|
|
LRP-net: A lightweight recursive pyramid network for single image deraining
这是篇发表于二区Top《Neurocomputing》的文章
解决问题:去雨网络存在较高的内存和计算成本,开发一款轻量级的去雨网络
1. Introduction
本文想实现轻巧的网络结构和低内存开销的去雨网络,主要贡献是设计了LPD( Lightweight Pyramid Deraining ) 模块,,为在参数量减少的同时保证性能的提升采用类似PReNet的递归机制来循环去雨,是一种拿时间换空间的策略。作者认为资源受限的平台 (例如移动终端或边缘设备),参数数量的减少是最重要的。
2. Lightweight recursive Pyramid network
LRP-net是由两个3\times 3卷积块和4个LPD块构成,然后输入原图和上一阶段的去雨图像(开始时由原图代替),输出去雨的图像

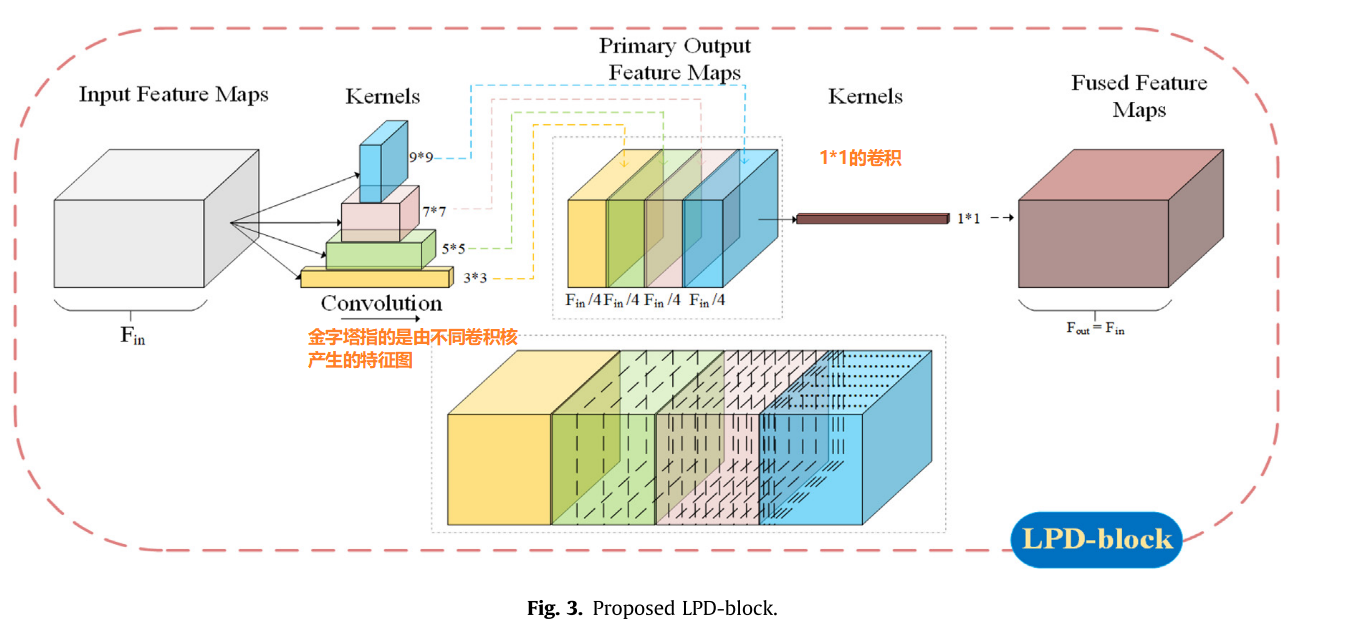
1、Lightweight Pyramid deraining block(LPD块,关键创新点)
大多数去雨网络采用的是3\times 3卷积核,这样会导致在某个特征野中提取特征,由于雨条纹的密度和方向不同,这导致多尺度特征更能提升去雨性能,大卷积核更擅长整合高阶信息,比如全局信息,语义信息,小卷积核擅长处理低阶信息,比如纹理。
作者采用卷积操作时融合不同大小的内核,具有基于不同大小的卷积核来获得多尺度特征,同时为减少计算量和模型容量,对于大卷积核参数量变大问题,采用了分组卷积策略,为防止分组卷积的结构化稀疏特性,不同分组的通道之间没有信息交换和不同尺寸内核产生的特征缺乏信息交换。因此,使用逐点卷积(1x1的普通卷积)来融合这些不同的特征并减轻信息分隔现象。
LPD中卷积核分别被设置为3,5,7,9。并采用填0策略保证输入和输出特征图保持一致,同时通道数保持一致,让内存访问消耗最低,这里的通道数为4

