|
|
今天听到同事说:MySQL 8 都不需要最左匹配就能用上联合索引了,最左匹配已经out了。
事实真的如此吗?邓爷爷说过,实践是检验真理的唯一标准。
以 MySQL 8.0.25 版本为例,做个实验
CREATE TABLE `example` (
`i1` int NOT NULL AUTO_INCREMENT,
`i2` int NOT NULL,
`i3` int NOT NULL,
PRIMARY KEY (`i1`),
KEY `idx_i2_i3` (`i2`,`i3`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
三个字段就够,一个主键索引,一个联合索引 idx_i2_i3。
再批量插入几条数据
INSERT INTO example(i2,i3) VALUES
(1,1), (1,2), (1,3), (1,4), (1,5), (2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO example(i2,i3) SELECT i2, i3 + 10 FROM example;
INSERT INTO example(i2,i3) SELECT i2, i3 + 15 FROM example;
INSERT INTO example(i2,i3) SELECT i2, i3 + 30 FROM example;
INSERT INTO example(i2,i3) SELECT i2, i3 + 60 FROM example;
先执行一下 ANALYZE ,防止MySQL 误判。
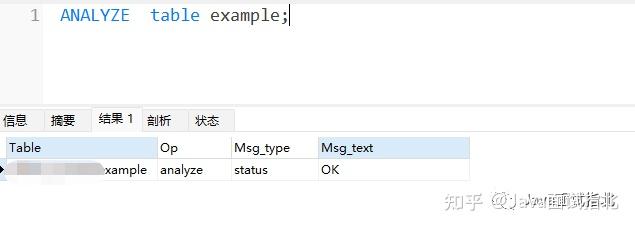
再执行 EXPLAIN 观察一下
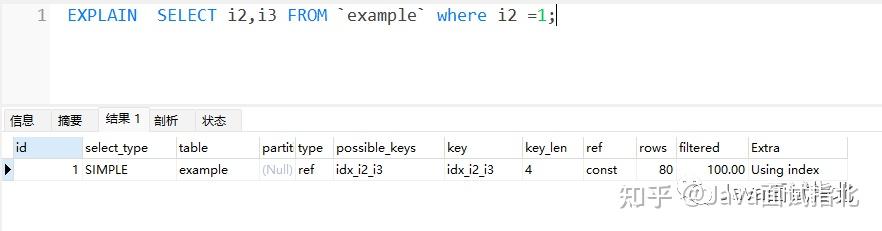
这个简单的查询结果,相信大家都能看懂,执行了一个 i2 为where条件的联合索引查询,用上了 idx_i2_i3,type是ref,说明用上了索引。
接下来换 i3 为where条件,大家先分析一下,这个时候理论上会用上索引吗?
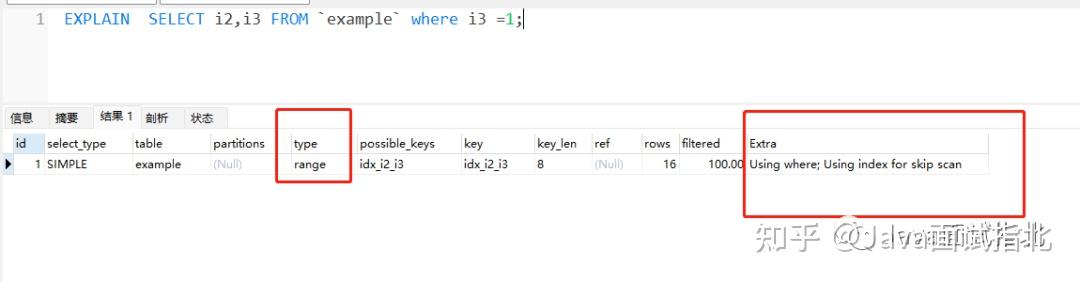
诶?确实用到了索引,但是好像又不太对,type 是 range,这是基于索引的范围扫描,明明是等值查询,怎么范围扫描了呢?还有 Extra 里的 Using index for skip scan又是什么鬼?
