|
|
非程序员,到处查文章的理解,引用信息可能有误,个人理解可能有误,请批判着看。文中经常有“我想”“我理解”并不是想显示我多能思考,只是表示观点很主观,很可能是错的。
语言本身只是一种标准,语言本身的规范只是基础。计算机这几十年的发展,需求越来越复杂,程序包体积越来越大。对语言的封装才是应用语言满足需求的基础。
人的天性是用更轻松的方式做事,程序员的需求就是用更少的代码量实现更复杂的需求。核心就是能标准化的代码封装。
对于代码本身的影响力,就是越能让程序员轻松使用 代码的标准封装解决需求,影响力就会越大。
对于程序员来说,就得学习怎么去更好的使用这些标准封装实现需求才叫会写代码。
规范是一种实现思路,以及思路的实现细节,是个“计划”,官方一般会在发布规范的时候自己实现最基础的部分,但现实,真正发展过程中,社区或其他公司都会贡献力量,有很多时候反而是外部给的更好。
JAVA
1995年5月23日,Java语言诞生。
JAVA=JAVA编程语言+JAVA解释器 跟C++最根本的不同是JAVA语言编译后不能直接被计算机运行。编译包含了语法检查,代码优化,生成目标代码的过程。 JAVA编程语言+JAVA编译+JAVA解释器=C++编程语言+ C++编译。
JAVA称为解释性语言的原因就是JAVA编程的程序,经过编译后生成的最终语言不是机器能识别的二进制语言,还需要JAVA解释器(JVM JavaVirtualMachine(Java虚拟机)才能运行。
JAVA版本
写JAVA程序必须安装JDK。JAVA的版本实际就是JDK的版本。Java Development Kit (JDK)是 Java 语言的软件开发工具包,它包含了JAVA的运行环境(JVM+Java系统类库)和JAVA工具。
JVM :语言还是那个语言,但你用语言写出来的东西,想让机器听懂,需要JDK配套的翻译才行。 比如某年规定了“翔”代表屎了,JVM不支持,你说了机器也听不懂。
JAVA类库:就是很多给你写好的组件,让你通过简单的一两句实现一个很复杂的功能。可以理解为包到你代码里的工具。
JAVA工具:编程过程中涉及的编译,文档等等外部工具。
JRE:JVM+JAVA类库是你编写的程序运行所必需的,合在一起成为JRE(JavaRuntimeEnvironment)
1996年1月,第一个JDK-JDK1.0诞生。JDK包含的基本组件包括:
javac – 编译器,将源程序转成字节码
jar – 打包工具,将相关的类文件打包成一个文件
javadoc – 文档生成器,从源码注释中提取文档
jdb – debugger,查错工具
java – 运行编译后的java程序(.class后缀的)
appletviewer:小程序浏览器,一种执行HTML文件上的Java小程序的Java浏览器。
Javah:产生可以调用Java过程的C过程,或建立能被Java程序调用的C过程的头文件。
Javap:Java反汇编器,显示编译类文件中的可访问功能和数据,同时显示字节代码含义。
Jconsole: Java进行系统调试和监控的工具
JDK1.0的代表性技术有:Java虚拟机、Applet、AWT等。
JDK1.1的代表性技术有:JDBC、JavaBeans、RMI、JAR文件格式、Java语法中的内部类和反射。
JavaBean
“1997年2月19日,Sun公司发布了JDK1.1,代表技术:JAR文件格式、JDBC、JavaBeans、RMI等,Java语法也进行了增强,内部类(Inner Class)和反射(Reflection)出现。“来源:星光:简述Java发展历史
“JavaBeans事实上有三层含义。首先,JavaBeans是一种规范,一种在Java(包括JSP)中可重复使用的Java组件的技术规范,也可以说成我们常说的接口。其次,JavaBeans是一个Java的类,一般来说,这样的Java类将对应于一个独立的 .java文件 ,在绝大多数情况下,这应该是一个public类型的类。最后,当JavaBeans这样的一个Java类在我们的具体的Java程序中被实例之后,这就是我们面向对象的对象,我们有时也会将这样的一个JavaBeans的实例称之为JavaBeans。总之,就是Java中的接口、类和对象。“JavaBeans_百度百科
JDK里面的JavaBeans就是官方提供的,已经写好的,程序猿可以加到自己代码里调用的程序段。
JAVA体系
JAVA程序应用在不同方面,所需要的库和工具等是不一样的。比如用在移动端和用在服务器端是不一样的。不管对于内部团队的研发,外部客户的使用,全部打包在一起都是不合理的。所以后来JAVA分成了三个体系,本质是JDK里具有的组件是帮助不同方向开发用。
1998年12月8日,JDK1.2——第二代Java平台的企业版J2EE发布。
JKD1.2的代表性技术有:Swing、Java IDL、EJB、Java Plug-in等,在API文档中,添加了strictfp关键字和Collections集合类。
1999年6月,Sun公司把Java体系分为三个方向:
J2SE(Java 2 Standard Edition,Java 2平台的标准版),应用于桌面环境;包含那些构成Java语言核心的类。比如:数据库连接、接口定义、输入/输出、网络编程
J2ME(Java2 Micro Edition,Java2平台的微型版),应用于移动、无线及有限资源的环境;J2ME 包含J2SE中一部分类,用于消费类电子产品的软件开发。比如:呼机、智能卡、手机、PDA、机顶盒
J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应用于基于Java的应用服务器。包含J2SE 中的类,并且还包含用于开发企业级应用的类。比如:EJB、servlet、JSP、XML、事务控制
J2EE
2017 年 8 月,Oracle 决定将 Java EE 移交给开源组织,最后 Eclipse 基金会接手。
由于甲骨文不允许开源组织用 Java 的名号,于是 Eclipse 选出了 "Jakarta EE" 和 "Enterprise Profile" 两个后续名字,最终前者以 64.4% 的票数获胜。也就是说,Java EE 已经正式更名为 Jakarta EE(雅加达)。
应用程序运行的位置就是程序的开发应用方向:前端程序
桌面(个人PC)JavaSE,个人PC上安装个JAVA写的程序,因为微软windows不具备对JVM的原生支持,还要个人用户去配置运行环境是不现实的,所以开发桌面程序用JAVA不受欢迎。
移动端(手机,PAD,机顶盒等)JavaME, 现在是安卓,苹果的天下,
虽然官方安卓语言是JAVA和Kotlin,但用JAVA写安卓程序不等于用JAVAME,安卓程序有自己的类库,自己的运行环境,JAVA写出来的程序不能叫JAVA程序,叫安卓程序。
苹果ios系统版本,开发语言是Objective-C;
所以JAVA在移动端也没什么好发力的了,JavaME算是已淘汰。
远端服务器端 JavaEE。
一个完整的应用分为前端和后端,前端就是用户用的那一段,可以是桌面程序,app,浏览器。 后端就是在远处响应前端请求的服务器。
JAVA在前端没那么大掌控的根本原因是前端都握在巨头手里,操作系统 微软.google,apple, 浏览器,google,微软。
但后端,最重要的是掌握的用户自己手里(这里的用户是服务提供的企业),它们考虑的就是好开发,好招人,稳定,开发效率高。
从现实中来说,阿里和美团用Java较多,而腾讯和百度的后端开发C++、php用得比较多。
JAVA语言确实比C++具有一些便利上的优势,最重要的是JAVA在发展中因为自己努力加上大家捧场,在后端开发的市场热度上算是第一语言,据说腾讯和百度没有技术债的很多新业务线也都是用java多。毕竟好开发,好招人,稳定。
应用服务器
“应用服务器是指通过各种协议把商业逻辑曝露给客户端的程序。它提供了访问商业逻辑的途径以供客户端应用程序使用。应用服务器使用此商业逻辑就像调用对象的一个方法一样。
随着Internet的发展壮大,“主机/终端”或“客户机/服务器”的传统的应用系统模式已经不能适应新的环境,于是就产生了新的分布式应用系统,相应地,新的开发模式也应运而生,即所谓的“浏览器/服务器”结构、“瘦客户机”模式。应用服务器便是一种实现这种模式核心技术。“应用服务器_百度百科
对应上面说的“浏览器/服务器”结构的话,服务器端程序的叫WEB应用,通信协议就是http/https。
“瘦客户机”模式就是部署在客户端的程序尽量少的处理应用逻辑。通信协议可以自己来定。
需要说一下通信协议:
“Internet 的传输层有两个主要协议,互为补充。无连接的是 UDP,它除了给应用程序发送数据包功能并允许它们在所需的层次上架构自己的协议之外,几乎没有做什么特别的事情。面向连接的是TCP,该协议几乎做了所有的事情。“
“为了实现不同网络之间的互连,美国国防部于1977年到1979年间制定了TCP/IP体系结构和协议。TCP/IP是由一组具有专业用途的多个子协议组合而成的,这些子协议包括TCP、IP、UDP、ARP、ICMP等。TCP/IP凭借其实现成本低、在多平台间通信安全可靠以及可路由性等优势迅速发展,并成为Internet中的标准协议。在上世纪90年代,TCP/IP已经成为局域网中的首选协议,在最新的操作系统(如Windows7、Windows XP、Windows Server2003等)中已经将TCP/IP作为其默认安装的通信协议。“通信协议_百度百科
以上的意思
1.现在使用互联网传输,标准协议就是TCP/IP协议。
2.操作系统层面已经默认安装了TCP/IP协议。也就是部署在操作系统层面的程序可以很方便的实现用TCP/IP协议通信。
HTTP协议是应用层协议,浏览器和web服务器软件内dou 封装了http。
如果不选择浏览器做客户端,而选择“瘦客户机”做客户端。 比如我们平时用的,一般办公用的SAAS服务都是通过浏览器做客户端的形式。微信,百度网盘,钉钉,都是“客户机”做客户端,瘦不瘦的就不好说了。
“客户机/服务器”的模式,应用层的协议要根据应用的特点来,多数情况下,也是用http,有些情况http不合适,比如视频会议,要用到RTMP和webrtc或者QUIC协议。例如微信客户端就要支持多种通信协议来支持发送文字,图片,以及视频通话。 腾讯会议比较重,电脑上就从微信客户端里拆出去了。 对于服务端的程序是服务商控制的,为了支持更高的并发,可能拆的很碎,很多个服务端来服务一个客户端。
关于拥有Java 的挣钱方式?
JAVA 1995年-2009年属于SUN公司
2009年4月20日 Oracle以74亿美元收购Sun。
拥有语言的公司为语言的影响力扩大,出了那么多力,怎么盈利呢?
”在Sun时代大家觉得使用Java是免费的,但是其实Sun也曾对IBM和制造蓝光播放器的厂商收取许可费用。之所以对绝大多数使用者免费,是因为Sun是以这种方式来销售其他的系统。“在收购Sun六年后,Oracle终于瞄准了Java的非付费用户。
那个时候使用Java免费涵盖了利用JAVA ME,JAVA SE,JAVA EE都免费。
2017 年 8 月,Oracle 决定将 Java EE 移交给开源组织,最后 Eclipse 基金会接手。
由于甲骨文不允许开源组织用 Java 的名号,于是 Eclipse 选出了 "Jakarta EE" 和 "Enterprise Profile" 两个后续名字,最终前者以 64.4% 的票数获胜。也就是说,Java EE 已经正式更名为 Jakarta EE(雅加达)。
但JAVASE 开始收费:
“2019 年 1 月之后,Oracle 将对 Java 的使用开始收费。Java SE 的收费标准从每用户 40 到 300 美元,或者每处理器 5000 到 15000 美元不等。另外对企业而言非常麻烦的是,Oracle 并没有区分客户和合作伙伴,专家们建议下载 Java SE 时一定要谨慎,已经下载的用户在 LMS 打电话过来之前一定要对使用情况进行审查,做好充分的准备。但是目前并没有办法将需要付费的 Java SE 产品和免费的 Java SE 产品分开,Oracle 也没有提供独立的免费 Java SE 安装软件,所以无论用户是否需要,从 Oracle 官方下载的 Java SE 都将包含所有内容,也即免费和收费的内容都有,因此也必须根据 Oracle 的要求进行付费。“Oracle 屠刀下的 Java 软件公司怎么活?
WEB
HTML
HTTP
socket
web server
JAVA applet
满足对动态内容的需求
JAVA发展积累的第一批大用户是因为JAVA applet,在当时Java Applet是实现动态内容呈现的唯一方式,大多数人学习JAVA语言的目的是编写applet。“1996年1月23日,JDK1.0发布,纯解释型的Java虚拟机(Sun Classic VM)、Applet、AWT等诞生。”来源:星光:简述Java发展历史
最早的计算机都是单机执行程序。
后来有了互联网,通过浏览器使用,远程计算机将结果通过网络返回给浏览器显示。
浏览器是个程序,是个解读网站内容的软件。
最初的浏览器只能解读纯html,只能显示文字,图片等静态内容,多媒体等能动的内容是显示不了的。(在 1994 年大多数都在使用 Mosaic, )
后来Java 语言的开发者自己开发了一个浏览器,并演变为 HotJava 浏路器。这个浏览器能识别HTML文件中的JAVA代码,然后下载一个JAVA程序执行环境,然后执行网页中的JAVA代码。嵌入在网页中的JAVA代码是一个程序Java Applet。在Java Applet中,可以实现图形绘制,字体和颜色控制,动画和声音的插入,人机交互及网络交流等功能。
怎么理解这是个JAVA applet程序?
首先JAVA applet是个JAVA程序,是一种特殊的JAVA程序,怎么体现它是特殊的呢?
首先编写applet程序的时候,代码里要引用applet类,(import java.applet.Applet;import java.awt.*;)
编码是下命令,画一个图形 ,设置颜色 :
Draw a rectangle width=250, height=100g.drawRect(0,0,250,100);
//Set the color to blue
g.setColor(Color.blue);
这个命令实际复杂的实现过程是你引用的类来做的。
编译没什么不一样,编译是把你引用的类的代码包到你程序里进行翻译的过程。 也就是你虽然实际写了10行代码,但翻译的代码其实真正包含了100行代码。
applet类跟其他的类不一样的地方在于它要求的执行环境是配合浏览器所要求的JVM的特殊执行环境的。不能直接被普通的jVM执行。
所以,虽然支持JAVA的浏览器在识别到JAVA代码时,会下载一个JVM插件或本地JVM。但JVM执行的时候是配合浏览器的机制的。是有限制的执行。我理解是jvm负责解释给浏览器,浏览器负责渲染, 表现出来就是applet的程序要嵌入HTML文件中来执行。
所以,因为JAVA厂家开发了applet类,并且与浏览器协商一致提供运行环境,就能轻松的实现网页的多媒体效果。
所以后来,不止JAVA自己开发的浏览器,其他浏览器也开始支持applet程序的运行。 根本原因是用户对这种多媒体效果有需求,而只有JAVA applet实现了。
JAVA applet为什么没落了?
