|
|
C++反射 - 反射信息的自动生成
在前一篇 <<C++反射 - 基于反射的Lua中间层实现>> 中, 我们介绍了如何利用c++反射的基础设施来实现一个lua中间层. 其中也有一些注册代码的示例. 当项目比较简单的时候, 手动编写相关的反射注册代码不会占用太多的时间. 但当项目达到一定规模, 手动编写并维护这些注册代码费时费力, 相关接口改个名可能会涉及到多处关联注册代码的修改, 这肯定是我们所不能接受的. 所以大部分项目在使用反射, 或者类反射的脚本中间层生成的过程中, 都会开发一些自动生成工具来减少重复性的工作, 笔者所经历的项目也是如此. 得益于llvm的流行, 我们大部分相关工具都是以libclang解析源代码头文件生成AST作为基础的. 本文将结合笔者的项目经验, 介绍如何在C#中用一种逐层处理的方式完成前文中提到的反射注册信息的自动生成的.
1. 示例代码
前文中也提到过, 对于一个c++中的Vector3的定义:
//-------------------------------------
//declaration
//-------------------------------------
class Vector3 {
public:
double x;
double y;
double z;
public:
Vector3() : x(0.0), y(0.0), z(0.0) {}
Vector3(double _x, double _y, double _z) : x(_x), y(_y), z(_z) {}
double DotProduct(const Vector3& vec) const;
};
我们通过反射注册代码:
//-------------------------------------
//register code
//-------------------------------------
__register_type<Vector3>(&#34;Vector3&#34;)
.constructor()
.constructor<double, double, double>()
.property(&#34;x&#34;, &Vector3::x)
.property(&#34;y&#34;, &Vector3::y)
.property(&#34;z&#34;, &Vector3::z)
.function(&#34;DotProduct&#34;, &Vector3::DotProduct);
);
即可以完成对它的构造函数以及几个属性的反射注册, 然后我们就可以通过反射库来使用它了.
代码自动生成的目的比较简单, 对于上面的代码来说, 我们通过定义部分代码信息的读取, 能够完成对应的注册代码的自动生成, 整个任务就算是完成了.
早期没有llvm库的时候, 我们只能通过正则匹配等字符串模式匹配的方式来完成相关工作, 这种方式比较大的弊端一方面是效率, 另外一方面是业务程序对代码的组织方式可能破坏自动工具的工作, 排查和定位相关问题又不是那么直接. 在llvm库流程后, 越来越多的人开始尝试在AST这一层对源代码信息进行提取, 这样相关的问题就回归到了c++本身来解决了, 这肯定比前面说的基于字符串的机制要稳定可控非常多, 相关的问题也更容易定位排查. 要使用这种方式, 我们先来简单的了解一下libclang.
2. libclang和它带来的改变
libclang是llvm工具链中的一部分, 整个llvm的工作过程简单来说可以看成下图所示:
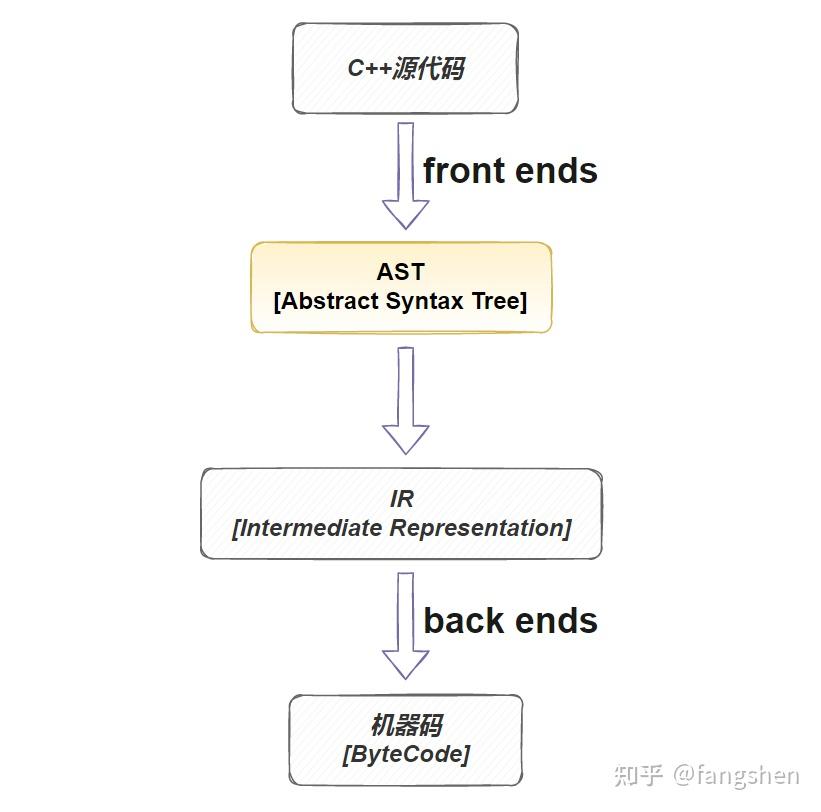
而libclang主要用于处理c++源码 -> AST 这部分的工作.
在llvm出现前, c++的compiler基本是&#34;复杂&#34;和&#34;神秘&#34;的代言人, 大家了解得比较多的: 1. GCC - 开源但复杂度高, 难以加入项目定制相关的需求 2. ms的compiler - 微软家的不必说了, 很多方面对比GCC有它的优势, 但, 神秘, 实现细节基本成迷. 3. Intel C++ Compiler - 大家都知道是高端的代言人, 但实际使用它的人并不多
而在llvm出现后, 整个c++ compiler的生态系统发生了巨大的改变, 先不说利用llvm工具链开发的各种语言的Jit版, 就从C++本身来说, 从原来的源码就是唯一, 我们多了更多的选择: 1. 利用llvm frontend部分在AST层级进行信息提取, 做离线分析或者离线生成相关的工作. 2. 在离BC侧更近但又不那么LowLevel的IR层, 做各种依赖函数插桩的工作.
3. 反射信息生成
回到反射信息生成上, 我们直接工作在libclang这一层就足够了, 原因是AST本身有足够多的相关信息, 我们能够提取到足够的类型和组成信息来组织最终的注册代码. 我们先来看一下普通模式下的编译方式和带反射信息下的编译方式:
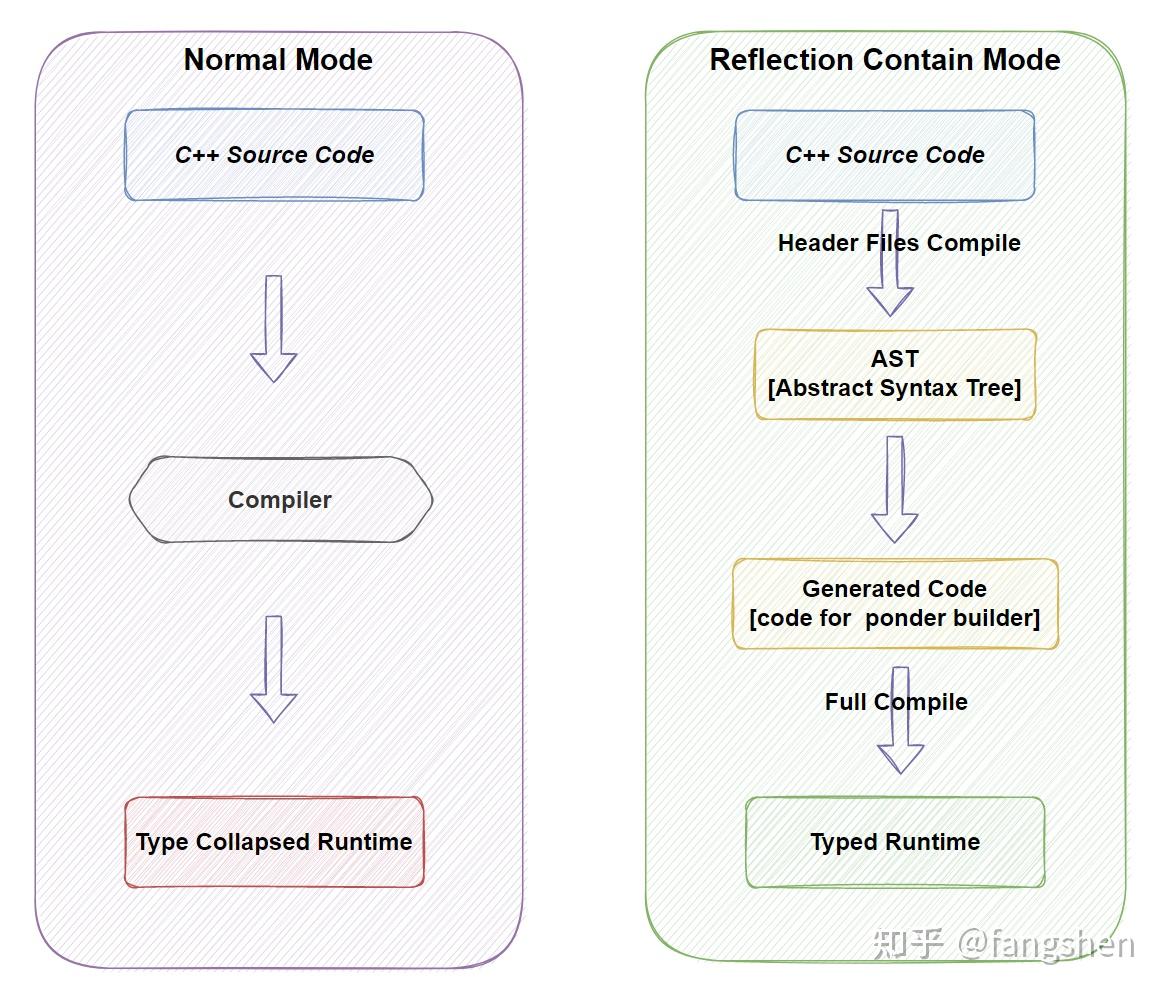
对比普通的处理过程[上图中的Normal Mode], 我们合理安排编译管线, 形成如右侧所示的二次Compile过程: - 第一次编译发生在工具内, 仅处理头文件, 用于提取必须的信息, 如类的定义等. - 第二次是真实的正常编译过程, 将工具额外产生的文件一起加入整个编译生成. 这样, 利用工具自动生成的一部分注册代码, 与原来的代码一起进行编译, 我们就能得到一个运行时信息完备的系统了, 这就是整个反射信息自动生成流程的基本工作原理 .