上官网瞅瞅去:
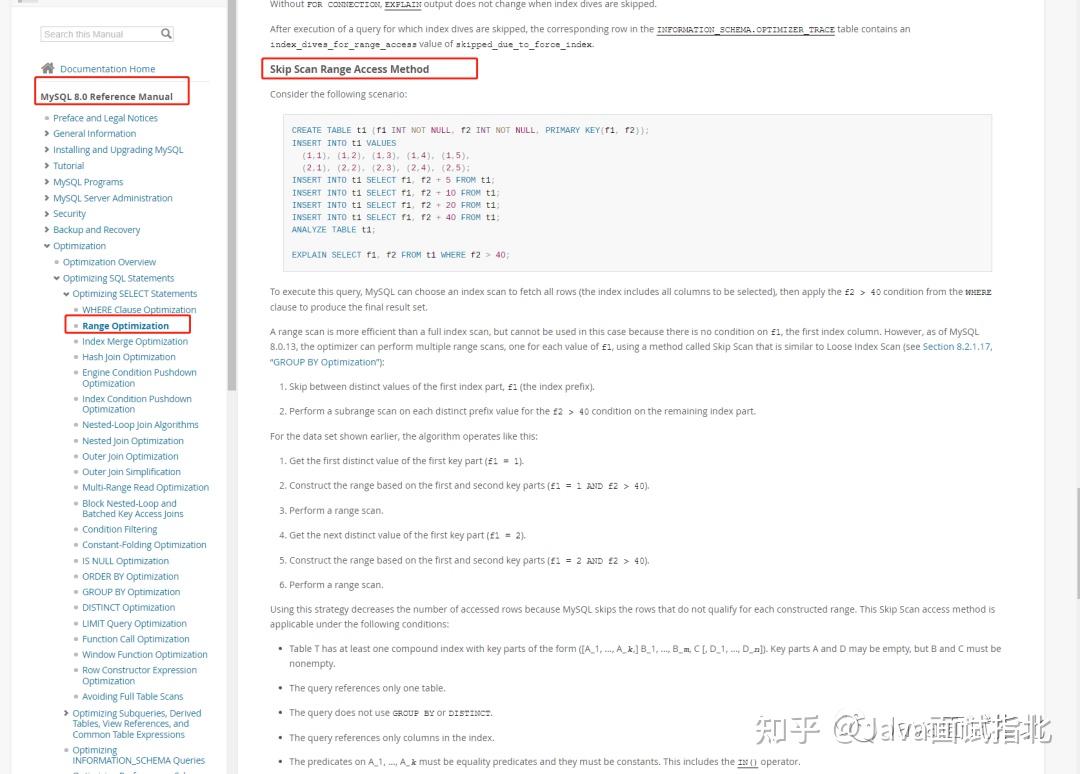
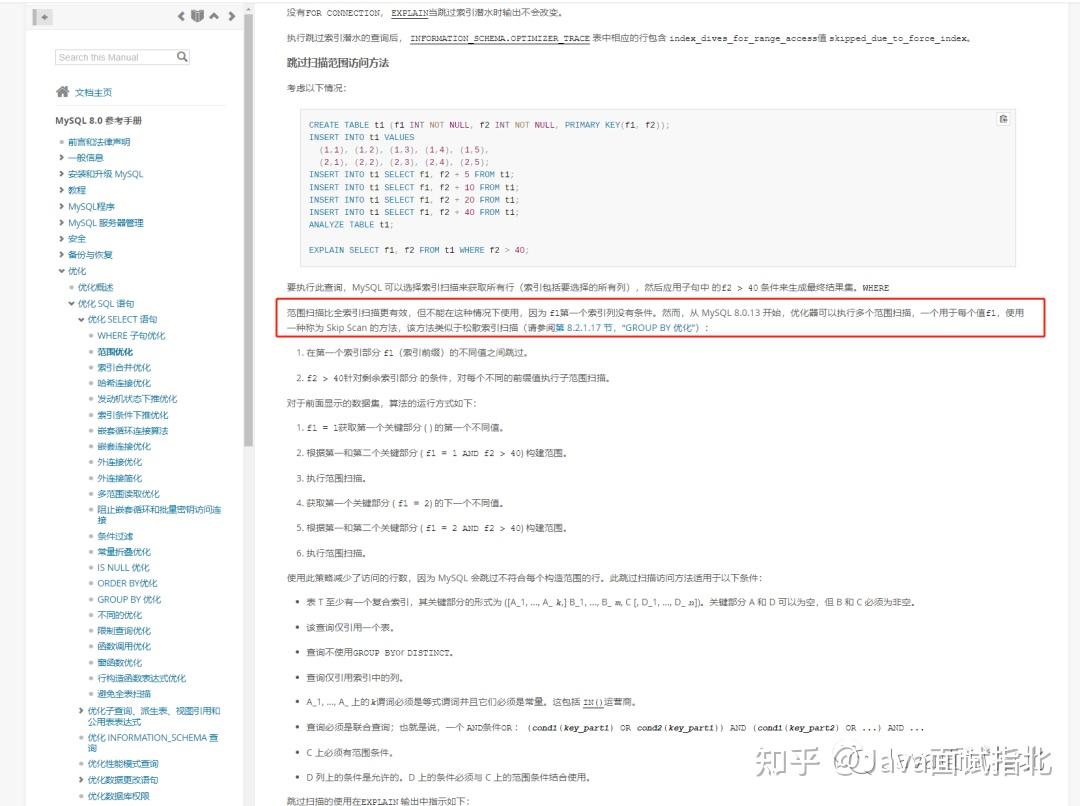
找到了,我给大家总结一下吧
按照过去对最左匹配原则的认知,刚刚的 where i3 = 1 的语句,不符合最左原则,是无法利用索引查询的。
那么也就导致了,要么全表扫描主键索引,要么全表扫描二级索引。看来MySQL官方是意识到了这样做效率低,故在8.0.13版本后,引入了SkipScanRangeAccessMethod(跳过扫描范围访问方法),在某些情况下,用范围扫描代替全文扫描,还是以刚才的语句为例,具体算法的运行方式如下:
- 在第一个索引分 i2 (索引前缀)的不同值之间跳过,这里一共有 1 和 2 两个值;
- 将 i2 的值拼入查询条件中构造 where i2 = 1 and i3 = 1 ;
- 执行语句,记录结果集;
- 重复步骤2,获取 i2 的第二个值2,where i2 = 2 and i3 = 1 ;
- 执行语句,记录结果集;
- 执行完毕,返回结果集至客户端。