JAVA语言的定位跟C++一样,后来逐渐演变为一种复杂的通用编程语言。JAVA的应用领域很广,WEB端的动态显示只是一小部分,JAVA开发人员对JAVA applet后续往更好用,更轻量的发展上投入不够,相比后来出现的很多替代技术Macromedia Flash、Microsoft Silverlight,HTML5 、javascript等,在WEB端的动态显示并不具有优势。随着用户端,厂商端对其支持力度的下降(FLASH有个大视频网站使用,浏览器内置对HTML5 、javascript的支持等),自然就渐渐式微。
JAVA applet,Macromedia Flash、Microsoft Silverlight、javascript,HTML5 对网页动态内容的支持是一样的吗?
(HTML5不放到里面做比较,因为html5发布比较晚-2008年,JavaScript是html5的基本组成部分;html5是用于在WWW上结构化和表示内容的HTML的最新版本,用于创建基本结构并在WWW中显示内容,JavaScript是用于构建网页行为的动态脚本和解释性编程语言,用于定义网页中的互动元素。)它们实现的方式本质上其实是一样的,都是为了在HTML本身局限上的扩展,扩展的方式是让浏览器执行除了HTML之外的另一种语言编写的程序,本质上浏览器提供了“容器”-其他语言的执行环境:JAVA applet 要下载JVM,后来JAVA开发了浏览器插件。Flash有插件。MicrosoftSilverLight也是插件,javascript提供了内置支持,但javascript想实现太复杂的功能,也需要插件。
插件就是浏览器提供外部程序运行环境的“容器”。 但这个运行环境的理解不能简单理解为JVM那样的纯翻译,甚至超出了JRE(JVM+JAVA类库)的范畴。比如 JAVA 为JAVA applet开发浏览器插件,需要编译,JVm和applet的类库,还需要执行逻辑一起封装。插件本身就是个完整的程序。 浏览器包着很多程序(插件)插件里面再包着特定类型的程序(applet程序,或flash程序等)。
因为都是在浏览器内部执行另外一个程序的方式,程序能实现非常复杂的逻辑,只要语言支持,有人愿意写。所以逻辑上这些语言能支持的动态内容其实是一样的。 但在现实发展中,又不一样,JAVA applet能实现的效果是基于applet类库的,如果官方不再更新类库,普通开发者不太可能自己去从头写那么复杂的逻辑。 所以,我理解applet最终实现的也就是一些简单的动态效果。
Flash 就不一样了,从95年的Future Splash Animator发布出来,就可以通过软件内简单的工具和时间线组成,可视化的去开发flash内容,到后来更新的版本不断的支持通过非常简单的方式开发flash内容。
| .版本名称 | 更新时间 | 增加功能 | | Future Splash Animator | 1995年 | 由简单的工具和时间线组成 | | Macromedia Flash 1 | 1996年11月 | Macromedia更名后为Flash的第一个版本 | | Macromedia Flash 2 | 1997年6月 | 引入库的概念 | | Macromedia Flash 3 | 1998年5月31日 | 影片剪辑,Javascript插件,透明度和独立播放器 | | Macromedia Flash 4 | 1999年6月15日 | 文本输入框,增强的ActionScript,流媒体,MP3 | | Macromedia Flash 5 | 2000年8月24日 | 智能剪辑,HTML文本格式 | | Macromedia Flash MX | 2002年3月15日 | Unicode,组件,XML,流媒体视频编码 | | Macromedia Flash MX2004 | 2003年9月10日 | 文本抗锯齿、ActionScript2.0,增强的流媒体视频行为 | | Macromedia Flash MX Pro | 2003年9月10日 | ActionScript2.0的面向对象编程,媒体播放组件 | | Macromedia Flash 8 | 2005年9月13日 | 详见Flash8 | | Macromedia Flash 8 Pro | 2005年9月13日 | 方便创建FlashWeb,增强的网络视频 | | Adobe Flash CS3 Professional | 2007年 | 支持ActionScript3.0,支持XML | | Adobe Flash CS3 | 2007年12月14日 | 导出QuickTime视频 | | Adobe Flash CS4 | 2008年9月 | 详见Flash CS4 | | Adobe Flash CS5 | 2010年 | FlashBuilder、TLF文本支持 | | Adobe Flash CS5.5 Professional | 2011年 | 支持 iOS 项目开发 | | Adobe Flash CS6 Professional | 2012年 | 支持HTML、3D转换 | | Adobe Flash CC Professional | 2013年 | 完全放弃原有结构代码,基于Cocoa从头开发原生64位架构应用 | | Adobe Flash CC(2014) Professional | 2014年 | 重新引进高度直觉化且流线型的“移动编辑器” |
Flash能提供的非常简单的开发方式相比JAVA的方式容易多了,我理解这是flash迅速崛起最重要的原因。何况在浏览器上只需要一个比JAVA applet轻量多的一个 flash player插件就能解读这些内容。
Flash应用面非常广,网页动态效果,视频,游戏。Flash的开发,可以像我们使用photshop一样创建各种直观的图形,然后结合flash的脚本语言ActionScript实现很复杂的互动逻辑。
(由于拥有直观的脚本语言,同时也结合了动画等美术流程,创作一款 Flash 游戏的难度相对较低。ActionScript是Flash的脚本语言。多用于Flash互动性、娱乐性、实用性开发,网页制作和RIA(富互联网应用)开发。ActionScript遵循ECMAscript第四版标准的脚本语言, 只能在Adobe Flash Player运行时环境执行,它在Flash内容和应用程序中实现交互性、数据处理及其他富应用功能。)
也所以,FLASH比JAVA applet体验更好的时候,开发者会选择用FLASH来实现。浏览器也会转而对JAVA applet支持没那么积极了。
后来的阶段,几乎所有浏览器都支持FLASH插件。JAVA applet就没落了。
Javascript既然理论上也能实现Flash能实现的,为什么在那么长的时间并没有去做Flash做的事情?
其实各种编程语言本身虽然有这样那样的区别和特点,但这些特性都不足以成为它们在某一领域成功或失败的直接原因。时代需求,商业逻辑,大家捧不捧场才是它发展的关键因素。
Javascript出现时的定位就是轻量,解决web互动的问题,它拿下与HTML亲密搭档这个地位的过程中,Flash已经在那个领域如日中天了,在很长的时间Javascript官方和社区都没有任何理由去做而已。
Flash的失败是拜给了开源,我估计根本原因也是因为html5发布而且将JavaScript作为html5的基本组成部分,说白了就是Flash的实现有官方支持的,免费开源的实现方式了。(HTML5 2008年发布,2015年,YouTube宣布,停止继续使用Adobe Flash作为默认设置,使用HTML5视频播放器作为视频默认设置。2020年12月开始,FlashPlayer将不再受Chrome浏览器支持。) 十几年的时间,JavaScript生态逐步发展到能完全替代Flash能做的事情。
JavaScript怎么替代flash呢? 你得解决开发简单和运行轻量的问题。
JavaScript通过开发框架和JavaScript运行插件,来实现开发简单和运行轻量。框架本来就是所有生命力强大的核心,框架是语言生态最重要的一部分。
javascript框架在HTML5出现以前就已经发展壮大了,只是偏重于web互动领域而已。DoJo(2005)、ExtJS(2007)
jQuery(2006)。
应该说javascript取代Flash原本做的事情只是自然发展中一个自然而然的事情。
比如JQuery百度百科介绍是:封装JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互。
比如 一个叫 Chris Smoak 的程序员,发起一个使用 JavaScript/HTML5 实现 Flash 功能的开源项目,Smokescreen,可以将 Flash 动画转换为纯 HTML5 + JavaScript,以便脱离 Flash 插件,直接在浏览器中实现 Flash 风格的动画。
javascript也发展到不再只局限于WEB开发,(我理解这个市场需求是不是很多程序员熟练使用JavaScript,有做服务端开发的需求,又不想学新的语言。这种情况只会发生在JavaScript因为本来领域的霸主地位,有足够多的人使用它,导致市场需求足够大的情况)
Node.js发布于2009年5月,由Ryan Dahl开发,是一个基于ChromeV8引擎的JavaScript运行环境,使用了一个事件驱动、非阻塞式I/O模型,[1]让JavaScript 运行在服务端的开发平台,它让JavaScript成为与PHP、Python、Perl、Ruby等服务端语言平起平坐的脚本语言。
所谓服务端=web服务器软件,web就是浏览器向web服务器软件发送请求要东西,
Web服务器的工作原理可以分为以下四个步骤: ①连接过程:是Web服务器与其浏览器之间建立的连接。检查连接过程是否实现。用户可以找到并打开虚拟文件套接字。该文件的建立意味着连接过程已经成功建立。 ②请求过程:Web浏览器利用socket文件向其服务器发出各种请求。 (3)响应过程:在请求过程中发出的请求通过使用HTTP协议传输到Web服务器,然后执行任务处理。然后,通过使用HTTP协议将任务处理的结果传送到网络浏览器,并且在网络浏览器上显示所请求的界面。 ④关闭连接:是最后一步——响应过程完成后,Web服务器与其浏览器断开连接的过程。Web服务器的上述四个步骤联系紧密,逻辑严密,可以支持多进程、多线程以及多进程、多线程混合的技术。
Web只是提供了一个可以执行服务器端程序和返回(程序生成的)响应的环境,没有超出功能的范围。
个人用户开始用互联网应该在90年代,中国接入互联网是1995年。
前面说过,浏览器1994 年大多数都在使用 Mosaic,后来Java 语言的开发者自己开发了一个浏览器,并演变为 HotJava 浏路器。
Apache最开始是Netscape网页服务器之外的开放源代码选择。后来它开始在功能和速度超越其他的基于Unix的HTTP服务器。1996年4月以来,Apache一直是Internet上最流行的HTTP服务器。(Unix/Linux/Windows/MacOS等操作系统下使用最广泛的免费HTTP服务器:Apache、Nginx、Tomcat。Windows Server系列操作系统使用IIS,Apache是使用最广泛的Web服务器。)
所以在那个年代,可能因为发展初期,要呈现的内容还没那么复杂,还没有动态网页这个需求。web服务器软件只需要会识别HTML的需求即可。
后来,网页要呈现的东西有了更多需求:比如 a.一个记数器 b.顾客信息表格的提交以及统计 c.搜索程序 d.WEB数据库。 web服务器自身不支持,为什么不能支持?
1.浏览器和web服务器之间的交流使用的是http协议,HTTP协议(超文本传输协议)是一种网络通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。意思是网络两端对数据的最终处理都是把HTML和二进制字节信息进行转换。所以浏览器和web服务器最基础的功能就是建立连接+解析HTML。
它们怎么用HTML来进行交互呢?
