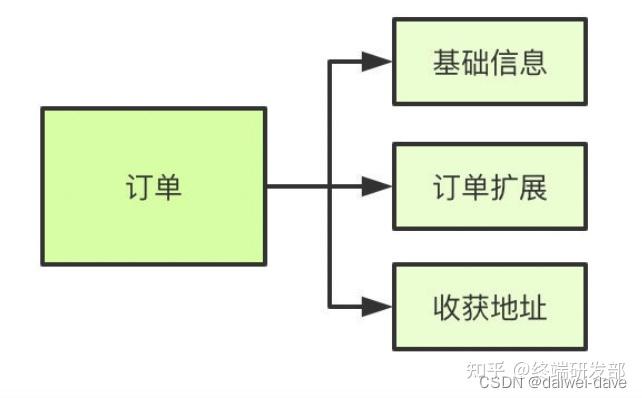
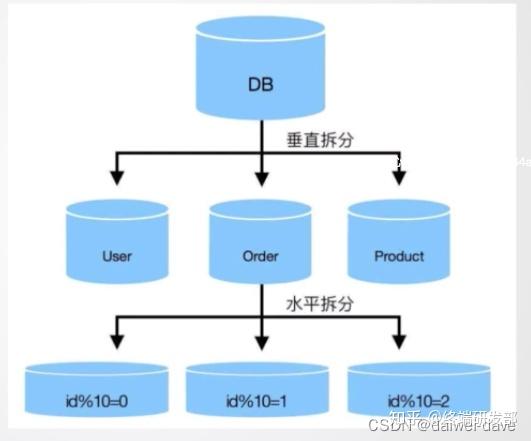
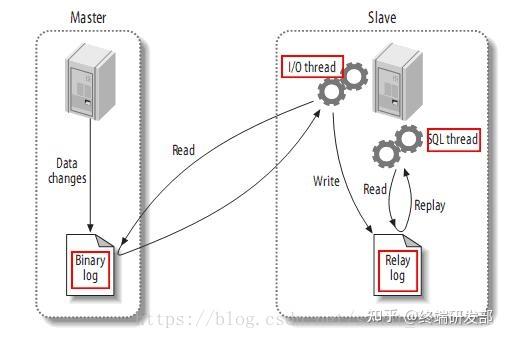
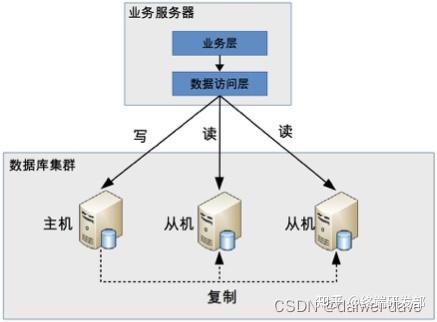
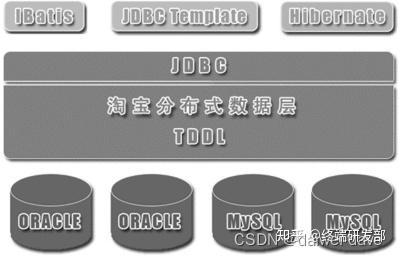
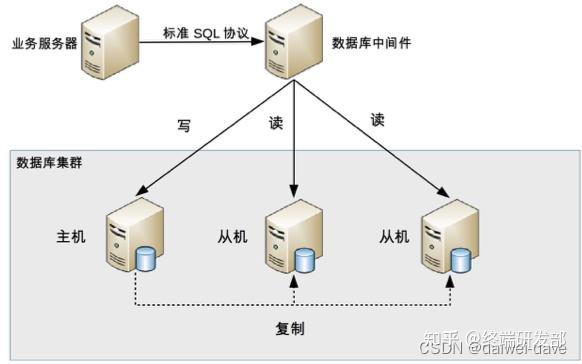
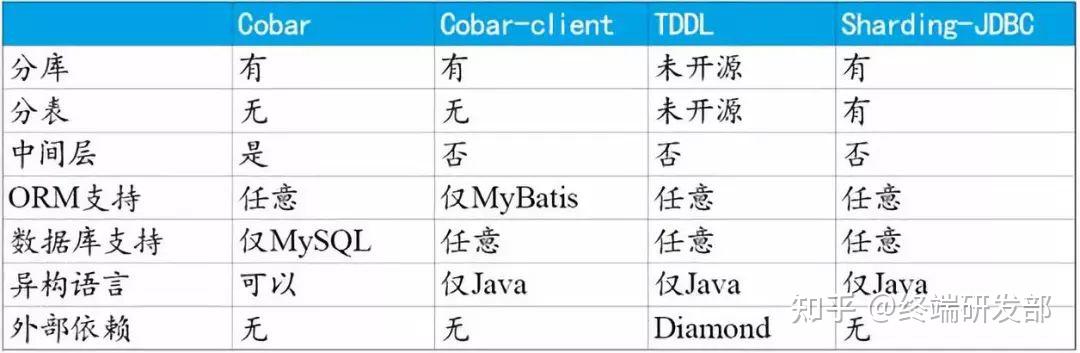
由于数据库中间件的复杂度要比程序代码封装高出一个数量级,一般情况下建议采用程序语言封装的方式,或者使用成熟的开源数据库中间件。如果是大公司,可以投入人力去实现数据库中间件,因为这个系统一旦做好,接入的业务系统越多,节省的程序开发投入就越多,价值也越大。
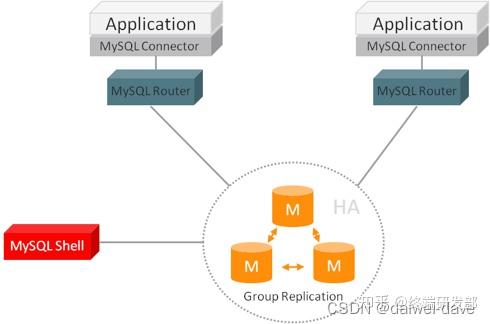
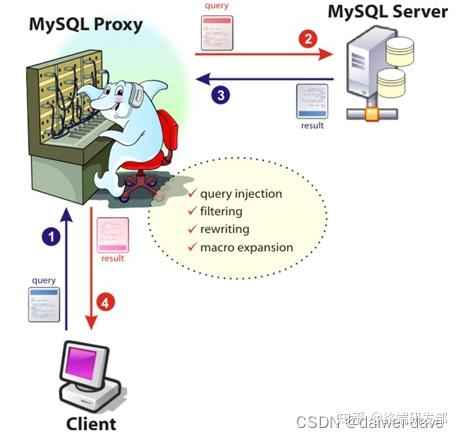
目前的开源数据库中间件方案中,MySQL 官方先是提供了 MySQL Proxy,但 MySQL Proxy 一直没有正式 GA,现在 MySQL 官方推荐 MySQL Router。MySQL Router 的主要功能有读写分离、故障自动切换、负载均衡、连接池等,其基本架构如下:
奇虎 360 公司也开源了自己的数据库中间件 Atlas,Atlas 是基于 MySQL Proxy 实现的,基本架构如下:


 发表于 2023-1-1 17:41:05
发表于 2023-1-1 17:41:05