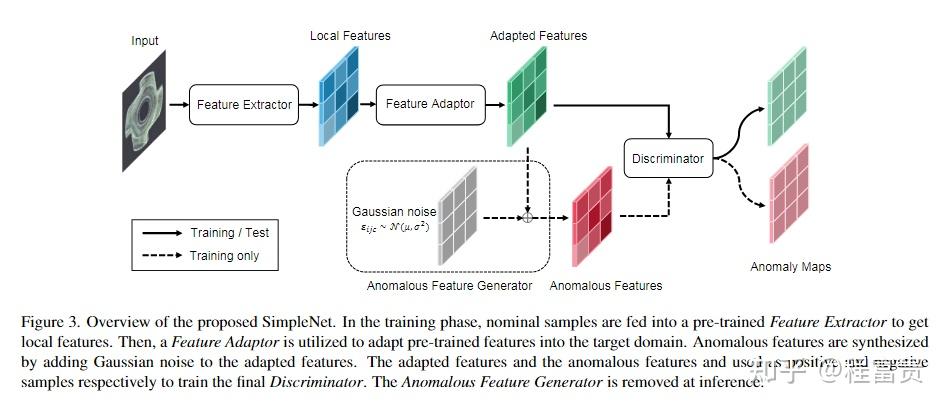
SimpleNet的四个组件:(1)生成局部特征的预训练特征提取器,(2)向目标域传输局部特征的浅层特征适配器,(3)通过向正常特征添加高斯噪声来伪造异常特征的简单异常特征生成器(4)将异常特征与正常特征区分开来的二进制异常鉴别器。
在推理过程中,异常特征生成器将被丢弃。首先,将预先训练的特征转换为面向目标的特征有助于避免领域偏见。其次,在特征空间中生成合成异常更有效,因为缺陷在图像空间中可能没有太多共性。第三,一个简单的鉴别器是非常有效和实用的。
SimpleNet由一个特征提取器、一个特征适配器、一个异常特征生成器和一个鉴别器组成。异常特征生成器仅在训练期间使用。
特征提取器:
对于位置(h,w)邻域定义如上,其中p为patchsize
特征适配器:
由于工业图像通常与骨干预训练中使用的数据集具有不同的分布,我们采用特征适配器Gθ将训练特征转移到目标域。
特征适配器可以由简单的神经块组成,例如全连接层或多层感知器(MLP)。我们通过实验发现,单个全连接层可以产生良好的性能。
异常特征生成器:
异常特征是在正常特征 q_{h,w}^{i} 添加高斯噪声来生成的。
鉴别器:
鉴别器 D_{ψ} 作为正态性记分器,直接估计每个位置(h,w)的正态性。鉴别器期望正常特征的正输出,而异常特征的负输出。我们只需像普通分类器一样使用双层多层感知器(MLP)结构,将正态性估计为 D_{ψ} ( q_{h,w} )∈R。
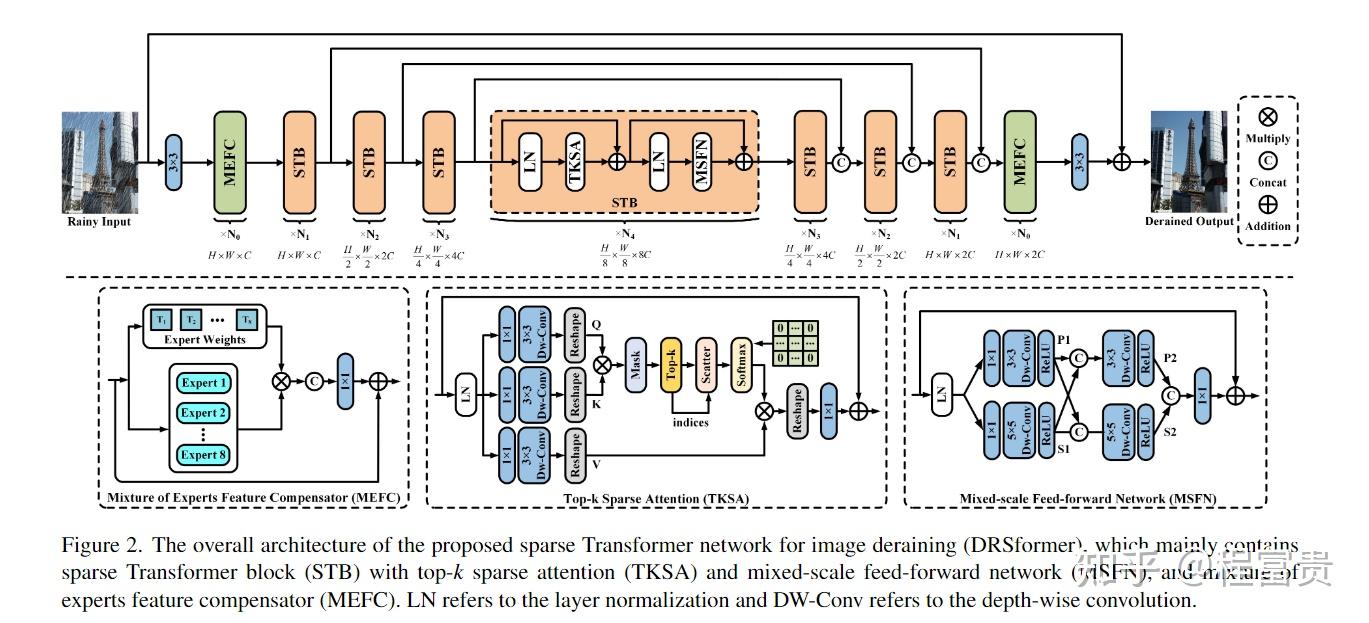
Learning A Sparse Transformer Network for Effective Image Deraining
基于CNN的图像去雨方法由于卷积具有局部的感受野和输入内容的独立性,阻碍了消除长程降雨退化扰动的能力。基于Transformer的方法,可以更好地对非局部信息进行建模,以进行高质量的图像重建,然而,基于Transformer的方法在恢复清晰的图像时,图像细节不能很好地建模。Transformer通常使用基于查询密钥对的所有注意力关系来聚合特征。由于来自密钥的令牌并不总是与来自查询的令牌相关,因此在特征聚合中使用从这些令牌估计的自关注值会干扰随后的潜在清晰图像恢复。
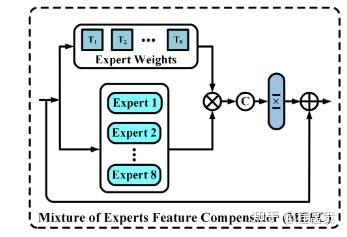