浏览器通过发送http请求的时候,除了发送你要的地址信息,还会把自己的能力一并告诉对方“我认识中文,我现在有本字典是xX“。 比如会通过发送Accept-charset:ASCII 的信息,常见的字符编码有gb2312、gbk unicode、utf-8。 它就是字典,规定了比如 0010 0001=“A“ 。网络里流动的是0和1. 浏览器根据字典“字符编码”翻译出来。
我刚试了下从微信聊天窗口里复制一个表情图标,在这粘贴就变成了“[耶]”,在微信窗口里手打输入[耶],点击发送就会变成一个图标。 这就是微信app内置了一个字典,它的字典里
[耶]=

。
浏览器最核心的部分是渲染引擎,真正解读“0”“1”的都是渲染引擎,它自己解读+调用其他的插件,进行渲染,在浏览器窗口进行排列布局显示。
比如 开源引擎wbekit,我们用的很多浏览器chrome,safari等都是基于wbekit开发了自己的渲染引擎,进而加入很多其他的功能形成完整的浏览器。
HTML是规范,它是描述性文本,HTML命令可以说明文字,图形、动画、声音、表格、链接等。可以理解为浏览器引擎按照html规范,编写了自己的翻译字典,它在解读到<html>文本的时候,就知道,我要通过HTML的字典来翻译接下来的文字,看到 <meta charset=&#34;UTF-8&#34;> 知道要再调另外一个字典把字符翻译成对应的文字,
看到 <h1>一级标题</h1>,就将“一级标题“四个字用标题的格式显示出来。看到<br/>的时候,就是要换行。
解读到<img>就是要显示一张图片, <img src=&#34;url&#34; /> url是图片地址,浏览器要再次请求服务器把这张图片传送这来。 这是现在通常的做法。
以前经常会把图片直接以编码的形式嵌入到HTML里,以文本的形式存在。不需要二次请求。浏览器可以直接根据字符解析成图片进行显示。
比如这样的字符
data:image/gif;base64,R0lGODlhkQAtAKIAAAAAAP///1a+5zfn9wAAAAAAAAAAACH5BAEAAAQALAAAAACRAC0AQAP/SLrc/jDKSau9uIrsxN5cAxJeSI5MmV6q4r1w3JKRDC/2W1Mz3/GoVO8UE2GGK+MEVQoKP04XKJqJBj+/DpUVGXgb3vAA/GWIz2EFekxIq8WLcnxNr8sddnd7bUn7v2V/e4BjhIaDg4WJinCBhWdvi5B/j5WIgolvelxCIU5bSRygV1kQOVoySyY0WkqfnKESr7GotDtStzi4OLNSSKgzvxZIpKC6rKKrysNWxstHzs+UjZWPmYbUlpOLbZds1YeU3mjj5OWObF1565Pg7nqQmuzz5PT2m6I3ykXPyzf8+fQd8XfMRItopqiQ0oBslUKEpgp6upJKRMVSEpccHOgi/9eDUVZqdRqGMSJGYR2JQDNWrJWtkR8hpnyZ0Ei0KTJ3meT1ZMqPnC6BlpzZ8VPFHEZt1Cgi7CIRgTGhPkVKVeFIJjUdgqojj52ye/H6iQ0hTh6iPWglzTFXj5u2b+rSxcUDTw6ftXceiBPkhtCcs2XNgutGTc1aTePOuQ3nd9pZCPjMbILzN2/YS265mZEQWfLkvJAjdx5LurTp0xpGoJSlNHXV1kthro4Jk8WpnheRAgN4wuCWhbxaC81I03bvfcSNf1SS+pnVfVAIJme4vDhtnRqnT5WqO3jS7z6Ys7a4lKn26g3FVwnZqVd460QzsnT6dLdH77+IURwqi796/P/ZnYcea/R1d9197wnoy08JwobfbMXsR5NUTyTkoC/0yZeeScONUgoTPag2HDIjJtdSgLO5NGB8x8WHxXj9bZhMSS++lGJsKqoEowoh9qhDQTdmpV6N2PGEHI4YXugfagEdxJtFr1FFwV1d2SENZZKYw+SWZIBFB15y/QWml1/OM6VdoGVywV7tvFWll2g14s2bZIZJJ5wTsJlYnOggpiY2jMiJyTt8vmVJN36iadafaXqWZaHWFMYHm435cQ1c9TBmaJlWHrJnaIYWGklf1iAWiGCZFZbWZImV9Y2mc4rWqKmwUsonYLVWQ5iqr1IGqK+5hjpNr2fWmWmWXA32jrEFzJL5QAIAOw==
。
我记得多年前上网,想保存下网页的图片,直接右键存储为html,所有图片都保存下来了。在本地看的时候直接打开html文件就行。
现在再右键保存,会多一个保存图片的文件夹,图片可能不全。本地打开html,发现很多图片没有。
最初的浏览器只支持解读HTML,类似 <img src=&#34;url&#34; />解读到从远端服务器下载,还是直接在本地解码显示都是能支持的。
HTML可以直接解读很多元素,图片<img>,但对于其他的比如文档,声音,视频等,HTML自身无法搞定,
有个object 标签,可以支持文档,比如PDF <object type=&#34;application/pdf data=&#34;/media/examples/In-CC0.pdf&#34;,声音等。 但并不是HTML解释器本身来解读,需要调用外部插件来支持。比如java applet就是最原始那个外部的支持力量。 后来的flash也一样。
这些新元素的支持,是随着HTML不断发展,逐步支持的。1993年HTML首次以因特网草案的形式发布,然后经历了2.0、3.2和4.0,直到1999年的HTML4.01版本稳定下来。由于发展缓慢,逐渐的被更加严格的XHTML取代。现在最新的是HTML5。因为HTML5的出现,Flash被干掉了。因为HTML5自己直接支持视频播放了。
字符集,最常用的编码方式是 ASCII UTF-8 和 UTF-16
charset:规定 HTML 文档的字符编码;
我们常见的<meta http-equiv=&#34;Content-Type&#34; content=&#34;text/html; charset=UTF-8&#34;>
HTML中,content=&#34;text/html; charset=gb2312&#34;;XML中 encoding=&#34;UTF-8&#34;
Accept-Language: zh-cn,zh;q=0.5
意思: 支持的语言分别是简体中文和中文,优先支持简体中文。
zh-cn:表示简体中文,zh:表示中文(包括简体中文,繁体中文)
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
意思:优先支持中文,如果没有中文则支持英文。
q:表示他之前语言的权重, 0 <= q <= 1
————————————————
内容首部
| 首 部 | 描 述 | | Content-Encoding | 对主体执行的任意编码方式 | | Content-Length | 主体的长度或尺寸 | | Content-Type | 这个主体的对象类型 |
HTML中的ContentType Content-Type,连接类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件。 例如将:ContentType设置为image/jpeg,那么浏览器打开页面将会作为图片来下载
Content-Type的类型如下:
常见的媒体格式类型如下:
text/html : HTML格式
text/plain :纯文本格式
text/xml : XML格式
image/gif :gif图片格式
image/jpeg :jpg图片格式
image/png:png图片格式
以application开头的媒体格式类型:
application/xhtml+xml :XHTML格式
application/xml : XML数据格式
application/atom+xml :Atom XML聚合格式
application/json : JSON数据格式
application/pdf :pdf格式
application/msword : Word文档格式
application/octet-stream : 二进制流数据(如常见的文件下载)
application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
html自身有它的局限性,有很多实现不了的功能,要么借助“插件”,但插件相对较重,一个插件就是一个小的程序, 浏览器自带的解释器能直接解读是最好的。1995年,为了解决在浏览器层面对表单验证的功能诞生了JavaScript。 这个功能其实用当时出现的java applet逻辑上是可以实现的。但用java实现需要编译,需要浏览器额外下载JRE。太重了。
前面说过,互联网时代最初的浏览器是Mosaic,Netscape收购了Mosaic,在Mosaic的基础上,开发了面向普通用户的新一代的浏览器Netscape Navigator。并开发了脚本语言JavaScript。1996年3月,Navigator 2.0浏览器正式内置了JavaScript脚本语言。这个商业逻辑很重要。浏览器公司自己开发语言,自己内置到解释器,是最简单的推广方式。 JavaScript跟java没关系,也是因为推广的因素跟SUN公司达成一致,借助JAVA的名气取了个像小弟的名字。
表单验证是网页与用户的互动方式:比如你要让用户填一个表,姓名,电话,地址是必须的。当用户点击“提交”的时候,你怎么知道用户已经把必需填的项目填上了?不可能提交完了人工验证不行,再让人家填。 这个html做不了,jAVA能做但太麻烦了,JavaScript能做,而且直接用浏览器,不用下载插件。
但直接让解释器多解释一种语言,解释器的负担大了岂不是比下载插件更恶心?
JavaScript的原始设计目标是一种小型的、简单的动态语言。对解释器加的负担不重。另外,这是需求实实在在存在,JavaScript是最优的解决方式。JavaScript给自家浏览器内置了做个表率。 以后其他浏览器也不好说,你给弄个插件的方式我才支持你。 这也是市场博弈。
JavaScript虽然诞生于支持表单验证,但可以实现页面的效果切换、动画效果、页面游戏等效果。
CSS
在HTML发展的过程中,随着市场需求的增多,HTML语言本身也一直在增加各种元素,一个网页里的元素分为两大部分:内容本身和内容排版。排版是感受层面,专业叫“显示属性”,内容决定是一条狗,排版决定了是一条漂亮的狗。 这算是两个不同的方向,HTML发展到后来,虽然尽力做排版,但只是让语言更臃肿。于是有其他人站出来专门搞排版,CSS出现了。
1995年的www网络会议上CSS博斯演示了Argo浏览器支持CSS的例子,哈肯也展示了支持CSS的Arena浏览器。96年,微软Internet Explorer浏览器支持CSS标准。
前端开发的基础语法,由HTML+CSS+JavaScript组成,这是前端开发最基本的3个语言。CSS与JavaScript是两个有着明确分工的领域,前者负责页面的视觉效果,后者负责与用户的行为互动。
所以,一般浏览器的解释器应该是内置就支持解读这三种语言的。
JAVA Servlet
Servlet是一种独立于平台和协议的服务器端的Java技术,可以用来生成动态的Web页面,与传统的CGI(公共网关接口)和许多其他类似CGI技术相比,Servlet具有更好的可移植性、更强大的功能,更少的投资,更高的效率,更好的安全性等特点。
动态web
这里的动态网页,跟上面的动态内容概念不一样。 上面的动态内容可以理解为动画,画面是动的,但内容是在客户计算机上实现的。
但这里的动态核心意义在于服务器端“动态获取内容”,需要服务器端动态的,配合数据库的数据,解读客户端的需求。
简单理解下,比如购物车,每个人的购物车里内容是不一样的。 服务器端不可能张三存一个HTML页面,里面是你购物车的内容,李四存一个HTML页面,况且,你删除,增加一个东西,是不是要再创建一个页面呢?这样设计的话,每次都要通过网络传给你一个完整的页面,太没效率。 动态的实现就是,第一次你打开购物车页面,里面就一样东西,你添加一个东西,服务端会往数据库写多了一个东西,然后把这个东西的数量图片等信息,传送给你显示出来。
动态网页会涉及登录,注册,搜索等等功能的实现,核心是要动态的于服务器端的数据库进行交互。
类似 <img src=&#34;url&#34; />这种从远端服务器下载图片的方式算动态吗?
不算,动态指的是会变化的,这种代码里已经有了确定的地址,它只是改善了内容在服务器上的存储方式而已。仍然是一次连接发送所有内容,只是要多次请求而已。我理解在http1.1出现之后,这种在HTML自身的升级就能实现了。
HTTP1.0每请求一个元素需要新建一次链接, <img src=&#34;url&#34; />这种在http1.0是不合适的。
HTTP 的第一个标准化版本 HTTP/1.1 ( RFC 2068 ) 于 1997 年初发布,<img src=&#34;url&#34; />这种方式在协议层面就没问题了。
从远端获取后存到本地缓存,数据不变,下一次不需要重新从远端获取数据。 动态网页必须每一次都从远端获取的数据,因为本地缓存的数据不准。
AJAX算动态吗?
AJAX 技术的核心是实现局部刷新。只是将以前每次获取内容都要发送整个页面的方式,改成了每次只需要获取新请求的内容。它提升了刷新效率,但只是改变了前端的逻辑,对于后端没区别。
AJAX的场景:第一次加载你在网页右边,看到一个按钮,按钮写着“按下就爆炸”,你点击,页面其他部分不变,按钮在的部分换成了一张爆炸的图片。 也就是你点击按钮触发了浏览器向远端请求下载爆炸图片。爆炸图片本来就在确定位置。
Ajax即AsynchronousJavascriptAndXML(异步JavaScript和XML)在 2005年被Jesse James Garrett提出的新术语,用来描述一种使用现有技术集合的‘新’方法,包括:HTML或XHTML, CSS,JavaScript,DOM, XML,XSLT, 以及最重要的XMLHttpRequest。[3]使用Ajax技术网页应用能够快速地将增量更新呈现在用户界面上,而不需要重载(刷新)整个页面,这使得程序能够更快地回应用户的操作。[3]
1999年,微软公司发布 IE 浏览器5.0版,第一次引入新功能:允许 JavaScript 脚本向服务器发起 HTTP 请求。
20世纪90年代,几乎所有的网站都由HTML页面实现,服务器处理每一个用户请求都需要重新加载网页。这样的处理方式效率不高。用户的体验是所有页面都会消失,再重新加载,即使只是一部分页面元素改变也要重新加载整个页面,不仅要刷新改变的部分,连没有变化的部分也要刷新。这会加重服务器的负担。
这可以用异步加载来解决。1995年,JAVA语言的第一版发布,随之发布的的Java applets(JAVA小程序)首次实现了异步加载。浏览器通过运行嵌入网页中的Java applets与服务器交换数据,不必刷新网页。1996年,Internet Explorer将iframe元素加入到HTML,支持局部刷新网页。
1998年前后,Outlook Web Access小组写成了允许客户端脚本发送HTTP请求(XMLHTTP)的第一个组件。该组件原属于微软Exchange Server,并且迅速地成为了Internet Explorer 4.0[2]的一部分。部分观察家认为,Outlook Web Access是第一个应用了Ajax技术的成功的商业应用程序,并成为包括Oddpost的网络邮件产品在内的许多产品的领头羊。但是,2005年初,许多事件使得Ajax被大众所接受。
1999年,微软公司发布 IE 浏览器5.0版,第一次引入新功能:允许 JavaScript 脚本向服务器发起 HTTP 请求。这个功能当时并没有引起注意,直到2004年 Gmail 发布和2005年 Google Map 发布,才引起广泛重视。2005年2月,AJAX 这个词第一次正式提出,它是 Asynchronous JavaScript and XML 的缩写,指的是通过 JavaScript 的异步通信,从服务器获取 XML 文档从中提取数据,再更新当前网页的对应部分,而不用刷新整个网页。后来,AJAX 这个词就成为 JavaScript 脚本发起 HTTP 通信的代名词,也就是说,只要用脚本发起通信,就可以叫做 AJAX 通信。W3C 也在2006年发布了它的国际标准。
类似 <img src=&#34;url&#34; />这种从远端下载的方式跟允许avaScript 脚本向服务器发起 HTTP 请求本质上是不一样的?
