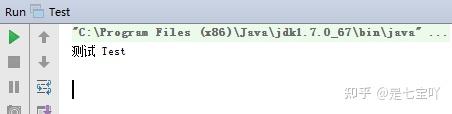
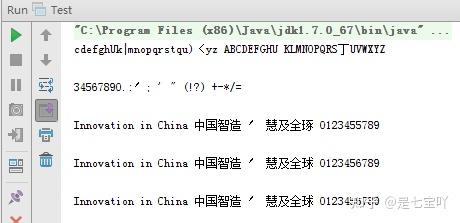
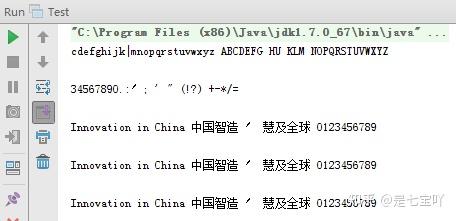
public class TesseractExample {
public static void main(String[] args) {
File imageFile = new File("eurotext.tif");
ITesseract instance = new Tesseract(); // JNA Interface Mapping
// ITesseract instance = new Tesseract1(); // JNA Direct Mapping


 发表于 2023-1-9 11:46:30
发表于 2023-1-9 11:46:30