2、Recursive deraining mechanism
x_{N}=f\left(\operatorname{Concat}\left(x_{N-1}, x_{0}\right)\right)
x_{N} 是第N阶段去雨结果, x_{0} 是原图, x_{N-1} 是第N-1阶段去雨结果。
3、loss function
对N阶段的每个阶段都计算MSE和SSIM,得到总的loss,标记为 L_{R-*}
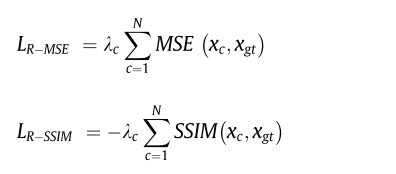
为了和上面作对比,作者采用另一种方法,就是直接计算最后一个阶段的输出最终去雨结果和ground-truth计算MSE和SSIM
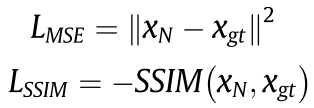
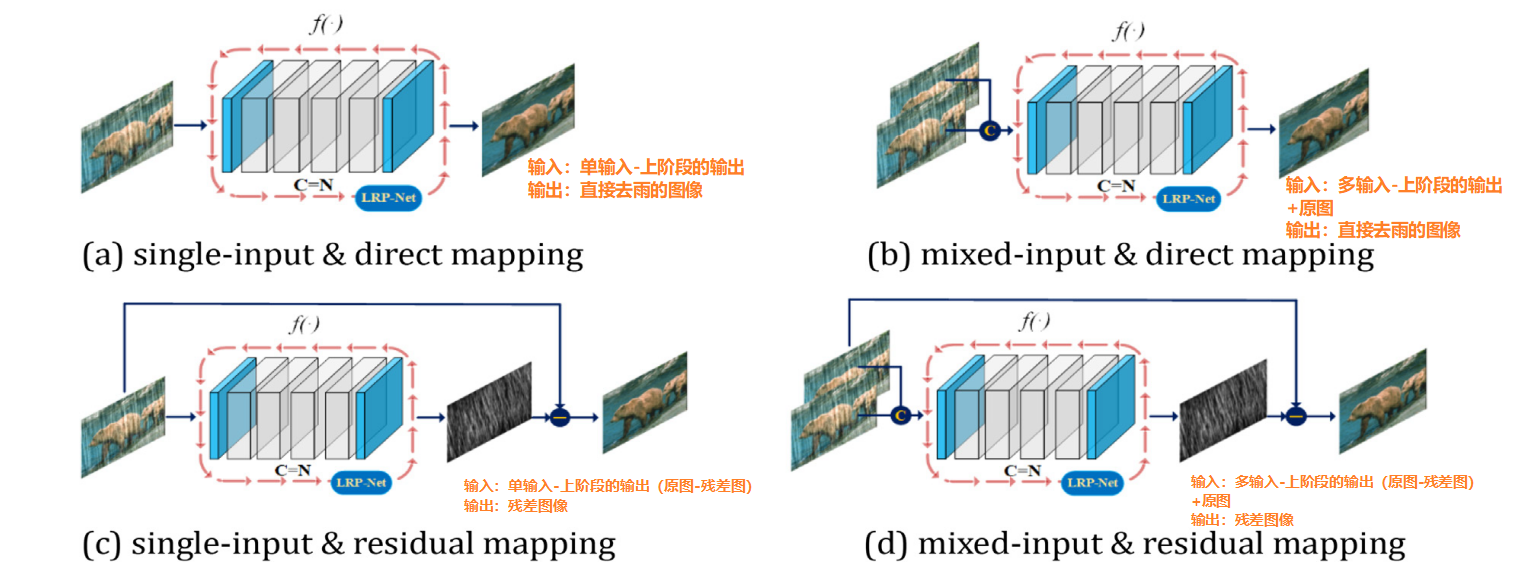
4、Network Input/Output
因为作者采用的是循环结构,因此可以有四种情况:输入可以是单输入和多输入,输出可以是残差图和直接的去雨图像
4. Experimental results and discussions
4.1、Ablation studies
4.1.1、loss function
R-MSE(1) R-MSE(2)是指不同的超参设置
首先是对于loss函数,可以看出最终的输出去雨图像的loss性能比在每轮计算loss,性能更好,这表明单一监督足以训练LRP-net,无需在每一轮的中间输出中进行微调
同时ssim更适合作为去雨的loss,因为人类测量两个图像之间的差异时,我们更加关注结构相似性,而不是计算每个像素的差异