<img src=&#34;url&#34; />这种从远端下载的方式跟一次传送HTML,在交互方面没有本质的区别。因为在一次连接的过程中,一个html里的元素不管是嵌入页面的形式,还是从远端下载的形式,一次就全部显示了。优化的只是远端服务器的存储方式而已。
但允许avaScript 脚本向服务器发起 HTTP 请求,是应用在页面有使用中有元素变化时,不需要将整个页面再传一遍,只需要传送变化的元素即可。这种叫局部刷新,AJAX 技术的核心。
动态的核心是要触发后端逻辑,以上所有的其实都是前端在喊“我要一个网页“”我要一个图片“,属于不需要动脑子的问题。 服务器端需要增加一个动脑子的模块。想针对不同情况,作出合理的响应,是需要针对不同情况编写不同逻辑。那这个模块就不能是固定的。必须是可以被编辑的。 或者说是可以根据不同情况,装入不同程序的。
最初就是web软件开放api接口,大家各凭能力开发程序来实现。这样的坏处就是每个web服务想用动态网页技术,都得自己完整的开发一遍。
CGI
后来出现了CGI标准,最初,CGI 是在 1993 年由美国国家超级电脑应用中心(NCSA)为 NCSA HTTPd Web 服务器开发的。
这个 Web 服务器使用了 UNIX shell 环境变量 来保存从 Web 服务器传递出去的参数,然后生成一个运行 CGI 的独立进程。CGI的第一个实现是 Perl 写的[1]。CGI标准提出的时候正是Perl如日中天的时候,CGI的提出当时也是主要为了解决Perl作为Web编程语言的需求。
也就是说Perl开创了一种新的方式,Perl官方实现了标准交互部分,perl语言的开发者用perl写动态web程序相对简单了,不用写交互部分,调用就行。 这种标准的实现方式命名为了CGI标准。标准提供的只是一个做事思路。理论上其他语言按照这个思路做事也能提升其他语言开发动态web程序侠侣。
CGI实现了动态WEB技术,但性能不好
CGI标准有很多缺点:
效率低下:每一个连接 fork 一个进程处理。
功能十分有限:CGI只能收到一个请求,输出一个响应。很难在CGI体系去对Web请求的控制,例如:用户认证等。
WEB软件接受的请求只有一部分是需要调用CGI程序进行解释,调用完后要进行销毁,这个调用销毁的过程,要先启动CGI解释器,然后把CGI程序装到解释器里进行解释,慢且耗资源大,就像冷车启动一样。 (比如java程序在外部运行需要JRE(JVM+对应类库),那对应的java cgi程序在web软件内部运行,也需要运行环境,JVM+CGI类库,这样你在写程序时候加的类库,才能在这个运行环境里顺利运行。这叫CGI解释器。)
解决方案就是CGI解释器启动后不进行销毁,一直运行。 但一直运行也不行吧? 更合理的是有个运行的逻辑,需要再有一个程序能进行 启动解释器,能同时启动几个,多久不用进行销毁之类的管理。
因为按照CGI标准,反而让性能受限,所以其他语言按照CGI标准实现各自语言的标准类不积极,web软件支持也不积极。在CGI诞生后的很长一段时间,各种Web Server都还是采用API这种强绑定的方式去支持Web开发。
有文章说CGI程序还有个缺点叫开发难度大、修改复杂。 但这个缺点在那个时候根本没得选。 只能说后来出现了更好的技术,你回过头来说CGI相比起来开发难度大,修改复杂。
CGI的百度百科解释:
通用网关接口(CommonGatewayInterface/CGI)是一种重要的互联网技术,可以让一个客户端,从网页浏览器向执行在网络服务器上的程序请求数据。CGI描述了服务器和请求处理程序之间传输数据的一种标准。
CGI程序的一个例子:首先用户代理程序向这个CGI程序请求某个名称的条目,如果该条目页面存在,CGI程序就会去获取那个条目页面的原始数据,然后把它转换成HTML并把结果输出给浏览器;如果该条目页面不存在,CGI程序则会提示用户新建一个页面。所有维基操作都是通过这个CGI程序来处理的。
CGI的工作方式,从Web服务器的角度看,是在特定的位置(比如:http://www.example.com/wiki.cgi)定义了可以运行CGI程序。当收到一个匹配URL的请求(服务器在认为这是一个CGI请求时),相应的程序就会被调用(调用相关CGI程序),并将客户端发送的数据作为输入。程序的输出会由Web服务器收集,并加上合适的档头,再发送回客户端。
web通过环境变量和标准输出将数据传送给CGI程序,CGI程序处理完数据,生成html,然后再通过标准输出将内容返回给服务器,服务器再将内容交给用户,CGI进程退出,在这个过程中,服务器的标准输出对应了CGI程序的标准输入,CGI程序的标准输出对应着服务器的标准输入,相当于利用两条管道建立了进程间的通信。
理解下这个CGI的百科解释:
CGI技术是让网页浏览器向执行在网络服务器上的程序请求数据
但关键是跟CGI程序请求的代理程序,不是浏览器直接跟CGI程序请求。
代理程序是谁呢?
文档说了,Web服务器收到一个匹配URL的请求,去特定的位置调用相应的程序。将客户端发送的数据作为输入。
将程序的输出加上合适的档头,再发送回客户端。 所以代理程序是web服务器。
CGI可以为我们提供许多HTML无法做到的功能。比如 a.一个记数器 b.顾客信息表格的提交以及统计 c.搜索程序 d.WEB数据库,用Html是没有办法记住客户的任何信息的,就算用户愿意让你知道。用Html也是无法把信息记录到某一个特定文件里的。要把客户端的信息记录在服务器的硬盘上,就要用到CGI。这是CGI最重要的作用,它补充了Html的不足。是的,仅仅是补充,不是替代。
使在网络服务器下运行外部分应用程序(或网关)成为可能。CGI-BIN 目录是存放CGI脚本的地方。这些脚本使Web服务器和浏览器能运行外部程序,而无需启动另一个程序。
它是运行在Web服务器上的一个程序,并由来自于浏览者的输入触发。CGI是在HTTP服务器下运行外部程序(或网关)的一个接口,它能让网络用户访问远程系统上的使用类型程序,就好像他们在实际使用那些远程计算机一样。
CGI能够让浏览者与服务器进行交互,如果你曾经遇到过在网络上填表或者进行搜索,就很有可能就是用的CGI。
为什么这个技术叫通用网关接口呢?
web服务器不是只有一个,编程语言也有很多种。 将web服务器与CGI程序间交互的过程标准化,让既能让web服务器和不同编程语言的配合最大便利化。将这个标准进行代码实现,封装成api,就是接口。
对于WEB服务器来说规定对CGI程序的标准输出,编程语言要实现一个CGI类来:承接这个标准输出,转化为程序的标准输入。编程语言还要实现一个CGI类来:将获取的内容,转化为标准输出,作为web服务器要求的标准输入。
承接上边的CGI发展,其他编程语言因为它的缺点并不是很欢迎它。 自己要发展更好的技术来替代。在这个编程语言的发展路线有来了分歧。
Fast CGI
Fast CGI是CGI标准的发展,它的出现解决了CGI的效率问题。
FastCGI,就是多了一个cgi进程管理器。cgi进程管理器不是web软件来实现,是对应编程语言来实现的。我理解不同编程语言的CGI程序进程管理都是不同的,让web软件来内置实现太复杂了。web软件只管说“你要不支持这种更合理的方式,我就不支持你用“。 对于web软件来说,多支持一种语言模式就是多一份负担。
FAST-CGI 的发布时间查不到。FAST-CGI 是微軟爲了解決 CGI 解釋器的不足而提出改進方案。为什么是微软提出来的呢?查不出更多的信息,貌似没说微软只是提了个实现思路,没有将fastCGI的实现
据说WEB开发有个&#34;3P“的说法,指的是 Perl /PHP / Python。PHP,Python,Perl的解释器都是以FastCGI模式加载到Web服务器。
Python 在 2000 年代开始让 Perl 黯然失色,并一度成为编程入门的首选语言.Perl已经淘汰了,不深究它的Fast CGI实现了。
PHP-Fast CGI
2004年Andrei Nigmatulin发明了PHP-FPM ,让php实现了Fast CGI.
PHP-FPM(FastCGI Process Manager)就是可以放置在web软件内部的FastCGI进程管理器, PHP-FPM 的基本工作原理:在 PHP-FPM 中,master 进程负责与 Web 服务器进行通信,接收 HTTP 请求,再将请求转发给 worker 进程进行处理,worker 进程主要负责动态执行 PHP 代码,处理完成后,将处理结果返回给 Web 服务器,再由 Web 服务器将结果发送给客户端。
Python-WSGI
WSGI最初于2003年推出,并于2010年更新.WSGI是基于Python 对Fast CGI的进一步改进
But,事情总是还有改进的余地的,FastCGI这套工作模式实际上没有什么太大缺陷,但是有些不安分的Python程序猿觉得,FastCGI标准下写异步的Web服务还是不太方便,如果能够收到请求后CGI端去处理,处理完毕后通过Callback回调来返回结果,那样岂不是很Coooool?!所以WSGI就被创造出来了。
其工作方式大致是:当Web服务器接收到一个请求后,可以通过Socket把环境变量和一个callback回调函数传递给后端Web应用程序,Web应用程序处理完成后,调用callback函数,把结果返回给WebServer。
这种方式的优点有:
异步化,通过callback将Web请求的工作拆解开,可以很方便地在一个线程空间里同时处理多个Web请求
方便进行各种负载均衡和请求转发,不会造成后端Web应用阻塞。
从不是程序员的角度理解下这个改进:
web服务器在发送一个动态web需求的时候,
Fast CGI。web服务器要等着回复,WEB服务器要为这个请求起一个进程管理器线程,进程管理器在服务器端是master,master将请求发送给woker后,因为要得着回复,需要维持一个连接。
WSGI把callback回调函数传递给后端,不用维持连接。多个请求不需要维持多个连接。对web服务器的压力小很多。
Fast CGI,以php-fdm为例,因为回复请求都要通过master,如果多个worker处理完后,得排队等着master回复完请求才能关闭到worker进程。 worker进程数量有上限,这时候如果有新的请求进来,worker就没法处理。
WSGI的话,如果也是worker,worker调用callback函数把结果推给master,就可以kill掉自己了。master按自己节奏处理结果即可。我理解master上应该有比FAST CGI多了个数据结构是接收结果的。
SCGI 是 CGI 的替代版本,它与 FastCGI 类似,同样是将请求处理程序独立于 Web 服务器之外,但更容易实现,性能比 FastCGI 要弱一些。
FastCGIweb服务器启动后,要启动一个进程管理器进程,进程管理器再启动几个解释器,再装载对应的CGI程序进解释器。这个流程是内置在web服务器内来实现,还是在外部实现?
这个过程,如果请求少的话,对web服务器的负担还不是那么大。但如果要处理的请求太多,负担就太大了。这个流程可以分离出去,独立部署。Web 服务器可以和 CGI 响应器服务器分开部署。web软件只管对外发命令,而不因需求的增多减少而增加web服务器本身的负担。
FastCGI 与传统 CGI 模式的区别之一则是 Web 服务器不是直接执行 CGI 程序了,而是通过 Socket 与 FastCGI 响应器(FastCGI 进程管理器)进行交互,也正是由于 FastCGI 进程管理器是基于 Socket 通信的,所以也是分布式的,Web 服务器可以和 CGI 响应器服务器分开部署。Web 服务器需要将数据 CGI/1.1 的规范封装在遵循 FastCGI 协议包中发送给 FastCGI 响应器程序。
JAVA实现动态web
试想,在最初web服务器,为前端做的工作是转化HTML文件传输,开始只能抓取服务器里已经存在的文件。发展到后来可以跟后端一个程序交互,但具体怎么实现,web服务器软件提供了基本的交互api。如果你要用JAVA开发一个互动的程序,首先要解决JAVA语言的运行环境问题,然后你要解决自己程序的业务逻辑,你还得解决你的程序和web程序的交互问题。
一个java程序员要转化成一个用JAVA写 WEB动态网页的程序员,除了要学习最基本的web页面的业务逻辑,在那个一穷二白的年代,还加了额外任务,要自己写代码处理运行环境和与web服务器的交互问题。 这要求太高了,如果官方不做努力,JAVA在这块的发展肯定没戏。一个语言的影响力取决于程序员能不能轻松的用它解决问题。人选择更轻松的方式解决问题是天性使然。
JAVA servlet解决了程序运行环境问题,让程序员不用操心运行环境。
JAVA servlet 容器提供了运行环境和web服务器软件的连接, 但它只是开了个通道,具体怎么交互的实现还得你自己来,这里的交互就是:web服务器说“这有个html的需求,是需要你来做的“,容器最终的应答要是”好的,我处理一下,······(一会儿后)这是你要的HTML。 JAVA servlet 容器只提供了传输给web服务器软件的HTML通信通道,但生成什么样的HTML(业务逻辑),怎么生成HTML,还得你自己处理。
生成什么样的HTML(业务逻辑),怎么生成HTML这个问题很复杂吗?
我理解它复杂在JAVA serlet要执行的动态元素部分是和普通的HTML混合在一起的。 并不是说是这个页面完全就是JAVA写的,直接转成一个完整的HTML页面。 所以你写代码的时候HTML文件本身会作为一个很重要的元素出现在你代码结构里,但它又不想JAVA类一样是那么熟悉的交互啊方式。 程序员要额外学习很多怎么与这个不熟悉的重要元素交互,肯定要遵守很多规矩才行。
这个应该就是介绍JSP的时候会说“直接使用 Servlet 开发依旧十分繁琐“的原因。
所以SUN又推出了JSP。解决与HTML文件的相处问题。所以现在在“容器“内部又加了一个 “JSP引擎”,JSP引擎解释JSP标识和脚本,生成所请求的内容(例如,通过访问JavaBeans组件,使用JDBC技术访问数据库或者包含文件),并且将结果以HTML(或者XML)页面的形式发送回浏览器。
有文章说“Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来。而JSP的情况是Java和HTML可以组合成一个扩 展名为.jsp的文件。JSP侧重于视图,Servlet主要用于控制逻辑。&#34;
我理解这个说法是基于JSP已经出现后说的,JSP 本身是个程序逻辑,这个逻辑是用JAVA写的,它本身应该就是一个JAVA servlet,支持JSP的容器,应该就是在容器启动的时候,首先把JSP先运行起来,并作为一个一致运行的线程。 所以“Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来“,更准确的说法应该是:JSP出现后,现在我们编写servlet,不需要再考虑与html组合的表示问题,只需要通过Servlet实现内容本身的应用逻辑即可。
JAVA servlet
JAVA没等CGI标准的发展,1997年7月JAVAServlet出现。(CGI1993年出现,FastCGI提出应该在2000年左右,WSGI2003年实现, PHP在2004年实现)
开始的时候,公共网关接口(Common Gateway Interface ,CGI)脚本是生成动态内容的主要技术。虽然使用得非常广泛,但CGI脚本技术有很多的缺陷,这包括平台相关性和缺乏可扩展性。为了避免这些局限性,Java Servlet技术应运而生。它能够以一种可移植的方法来提供动态的、面向用户的内容,处理用户请求。
Servlet是一种独立于平台和协议的服务器端的Java技术,可以用来生成动态的Web页面,与传统的CGI(公共网关接口)和许多其他类似CGI技术相比,Servlet具有更好的可移植性、更强大的功能,更少的投资,更高的效率,更好的安全性等特点。
狭义的Servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的类,一般情况下,人们将Servlet理解为后者。
Servlet程序 跟普通JAVA程序有什么区别?