这波优化是隐式的把索引前缀拼上了,一条查询就变成了多次查询,所以 type 就变成了 range 了,原理还是最左匹配原则(小样儿,你脱了马甲我照样认识你!手动狗头)。
想必此时有的朋友肯定想到了,当索引前缀基数很大的时候,还不如全表扫描了呢?让我们来实践一下。
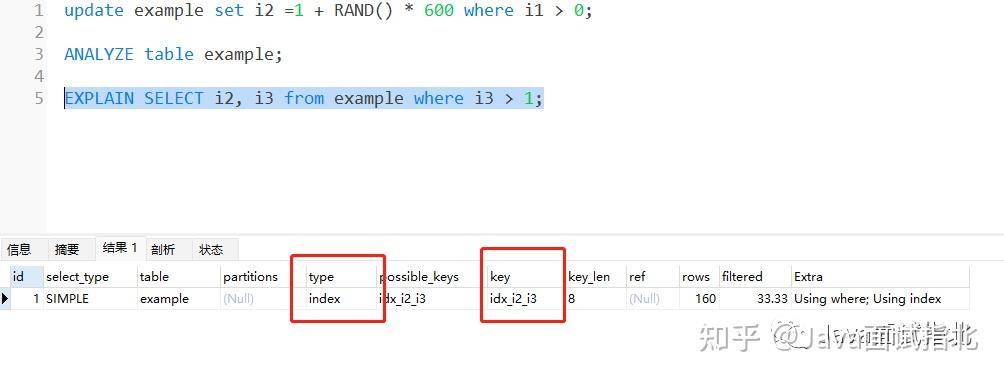
果然,变成了一个基于二级索引的全索引扫描。
关于局限性,我根据官网做了一下总结
- 需要联合索引;
- 查询仅引用一个表;
- 查询不能用GROUP BY 或者DISTINCT;
- 查询只能用一个索引,索引需要覆盖查询的值;
- 查询条件必须是常量,这里包括IN()运算符。
所以,说最左匹配out的,只是知其然,而不知其所以然,当面试官在问到最左匹配的时候,可以开始你的表演了。
附MySQL官网链接:
https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html |
|


 发表于 2023-1-8 17:45:36
发表于 2023-1-8 17:45:36