设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
NET
›
NeurIPS 2022 | HUMUS-Net:用于加速MRI重建的混合展开 ...
返回列表
发帖
查看:
242
|
回复:
1
NeurIPS 2022 | HUMUS-Net:用于加速MRI重建的混合展开 ...
[复制链接]
对影成双
对影成双
当前离线
积分
39
7
主题
18
帖子
39
积分
新手上路
新手上路, 积分 39, 距离下一级还需 11 积分
新手上路, 积分 39, 距离下一级还需 11 积分
积分
39
发消息
发表于 2023-1-19 08:44:33
|
显示全部楼层
|
阅读模式
一句话总结
HUMUS-Net:一种基于Transformer和CNN的混合网络,用于加速MRI重建,其在fastMRI数据集上表现SOTA!代码已开源!收录于NeurIPS 2022!
点击关注@CVer计算机视觉,第一时间看到最优质、最前沿的CV、AI工作~
点击进入—>
医疗影像和Transformer微信技术交流群
HUMUS-Net
HUMUS-Net: Hybrid Unrolled Multi-scale Network Architecture for Accelerated MRI Reconstruction
单位:南加大
代码:https://github.com/z-fabian/HUMUS-Net
论文:https://openreview.net/forum?id=z0M3qHDqH20
在加速MRI重建中,患者的解剖结构是从一组欠采样和噪声测量中恢复的。深度学习方法已被证明能够成功地解决这一病态逆问题,并能够产生非常高质量的重建。然而,当前的架构严重依赖卷积,卷积与内容无关,并且难以对图像中的长期依赖关系进行建模。最近,Transformer,当代自然语言处理的主力,已经成为大量视觉任务的强大构建块。这些模型将输入图像拆分为不重叠的patch,将patch嵌入到低维标记中,并利用注意力自机制,该机制不会受到上述卷积架构弱点的影响。然而,当1)输入图像分辨率很高和2)当图像需要拆分成大量patch以保留精细细节信息时,Transformer会招致极高的计算和内存成本,这两者都是MRI重构等低层视觉问题的典型特征,具有复合效应。为了应对这些挑战,我们提出了HUMUS-Net,这是一种混合架构,将卷积的有益隐性偏见和效率与展开的多尺度网络中Transformer块的力量相结合。