4. libclang的使用方式选择
前面介绍了libclang和整个基于AST代码生成的工作原理, 但libclang的使用方式有多种, 我们应该如何选择呢?
4.1 直接使用本命语言 - c++
能想到的最直接的方式, 当然是直接使用 c++来调用libclang完成相关的功能开发了, 这也是大部分开源库所选择的, 这种方式的优势和缺点都比较明显:
优势
- 使用c++不需要对libclang做任何的Wrapper, 即可访问相关的功能和实现
- 功能更新没有滞后性, 一些新功能更新libclang到最新版后即可使用
缺点
- 分析和使用AST信息的应用场景一般涉及大量的字符串处理, c++并不是这块的佼佼者.
- libclang默认使用callback的方式对AST进行访问, 复杂应用场景需要对节点进行反复操作时比较不便.
4.2 使用语言 - python
llvm库自带了python wrapper, 所以这种方式也被不少开源库使用, 一方面官方自带的wrapper, 另外python本身使用也非常方便, 也能很好的弥补c++字符串处理不便的问题. 但当相关的代码复杂度较高, 处理的代码量比较大时, python本身的性能劣势就会凸显, 工程组织以及性能提升上的短板都会凸显.
4.3 使用语言 - c#
可能有同学之前也接触过, 微软有个一直挺活跃的叫 ClangSharp 的库, 这是一个质量比较高的libclang的C# binding, 另外因为库本身的活跃度比较高, 对llvm新版本的支持也follow的比较快, 甚至你可以自己上github发Issues, 感觉响应度还挺高的. 之前我们更新到LLVM12以方便coroutine支持的时候就上去发过Issues, 响应还比较迅速, 大概两周时间库的维护者就添加了对LLVM12版本的支持并关闭了对应的Issue.
相比前面提到的c++和python, c#可以很好的弥补前面我们提到的这些缺点. 另外通过.net core, C#的跨平台性也得到了极大的提升, 在CentOS或者MacOS下运行C#程序都是比较简单的事情. 这也是笔者之前经历的项目比较多采用的方式的原因. 本文也会重点介绍以C#使用libclang的方式.
4.4 笔者经历的自动生成工具迭代
聊完libclang使用语言的选择, 我们也来看一下笔者经历的项目反射信息生成工具的选型迭代过程:
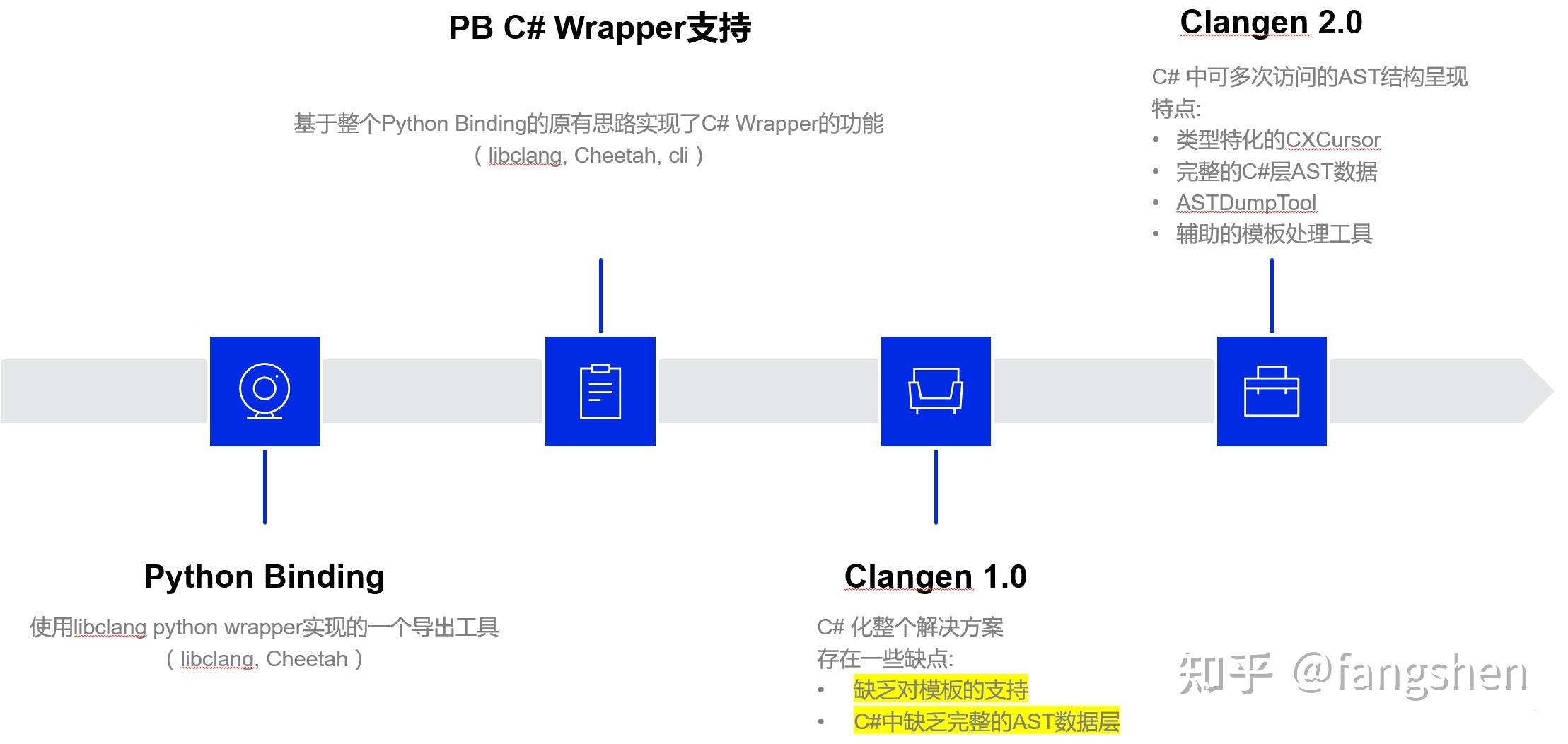
4.4.1 Python Binding
这个是官方的一个比较原始的版本, 利用llvm自带的libclang python wrapper, 和模板引擎Cheetah - python实现的一个小众模板引擎, 来完成c++ -> python的bridge代码生成, 所以它也包含了: - 使用libclang生成AST - 遍历AST提取相关信息 - 最终利用Cheetah组织生成需要的bridge代码 的完成实现.
4.4.2 Python Binding 提供 C# Bridge支持
这个阶段我们因为C#版的Editor, 需要提供一个c++到C#的Bridge支持, 当时因为编辑器只有Windows版的需求, 所以选择了最方便的微软独有的c++/cli来作为bridge的中间语言. 因为对比python的实现, c#版对AST的信息依赖度更重, 所以我们重新组织了整个python binding, 将不同类型的Cursor的处理代码独立出来, 最终实现了c#版的bridge基于c++源码的自动生成功能. 但随着需要处理的类变得越来越多, 类本身的实现也越来越复杂, 一方面python的工程组织相对薄弱, 动态语言带来的好处很快就被复杂问题的定位和性能低下给摊薄, 这种情况下, 我们开始思考更好的解决方案.
