|
|
考察重点:⽂件处理、字符串处理、map与排序
要求:
读取⽂件内容,按单词出现词频降序排序,并打印输出
1、读取⽂件
2、处理字符串
3、单词不区分⼤⼩写、过滤特殊字符、过滤数字
4、形成map<string, int>(单词,词频)
5、按词频降序排序,打印输出“单词:频次”
6、考虑unicode的场景
sample.txt文件
链接:https://pan.baidu.com/s/1HheS_u2ia37EqRSw8FR__g
提取码:es0o
代码展示:
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <set>
#include <map>
#include <algorithm>
#include <vector>
using namespace std;
class CWordMap {
map<string, int>wordmap;
public:
bool AddString(string& s) {
//[],at,count,find
for (int i = 0; i < s.size(); i++) {
if (! (s >= &#39;a&#39; && s <= &#39;z&#39; || s >= &#39;A&#39; && s <= &#39;Z&#39; || s == &#39;+&#39;)) {
return false;
}
}
transform(s.begin(), s.end(), s.begin(), tolower);
wordmap++;
return true;
}
void Show(ostream& os) {
map<string, int>::iterator it = wordmap.begin();
int i = 0;
vector< pair<string, int> > vec;
while (it != wordmap.end()) {
vec.push_back(pair<string, int>(it->first, it->second));
it++;
}
stable_sort(vec.begin(), vec.end(), [](pair<string, int> a, pair<string, int> b) {
return a.second > b.second;
});
for_each(vec.begin(), vec.end(), [&i,&os](pair<string, int>n) {
os << n.first << &#34; : &#34; << n.second << &#34; &#34;;
i++;
if (i % 4 == 0) {
os << endl;
i = 0;
}
});
cout << vec.size() << endl;
}
};
int main() {
CWordMap wordMap;
string buff = &#34;&#34;;
string delimset = &#34;,.?!;:\&#34;\&#39;()[]{}123456789/&#34;;
vector<string> messy_code;
ifstream in(&#34;d:\\sample.txt&#34;);
while (getline(in, buff)) {
if (buff == &#34;&#34;) continue;
int pos = 0;
while ((pos = buff.find_first_of(delimset, pos)) != string::npos) {
buff.replace(pos, 1, &#34; &#34;);
pos++;
}
istringstream ss(buff);
string temp;
//if(temp )
while (ss >> temp) {
if (temp == &#34;&#34;)continue;
if (! wordMap.AddString(temp)) {
messy_code.push_back(temp);
}
}
}
in.close();
wordMap.Show(cout);
cout << endl;
for_each(messy_code.begin(), messy_code.end(), [](string s) {
cout << s << &#34; , &#34;;
});
return 0;
}
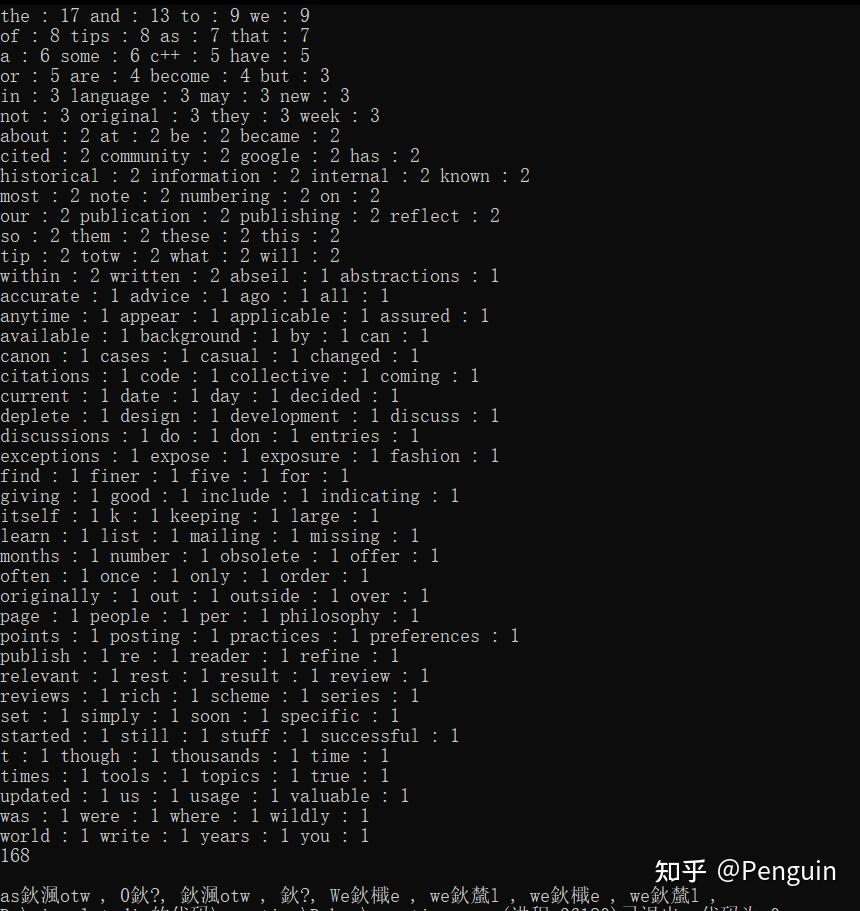
不懂的友友可以参考: |
|


 发表于 2023-1-5 01:42:11
发表于 2023-1-5 01:42:11