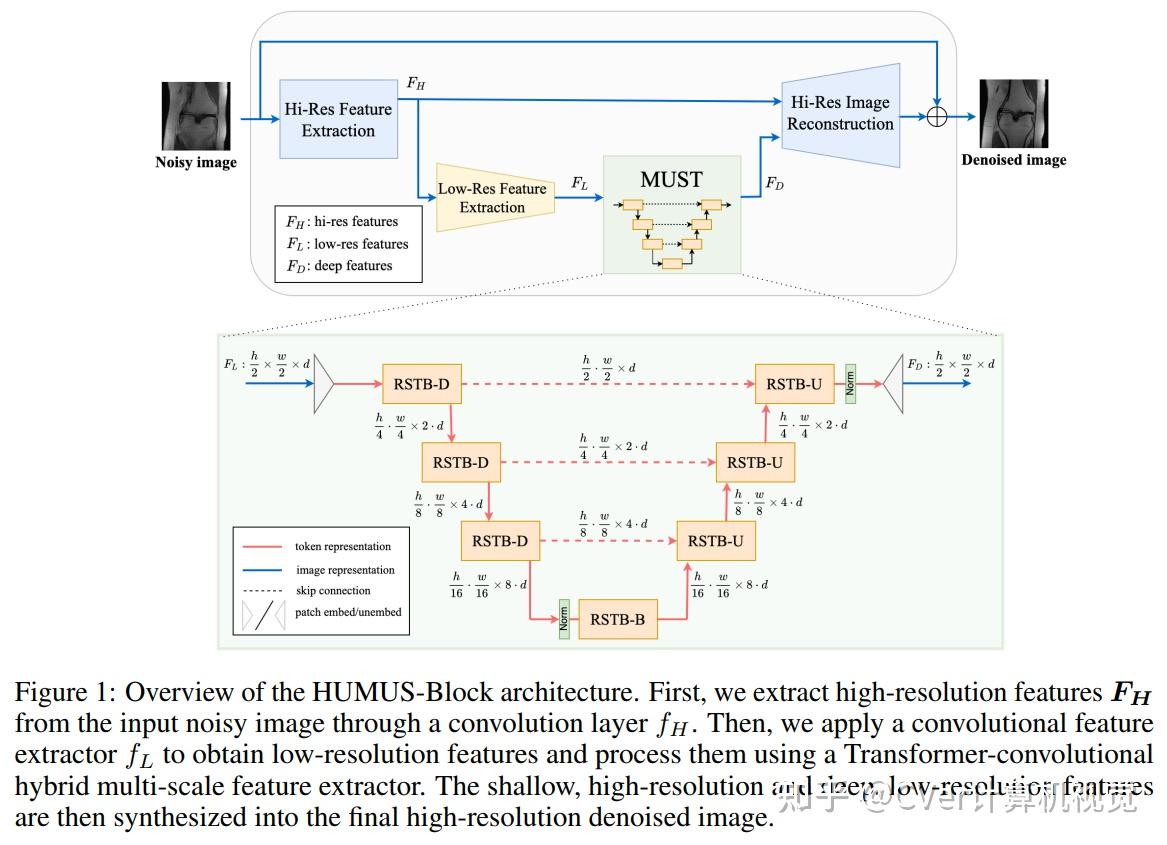
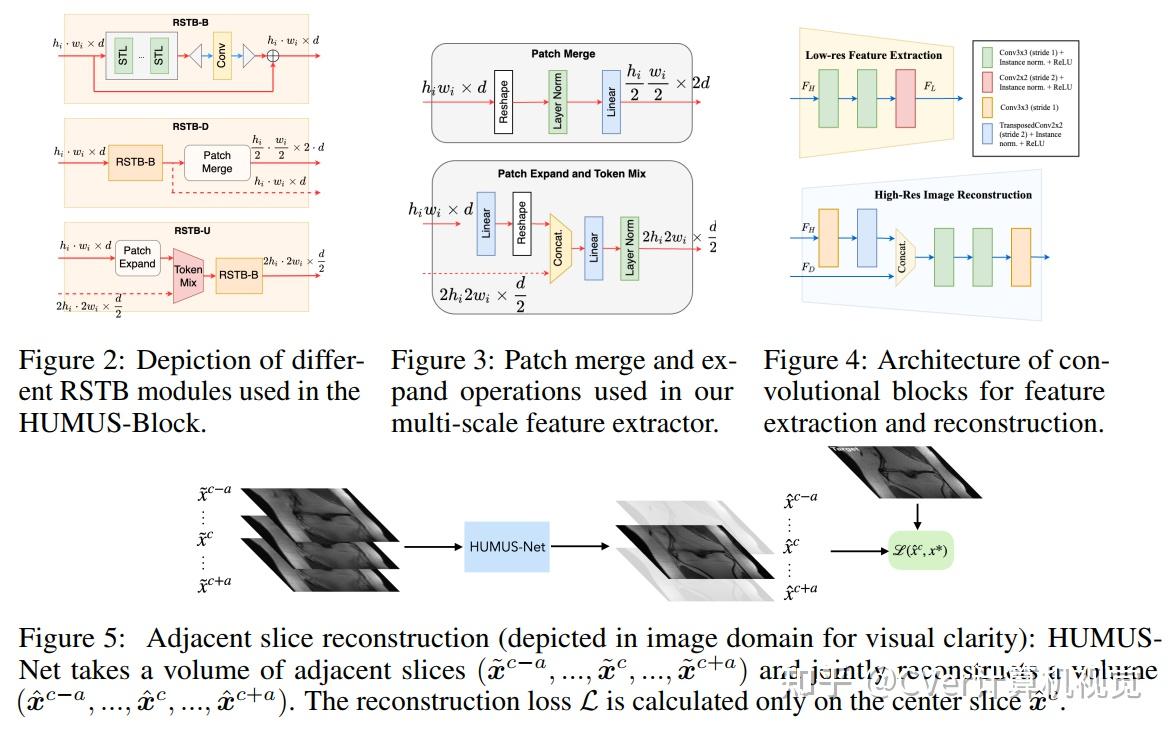
HUMUS-Net通过卷积块提取高分辨率特征,并通过新颖的基于Transformer的多尺度特征提取器细化低分辨率特征。然后将两个级别的特征合成为高分辨率输出重构。
算法细节
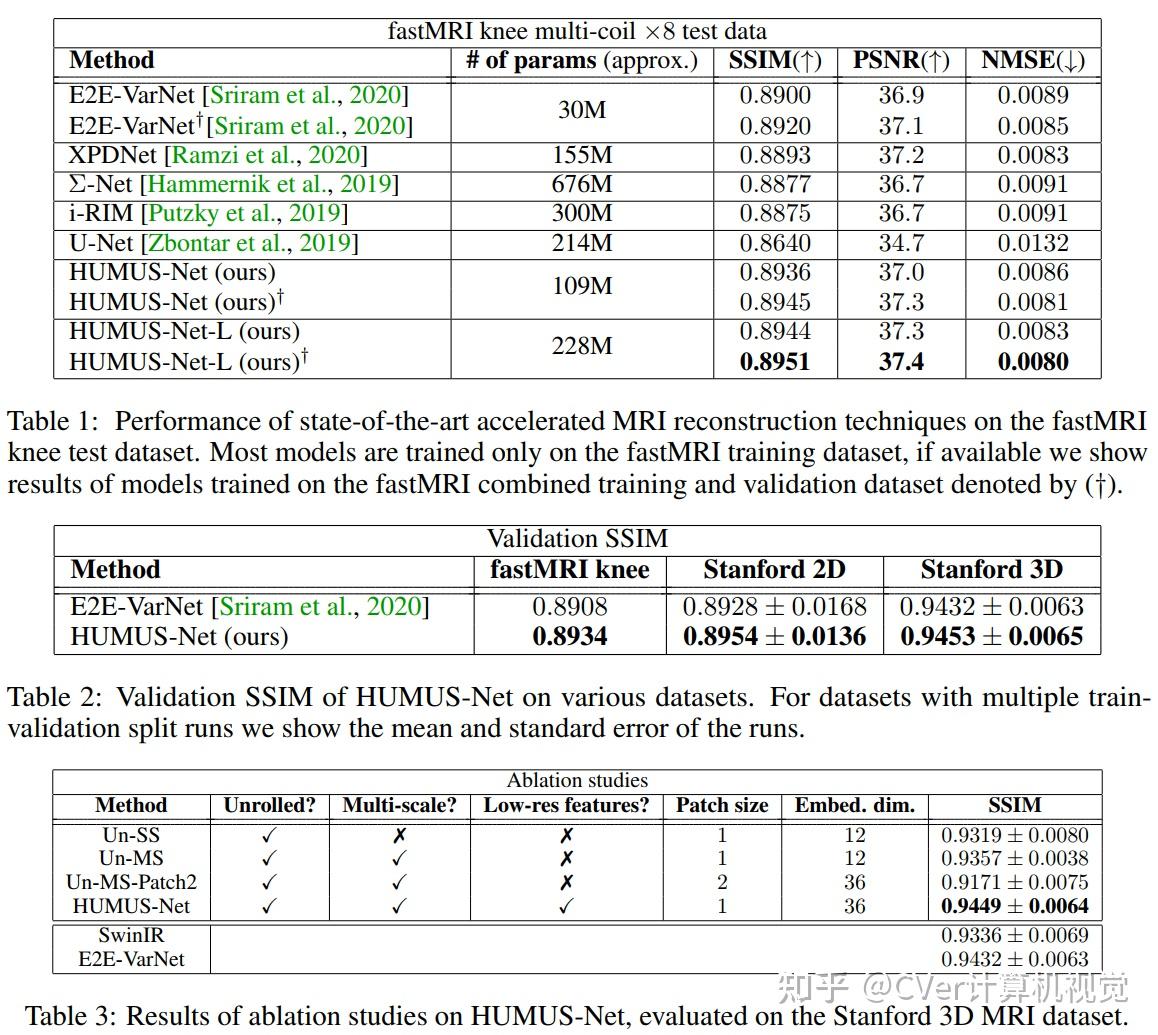
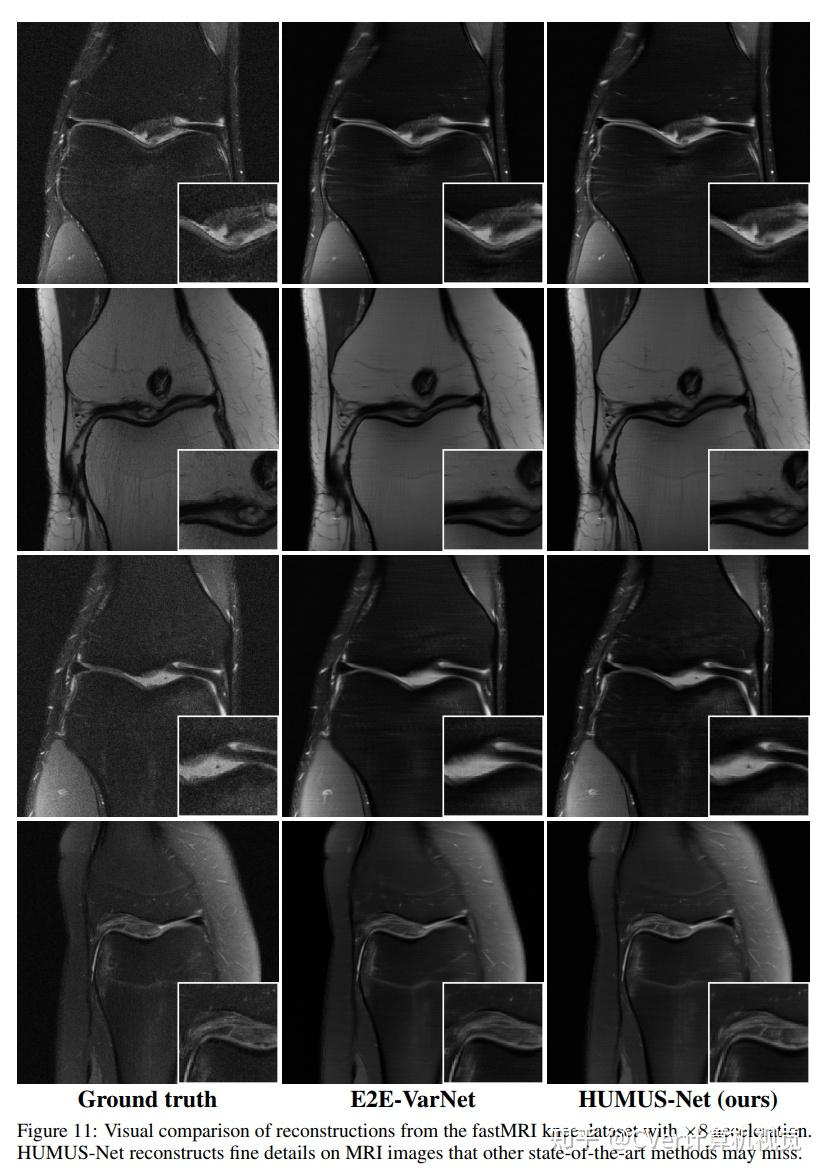
实验结果
我们的网络在最大的公开磁共振成像数据集上建立了新的技术水平,即快速磁共振成像数据集。我们进一步在另外两个流行的磁共振成像数据集上展示了HUMUS-Net的性能,并进行细粒度消融研究来验证我们的设计。
点击进入—>
医疗影像和Transformer微信技术交流群
CVer-Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号:
CVer222
。加的时候备注一下:
Transformer+学校/公司+昵称+知乎
,即可。然后就可以拉你进群了。
CVer-医疗影像交流群
建了CVer-医疗影像交流群!想要进医疗影像学习交流群的同学,可以直接加微信号:
CVer222
。加的时候备注一下:
医疗影像+学校/公司+昵称+知乎
,即可。然后就可以拉你进群了。
推荐阅读
CNN再次反击!FCViT:视觉新主干!近距离观察空间建模:从注意力到卷积
NeurIPS 2022 | Stoformer:用于图像恢复的随机窗口Transformer
CLIP是强大的微调器:用ViT-B和ViT-L实现85.7%和88.0%的准确率
替换U-Net!DiT:基于Transformer的可扩展扩散模型
微软等提出A-CLIP:Attentive Mask CLIP
扩散模型在医学图像上击败GAN
华为诺亚提出FastMIM:加速用于视觉的掩码图像建模预训练
NMS(非极大值抑制)的反击!DETA:基于Transformer的新目标检测器
UNETR++:深入研究高效准确的3D医学图像分割
CCF论文列表(2022拟定)大更新!MICCAI空降B类!PRCV空降C类!ICLR继续陪跑...