4.1.2、Round number
由于采用循环的方式进行去雨,去雨性能依赖于循环的轮数,适当的轮数将有助于LRP-Net达到最佳性能
可以从实验看出,其实5,6,7轮的结果来看相差不大,在实用的角度上来看第五轮其实完全可以进行使用
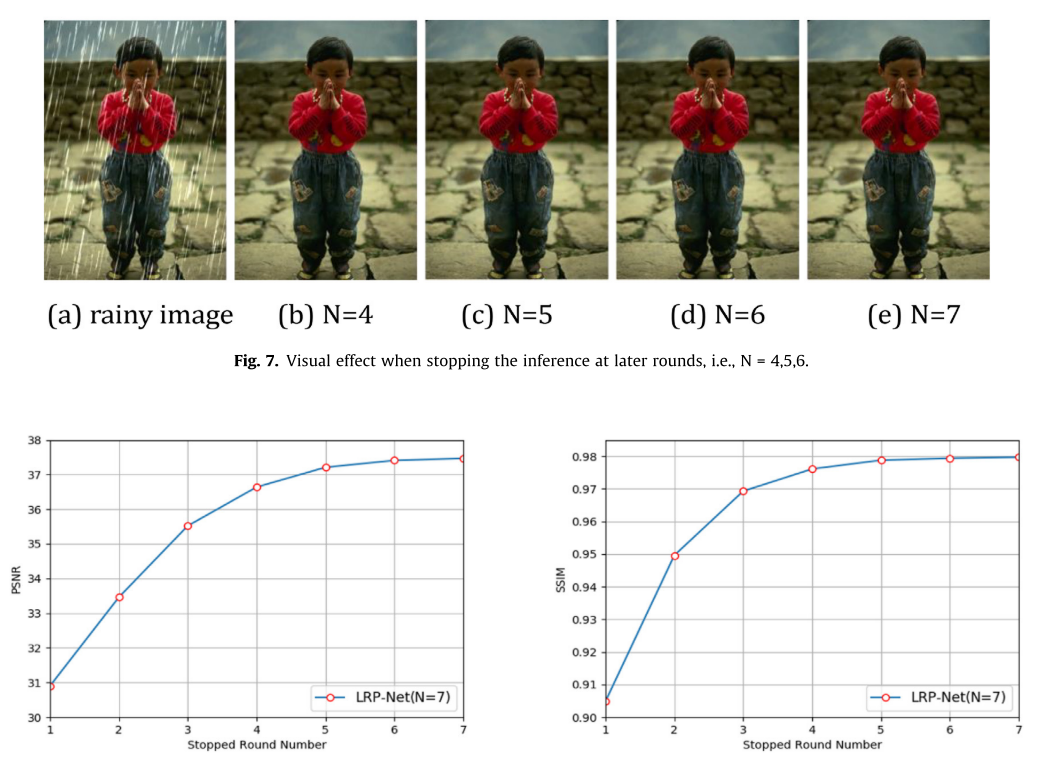
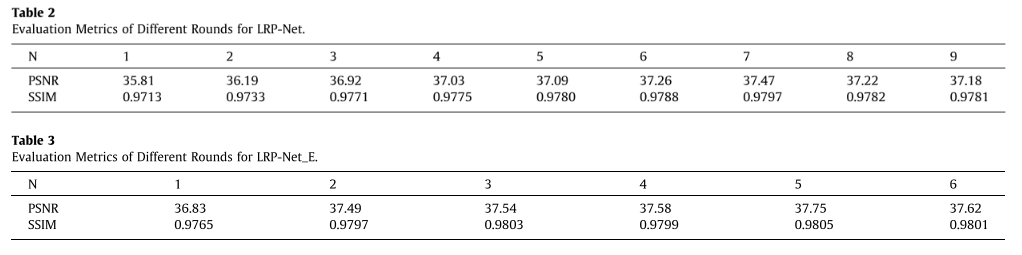
LRP-Net是由4个LPD blocks 组成,LRP-Net_E(更复杂)是由8个LPD blocks 组成,从实验可以得到较轻的网络模型(第七轮性能最好)通常会获得更多的迭代过程来充分提取特征。而对于相对较深的网络模型(第五轮性能最好),过多的回合将导致特征的冗余,这对网络能力产生负面影响,导致训练时间和资源增加同时泛化能力下降。
4.1.3、Network architecture
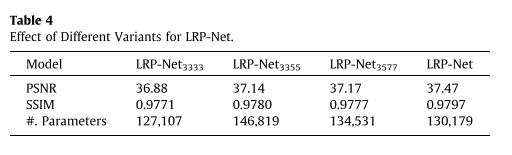
其他设置保持不变,只改变LPD模块的卷积核大小,作者提出LRP-Net的卷积核分为 3\times 3,5\times 5,7\times7,9\times 9 ,缩写可以为 LPR-Net_{3579} ,以 LPR-Net_{3355} 为例,即LPD模块的卷积核分别为 3\times 3,3\times 3,5\times 5,5\times 5
4.1.4、Group convolution strategy
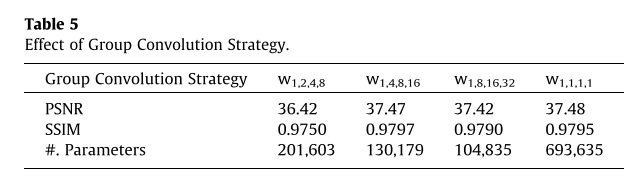
由于采用的大卷积核,虽然采用分组策略但是分多少组是不确定的,作者做了相应的实验来进行说明
以 W_{1,2,4,8} 为例,就是对 3\times 3,5\times 5,7\times7,9\times 9 的卷积核分别分1,2,4,8组来降低模型参数,作者通过实验得出1,4,8,16是最佳的分组方式,但并未给出解释
4.1.5、The effect of input & output
与mixed-input和direct mapping相比,mixed-input和residual mapping的性能显着提高。这表明residual mapping对脱轨任务有很大帮助。作者解释不列single-input&direct mapping的原因是通过实验发现,single-input&direct mapping不能达到令人满意的性能。