1.编写语言还是JAVA,
2.能实现的功能跟普通JAVA类一样,但实现的方式不一样,JAVA普通程序调用的是普通JAVA API(指的是比如JAVE EE里面封装的普通类,类是一个官方写好的JAVA程序,对外暴露API接口,写程序的时候通过API接口直接使用类能实现的相对复杂的功能,比如某个类能算开平方,你通过api传入一个4,它就能给你返回一个2.)。servlet程序是通过调用Java serlet API,Java serlet API是对开发动态网站需要使用的原生 Java API 重新进行了封装,形成的一套新的 API。
据说&#34;servlet程序几乎可以使用所有的 Java API&#34;,这个说法我有些存疑,从逻辑上讲,当然可以使用所有的Java api,但这取决于java官方是不是重新按照servlet封装了所有的普通JAVA类,但这会导致servlet程序的运行环境的类库体积跟普通JAVA的类库体积一样大,甚至更大,这样不太合理吧。
3.运行环境不一样,普通的JAVA运行环境是普通JAVA类+JVM。JVM是与计算机直接通信,翻译出来的“1“0”。Java servlet程序不与计算机直接通信,它与web服务器通信,它经过处理翻译出来的是HTML。 servlet程序的运行环境是 执行Java servlet程序,servlet 化的逻辑类+与web服务器通信的一个中间程序。 这个运行环境叫“Servlet 容器“。
servlet程序的执行和与web通信的实现都要在程序里有标准的实现,这个实现理解为servlet程序与Servlet 容器的接口和与web服务器的接口,实现了这两个接口的程序才叫JavaServlet程序。
“servlet接口是servlet主要抽象的API。所有servlet都需要直接实现这一接口或者继承实现了该接口的类。servlet API中有两个类实现了Servlet接口,GenericServlet和HttpServlet。大多数情况下,开发人员只需要在这两个类的基础上扩展来实现他们自己的Servlet。 “
程序员用这个做模板,修改里面的业务逻辑部分就好,GenericServlet和HttpServlet就是于Servlet 容器的接口和与web服务器的接口,模板里已经有了,不用自己再重新写了。
Servlet 接口和Servlet 容器这一整套规范就叫作Servlet 规范
Java Servlet API 是Servlet容器(tomcat)和servlet之间的接口,它定义了serlvet的各种方法,还定义了Servlet容器传送给Servlet的对象类,其中最重要的就是ServletRequest和ServletResponse。所以说我们在编写servlet时,需要实现Servlet接口,按照其规范进行操作。
Tomcat-JAVA web 容器
上面说了,JAVA servelt程序的运行需要一个“容器“。1997年7月JAVAServlet出现。但它想真正使用起来,跟web服务器软件不做好配合是不行的。 刚出来的时候没理由市场上流行的web服务器软件就花大力气去支持它,毕竟这是JAVA(SUN公司)的生意。于是Sun公司自己开发了一个webserver-JavaWebServer ,这是第一个Servlet容器.
现在使用者面临的选择是,要想使用JAVA实现动态web技术,你就得用JavaWebServer。 你用其他的web server就得接着用满是缺点的CGI技术实现动态web.
JAVA不是专门做webserver的,SUN的webserver好不好用不知道,但那时候 Apache HTTP Server已经出来了,并且很好用是现实。
那对JAVAServlet 最好的发展情况一定是,使用者能在 Apache HTTP Server上实现JAVA servelt。
另一面,webserver市场的情况:
1995年2月,8名志同道合的开发者决定成立一个小组开发了Apache HTTP Server。Apache HTTP Server发布后,由于其具有坚实的稳定性、异常丰富的功能和灵活的可扩展性,得到了极大的成功。1999年6月,为有效支持Apache HTTP Server以及相关软件的发展,Apache开发小组成员们成立了一个非盈利性的Apache软件基金会(Apache Software Foundation)。
Apache 旗下有很多大神,以项目的形式开发以支持Apache HTTP Server的扩展。Jakarta是apache组织下的基于Java实现的解决方案的项目。那时候实现动态web的技术最好的就是JAVA servelt, Apache组织开发了JServ,它是一个与Apache服务器集成的Servlet引擎。
很奇怪为什么之前SUN没有跟Apache组织沟通,一起开发,也许巨头门都有自己的坚持,手里没东西,不好跟别人张嘴,不过很快,SUN跟Apache开始了合作:
1999年,Sun将Java Web Server容器贡献给了ASF,使Java Web Server和JServ两个项目合并为Tomcat。Tomcat作为Sun的官方参考时限,也标志这它支持Servlet和JSP的参考标准。
Tomcat第一个版本是从3.1.1开始的,它完全支持Servlet2.2和JSP1.1标准,并集成了Java Web Server。2001年Tomcat4.0发布,并命名为Catalina,完全重新设计了架构和基础代码,Tomcat4.x系列时限了Servlet2.3和JSP1.2标准。
目前最新版本是Tomcat8
Tomcat 是Web应用服务器,是一个Servlet/JSP容器. Tomcat 作为Servlet容器,负责处理客户请求,把请求传送给Servlet,并将Servlet的响应传送回给客户.而Servlet是一种运行在支持Java语言的服务器上的组件. Servlet最常见的用途是扩展Java Web服务器功能,提供非常安全的,可移植的,易于使用的CGI替代品.
我们编写的 Servlet 类没有 main() 函数,不能独立运行,只能作为一个模块被载入到 Servlet 容器,然后由 Servlet 容器来实例化,并调用其中的方法。
一个动态页面对应一个 Servlet 类,开发一个动态页面就是编写一个 Servlet 类,当用户请求到达时,Servlet 容器会根据配置文件(web.xml)来决定调用哪个类。
servlet容器不仅具有翻译的功能,还具备挑选翻译哪个类执行的能力。对比JVM的翻译,挑选哪个类执行是程序内部的逻辑。servlet容器+servlet程序 相当于以一个把翻译内置的程序。 从这也能理解为什么Servlet 类没有 main() 函数main函数的意义就是执行引擎, serlet类里只用执行引擎规定的方式(servlet类)编写自己要怎么被执行。
JSP
直接使用 Servlet 开发依旧十分繁琐,因此 SUN 公司又推出了JSP技术。JSP 对 Servlet 再次进行了封装,JSP 经过编译后依然是 Servlet。编写的JSP页面最终将由web容器编译成对应的servlet。
SUN推出JSP,解决与HTML文件的相处问题。所以现在在“容器“内部又加了一个 “JSP引擎”,JSP引擎解释JSP标识和脚本,生成所请求的内容(例如,通过访问JavaBeans组件,使用JDBC技术访问数据库或者包含文件),并且将结果以HTML(或者XML)页面的形式发送回浏览器。
JSP 1999年6月发布。JSP发布的很及时,如果没有JSP改善基于Servlet 的繁琐开发,可能后来跟apache的合作开发tomcat,SUN会少很多筹码。
Tomcat的第一个版本(3.x)发布于1999年,该版本基本源自Sun公司贡献的代码,实现了Servlet 2.2和JSP 1.1规范。
2001年,Tomcat发布了4.0版本,作为里程碑式的版本,Tomcat完全重新设计了其架构,并实现了Servlet 2.3和JSP 1.2规范。(我想Java作为动态web技术的影响力,也是伴随着tomcat这个里程碑的版本才开始崛起)
JSP的本质就是基于JSP引擎-&#34;JSP解释器“ 来对基于JAVA的另一种规范进行翻译,它通过内置对象,解决Servlet 的繁琐开发的问题,还有衍生出来的如何简单使用它自身的问题。
现在JSP用于视图,也就是JAVA servlet实现的动态内容和HTML结合问题,以及将serlet类和HTML结合转化成纯HTML页面 输出给web服务器,Servlet主要用于动态内容自身的控制逻辑。
JSP = HTML + Java,Jsp页面看成一种特殊的html页面,只是在html页面上插入了java程序段和jsp标记,jsp页面在服务端执行之后还是返回一个html页面给浏览器。请求 JSP 时,服务器内部会经历一次动态资源(JSP)到静态资源(HTML)的转化。服务器会自动把 JSP 中的 HTML 片段和数据拼接成静态资源响应给浏览器。也就是说,JSP 运行在服务器端,但最终发给客户端的是已经转换好的 HTML 静态页面。
”JSP文件在运行时会被其编译器转换成更原始的Servlet代码。JSP编译器可以把JSP文件编译成用Java代码写的Servlet,然后再由Java编译器来编译成能快速执行的二进制机器码“ 来源:JSP_百度百科
&#34;一个JSP文件第一次被请求时,JSP引擎把该JSP文件转换成为一个servlet,JSP引擎使用javac把转换成的servlet的源文件编译成相应的class文件,对每一个请求,JSP引擎创建一个新的线程来处理请求。&#34;来源:JSP转换Servlet_影兮的博客-CSDN博客_jsp导向servlet。javac是java语言编程编译器。全称java compiler
“JSP在执行第一次后,会被编译成Servlet的类文件,即.class,当再重复调用执行时,就直接执行第一次所产生的Servlet,而不再重新把JSP编译成Servelt。“
当JSP网页在执行时,JSP Container会做检查工作,如果发现JSP网页有更新修改时,JSP Container才会再次编译JSP成Servlet; 如果JSP没有更新时,就直接执行前面所产生的Servlet。“来源JSP转译成Servlet详细过程_
我想象一下这个过程“当用户打开一个页面的时候,输入域名,客户端开始与服务器端建立连接,服务器端解析url请求信息,发现需要调用服务器上一个页面(web服务器只管顺着地址找),找到后,尝试解析,发现是JSP,需要让“容器”来解析,于是web服务器主线程将请求传递给&#34;容器“,容器一看,不是servlet,于容器再将请求传递给JSP引擎“你给转化成servlet,我再解析“,JSP引擎识别后,载入指定JSP文件,转换成一个servlet,然后“容器”开始执行这个临时的JSP转化来的servlet,执行就是解析哪插入了JAVA代码,调用对应的servlet类执行,servlet类执行去数据库核对数据,再将对应的静态文本,图片或其他信息提供,最后拼成一个静态页面(拼的动作是容器做的,但拼的逻辑在JSP里)。 容器再把生成的html位置信息通知web服务器主线程,web服务器将HTML页面解析发给浏览器显示。“
没有JSP的时候,用servlet写跟HTML关系的,你得凭想象,还得把servlet在HTML里的位置信息等用代码写出来。 现在有了JSP,可视化了,直接在HTML文件中对应的位置填入调用信息就好。写servlet类的时候不用管它应该出现在HTML的什么位置。
动态网站开发中很重要的一个问题是网页之间的信息传递和状态维护,每当网页被发送到服务器时,都会在服务器端重新生成网页。在这个往返过程(浏览器一服务器一浏览器)中,JSP提供了一些内置对象保存所有与网页关联的信息。
为简化页面的开发过程,JSP提供了一些内置对象,它们由容器实现和管理。在所有的JSP页面中,这些内置对象不需要预先声明,也不需要由JSP应用程序的编写者进行实例化就可以使用。JSP主要有out、request、response、session、application、pageContext、page、config和exception等9个内置对象。
1.Request对象
Request对象是javax.servlet.http.HttpServletRequest类的实例。代表请求对象,主要用于接受客户端通过HTTP协议连接传输到服务器端的数据。比如表单中的数据、网页地址后带的参数等。()
2.Response对象
Response对象是javax.servlet.http.HttpServletResponse类的实例。代表响应对象,主要用于向客户端发送数据。()
3.Out对象
Out对象是javax.servlet.jsp.JspWriter类的实例。主要用于向客户端浏览器输出数据。
4.session对象
Session 对象是javax.servlet.http.HttpSession类的实例。主要用来保持在服务器与一个客户端之间需要保留的数据,比如在会话期间保持用户的登录信息等,会话状态维持是Web应用开发者必须面对的问题。当客户端关闭网站的所有网页或关闭浏览器时,session对象中保存的数据会自动清除。由于Htp协议是一个无状态协议,不保留会话间的数据,因此通过session对象扩展了htp的功能。比如用户登录一个网站之后,登录信息会暂时保存在session对象中,打开不同的页面时,登录信息是可以共享的,一旦用户关闭浏览器或退出登录,就会清除session对象中保存的登录信息。
5.Application对象
Application对象是javax.servlet.ServletContext类的实例。主要用于保存用户信息,代码片段的运行环境;它是一个共享的内置对象,即一个容器中的多个用户共享一个application对象,故其保存的信息被所有用户所共享。
6.PageContext对象
PageContext对象是javax.servlet.jsp.PageContext类的实例。用来管理网页属性,为JSP页面包装页面的上下文,管理对属于JSP中特殊可见部分中已命名对象的访问,它的创建和初始化都是由JSP容器来完成的。
7.Config对象
Config对象是javax.servlet.ServletConfig类的实例。是代码片段配置对象,表示Servlet的配置。
8.Page(相当于this)对象
Page对象是javax.servlet.jsp.HttpJspPage类的实例。用来处理JSP网页,它指的是JSP页面对象本身,或者说代表编译后的servlet对象,只有在JSP页面范围之内才是合法的。
9.Exception对象
Exception对象是java.lang.Throwable类的实例。处理JSP文件执行时发生的错误和异常只有在JSP页面的page指令中指定isErrorPage=“true”后,才可以在本页面使用exception对象。
原文链接:浅谈Servlet和JSP_白泯的博客-CSDN博客_servlet jsp“ 中说“JSP 只能接受HTTP请求,但Servlet可以接受所有类型的协议请求。“
这句话我不太理解,servlet不就是用来实现web动态内容的吗?WEB服务器不就是http吗?JSP只能接受HTTP请求能理解,因为与web服务器的交互部分JSP封装好了,写JSP的时候不会管协议,JSP只封装了http,那就只能接受HTTP。
但servlet不一样要通过&#34;容器“已经封装好的http协议与web服务器通信吗?