4.4.3 Clangen 1.0
正如前面所说, 这个阶段其实我们主要是寻求一种工程组织更好, 性能更高的语言, 然后我们就发现了一个微软官方维护并且还比较活跃的库, ClangSharp, 另外python的Cheetah模板整体使用下来, 还是给我们的C# bridge工具的开发带来了比较多的便利, 所以在C#中, 我们也尝试寻求相关的模板语言解决方案, 最终选择的是被广泛使用的Liquid模板语言. 这一版本的目标比较简单, 对标上一版本的功能, 完整实现python版的能力即可. 但过程中我们也发现了libclang AST访问机制带来的问题, libclang的AST访问大量依赖Callback, 所以当需要对相关信息进行重复访问的时候, 会带来比较多的障碍, 代码不是特别清晰, 这种问题在我们尝试对一些带模板的类进行支持的时候, 被放大的特别彻底, 所以我们在思考有没有更好的方式来解决相关的问题.
4.4.4 Clangen 2.0
在1.0的基础上, 在使用libclang生成AST之后, 并不马上进入最终的代码生成, 而是先生成一份C#组织的AST数据, 这层数据本身是支持重复访问的, 也规避掉了libclang自带的callback模式, 这样对于后续组织模板语言的Drop来说, 是更有利的. 后续以此为基础支持像: - LuaBridge的代码自动生成 - 反射信息的生成 - 基于反射的Lua信息的生成 等都比较简单, 像后续因为实际需要扩展出的c++ meta attribute支持, 在这个分层的架构中也很容易实现. 这部分后续会具体展开.
5. 必要的辅助库 - 模板语言
代码生成会涉及到大量带pattern的代码的处理, 我们可以直接选择在运行时拼接字符串, 如利用C#的$语法糖:
objCallStart = $&#34;_{ClassName}::&#34;;
对比使用string.Format()的同等表达:
objCallStart = string.Fomart(&#34;_{0}::&#34;, ClassName);
使用$的表达明显要简洁很多, 但如果生成的代码相对复杂, 迭代频率比较高, 我们会发现整个用于格式化生成的代码维护起来成本依然会比较高, 逻辑代码与字符串拼接的代码耦合. 那么有没有更好的方式呢?
5.1 protoc中使用的格式化方法
以protoc举例, 对于具体的message定义, 当我们生成c++中间代码的时候, protoc会根据message的定义来生成相关的代码, 很多时候比较pattern化的代码生成如:
for (int i = 0; i < file_->public_dependency_count(); i++) {
const FileDescriptor* dep = file_->public_dependency(i);
format(&#34;#include \&#34;$1$.proto.h\&#34;\n&#34;, StripProto(dep->name()));
}
在protoc中是这样来实现的, 通过自己包装的format()函数, 支持$number$定义占位符, 通过这种机制, 生成代码中可变的部分和不变的部分被良好的分离了.
但这么做依然是不够的, 我们看protoc相关的代码实现, 依然还是会觉得这些生成的代码与相关的逻辑处理代码耦合在了一起, 调整起来依然比较麻烦, 这种情况下, 更进一步的使用模板语言的方式就出现了.
5.2 模板语言
通过模板语言, 我们能对需要格式化输出的字符串内容与逻辑代码做更进一步的分离. 模板语言可以看成是一种专用型的脚本语言, 以格式化文本输出作为自己的设计目的. 因为我们的离线工具选用的是C#, 模板语言我们选在C#中有良好的第三方库支持的Liquid, 我们通过dotnet的包管理工具NuGet即可获取到Liquid库并直接使用它.
5.3 Liquid Template简介
我们先来看一个简短的liquid代码片段:
__register_type<{{ this_class.name }}>(&#34;{{ this_class.name }}&#34;)
{% comment %} class export start {% endcomment %}
{%- if this_class.has_base_class -%}
.base<{{this_class.base_class_name}}>()
{%- endif -%}
//member fields export here
{%- for field in this_class.fields -%}
{{ field.render }}
{%- endfor -%}
//member properties export here
{%- for prop in this_class.properties -%}
{{ prop.render }}
{%- endfor -%}
{% comment %} ... ignore something here {% endcomment %}
对于一次具体的输出, 可能的输出内容为:
__register_type<Vector3>(&#34;Vector3&#34;)
.property(&#34;x&#34;, &Vector3::x)
// ... ignore something here
除了无任何特殊含义的直接输出的文本部分, liquid中承担特殊作用的语法主要有三类: {{obj.property}} -> liquid的对象和属性定义, 后面会提到, 通过这种方式, liquid代码可以直接访问c#中定义的Drop对象的属性进行输出. 如上例中的{{ this_class.name }}用于输出类的名称.
{% %} -> liquid中的tags, 一般用于过程控制如if, for和一些特殊功能的实现. | 操作符 -> 特殊的filter支持, 我们一般只使用liquid自带的一些字符串的filter操作支持, 当然, liquid允许用户自定义filter.
整个Liquid的工作流程大致如下所示:
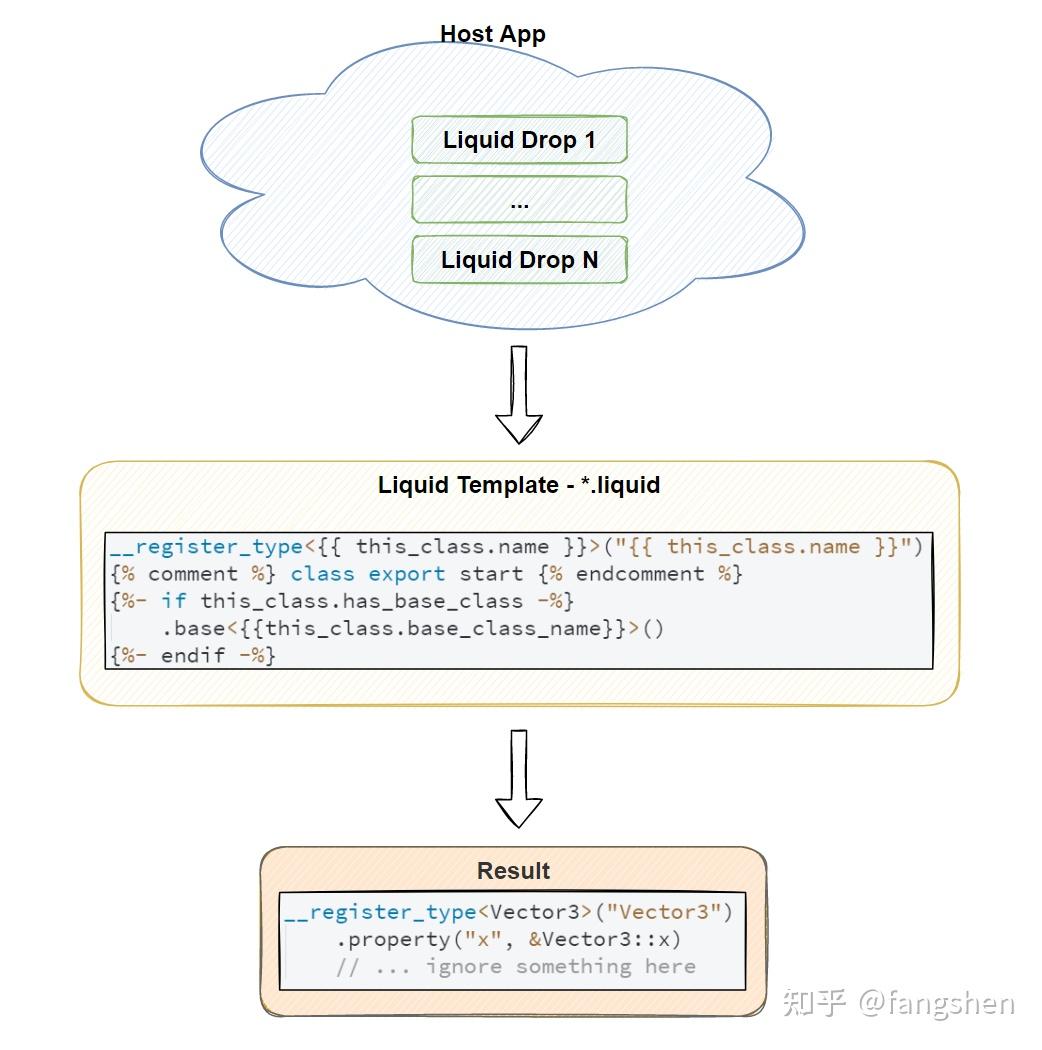
如上图所示, 通过模板语言, 业务层只需要关注较轻量的Drop实现, 复杂多变的文本组织和输出部分由Liquid模板文件来负责, 每层的功能和作用都比较明确, 更容易打理.