首个!SinFusion:在单个图像或视频上训练扩散模型
DiffusionDet:第一个用于目标检测的扩散模型
65.4 AP刷新COCO目标检测新记录!InternImage:探索具有可变形卷积的大规模视觉基础模型
Sea和北大提出新优化器Adan:深度模型都能用!训练ViT和MAE减少一半计算量!
MedSegDiff:基于扩散概率模型的医学图像分割
YOLOv4团队打造YOLOv7!最先进的实时目标检测网络来了!
FAIR提出ConvNeXt:2020 年代的卷积网络
清华提出:最新的计算机视觉注意力机制(Attention)综述!
为何Transformer在计算机视觉中如此受欢迎?
Transformer一脚踹进医学图像分割!看5篇MICCAI 2021有感
回复
使用道具
举报
独孤飞宇
独孤飞宇
当前离线
积分
14
2
主题
7
帖子
14
积分
新手上路
新手上路, 积分 14, 距离下一级还需 36 积分
新手上路, 积分 14, 距离下一级还需 36 积分
积分
14
发消息
发表于 2025-6-20 15:03:22
|
显示全部楼层
顶
回复
使用道具
举报
泰鹏注塑朱雪峰
泰鹏注塑朱雪峰
当前离线
积分
37
4
主题
18
帖子
37
积分
新手上路
新手上路, 积分 37, 距离下一级还需 13 积分
新手上路, 积分 37, 距离下一级还需 13 积分
积分
37
发消息
发表于 2025-12-22 09:29:03
|
显示全部楼层
众里寻他千百度,蓦然回首在这里!
回复
使用道具
举报
玉树清风
玉树清风
当前离线
积分
32
2
主题
18
帖子
32
积分
新手上路
新手上路, 积分 32, 距离下一级还需 18 积分
新手上路, 积分 32, 距离下一级还需 18 积分
积分
32
发消息
发表于 2025-12-22 12:23:33
|
显示全部楼层
佩服佩服!
回复
使用道具
举报
放纵的年华
放纵的年华
当前离线
积分
17
2
主题
10
帖子
17
积分
新手上路
新手上路, 积分 17, 距离下一级还需 33 积分
新手上路, 积分 17, 距离下一级还需 33 积分
积分
17
发消息
发表于 2025-12-22 19:43:56
|
显示全部楼层
小白一个 顶一下
回复
使用道具
举报
神不在的世界
神不在的世界
当前离线
积分
39
4
主题
20
帖子
39
积分
新手上路
新手上路, 积分 39, 距离下一级还需 11 积分
新手上路, 积分 39, 距离下一级还需 11 积分
积分
39
发消息
发表于 2026-3-18 12:42:29
|
显示全部楼层
我了个去,顶了
回复
使用道具
举报
酸甜苦辣
酸甜苦辣
当前离线
积分
18
0
主题
10
帖子
18
积分
新手上路
新手上路, 积分 18, 距离下一级还需 32 积分
新手上路, 积分 18, 距离下一级还需 32 积分
积分
18
发消息
发表于 2026-3-19 09:18:05
|
显示全部楼层
1v1飘过
回复
使用道具
举报
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
数据库
快速回复
返回顶部
返回列表


 发表于 2023-1-19 08:44:33
发表于 2023-1-19 08:44:33