或者说,退回到“tomcat容器”诞生以前,servlet容器你愿意自己实现也行,你自己封装支持别的协议,然后你再写个客户端,用你自己的协议跟你封装的容器通信。。这也没毛病。
但要这么解释,“Servlet可以接受所有类型的协议请求。”这句话有什么现实意义吗?现实是servlet就是为web诞生的。
WAR包,JAR包
JAVA web应用
JavaWeb 应用由一组 Servlet/JSP、HTML 文件、相关 Java 类、以及其他的资源组成,它可以在由各种供应商提供的 Servlet 容器中运行。
为了让 Servlet 容器顺利地找到 JavaWeb 应用的各个组件,Servlet 规范规定,JavaWeb 应用必须采用固定的目录结构,即每种组件在 JavaWeb 应用中都有固定的存放目录。
以 Tomcat 为例,通常将 JavaWeb 应用存放到 Tomcat 的 webapps 目录下。在 webapps 下,每一个子目录都是一个独立的 Web 应用,子目录的名字就是 Web 应用的名字,也被称为 Web 应用的上下文根。用户可以通过这个上下文根来访问 JavaWeb 应用中的资源。
webapps 的目录结构如下图。
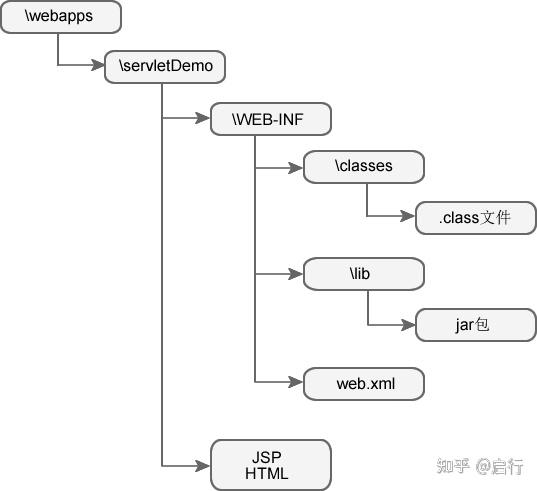
在 Tomcat 中部署 JavaWeb 应用最快捷的方式,就是直接将 JavaWeb 应用的所有文件复制到 Tomcat 的 /webapps 目录下。
Tomcat 既可以运行采用开放式目录结构(只编译不打包)的 Web 应用,也可以运行 Web 应用的打包文件(WAR 文件)。在开发阶段,为了方便程序调试,通常采用开放式的目录结构部署 JavaWeb 应用。在开发完成,进入产品发布阶段时,就应该将整个应用打包成 WAR 文件,再进行部署。来源“Servlet的部署和访问“
web.xml
XML是一种元标记语言,强调以数据为核心。.xml的文件内部就是符合XML编写规范的文本,这个文件可以是手动编写,也可以是软件生成的。
上面说了web项目里面包含那么多元素:Servlet/JSP、HTML 文件、相关 Java 类、以及其他的资源。
web.xml学名叫部署描述符文件,是在Servlet规范中定义的,是web应用的配置文件
“Web.xml是Java Web项目中的一个配置文件,主要用于配置首页、Filter、Listener、Servlet等。 tomcat在部署启动web应用时,会解析加载${CATALINA_HOME}/conf目录下所有web应用通用的web.xml,然后解析加载web应用目录中的WEB-INF/web.xml。如果没有WEB-INF/web.xml文件,tomcat会输出找不到的消息,但仍然会部署并使用web应用程序,因此,这个web.xml并不是必要的,不过通常最好还是让每一个上线的web应用程序都有一个自己的WEB-INF/web.xml。
conf/web.xml文件中的设定会应用于所有的web应用程序,而web应用程序的WEB-INF/web.xml中的设定只应用于该应用程序本身。“
WEB.XML的作用
“1、指定欢迎页面。
訪问一个站点时,默认看到的第一个页面就叫欢迎页。普通情况下是由首页来充当欢迎页的。普通情况下,我们会在web.xml中指定欢迎页。但web.xml并非一个Web的必要文件,没有web.xml。站点仍然是能够正常工作的。
对于tomcat来说,当你仅仅指定一个web的根名,没有指定详细页面,去訪问时一个web时。 假设web.xml文件里配置了欢迎页,那么就返回指定的那个页面作为欢迎页。而在文中没有web.xml文件,或尽管有web.xml,但web.xml也没指定欢迎页的情况下。它默认先查找index.html文件。假设找到了。就把index.html作为欢迎页还回给浏览器。假设没找到index.html,tomcat就去找index.jsp。
找到index.jsp就把它作为欢迎页面返回。
而假设index.html和index.jsp都没找到。又没实用web.xml文件指定欢迎页面,那此时tomcat就不知道该返回哪个文件了。它就显示The requested resource (/XXX) is not available的页面。当中XXX表示web的根名。但假设你指定了详细页面。是能够正常訪问的。
2、命名与定制URL。我们能够为Servlet和JSP文件命名并定制URL,当中定制URL是依赖一命名的。命名必须在定制URL前。
3、定制初始化參数:能够定制servlet、JSP、Context的初始化參数,然后能够再servlet、JSP、Context中获取这些參数值。
4、指定错误处理页面,能够通过“异常类型”或“错误码”来指定错误处理页面。
5、设置过滤器:比方设置一个编码过滤器。过滤全部资源
6、设置监听器:
7、设置会话(Session)过期时间,当中时间以分钟为单位,假如设置60分钟超时:“
来源:Jsp在Web.xml中的配置
首页、Filter、Listener之类的相对好理解,不用相应功能也不用设置,但既然要配置servlet,为什么还是可以不需要web.xml?
我理解下,命名与定制URL,主要是建立URL里面的命名和你实际对servlet命名之间的映射,这个映射只是改名字,应该不是必需的。如果不建立映射,在部署JAVA WEB项目的时候,会自动将实际servlet命名作为URL里面的命名。
但定制初始化參数很可能会影响到某些页面的正常显示,对于程序来说,参数是写在代码里的“变量”,在你写代码的时候,你可以给这个变量固定的值,也可以等程序执行的时候根据实际情况生成值。 假设你定义了一个变量是连接数据库的时候要通过“XXX“去链接,“XXX“代表某个JDBC的组件名称和位置。 你如果直接把这个名称位置写死在代码里,当然没问题。 但后期你如果想换其他的JDBC组件,一旦名字位置不一样了,就得在原始代码里进行更改。 这样很不方便,而且容易出错。
这时候,用“定制初始化參数”的方式就很方便了,你在web.xml中写 &#34;xxx&#34;=&#34;abc/ddd/JDBC.jar&#34; ,并规定好这个参数属于哪个程序(servlet/JSP),只有它才能引用。那在tomcat执行对应页面的时候,在代码里看到了变量“XXX“,就自动替换为&#34;abc/ddd/JDBC.jar&#34; 再执行。 这样你就不用去动原始代码了。
所以,某些情况下,web.xml确实不是必需的。但它是一个不那么“水”的程序员必需的。
&#34;web.xml,一个Tomcat工程中最重要的配置文件。web.xml没有其实也可以----只要你确定你的项目里面不需要任何过滤器、监听器、servlet等等。我试了一下,没有web.xml对那些已经编译成Servlet的jsp页面来说,是不影响正常显示的,但是那些没有编译成Servlet的jsp页面,访问的时候就会报500的错误了。&#34;引用自:创建web项目没有web.xml(WEB之web.xml详解)-爱玩科技
我理解,这个里面出现的“没有web.xml对那些已经编译成Servlet的jsp页面来说,是不影响正常显示的,但是那些没有编译成Servlet的jsp页面“ 这个错误并不是必然出现的,跟JSP代码里的引用参数有很大关系。
WAR包
war 包是 Sun 提出的一种 web 应用程序格式。也就是它是专门针对JAVA web应用的。
war里面有个非常重要,不可或缺的元素是“目录结构”,程序员在开发JAVA web项目的时候,比如创建JSP页面,保存的过程中IDE自然就放到它该在的目录。 程序员虽然不用特别关注这个目录。但这个目录是生成war包,部署war包的时候非常重要的依据。 目录本身也是访问路径的一部分组成。
我理解,部署的过程,很重要的一部分就是把项目本身的路径结合web服务器配置的URL结合作为web服务器解析的一部分。
而web.xml只是属于让JAVA web项目更灵活强大的工具。
JAR包
JAR文件是Java Archive File-java档案文件的简称。“1997年2月19日,Sun公司发布了JDK1.1,代表技术:JAR文件格式、JDBC、JavaBeans、RMI等,Java语法也进行了增强,内部类(Inner Class)和反射(Reflection)出现。“来源:星光:简述Java发展历史
jar包是对写好的类进行了打包。我们可以通过将jar包放到lib目录下来使用这些jar包中的类、属性和方法。
但你写完一个JAVA程序后,在IDE里生成JAR包的过程:1.选择所要打包的项目,右击选择Export。2.找到java 选择JAR file,点击next。3.选中java项目,JAR file选择JAR文件的储存路径,点击next继续(一个大项目里包含一些小项目)4.点击Finish,jar文件生成。
所以JAR包就是把你原始代码包起来,但我理解JAR包的精髓并不止是打包,压缩。 更重要的是JAR包能让JVM解开并顺利编译,而这个的核心是因为jar打包的时候,把项目的“目录”打包进去了,这是JVM编译的时候最核心的路径依赖。
就像前面讲的war包的目录一样的,因为这个目录在开发环境和部署环境是一一对应的。war的目录是WEB服务器执行的依据。JAR包的目录是JVM编译执行的路径依据。
JAR包是代码存在的一种形式,它代表一些.java,以及它们的执行逻辑,(依靠目录和其他什么)
WAR包和JAR包的区别
前面定义“JavaWeb 应用由一组 Servlet/JSP、HTML 文件、相关 Java 类、以及其他的资源组成”“war包是java web程序打的包,war包里包括: - 代码编译成的 class文件 - 依赖包 - 配置文件 - html,jsp“
不管servlet,JSP,JAVA类,都可以以JAR包的形式存在,但不是非必须形式,依赖包应该都是以JAR形式存在的。
所以在JAVA web这个领域来讲,JAR包属于WAR里的组成一部分。
WAR相当于简化了一个JAVA web项目开发,部署的流程。如果你现在只有JAR包,也可以以相对复杂的形式进行JAVA web项目部署。
JAVA服务器应用
从涵盖的范围来说,JAVA服务器应用>JAVA web程序>JAVA servlet程序>JSP程序。
这里JAVA web程序不能单纯理解为运行在容器里与WEB服务器交互的程序,前面说的war包是专门运行在容器里的,对应到JAVA servlet程序更合适。 JAVA web程序应该理解为服务于web整个大流程里的程序,是个逻辑概念,比如最初的JAVA web server,它是用java编写的,运行环境是部署在计算机操作系统上的JVM,它是服务于web的。它属于 JAVA服务器应用在应用场景上的一种。
比如你前端如果是桌面程序,或者安卓app,通信的协议可能不是http,那对应在服务器上用JAVA开发的程序就不是 JAVA web程序。
JavaEE就是应用在服务器应用开发方面,对应的是JAVA服务器应用
“Java EE 是在 Java SE 基础上构建的,它提供 Web 服务、组件模型、管理和通信 API,可以用来实现企业级的面向服务体系结构(Service Oriented Architecture,SOA)和 Web 2.0 应用程序。“来源:Java是什么?Java的特点有哪些?
JavaEE 号称有十三种核心技术。它们分别是:JDBC、JNDI、EJB、RMI、Servlet、JSP、XML、JMS、Java IDL、JTS、JTA、JavaMail和JAF。
对一个程序最重要的是程序的运行环境,JRE,所有的都是围绕程序运行环境展开的。
JAVAEE 规范的意思就是告诉大家怎么编写代码才能在对应的运行环境执行,比如在程序里约定什么执行逻辑,调用什么标准类。
对于围绕JAVA的生态,最重要的就是你开发的东西一定要对应某个可以运行它的环境,一般看JDK版本,因为JRE是包在JDK里的。
JDK版本有个潜规则,高版本一般是可以兼容低版本的。比如JAVA框架 Hibernate3.x版本的话,JDK版本要在1.5版本以上。
官方能掌控的就是语言的运行环境,对于一个程序的生命周期来说,开发的时候用IDE软件,编写的时候调用的框架,都不一定是官方出品,只要大家按照运行环境的规矩来就行。
比如写程序时,代码里要实现实现连接数据库,你准备在代码直接把调用Hibernate3.x,那你的IDE版本的支持JDK1.5以上。一般ide版本都内置了JDK的支持?安装IDE的时候JDK就直接安装了? 但你发现调框架的时候执行有问题时因为JDK版本问题的时候,可以不升级ide,直接设置下载更新的jdk吗? 我就不去深究了。
高并发架构
Sun的最佳实践中 推荐jsp和servlet作为view层,EJB作为业务逻辑层。
以一个HTML页面获取过程为例,客户端发请求“我要看这个HTML页面“,web服务器解析请求往后面tomcat发请求“客户端要的HTML页面在你这“,tomcat服务器解析JSP文件,解析其中JAVA写的动态部分。
解析JAVA动态部分就是业务逻辑,假设一个简单的场景是显示购物车里包含衣柜的商品,你作为淘宝的业务运营思路是“我除了给你显示衣柜的商品,还要给你在页面旁边显示床的,衣架的推荐商品“。
然后程序员通过代码编写业务逻辑实现这个思路,先去数据库里找这个用户的购物车信息,再从数据库操作筛选出包含衣柜的条目。 然后去推荐引擎输入衣柜,推荐引擎返回“你去找XX商家的1.8粉红实木大床“,程序再用推荐引擎的输出,作为去数据库的输入,筛选出对应的条目。
最后把这些所有的信息给到tomcat服务器拼成HTML静态页面,tomcat再返回给web服务器。
这个看到这里面最费脑子“CPU“的部分就是业务逻辑的处理,高并发请求的时候,最需要提升计算力的就是处理业务逻辑的部分。
这种将业务逻辑分离出来的理念的具体实现模型叫MVC模式
经典MVC模式中,M是指模型,V是视图,C则是控制器,使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。其中,View的定义比较清晰,就是用户界面。
所以随着并发的不断提高,原来将业务逻辑直接写在servlet的方式不行了,要把业务逻辑部分单独拆出来。提升计算力的方式,要么提高单台服务器的配置,但服务器配置有上限,最终的解决方案只能是把任务交给很多个人一起干,这就是“分布式处理”
分布式
因为请求数变的太大的时候,后端靠一台服务器为前端提供服务不行了,需要用很多台共同为前端提供服务。 再到后面需要把一个大服务按模块拆分成独立的服务,每个模块都部署多台来提供服务。这就是分布式。
分布式要解决的核心问题是服务间通信问题,以前都是在一台服务器上,不存在通信的问题。分布式的通信是服务器和服务器间的通信,数据包要经过程序-操作系统-底层-网络-操作系统-程序。 就像一个大机器人里,同时有很多人操作,这些人之间必须保证良好的通信是让机器人看起来像一个人一样灵活的最基础条件。 但实现起来是个复杂的问题。
分布式要解决的问题不止是通信的问题:
某个模块现在是5台,随流量增长需要10台,怎么让这10台顺利接入到这个大架构中,这是扩展问题。
比如一个请求是“我要对比现在公司工资的支出和加10个人之后工资的支持“ 这个操作,需要先从数据库读取现在公司的支支出,然后要写入10个人之后,公司工资支出变化后,再读取一个。 如果中间有其他人访问数据库写入5个人,数据就会出错。 那我们就要在处理那个请求的过程中,不允许其他人操作数据库,那个请求中读+写+读就是一个事务。 这是分布式数据库要解决的事务处理问题。
还有分布式数据存储的问题,还有通过网络传输带来的安全问题。等。
框架
一个应用的处理实现越来越复杂,但市场的需求永远都是“用最快的方式写出能满足需求的应用”,分布式带来的复杂问题与运营思路无关,与业务逻辑本身也无关,它只是让实现复杂度提升了。 这时候就要将能标准化的东西尽量标准化,让程序员的实现复杂度降下来。
框架其实跟“类”没本质区别,都是一个问题解决思路的标准实现方式的实现,只是从逻辑上理解,类一般用来程序一个小问题实现的代码段的可复用实现;框架是针对一个领域问题的很多可复用代码段的可复用实现。
EJB
EJB是Enterprise Java Beans技术的简称, 又被称为企业Java Beans,是由Sun公司发布的基于JavaEE的框架。EJB通过定义了运行bean的容器必须提供的一组服务来简化应用系统的开发,目标是部署分布式应用程序。
具体的实现方式是程序员把EJB提供的标准代码段封装到自己写的EJB程序里,再把EJB程序部署到EJB容器里。 分布式要解决的问题容器来解决。(针对怎么解决那些问题的程序实现,SUN给了标准的企业Bean,以及规定了跟它们的交互方式。 开发容器的企业负责在自己的容器软件里实现与企业bean的交互封装,与内部EJB程序的交互封装,以及企业bean组件的部署?)