C#版的Liquid有两个可选库, 我们当时选的是dotliquid, 另外一个是号称比dotliquid快5倍占用内存更少的fluid, 两者都是liquid的dotnet实现, 可以按自己需要选用其中一个.
6. ClangSharp的编译
涉及到多平台的llvm编译, 整个过程还比较复杂, 所以这里单独成另外一篇文章 , 直接发在知乎上了, 这里给出链接 ClangSharp依赖的动态库编译, 文章中包含了Linux平台和Windows平台ClangSharp的编译指南, 主要是llvm的编译, 以及ClangSharp自己扩展出来的libClangSharp这个c++库的编译. 编译的时候需要注意一下llvm版本与libclangsharp的匹配, g6使用的版本对应的应该是llvm9. 一般使用ClangSharp唯一的障碍就是这一步了, 正确的编译llvm + libClangSharp, 剩下的C#部分工程, 跨平台兼容性足够好, 不容易出问题.
7. ClangSharp实现概述
7.1 libClangSharp - 扩展的c++部分
这部分代码比较少, 主要是补充直接Wrapper到C#中存在缺失的一些功能点, 这也是C#版和python版的wrapper差别比较大的一个地方, ClangSharp除了通过P/Inovke方式访问libclang动态库的Api外, 还有扩展一部分c++代码来保证上层的C#接口的整体性和易用性, python则基本是对原版libclang的Wrapper. libClangSharp相关的文件列表如下图所示:
7.1.1 ClangSharp.h
该文件是整个PIvokeGenerator工具生成ClangSharp.Interop工程相关C#代码时的入口文件, 中间包含需要bridge到C#中的枚举和函数的定义, 如:
#include <clang/AST/Decl.h>
#include <clang/AST/DeclCXX.h>
#include <clang/AST/DeclObjC.h>
#include <clang/AST/Expr.h>
#include <clang/AST/ExprCXX.h>
#include <clang/AST/ExprObjC.h>
#include <clang/AST/Stmt.h>
#include <clang/AST/StmtCXX.h>
#include <clang/AST/StmtObjC.h>
#include <clang/AST/VTableBuilder.h>
#include <clang/Basic/Specifiers.h>
#include <clang-c/ExternC.h>
#include <clang-c/Index.h>
// ... something ignore here
enum CX_AttrKind {
CX_AttrKind_Invalid,
#define ATTR(X) CX_AttrKind_##X,
#define ATTR_RANGE(CLASS, FIRST_NAME, LAST_NAME) CX_AttrKind_First##CLASS = CX_AttrKind_##FIRST_NAME, CX_AttrKind_Last##CLASS = CX_AttrKind_##LAST_NAME,
#include <clang/Basic/AttrList.inc>
};
// ... something ignore here
clangsharp_Cursor_getArgument(CXCursor C, unsigned i);
CXType clangsharp_Cursor_getArgumentType(CXCursor C);
int64_t clangsharp_Cursor_getArraySize(CXCursor C);
// ... something ignore here
7.1.2 其他文件
其他文件大多是用来为前面的ClangSharp.h中定义的全局函数服务的, 比如以其中的CXCursor.h为例, 里面主要包含了从具体的Node类型到CXCursor互转的支持, 如下面代码所示:
ASTUnit* getCursorASTUnit(CXCursor Cursor);
ASTContext& getCursorContext(CXCursor Cursor);
CXTranslationUnit getCursorTU(CXCursor Cursor);
const Attr* getCursorAttr(CXCursor Cursor);
const Decl* getCursorDecl(CXCursor Cursor);
const Expr* getCursorExpr(CXCursor Cursor);
CXCursor MakeCXCursor(const Attr* A, const Decl* Parent, CXTranslationUnit TU);
CXCursor MakeCXCursor(const CXXBaseSpecifier* B, CXTranslationUnit TU);
CXCursor MakeCXCursor(const Decl* D, CXTranslationUnit TU, SourceRange RegionOfInterest = SourceRange(), bool FirstInDeclGroup = true);
CXCursor MakeCXCursor(const Stmt* S, const Decl* Parent, CXTranslationUnit TU, SourceRange RegionOfInterest = SourceRange());
这些函数最终会被ClangSharp.cpp中全局函数的实现所所用, 以上面的MakeCXCursor()举例, 在clangsharp_Cursor_getDependentLambdaCallOperator()的实现中我们就能找到它的使用:
CXCursor clangsharp_Cursor_getDependentLambdaCallOperator(CXCursor C) {
if (isDeclOrTU(C.kind)) {
const Decl* D = getCursorDecl(C);
if (const CXXRecordDecl* CRD = dyn_cast<CXXRecordDecl>(D)) {
return MakeCXCursor(CRD->getDependentLambdaCallOperator(), getCursorTU(C));
}
}
return clang_getNullCursor();
}
7.1.3 libClangSharp的封装思路
其实从上面的代码不难理解libClangSharp的封装思路, 区别于 仅对libclang的C接口进行导出, libClangSharp还使用llvm相关的c++接口对相关功能进行了一次补充封装, c#中会使用到的扩展的函数和枚举都基本集中在ClangSharp.h中, 相关的接口做了更适合C#访问的处理,
为后续ClangSharp做出更HighLevel的封装提供了基础.
7.2 ClangSharp - C#部分代码
介绍完C++部分, 我们来看一下ClangSharp的C#部分实现. ClangSharp的C#部分由好几个库组成:
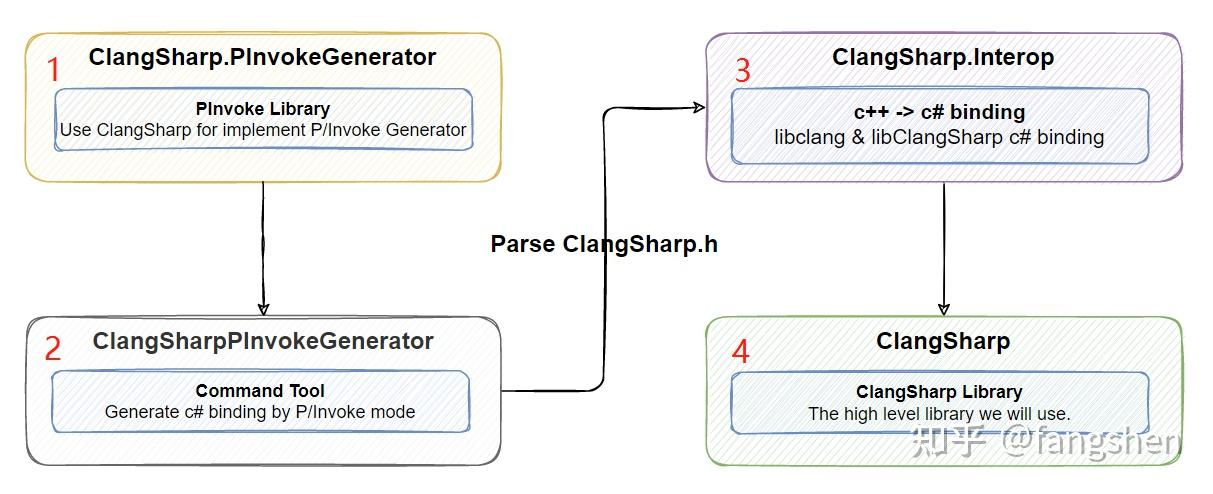
库之间的关系比较复杂: - ClangSharp.PInokeGenerator - 利用ClangSharp.Interop和ClangSharp库实现的c++ -> C#自动bridge代码生成库, 生成的中间代码采用P/Invoke模式. - ClangSharpPInvokeGenerator - 使用上面ClangSharp.PInvokeGenerator库实现的命令行工具. 注意ClangSharp.Interop中的部分代码也是由它来生成的. - ClangSharp.Interop - libclang 与 libClangSharp C++库的C#包装, 我们可以认为这部分是LowLevel的libclang C#版接口 - ClangSharp - 对ClangSharp.Interop库二次封装后的HighLevel版libclang C#库, 我们一般直接使用这个库中封装的相关功能就可以了.
前面的两个PInvokeGenerator相关的工程因为我们使用的都是预处理好的ClangSharp库, 所以实际应用过程中并不需要用到相关的代码和实现, 有P/Invoke方式自动导出需求的可以自行翻阅了解, 本篇会直接跳过相关的介绍.