4.2. Comparison with the State-of-the-Arts
参数量比PReNet还小,同时性能优于PReNet
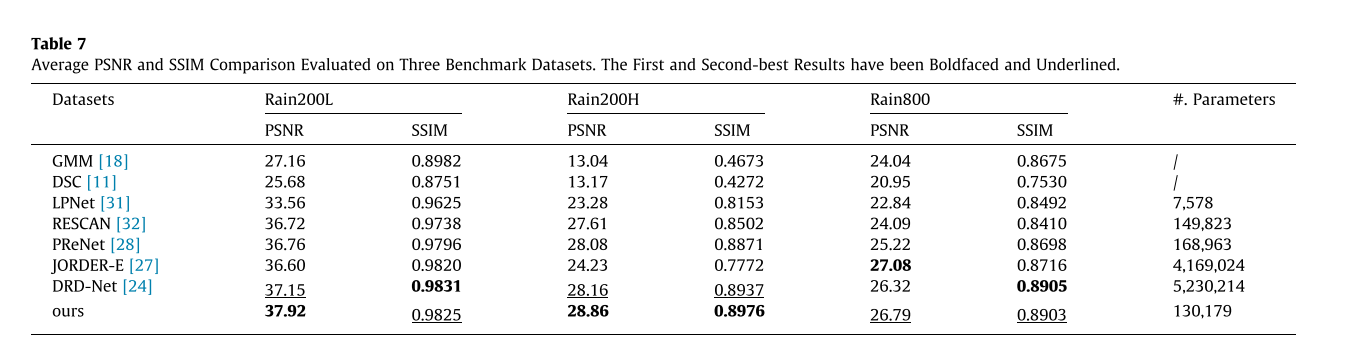


从运行时间上来看,可以发现虽然参数量很小但是由于采用多轮的策略,确实是用时间来换取空间的提高性能的策略。

如果觉得对你有帮助的话:
点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富! |
|


 发表于 2023-1-15 15:28:45
发表于 2023-1-15 15:28:45