1998年3月24日发布。EJB 1.0 定义了EJB和EJB容器的作用,实现与互动。
- “EJB 从技术上而言不是一种&#34;产品&#34;,EJB 是一种描述了构建应用组件要解决的标准:
可扩展 (Scalable)、分布式 (Distributed)、事务处理(Transactional)、数据存储(Persistent)、安全性 (Secure)“
EJB_360百科
EJB提供了开发者便利开发的组件,“它有三种实现:SessionBean,EntityBean,MessageDrivenBean。
SessionBean:它是对业务逻辑的封装,类似于我们经常写的Service层。它可以以local, remote, webservice 服务的方式被client调用。
EntityBean:它是对数据库对象的封装,一个EntityBean,就是数据库的一条记录。
MessageDrivenBean:一个messageDrivenBean其实就是一个javax.jms.MessageListener。在JMS中有MessageConsumer,它支持两种接收消息的方式:同步接收采用MessageConsumer#receive()方法,异步接收则是为MessageConsumer设置一个MessageListener,一旦接收到消息,就调用listener#onMessage()。“
原文链接:EJB框架 详细介绍和注解的使用
“Session Bean的种类:分为有状态的会话Bean和无状态的会话Bean(Stateful Session Bean和Stateless Session Bean)
- Session Bean的作用:Session Bean是用来实现业务逻辑的,Session Bean可以直接操作数据库,通过Entity Bean实现数据库的访问
- 无状态的Bean:
- 无状态Bean:能够被启用很多次,该Bean是可以重复使用的,就是实例化的一个实例可以由任意用户调用,在EJB容器中实现共享,性能方面往往比有状态的Bean更为优 越些。负责记录使用者的状态
- 有状态的Bean:每次客户调用都初始化一个对象,每个用户都拥有自己的一个实例,Statefull Bean必须实现Serializable接口;和无状态的Bean的开发过程一样,不负责记录使用者的状态,会消耗更多的内存“Session Bean(会话Bean)
EJB容器
EJB容器为EJB组件提供了运行环境,EJB容器管理EJB的方式与Web容器管理Servlet的方式类似,EJB必须在EJB容器里运行。EJB容器主要管理了EJB的持久性、生命周期管理、安全性管理、事务管理、远程连接、并发处理、集群和负载均衡等问题。J2EE基础之EJB全面了解_yeyinganny的博客-CSDN博客
EJB容器有 JBoss(开源),WebLogic(Oracle),WebSphere(IBM)等。
有点奇怪,EJB 98年发布出来,sun自己没有做个容器?
JBoss 在2004年 6月,JBoss公司宣布,JBoss应用服务器通过了Sun公司的J2EE认证。JBoss公司在支持JAVA前同HP、Novell、Computer Associates、Unisys等都是合作伙伴。
“EJB大概是J2EE架构中唯一一个没有兑现其能够简单开发并提高生产力承诺的组件。“EJB框架 详细介绍和注解的使用
这个说法觉得是有问题的。
简单开发并提高生产力的方式就是把一切能封装的进行封装,让程序员简单调用。但调用封装的缺点就是灵活性降低。 开发程序的需求分很多面,很多层。 官方的提供方向一定是往尽量满足一切需求。社区或第三方就尽量集中满足某一方面的需求,先立足,再图发展。
我觉得EJB不能说是失败,作为官方,开始的复杂是必须要经历的过程。EBJ1 EBJ2 到EBJ3。据说EBJ1和EBJ2的阶段,都没有突破复杂,在这个期间一些针对特定方向的,满足市场需求的优秀框架比如Struts,Hibernate,spring等得到大量应用。 EBJ3提出的时候,虽然比EBJ1,EBJ2在简单开发有了非常大的进步,但属于晚了一步进入“简单开发”的市场。
但官方和外部的发展路线并不是完全性的竞争,比如spring因为轻量化的定位取得成功,注定在很长的时间内,会比较适合中小型用户的需求。而一些大型,超大型用户,某些方面所需要的实现 是spring封装提供不了,开发灵活性受到限制。它们依然会选择EJB去做。
所以EJB看起来像是失败了一样,一是因为市场中中小用户占大多数,而是EJB发展慢了一些。但EJB在大型用户中在很长的周期内依然是刚需。也因为面对的是大型客户,所以WebLogic(Oracle),WebSphere(IBM)这样的容器服务才能收费而且能收到。
当然后面EJB3也实现了类似spring的思路实现简单化,也借助Struts,Hibernate等相对底层的框架来实现。去争取中小用户的市场。
spring也越来越复杂,去发展大型用户的市场。
它们之间还能互相结合着用
“应用EJB的标准结构是:
表现层(Struts/JSF等)+应用层(EJB中的Session Bean)+持久层(实体Bean)。
或者纯Spring的:
表现层(Struts/JSF/Spring MVC)+应用层(Spring)+持久层(ORM框架或JDBC)。
Spring+EJB的:
表现层(Struts/JSF/Spring MVC)+应用层(Spring+EJB中的Session Bean)+持久层(实体Bean/ORM框架/JDBC)。“EJB3最新的EJB标准_jianguo1224的博客-CSDN博客
Struts框架
Struts是最早的Java开源框架之一,它是MVC设计模式的一个优秀实现。
在Java EE的Web应用发展的初期,除了使用Servlet技术以外,普遍是在JavaServer Pages(JSP)的源代码中,采用HTML与Java代码混合的方式进行开发。因为这两种方式不可避免的要把表现与业务逻辑代码混合在一起,都给前期开发与后期维护带来巨大的复杂度。为了摆脱上述的约束与局限,把业务逻辑代码从表现层中清晰的分离出来,2000年,Craig McClanahan采用了MVC的设计模式开发Struts。后来该框架产品一度被认为是最广泛、最流行JAVA的WEB应用框架。
2006年,WebWork与Struts的Java EEWeb框架的团体,决定合作共同开发一个新的,整合了WebWork与Struts优点,并且更加优雅、扩展性更强的框架,命名为“Struts 2”,原Struts的1.x版本产品称为“Struts 1”。Struts项目并行提供与维护两个主要版本的框架产品——Struts 1与Struts 2。
在2008年12月,Struts1发布了最后一个正式版(1.3.10),而2013年4月5日,Struts开发组宣布终止了Struts 1的软件开发周期。 [1]struts_百度百科
Struts定义了通用的Controller(控制器),通过配置文件(通常是 Struts -config.xml)隔离Model(模型)和View(视图),以Action的概念以对用户请求进行了封装,使代码更加清晰易读。 Struts还提供了自动将请求的数据填充到对象中以及页面标签等简化编码的工具。
MVC三层属于逻辑上的层,Struts属于将这种逻辑隔离落实到分离开发的物理实现。通过ACTION对请求进行分装的意思是为了运行程序员编程时调用Struts的封装以实现这种逻辑隔离的物理实现,需要对请求中的参数进行一层翻译转化。
JSF(JavaServer Faces)
JSF 是由 Oracle 开发和维护的基于 Java 的 Web 应用程序框架。主要用于开发基于服务器的应用程序和简化基于 Web 的用户界面的开发集成。JSF 与 Struts 非常相似。
Hibernate框架
把前面的场景搬过来说明下Hibernate框架要解决的问题。
“假设一个简单的场景是显示购物车里包含衣柜的商品,你作为淘宝的业务运营思路是“我除了给你显示衣柜的商品,还要给你在页面旁边显示床的,衣架的推荐商品“。
然后程序员通过代码编写业务逻辑实现这个思路,先去数据库里找这个用户的购物车信息,再从数据库操作筛选出包含衣柜的条目。 然后去推荐引擎输入衣柜,推荐引擎返回“你去找XX商家的1.8粉红实木大床“,程序再用推荐引擎的输出,作为去数据库的输入,筛选出对应的条目。“
上面流程结束之后,你手机来了一条微信消息,退出淘宝,看微信,再打开淘宝,之前的页面没了。你又要筛选“衣柜”信息,后台又要重续一下那个复杂的流程。
这个过程里前端的操作没有任何变化,但后台又要重新执行一遍,聪明的大神想“能不能把那个结果固化,对同样的请求,直接返回结果不好吗?“。 这就是 对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping)将请求和结果(固化成对象)之间建立一个映射。
这个对象跟数据库里面存的数据不一样,它是一个“逻辑结果”,对象是逻辑结果的持久化。 这些对象要另找一个地方存放,存放的地方叫“对象数据库”。&#34;对象数据库“是个逻辑概念,使用的数据库类型仍然可以跟原来的数据库一样,比如mysql。
&#34;2001年,澳大利亚墨尔本一位名为Gavin King的27岁的程序员,上街买了一本SQL编程的书,他厌倦了实体bean,认为自己可以开发出一个符合对象关系映射理论,并且真正好用的Java持久化层框架,因此他需要先学习一下SQL。这一年的11月,Hibernate的第一个版本发布了。
2002年,已经有人开始关注和使用Hibernate了。
2003年9月,Hibernate开发团队进入JBoss公司,开始全职开发Hibernate,从这个时候开始Hibernate得到了突飞猛进的普及和发展。&#34;Hibernate_百度百科
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
Hibernate 将通过POJO用户“发请求”这个操作进行复杂的解读,POJO是Hibernate编写的标准类,专门用来将请求结果转换为对象,将对象存储到对象数据库,解读请求,看需要映射到对象数据库,还是到普通数据库等等操作。 程序员在开发程序的时候,将Hibernate下载,集成到IDE中,实际就是把Hibernate包含的POJO类之类的放到了IDE的路径下,写程序就可以直接调用。
对象数据库选择谁呢?mysql mongodb redis?
Hibernate 不考虑这个,每种数据库都有自己的特殊查询语言逻辑, Hibernate直接实现JDBC,它要支持的是标准SQL,只支持JAVA到标准SQL之间的翻译。
假如你选择了一个不支持标准SQL的数据库,那标准SQL和你选择的数据库之间的翻译,需要自己去写代码或集成其他组件去处理。
Mybatis
Mybatis是开源的持久层框架,能够度jdbc进行简单的封装,但其并不是完全的ORM(Object Relational Mapping,对象关系映射),无法脱离数据库进行适配。
“两者最大的区别:
针对简单逻辑,Hibernate和MyBatis都有相应的代码生成工具,可以生成简单基本的DAO层方法。
针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程。
开发难度对比
Hibernate的开发难度要大于Mybatis。主要由于Hibernate比较复杂、庞大,学习周期较长。
而Mybatis则相对简单一些,并且Mybatis主要依赖于sql的书写,让开发者感觉更熟悉。“mybatis与hibernate区别_java领域的博客-CSDN博客_mybatis和hibernate
也就是说程序员看自己的能力来选择用mybatis和hibernate,如果对sql很熟悉,用mybatis学习成本就相对低,而且更灵活。
如果对SQL不够熟悉,就对学习基于hibernate对SQL处理的逻辑。
Apache Hadoop Apache Hadoop
是一个开源 Java 框架,专注于处理大型数据集,处理千兆字节到 PB 级的数据。它使用简单的编程模型在计算机集群之间分配数据,并且可以轻松地从单个服务器扩展到数千台机器。 Apache Hadoop 的主要优点:
- 有效处理大数据;
- 可以检测和处理应用层的错误;
- 分布式数据存储。
- https://baijiahao.baidu.com/s?id=1744363758815943596&wfr=spider&for=pc
Spring
Spring是于2003 年兴起的一个轻量级的Java 开源开发框架,Spring 由 Rod Johnson 创立,2004 年发布了 Spring 框架的第一版。
“为什么说 Java 程序员必须掌握 Spring Boot ?
这个问题放在五年以前,还可以存在,但放到 2021 年,这个问题已经没有存在的价值了,因为所有的 Java 程序员都必须得掌握 Spring Boot 已经变成了一条定律,就像勾股定律一样。“为什么说 Java 程序员必须掌握 Spring Boot ?