因为ClangSharp.Interop其实包含对两个c++动态库的P/Invoke封装, 我们可以简单通过对应的文件名和静态类名来区分, libclang相关的接口基本都集中在 clang.cs中, 对应的静态类是 clang, 而libClangSharp相关的接口基本都集中在 clangsharp.cs中, 对应的静态类是clangsharp. 当然, 除了基础的接口外, 还有不少自动生成 + 手写的struct和enum实现. 7.2.1 unsafe的C#封装
P/Invoke模式下, 会涉及到大量unsafe特性的使用, 我们以libclang中常用的CXCursor的C#封装为例, 来简单看一下它的实现:
namespace ClangSharp.Interop
{
public partial struct CXCursor
{
[NativeTypeName(&#34;enum CXCursorKind&#34;)]
public CXCursorKind kind;
public int xdata;
[NativeTypeName(&#34;const void *[3]&#34;)]
public _data_e__FixedBuffer data;
public unsafe partial struct _data_e__FixedBuffer
{
public void* e0;
public void* e1;
public void* e2;
public ref void* this[int index]
{
get
{
fixed (void** pThis = &e0)
{
return ref pThis[index];
}
}
}
}
}
}
注意unsafe和fixed关键字的使用, P/Invoke封装通过对非安全的指针的使用, 弱化c++与C#的差异, 使相关的结构体, 如CXCursor可以在两个语言间自然的转换, 这对于跨语言接口的实现是很关键的. 另外, ClangSharp也对CXCursor做了很多方便使用的包装, 如下:
namespace ClangSharp.Interop
{
[DebuggerDisplay(&#34;{DebuggerDisplayString,nq}&#34;)]
public unsafe partial struct CXCursor : IEquatable<CXCursor>
{
public static CXCursor Null => clang.getNullCursor();
public CXType ArgumentType => clangsharp.Cursor_getArgumentType(this);
public long ArraySize => clangsharp.Cursor_getArraySize(this);
public CXCursor AsFunction => clangsharp.Cursor_getAsFunction(this);
public CX_AtomicOperatorKind AtomicOperatorKind => clangsharp.Cursor_getAtomicOpcode(this);
public CX_AttrKind AttrKind => clangsharp.Cursor_getAttrKind(this);
// ... something ignore here
};
}
通过partial关键字, native类的数据部分和接口属性部分做了分离, 数据部分更多依托于自动生成, 而接口属性部分则更多使用手动方式去暴露外层可使用的各种属性和方法. 这也是c#版libclang接口对比python版接口来说更好用的一部分原因.
7.3 ClangSharp实现小结
ClangSharp库的整体构成看似复杂, 但主线其实还是比较明确的: 1. libClangSharp c++部分实现完成对libclang的补充封装, 与libclang一起为C#化做最底层的支持. 2. ClangSharp.Interop库完成对libclang 和 libClangSharp c++部分的bridge, 实现初步的libclang c#接口. 3. ClangSharp库再次对ClangSharp.Interop进行封装, 提供HighLevel版的libclang C#接口. 4. PInvokeGenerator相关的库和命令行, 一方面使用前面的几个库完成自己的c++ -> C#的bridge层自动生成功能, 另外ClangSharp.Interop中的部分代码也使用该工具来生成(有点自循环的味道, 类似编译器的自举, 但这里只是部分的, 整体实现还是会依赖不少手动代码). 接下来我们将介绍ClangSharp的使用, 同时也会以ASTDumpTool类的实现作为例子来讲解ClangSharp的基本使用, 同时这个类本身也是我们离线工具分析定位问题的一个常规手段.
8. ClangSharp的使用简介
整个ClangSharp的使用其实跟我们使用compiler tools的体验基本是一致的: 1. 传入侍处理的文件 2. 配置相关的参数, 如-I指定额外的头文件搜索路径 3. 其他影响编译的参数, 如-D指定额外的宏 4. 编译生成CXTranslationUnit对象, 出错则直接输出错误信息 5. 在正确生成的CXTranslationUnit上执行后续需要的操作.
有过cmake等build system使用经验的同学, 对1, 2, 3相关的过程应该都非常熟悉, 后面我们也会看到ClangSharp中相关步骤唯一的差别是我们并不是将命令行参数传给命令行, 而是传给了一个ClangSharp的Api.
注意因为c++是编译执行的静态语言, 所以如果编译生成的过程出错, 就不会产生正确的CXTranslationUnit对象, 首先我们要保证编译这步是正确执行的, 后续的操作才有意义. 我们本章会先介绍编译代码到AST的具体过程, 正确生成基础的CXTranslationUnit后, 我们将介绍如何dump 相关的AST信息到一个文本文件, 这也是我们检查生成工具处理的原始AST数据的一种必要手段, 工具本身的开发过程中, 一些执行与预期不符的情况 , 我们就会借助相关的功能来检查问题产生的原因.
8.1 编译代码到AST
我们直接以Clangen使用的编译函数为例来说明整个编译过程:
public CXTranslationUnit ParseWithClangArgs(List<string> sources, string[] args)
{
var tmpfile = Path.GetTempFileName() + &#34;.cxx&#34;;
var lines = new List<string>();
foreach(var source in sources)
{
lines.Add(string.Format(&#34;#include \&#34;{0}\&#34;&#34;, source));
}
File.WriteAllLines(tmpfile, lines);
// the index object
CXIndex Index = CXIndex.Create(false, false);
// prepare some vars for parse
CXTranslationUnit TU;
CXTranslationUnit_Flags tmpFlag = CXTranslationUnit_Flags.CXTranslationUnit_DetailedPreprocessingRecord;
var error = CXTranslationUnit.TryParse(Index, tmpfile, new ReadOnlySpan<string>(args), null, tmpFlag, out TU);
if (error != CXErrorCode.CXError_Success)
{
Log.Error(&#34;Failed to parse Translation Unit!&#34;);
return null;
}
bool fatal = false;
for (uint i = 0; i < TU.NumDiagnostics; ++i)
{
fatal |= DealingWithDiagnostic(TU.GetDiagnostic(i));
}
if (fatal)
{
Log.Error(&#34;Fatal Erros to stop!&#34;);
return null;
}
Index.Dispose();
return TU;
}
8.1.1 需要Parse的头文件
因为需要进行处理的头文件可能有多个, 我们这里可以支持多个头文件Parse, 其实就是通过一个临时生成的头文件进行包装来实现的:
var tmpfile = Path.GetTempFileName() + &#34;.cxx&#34;;
var lines = new List<string>();
foreach(var source in sources)
{
lines.Add(string.Format(&#34;#include \&#34;{0}\&#34;&#34;, source));
}
File.WriteAllLines(tmpfile, lines);
后续传入libclang进行编译的文件就是这个临时生成的*.cxx 文件.
8.1.2 编译生成AST
我们使用CXTranslationUnit.TryParse()这个静态方法即可完成对指定源代码的编译:
CXTranslationUnit TU;
CXTranslationUnit_Flags tmpFlag = CXTranslationUnit_Flags.CXTranslationUnit_DetailedPreprocessingRecord;
var error = CXTranslationUnit.TryParse(Index, tmpfile, new ReadOnlySpan<string>(args), null, tmpFlag, out TU);
其中的args就是前面介绍到的外部指定的-I, -D命令行参数, 这些与标准的c++ compiler的含义一致, 对于仅包含头文件的处理情况, 会比完整编译代码简单很多, 正常来说正确通过-I指定头文件包含路径, 通过-D指定必要的宏声明, 就满足需要了.
比较特殊的是tmpFlag, 此处我们指定了:
CXTranslationUnit_Flags tmpFlag = CXTranslationUnit_Flags.CXTranslationUnit_DetailedPreprocessingRecord;
这个标识用于需要对宏信息进行处理的情况, 默认宏会直接被展开, 生成的AST里不包含这部分内容.
libclang对宏的处理比较特殊, 使用相关标识后, 所有宏相关的节点会出现在CXTranslationUnit的最头部, 而不是具体在代码实际使用的位置, 读取宏信息的时候需要注意这一点. 8.1.3 错误处理
代码中可能存在错误, 这种情况下我们没法继续后续AST分析的过程, 我们需要输出错误日志, 让使用者知道出现问题, 尝试修复代码, 错误处理的代码也比较简单, 也是利用libcalng本身的Api能力来完成的:
if (error != CXErrorCode.CXError_Success)
{
Log.Error(&#34;Failed to parse Translation Unit!&#34;);
return null;
}
bool fatal = false;
for (uint i = 0; i < TU.NumDiagnostics; ++i)
{
fatal |= DealingWithDiagnostic(TU.GetDiagnostic(i));
}
if (fatal)
{
Log.Error(&#34;Fatal Erros to stop!&#34;);
return null;
}
一般的Warning不影响AST的生成, 这种情况下后续步骤可以继续, 但对于有Fatal的情况, AST并未正确生成, 此时我们直接向调用方返回null对象.
8.1.4 编译小结
整个过程我们需要注意以下几点: 1. 整个流程与我们平时对代码进行编译是高度一致的. 2. 一些-I -D等命令行参数与常规的compiler保持一致. 3. 代码出错情况的处理. 4. 最终返回的CXTranslationUnit.