为了克服这个问题,我们提出了一种有效的训练网络,稀疏变换器(DRSformer),它可以自适应地保持最有用的自注意值用于特征聚合,以便聚合的特征更好地促进高质量的图像重建。具体而言,我们开发了一种可学习的top-k选择算子,以自适应地保留每个查询的关键点中最关键的注意力分数,从而实现更好的特征聚合。同时,由于Transformers中的朴素前馈网络没有对潜在清晰图像恢复重要的多尺度信息进行建模,我们开发了一种有效的混合尺度前馈网络,以生成更好的图像去噪特征。为了学习一组丰富的混合特征,它结合了CNN的局部上下文,我们在我们的模型中配备了混合专家特征补偿器,以提出一种合作细化去细化方案。
本文贡献:
1.我们提出了一种稀疏Transformer架构,以帮助生成具有更准确细节和纹理恢复的高质量去噪结果。
2.我们开发了一种简单而有效的可学习top-k选择算子,以自适应地保持最有用的自注意值,从而实现更好的特征聚合。
3.我们设计了一种基于混合尺度融合策略的有效前馈网络,以探索多尺度表示,从而更好地促进图像去噪。
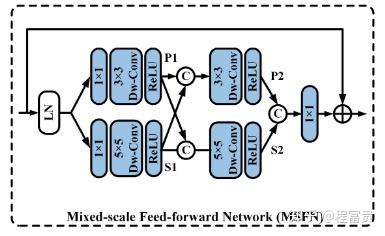
稀疏变换块(STB)为本文方法的基本构建单元,它主要包含两个关键元素:top-k稀疏注意力(TKSA)和混合规模前馈网络(MSFN)。最后,我们介绍了引入的专家混合特征补偿器(MEFC)。
STB:
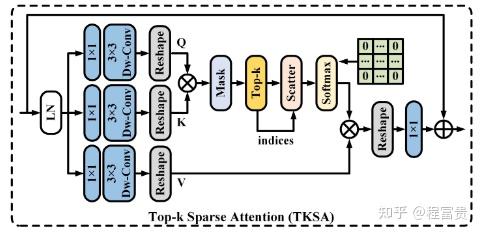
TKSA:
Tk(·)是可学习的top-k选择算子。
MSFN:
混合专家特征补偿器:
回复
使用道具
举报
韶华易逝
韶华易逝
当前离线
积分
26
2
主题
13
帖子
26
积分
新手上路
新手上路, 积分 26, 距离下一级还需 24 积分
新手上路, 积分 26, 距离下一级还需 24 积分
积分
26
发消息
发表于 2025-10-9 20:33:12
|
显示全部楼层
前排顶,很好!
回复
使用道具
举报
扛着犁耙闯天下
扛着犁耙闯天下
当前离线
积分
28
3
主题
14
帖子
28
积分
新手上路
新手上路, 积分 28, 距离下一级还需 22 积分
新手上路, 积分 28, 距离下一级还需 22 积分
积分
28
发消息
发表于 2025-12-15 12:47:07
|
显示全部楼层
没人回帖。。。我来个吧
回复
使用道具
举报
剑虹
剑虹
当前离线
积分
32
3
主题
19
帖子
32
积分
新手上路
新手上路, 积分 32, 距离下一级还需 18 积分
新手上路, 积分 32, 距离下一级还需 18 积分
积分
32
发消息
发表于 2026-3-19 04:00:40
|
显示全部楼层
路过的帮顶
回复
使用道具
举报
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
PHP
易语言
C++
C语言
数据库
JAVA
快速回复
返回顶部
返回列表


 发表于 2023-6-5 12:20:29
发表于 2023-6-5 12:20:29