8.2 libclang AST的组成
前面我们也介绍了, c++源代码由libclang进行Parse之后, 会产出一个CXTranslationUnit对象, 其中包含了完整的AST表达, C++本身的语法比较复杂, 组成AST的部分, 我们可以简单看成两大部分: - Cursors - Types
Cursors提供了AST的结构表达, 而Types则为结构添加最后的细节描述. 比如对于一CXXMethodDecl[函数定义]类型来说, 参数表和返回值的类型为这个节点提供了最终的约束, 一起完善了整个Cursor的信息. 这也是跟动态解释类型语言差异比较大的地方.
8.2.1 一个简单的示例
我们先以一段简单的代码和它对应的AST来初步了解一下源码和AST之间的关系:
namespace math {
class Ray {
protected:
Vector3 mOrigin;
Vector3 mDirection;
public:
Ray();
Ray(const Vector3& origin, const Vector3& direction);
/** Sets the origin of the ray. */
void setOrigin(const Vector3& origin);
//... something ignore here
};
} //namespace math
对应的AST:

与源码一一对应的看, 还是比较好了解AST中对应Cursor的作用的.
8.2.2 Cursors概述
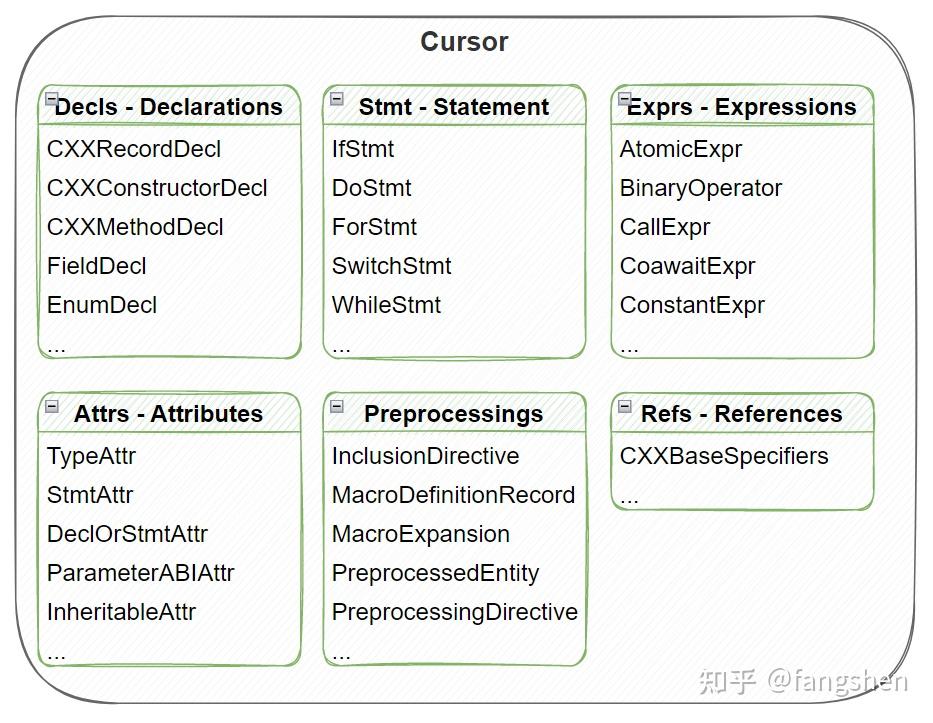
因为C++本身语法的复杂度, 相关的Cursor类型还是比较多的, 不过我们也可以根据离线工具的具体作用来做一些针对性的学习, 比如: - 读取类定义信息辅助代码生成 - 这种一般涉及到的多为Decls类型的节点. - 代码静态分析检查 - 这种一般会涉及到Stmt 和 Exprs类型的节点. - 宏信息提取和处理 - 这种基本只涉及到Preprocessings类型的节点. - Meta Attributes - 这种一般涉及到Attrs节点. 复杂度较高的Cursor主要还是集中在Stmt和Exprs部分. 但因为跟源代码语法基本是一一对应的关系, 上手难度并不高.
8.2.3 Types概览
c++复杂的类型系统始终是离线工具处理的一大难点, 如下图所示, 我们给出了c++中大概的类型分类:

类型系统的复杂度主要体现在: - c++中众多的builtin类型 - 用户可以通过自定义的方法扩展大量的UDT(如class和enum等) - c++支持如Pointer和Reference, Array这些进阶类型, 这些类型还能相互嵌套作用 - 类型可以加const, volatile等修饰, 形成新的类型 - 我们还能通过using, typedef为类型指定别名 - 再加上c++11开始扩展的关键字, 我们可能还会使用auto, decltype, typeof进行类型表达 - 模板的支持带来了更复杂的类型系统表达(复杂度比较高, 本篇直接先略过了).
所以整个类型系统的复杂度是步步攀升, 基本上离线工具处理的难点就集中在这一部分了. 当从某个Cursor中解析到一个Type, 很多时候我们需要层层递进的分析, 才能最终解析出它实际的类型.
小提示: 就这点来说, compiler time很多时候我们是可以规避掉deduce部分的细节, 只要有最终的结果, 或者我们可以更多的利用编译期递归来处理类型相关的逻辑, 所以最终我们的反射工具其实是compiler time + offline tools组合平衡的模式, 这样一方面性能会比较优, 另外也能更多的借助两边擅长的部分来处理相关逻辑. 8.2.4 AST遍历 - CXCursor的VisitChildren()使用
在libclang中, 我们更多的通过callback方式来访问c++的AST, 在 ClangSharp中也同样支持这种方式, 我们先来看一下相关API的定义:
namespace ClangSharp.Interop
{
[UnmanagedFunctionPointer(CallingConvention.Cdecl)]
[return: NativeTypeName(&#34;enum CXChildVisitResult&#34;)]
public unsafe delegate CXChildVisitResult CXCursorVisitor(CXCursor cursor, CXCursor parent, [NativeTypeName(&#34;CXClientData&#34;)] void* client_data);
public CXChildVisitResult VisitChildren(CXCursorVisitor visitor, CXClientData clientData)
{
var pVisitor = Marshal.GetFunctionPointerForDelegate(visitor);
var result = (CXChildVisitResult)clang.visitChildren(this, pVisitor, clientData);
GC.KeepAlive(visitor);
return result;
}
}
这个就是使用P/Invoke方式来封装的一个libclang中的API, 对应的Api是clang_visitChildren, 在ClangSharp中, 我们最终是直接使用CXCursor.VisitChildren()这个成员方法来完成对相关AST节点的子节点的访问的.
8.3 一个C#版-ast-dump的实现
熟悉clang的同学可能知道clang是可以通过命令行参数来支持AST输出的:
clang -cc1 -ast-dump your_file.c
clang -cc1 -ast-view your_file.c
clang -cc1 -ast-print your_file.c
在正常的编译流程中, 我们很少需要对AST进行分析和处理, 基本很少使用相关功能.
但对于离线流程来说, AST的输出就变得特别重要了.
因为我们离线程序的输入就是AST, 所以我们经常会 输出AST来进行检查. 开发阶段有类似-ast-dump的工具存在, 是比较重要的.
libclang本身并没有直接提供最终的Api, 但利用ClangSharp本身, 实现类似的功能并不复杂, 利用上一节中介绍过的遍历一个Cursor所有子节点的方式, 我们就能完成相关功能的封装了. 上面我们看到的AST示例, 就是使用我们的AstDumpTool来实现的. 我们来看一下AstDumpTool的核心实现:
private static void PrintASTByCursor(CXCursor cursor, int level, List<string> saveList)
{
bool needPrintChild = true;
saveList.Add(GetOneCursorDetails(cursor, level, out needPrintChild));
unsafe
{
PrintCursorInfo cursorInfo = new PrintCursorInfo();
cursorInfo.Level = level + 1;
cursorInfo.SaveList = saveList;
GCHandle cursorInfoHandle = GCHandle.Alloc(cursorInfo);
cursor.VisitChildren(VisitorForPrint,
new CXClientData((IntPtr)cursorInfoHandle));
}
}
主要是利用我们前面介绍的CXCursor.VisitChildren()这个成员函数来完成对某节点下的所有下级子节点的访问, 而对应的callback函数, VisitorForPrint(), 本身也是个递归的实现, 我们会利用它来继续访问子节点的下级子节点:
private static unsafe CXChildVisitResult VisitorForPrint(CXCursor cursor, CXCursor parent, void* data)
{
CXClientData tmpData = (CXClientData)data;
var tmpHandle = (GCHandle)tmpData.Handle;
var cursorInfo = tmpHandle.Target as PrintCursorInfo;
bool needPrintChild = true;
cursorInfo.SaveList.Add(GetOneCursorDetails(cursor, cursorInfo.Level, out needPrintChild));
if (needPrintChild)
{
unsafe
{
PrintCursorInfo childInfo = new PrintCursorInfo();
childInfo.Level = cursorInfo.Level + 1;
childInfo.SaveList = cursorInfo.SaveList;
GCHandle cursorInfoHandle = GCHandle.Alloc(childInfo);
cursor.VisitChildren(VisitorForPrint,
new CXClientData((IntPtr)cursorInfoHandle));
}
}
return CXChildVisitResult.CXChildVisit_Continue;
}
真正负责生成每个节点格式化字符串内容的函数是GetOneCursorDetails(), 这个其实就是根据Cursor的类型产生不一样的格式化字符串, 实现也比较简单:
private static string GetOneCursorDetails(CXCursor cursor, int level, out bool needPrintChild)
{
string indentContent = GetIndentString(level);
string declKind = &#34;&#34;;
if (cursor.DeclKind != CX_DeclKind.CX_DeclKind_Invalid)
{
declKind = cursor.DeclKind.ToString();
}
needPrintChild = false;
string nodeContent;
if (cursor.IsAttribute)
{
var attr = ClangSharp.Attr.Create(cursor);
////var attr =.GetOrCreate<ClangSharp.Attr>(cursor);
nodeContent = $&#34;Attr: {attr.Kind.ToString()} \&#34;{attr.Spelling}\&#34;&#34;;
needPrintChild = false;
}
else if (cursor.IsDeclaration)
{
var decl = ClangSharp.Decl.Create(cursor);
nodeContent = $&#34;Decl: {decl.Kind.ToString()} \&#34;{decl.Spelling}\&#34; <{cursor.KindSpelling.CString}> &#34;;
needPrintChild = true;
}
else if (cursor.IsExpression)
{
// ... something ignore here
needPrintChild = false;
}
else if (cursor.IsPreprocessing)
{
// ... something ignore here
needPrintChild = false;
}
else if (cursor.IsReference)
{
// ... something ignore here
needPrintChild = false;
}
else if (cursor.IsStatement)
{
// ... something ignore here
needPrintChild = true;
}
else
{
string typeName = cursor.KindSpelling.CString;
nodeContent = $&#34;Others: {typeName} \&#34;{cursor.Spelling}\&#34;&#34;;
needPrintChild = true;
}
return $&#34;{indentContent} {cursor.Kind.ToString()} {nodeContent}[{cursor.Location.ToString()}]&#34;;
}
通过libclang的Callback机制和少量的格式化字符串处理, 我们c#版的-ast-dump就基本完成了.
小提示: ClangSharp的使用感觉比较好的上手方法是实际拿一个简短的代码自行执行相关过程, 查看相应输出. 9. 结构化的AST
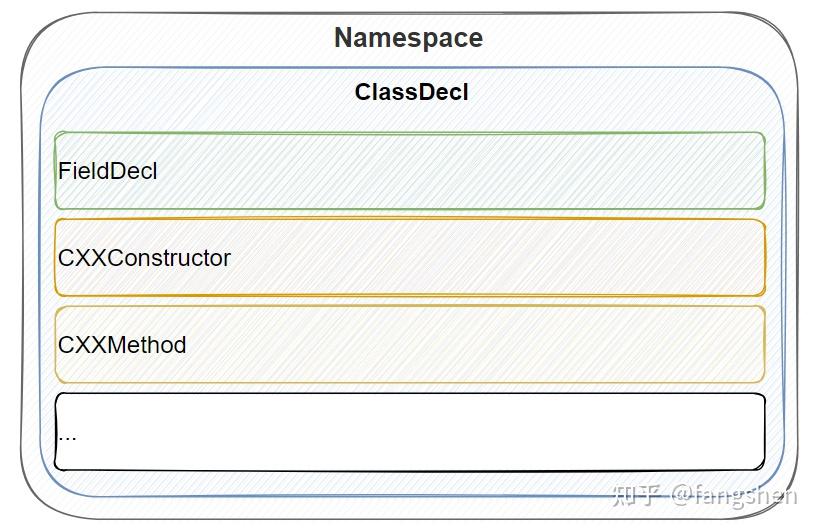
前面我们介绍了c++ AST的基本表达, 对于HighLevel的ClangSharp来说, 某个namespace下的类的定义, 其结构如下:
9.1 需要结构化AST的原因
实际的工程使用中, 我们需要处理的类可能分散在多个不同的.h文件中, 比如Vector3被定义在vector3.h中, 而Ray被定义在ray.h中, 实际的处理过程, 再加上一些前置声明, 我们可能会在不同的Cursor上处理这些相关的内容, 这对于多Pass的处理, 或者一些自定义的数据注入(比如后续会介绍的MetaAttribute支持), 都会是一个障碍, 所以虽然ClangSharp有提供对比原始的callback好用很多的HighLevel支持, 我们还是需要一层自己的c# structured AST组织, 方便刚才提到的几点: 1. 更好的多Pass支持, 不需要每次处理都重复整合和过滤数据. 2. 方便在需要的节点加入自定义数据, 处理定制流程, 如meta attribute支持.
9.2 整体的处理流程
加入自定义的结构化ClangAST层, 整个处理流程如下所示:
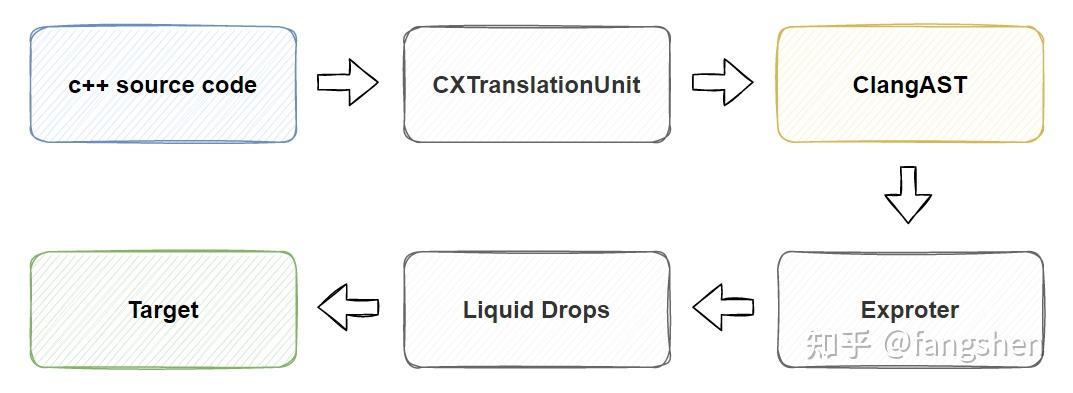
9.3 结构化AST的代码组织 - ClangAST
整个ClangAST的组织也比较简单, 主要包含了对ClangSharp各个Cursor对象的浅封装(***Node), 我们来简单看一下ClangAST的成员:
public class ClangAST
{
public CXTranslationUnit NativeTranslationUnit { get; private set; }
public ClangSharp.TranslationUnit TranslationUnit { get; private set; }
public TranslationUnitNode RootNode { get; private set; }
public Dictionary<string, NamespaceNode> AllNamespaceMap { get; private set; } = new Dictionary<string, NamespaceNode>();
public Dictionary<string, ClassDeclNode> AllClassMap { get; private set; } = new Dictionary<string, ClassDeclNode>();
public Dictionary<string, EnumDeclNode> AllEnumMap { get; private set; } = new Dictionary<string, EnumDeclNode>();
public Dictionary<string, TypedefNode> AllGlobalTypedefMap { get; private set; } = new Dictionary<string, TypedefNode>();
public Dictionary<string, ClassTemplateNode> AllClassTemplateMap { get; private set; } = new Dictionary<string, ClassTemplateNode>();
public Dictionary<string, ClassTemplateSpecializationNode> AllClassTempInstanceMap { get; private set; } = new Dictionary<string, ClassTemplateSpecializationNode>();
public Dictionary<string, UsrKeyNode> AllUsrKeyNodeMap { get; private set; } = new Dictionary<string, UsrKeyNode>();
public Dictionary<string, ClangSharp.Type> AllUsedTypeMap { get; private set; } = new Dictionary<string, ClangSharp.Type>();
public Dictionary<string, CXType> AllBasicTypeMap { get; private set; } = new Dictionary<string, CXType>();
public Dictionary<string, ClassDeclNode> AllWithMetaClassMap { get; private set; } = new Dictionary<string, ClassDeclNode>();
public Dictionary<string, EnumDeclNode> AllWithMetaEnumMap { get; private set; } = new Dictionary<string, EnumDeclNode>();
};
9.4 结构化AST小结
如上图所示, ClangAST是由我们对CXTranslationUnit做了第一轮Parse后产生的结构化数据, 其中的ClassDeclNode 和 EnumDeclNode等都是对ClangSharp中对应对应的浅封装, 这样处理之后: - 能过滤掉绝大部分不需要使用到的数据. - 在不对AST做重复遍历的情况下, 快速获取需要的类或者枚举等数据. - 可以很方便的在XXXNode中加入定制逻辑. - 对应的Drop实现针对性更强, 结构化产生的XXXNode与Liquid Drop之间基本是一一对应的关系. - 各种方便使用的Dictionary<>的存在可以快速的查询需要用到的数据.
所以对于一些比较复杂的任务, structured ast这一层还是很有必要的. 整个AST也由针对compiler, 更多的变得结构化, 对象化, 更适合用来组织最终Target的生成了.
10. meta attribute支持 - 避免代码配置分离
c++从11后开始加入对attribute的支持, 如大家经常看到的:[[deprecated]]等. 但c++的attribute实现不像C#, 它其实默认是不支持玩家自定义attribute的, 我们需要在libclang那一层级定义自定义插件, 才能够让compiler能够识别自定义的attribute, 否则compiler会直接忽略掉相关的attribute定义, 并且给出warning.
10.1 基本的原理
通过扩展attribute来实现attribute的自定义, 明显是很不适合用来定制的. 所以最后我们选用的是一个比较折中的方案, 利用可以携带任意字符串的annotate attribute来完成这部分工作:
__attribute__((annotate(&#34;custom strings&#34;)))
也可以表达为:
[[annotate(&#34;custom strings&#34;)]]这样, 对应的annotate attribute就会被AST正确的识别, 我们在处理相关的节点的时候可以正确的读入它.
10.2 c++侧的包装 - 借助宏
当然, 考虑到业务层使用的规整性, 我们使用宏对annotate做了一些包装:
#if defined(CLANG_GENERATOR)
#define RSTUDIO_META_KEYWORD_SEPARATOR_INTERNAL ____
#define RSTUDIO_META_KEYWORD_SEPARATOR_ARGUMENT_INTERNAL &#34;|&#34;
#define RSTUDIO_META_WORD_COMBINE(X, Y) RSTUDIO_JOIN(RSTUDIO_JOIN(X, RSTUDIO_META_KEYWORD_SEPARATOR_INTERNAL), Y)
#define RSTUDIO_META_LEADER_WORD_INTERNAL rmeta
#define RSTUDIO_META_COMBINE_IMPL(X) RSTUDIO_JOIN(RSTUDIO_META_LEADER_WORD_IMPL, X)
#define RSUTDIO_META_TO_STR_IMPL2(X) #X
#define RSUTDIO_META_TO_STR_IMPL(X) RSUTDIO_META_TO_STR_IMPL2(X)
#define RSTUDIO_META_IMPL(X, Y) \
__attribute__((annotate(RSUTDIO_META_TO_STR_IMPL(RSTUDIO_META_WORD_COMBINE(RSTUDIO_META_LEADER_WORD_INTERNAL, X)) \
RSTUDIO_META_KEYWORD_SEPARATOR_ARGUMENT_INTERNAL Y)))
#define RSTUDIO_META_CLASS_LEADER_WORD_IMPL class
#define RSTUDIO_META_FUNCTION_LEADER_WORD_IMPL function
#define RSTUDIO_META_FIELD_LEADER_WORD_IMPL field
#define RSTUDIO_META_ENUM_LEADER_WORD_IMPL enum
#define RSTUDIO_META_NOT_SET_WORD_INTERNAL not_set_internal
#define RCLASS_IMPL(FEATURE, ARGUMENT) \
RSTUDIO_META_IMPL(RSTUDIO_META_WORD_COMBINE(RSTUDIO_META_CLASS_LEADER_WORD_IMPL, FEATURE), ARGUMENT)
#define RCLASS(FEATURE, ...) RCLASS_IMPL(FEATURE, #__VA_ARGS__)
#define RCLASS_LUA(...) RCLASS_IMPL(lua, #__VA_ARGS__)
#else
#define RCLASS(FEATURE, ...)
#define RCLASS_LUA(...)
#endif
这里其实简单参考了UE相关的设定, 利用__VA_ARGS__来解除宏能够接受的参数列表的限制, 机制并不复杂, 但有不少辅助宏的定义. 以具体的例子来看:
class RCLASS_LUA(desc = &#34;abc&#34;, id = 5, browser = false) TestVec;
对应的宏会被展开为:
__attribute__((annotate(&#34;rmeta___class___lua&#34; &#34;|&#34; &#34;desc = \&#34;abc\&#34;, id = 5, browser = false&#34;)))
这样, 我们在C#中加入对annotate节点的识别和解析, 相关的数据就能够被我们的工具正确使用了.
另外, 为了避免对代码的干扰, 我们只有在CLANG_GENERATOR宏被声明的情况下, 对应的宏才会被解释成annotate, 否则定义的宏则是一个空实现.
class和struct声明对attribute支持会比较特殊, 你只能在class和类名中间加入你的attribute, 所以就有了上面略显怪异的写法, field和method的attribute支持可以直接写在对应的成员和函数定义之前, 看着就会舒服很多. 10.3 c#侧对attribute的识别
借助clangsharp, 我们就能很好的在c#中实现对前面定义的annotate attribute的识别了, 这里我们以class对应的attribute识别为例:
if(cursor.kind == CXCursorKind.CXCursor_AnnotateAttr)
{
//Handle meta information
////var attr = ClangSharp.Attr.Create(cursor);
var attr = ParentAST.TranslationUnit.GetOrCreate<ClangSharp.Attr>(cursor);
string meta = attr.Spelling;
string errorMessage;
var metaAttr = CustomAttributeTool.ParseMetaStringFor(meta, CustomAttributeTool.kMetaClassLeaderWord, out errorMessage);
if (metaAttr == null && !string.IsNullOrEmpty(errorMessage))
{
Log.Error($&#34;[Error] handle meta not right, detail: {errorMessage}!, location:{cursor.Location.ToString()}&#34;);
}
else
{
MetaMap.MetaList.Add(metaAttr);
if(MetaMap.MetaList.Count == 1)
{
//Just call here when the first meta attribute handle
if(this is ClassDeclNode)
{
ParentAST.AddWithMetaClass(this as ClassDeclNode);
}
}
}
}
当我们处理的子节点类型为CXCursorKind.CXCursor_AnnotateAttr时, 我们就需要对该节点做进一步的处理, 这个地方我们是通过一个CustomAttributeTool的自定义类来处理相关的解析的, 因为自定义的meta attribute很多时候会带有一些额外的语法规则, 所以可以考虑自己实现一个简单的词法分析器来处理这种情况 , 也能对meta attribute错误使用的情况提供异常日志输出等功能, 这部分跟clang本身关系不大, 这里就不展开了.
有了对meta attribute分析的工具类, 读取出具体meta attribute包含的信息就比较简单了, 在合适的地方使用它们即可.
10.4 meta attribute的使用
meta attribute的使用主要包括两部分: 1. 对导出本身进行细节性的控制 2. 为c++ runtime提供元数据, 这个就比较类似原生C#的attribute的作用了
10.4.1 对导出的控制
比如有一些field或者function并不需要被导出, 或者我们导出子类的时候, 不需要导出基类, 这种我们都能通过attribute很好的进行扩展, 如:
class RCLASS_LUA(ignore_base = true) TestVec: public AllocObj {};
通过这种方式, 我们甚至都不需要额外的配置文件, 在c++中通过我们的meta attribute扩展就能很好的完成对类的导出的控制了, 避免代码和配置分离, 这在一些特定的场合是非常有用的.
10.4.2 为c++ runtime提供元数据
还有一些场合, 我们的类可能被用于一些特殊场景, 如我们之前项目碰到的情况 , 如:
struct RCLASS_PB(msgid = 1) TestPBMessage {
public:
RFIELD_PB(id = 1)
float x;
RFIELD_PB(id = 2)
double y;
RFIELD_PB(id = 3)
uint64_t z;
};
就是通过meta attribute为结构体注入protobuf相关的信息, 这样如果离线工具正确的提取并注册了这些信息, 我们在c++ runtime的时候, 就能利用这些信息驱动相关的业务逻辑了, 这种情况下, meta attribute的使用与C#的完全一致, 我们可以为类的meta数据存入一些业务定制的内容, 极大的扩展反射体系能够带来的优势 .
具体protobuf运行时序列化反序列化的细节跟本篇关系不大, 此处也直接略去了. 11. 总结
本篇主要讲解了利用libclang和ClangSharp, 如何实现一套离线的反射工具, 与之前介绍的运行时反射结合, 一起来起来实现一个工业级的反射方案. 同时我们也探讨了在这个方案下怎么来实现类c#的meta attribute 的方法. 工具相关的具体代码我们并没有过多的展开, 这块更多还是细节向的实现.
12. Reference
- ClangSharp
- liquid
- dotliquid
- fluid
- ClangSharp依赖的动态库编译
|
|


 发表于 2022-12-1 17:54:41
发表于 2022-12-1 17:54:41