”Spring的发展历程
1997年,IBM提出了EJB的思想
1998年,SUN制定开发标准规范EJB1.0
1999年,EJB1.1发布
2001年,EJB2.0发布
2003年,EJB2.1发布
2006年,EJB3.0发布
Rod Johnson(Spring之父)
2002:阐述了J2EE使用EJB开发设计的优点及解决方案
2004:阐述了J2EE开发不使用EJB的解决方式(Spring雏形)“
原文链接:Spring框架简介_李智文的博客-CSDN博客
“2002年10月,Rod Johnson 撰写了一本名为《 Expert One-on-One J2EE 》设计和开发的书。这本书介绍了当时 Java 企业应用程序开发的情况,并指出了 Java EE 和 EJB 组件框架中的存在的一些主要缺陷。在这本书中,他提出了一个基于普通 Java 类和依赖注入的更简单的解决方案。在书中,他展示了如何在不使用 EJB 的情况下构建高质量,可扩展的在线座位预留系统。为了构建应用程序,他编写了超过 30,000 行的基础结构代码。包含许多可重用的 Java 接口和类,如 ApplicationContext和BeanFactory。由于java接口是依赖注入的基本构建块,因此他将这些类的根包命名为com.interface21。在本书发布后不久,开发者 Juergen Hoeller 和 Yann Caroff 说服 Rod Johnson 创建一个基于基础结构代码的开源项目。
2003年2月左右,Rod、Juergen 和 Yann 开始合作开发该项目 。Yann 为新框架创造了“Spring”的名字。这样Spring项目就诞生了。
2003年8月,Spring1.0-m1
2004年3月,Spring1.0
2004年8月,Rod Johnson,Juergen Hoeller,Keith Donald 和 Colin Sampaleanu 共同创立了一家专注于 Spring 咨询,培训和支持的公司 interface21。
2006年10月,Spring 2.0
2007年11月,在 Rod 领导下,Interface21公司被更名为 SpringSource。
2007年11月,Spring 2.5
2008年4月,GitHub成立,方便了Spring代码迁移
2009年8月,SpringSource 以 4.2 亿美元被 VMWare 收购。
2009年12月,Spring 3.0
2012年7月,Rod Johnson 离开了团队。
2013年4月,VMware 和 EMC 通过 GE 投资创建了一家名为 Pivotal 的合资企业。所有的 Spring 应用项目都转移到了 Pivotal。
2012年10月,Mike Youngstrom 在 Spring jira 中创建了一个功能请求,要求在 Spring 框架中支持无容器 Web 应用程序体系结构。这一要求促使了2013年初,Pivotal开始了Spring Boot 项目的研发。
2014年4月,Spring Boot 1.0.0 发布。Spring Boot非常简单,这样以来java开发人员能够快速地采用它。Spring Boot可以说是在 Java 中开发基于 REST 的微服务 Web 应用程序的最快方法之一。
2015年11月,Spring boot 2.0.0 发布。“
原文链接:Spring发展史_诗人不写诗的博客-CSDN博客_spring历史
分析一下,SPring框架是后起之秀,它站在了前人的基础上,spring在自己的核心上提供了对其他框架(struts2 hibernate)优秀的整合。
SPring框架在官方3-4年之前找到了解决广大中小用户的核心诉求“基于java简单开发“的方案,作为唯一的选择,在那个计算机世界快速繁荣的时候,几年的时候已经足够spring在市场上站稳脚跟了。
当2006年EJB3.0发布出来的时候,已经有足够多的spring程序员,它们有什么动力一定要去学另外一个能做一样事情的框架?
而且,EJB需要容器,EJB3.0只是标准,程序员顺利的使用ejb3.0还得等着java ee的厂商门先支持EJB3.0,等EJB3.0广泛地为所有主要J2EE厂商所支持的时候,又一两年时间过去了。
我想在EJB3.0出来后,一定会吃掉一部分spring的市场份额,但EJB3.0最大的敌人就是人的惰性,你没有特别优势,现有的势力划分很难动。
更何况spring也在高速发展,&#34;2014年4月,Spring Boot 1.0.0 发布。Spring Boot非常简单,这样以来java开发人员能够快速地采用它。Spring Boot可以说是在 Java 中开发基于 REST 的微服务 Web 应用程序的最快方法之一。&#34;
所以才会有那个说法“所有的 Java 程序员都必须得掌握 Spring Boot 已经变成了一条定律,就像勾股定律一样。“ 因为市场对spring 程序员有足够大的需求,学习spring 就是提升自己的被需求能力。
spring framework
Spring是一个轻量级的控制反转(IOC)和面向切面(AOP)的框架。
IOC是一种设计思想, 让程序员不再关注怎么去管理对象,而是关注于对象创建之后的操作,把对象的创建、初始化、销毁等工作交给spring容器来做。
对象就是一次动态请求的“虚拟固化”,hibernate提供了实现 对象简单的生成(创建),存储到“对象数据库”等方法(初始化),但在没有spring的时候,对这个对象的利用和维护逻辑要自己实现,利用逻辑比如这个对象能不能直接嵌到另一个更复杂的需求里。(假设一个场景,淘宝运营团队需要知道一天内有多人少在订单里搜索过“衣柜”,准备以此为依据来决定要不要扩大纳入衣柜推荐系统的 衣柜供应商数量。) 维护逻辑,比如创建、初始化 ,这个对象没用了要销毁。
spring容器对底层的标准方法进行再次封装(Spring整合Hibernate),程序里只要简单调用就能实现。
spring 容器内置的逻辑将代码里的简单调用转化为Hibernate能理解的复杂实现。
前面假设的那个运营团队的需要的查询“衣柜”数量的需求,是个常态化的需求,需要固化在后台程序的程序逻辑里。 那写实现这个需求代码的时候,除了要写业务逻辑“根据搜索衣柜的所有条目,计算条目数量“,你还得写”如何去数据库搜索 搜索过衣柜的用户:2003-3-12 衣柜 订单 “这个逻辑。 “2003-3-12 衣柜 订单 ”这个请求会生成一个对象。
这是业务逻辑对底层搜索逻辑的依赖。这叫传统的直接把依赖的实现写在调用方,这个场景就是调用方直接控制对象的创建。
控制反转就是,不再由请求方代码层去实现“2003-3-12 衣柜 订单 “的具体执行逻辑,现在只写业务逻辑“根据搜索衣柜的所有条目,计算条目数量“然后写“我需要搜索衣柜的所有条目 参数是:2003-3-12 衣柜 “给SPring根据这个参数生成一段具体的执行代码,“注入“到调用方,这叫“依赖注入”
AOC是一种通过预编译方式和运行期动态代理实现:在不修改源代码的情况下给程序动态统一添加某种特定功能(例如日志或事务支持)的技术。
spring boot
spring framework在发展的过程中,支持越来越来的外部组件,实现越来越多的功能,导致配置复杂。
配置复杂咋理解呢“比如开车跑长途去旅游,不是你会打火,挂档,踩油门就行,你得检查油够不够,胎压行不行,行李装没装好,目的地天气如何,等等, 任何一项没做好,就可能导致大问题“ ,配置跟生活不一样,配置是强制的,弄不好,程序就搞不定。
怎么解决呢? 还是标准化封装,还以出差为例,你找来一个修理工,一个旅游顾问,把需求抛给它们解决“我要旅游,让车符合要求,旅游三天需要的东西准备一下“。
简单理解 spring boot=spring framework+配置模板封装。 当然实际能实现的更复杂。 我理解spring boot就是在spring framework加了一些中间实现代码块。
spring cloud
“Spring Cloud的子项目,大致可分成两类,一类是对现有成熟框架”Spring Boot化”的封装和抽象,也是数量最多的项目;第二类是开发了一部分分布式系统的基础设施的实现,如Spring Cloud Stream扮演的就是kafka, ActiveMQ这样的角色。
对于我们想快速实践微服务的开发者来说,第一类子项目就已经足够使用,如:
- Spring Cloud Netflix 是对Netflix开发的一套分布式服务框架的封装,包括服务的发现和注册,负载均衡、断路器、REST客户端、请求路由等。
- Spring Cloud Config 将配置信息中央化保存, 配置Spring Cloud Bus可以实现动态修改配置文件
- Spring Cloud Stream 分布式消息队列,是对Kafka, MQ的封装
- Spring Cloud Security 对Spring Security的封装,并能配合Netflix使用
- Spring Cloud Zookeeper 对Zookeeper的封装,使之能配置其它Spring Cloud的子项目使用
- Spring Cloud Eureka 是 Spring Cloud Netflix 微服务套件中的一部分,它基于Netflix Eureka 做了二次封装,主要负责完成微服务架构中的服务治理功能。“spring cloud_百度百科“
- “SpringCloud是基于SpringBoot的,所以两者的jar包都需要导入,需要注意的是SprinbCloud的版本需要和SpringBoot的版本兼容“二、Spring Cloud 极简入门-Spring Cloud简介
spring cloud的就是让你用简单的语言实现其他模块的部署,通信之类的。说白了又是一层“翻译器“。 只是这里的其他模块,已经是作为独立程序,甚至程序集群存在。
通常来说Spring Cloud=Spring Cloud Netflix
springcloud是在netflix的基础上,对其按照springboot 的标准进行重构组装,整合进springboot 体系中的一种生态结构。
Netflix 微服务技术栈的核心组件基本上都是开源的。Pivotal (Spring项目的母公司)把 Netflix 开源的这摊东西封装一下改头换面,再拼凑一些其它东西(配置中心,调用链监控等)就变成了 Spring Cloud。现在大家耳熟能详的 Zuul 网关,Eureka 服务发现注册中心,Hystrix 熔断限流,Archaius 配置等组件,Netflix 在 2012 年左右就都开源出来了。
spring cloud alibaba
spring cloud alibaba属于 Spring Cloud的子项目,我觉得用“衍生项目”形容更合适,
spring cloud alibaba跟Spring Cloud Netflix是一样即成了很多模块的,能方便接入更多软件功能的衍生框架
重点在于“”Spring Boot化”,中间的核心机制还是spring原来的,阿里做的工作是把那些模块springboot化。然后对前端的命令翻译内容根据自己的修改做些匹配。
- 流量控制和服务降级:使用阿里巴巴Sentinel进行流量控制,断路和系统自适应保护;
- 服务注册和发现:实例可以在Alibaba Nacos上注册,客户可以使用Spring管理的bean发现实例,通过Spring Cloud Netflix支持Ribbon客户端负载均衡器;
- 分布式配置:使用阿里巴巴Nacos作为数据存储;
- 事件驱动:构建与Spring Cloud Stream RocketMQ Binder连接的高度可扩展的事件驱动微服务;
你只要能拿到那些组件的源码进行“spoot化”,也能像spring cloud alibab一样,开发个spring cluoud XX体系出来。比如 Spring Cloud for Amazon Web Services, Spring cloud tencent, spring cloud azure等
各大云厂商这么热衷开发自己基于spring cloud的框架,因为框架决定了用户能不能很方便的用云厂商的产品。
为啥Google居然没有基于spring cloud开发框架?
google的技术是公认的强大,我猜想最核心的原因是 kubernetes ,Spring Cloud 和Kubernetes都声称自己是开发和运行微服务的最佳环境.
kubernetes 现在的发展就不用多说了。google确实没理由为了多卖点云服务,非得再搞个spring cloud google,太掉价了。
项目构建工具
侵入式与非侵入式
非侵入式:使用一个新的技术不会或者基本不改变原有代码结构,原有代码不作任何修改即可。侵入式代码结构则要与该技术产生依赖。
侵入式框架:引入了框架,对现有的类的结构有影响,需要实现框架某些接口或者基础某些特定的类。侵入式让用户的代码对框架产生了依赖,不利于代码的复用,当去除框架的时候,程序就无法运行。当然侵入式可以使得用户的代码与框架更好的结合,充分利用框架提供的功能。(代码结构和框架产生耦合)例子:Struts1框架, Struts1代码严重依赖于Struts1 API,属于侵入性框架。
Spring框架,通过配置完成依赖注入就可以使用,当我们想换个框架,只需要修改相应的配置,程序仍然可以运行。(实际上一般Spring所倡导的无侵入性一般来说都是指它的IOC框架,象楼上所说的事务管理,或者诸如AOP等,都是有侵入的,如果设计的好的话,可以把损失降低到更小,但的确不是一点侵入都没有。)Spring学习(1):侵入式与非侵入式,轻量级与重量级
工具类的属于辅助构建,对代码不应该有侵入性
Maven
本来想看看Maven的历史,发现找不到。
maven方式和不用maven的方式部署的时候有个本质的区别:不用maven可以直接将代码包拷贝到tomcat目录下部署时 后缀名可以是 .java 可以是.jar .war。 但Maven 往tomcat部署的时候是已经编译过的文件,后缀.class。
maven像个洗碗机。
Jenkins
Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件项目可以进行持续集成
Dubbo
Dubbo是阿里开源的分布式服务框架
不止阿里的Dubbo、其他各种大厂商也都有自己的分布式服务框架,腾讯的Tars、Google的gRPC、Facebook的Thrift、京东的JSF、美团的OCTO-RPC
为什么有了spring,EJB,这些大厂商还要开发自己的框架?
随着前端并发的增大,实际经过了几个阶段。
第一阶段是单体架构阶段,开发servlet程序,放在容器比如tomcat内部执行。
第二阶段是垂直架构阶段,把程序拿到容器外面,程序在外面与容器通信。 这个时候程序自己占了服务器,处理能力大幅增强,但要解决程序开发复杂度的问题。这个时候程序模块间的通信还在本地,只涉及跟数据库的通信。 spring是这个阶段出现的,主要是为解决开发复杂度的问题。
第三阶段是分布式架构阶段,从程序里拆公共模块出来形成单独程序,且要用分布式的方式支撑。spring cloud出现。
第四阶段是微服务器架构,继续把程序拆散,把程序逻辑层面也拆出来,都采用分布式部署。 容器,K8S时代。
这个对架构演变的表述很粗浅,详细的可以看看分布式架构演进过程_Unknowncheats的博客-CSDN博客_分布式架构的发展历程
spring出现时,初识定位就是解决“开发简单“的问题。JAVA的EJB出来的时候定位是不一样的,是为了解决分布式问题,应该说JAVA还是非常有前瞻性的,只是在很长一段时间内,分布式还不是最主流的需求,只有少数很大的企业才有这个需求。 所以EJB1.0,EJB2.0时代,有spring可选的情况下,对于需要简单开发又不需要分布式的场景下,EJB1.0,EJB2.0不是大多数公司的最好选择。 EJB 3.0虽然往简单开发方向走了,但底子仍然是对分布式的支持。
分布式最核心的是“通信”问题,EJB从开始避不开的一个核心就是远程调用协议RMI,所以非要对比,EJB是要对标spring cloud的,但EJB生不逢时,而且我理解EJB还有另外一个问题限制了自己的发展,在EJB推出的时代,JAVA应该是处于服务器开发语言霸主的地位,RMI的定位是JAVA应用,没考虑跟其他语言开发的程序通信问题。但当分布式需求真正起来的时候,很多用户的程序并不是用JAVA开发的,选择EJB就意味着要从头来过,肯定是直接pass的。
在分布式需求逐渐起来的过程中,出现了一些能解决部分问题的框架,因为分布式本来就是先把需要分布式的部分拆出来做分布式,比如大数据计算框架hadoop,大数据存储框架HDFS。
前面讲过,完整的分布式要解决的核心是通信,但还有其他问题也都是要解决的扩展问题(每个模块都要解决),分布式事务问题(数据库要解决的)安全问题(通信层面要解决的)等。比如Hadoop只是解决了一个模块内的扩展等问题。
一个模块内的控制问题,很核心的是众多节点的协调问题,比如hadoop里面,用ZooKeeper来解决,ZooKeeper也是分布式框架。
所以分布式是分层的需求,对应的是分层解决问题的各种分布式框架。spring framework是解决开发问题的框架,Hadoop是解决大数据模块分布式的框架,dubbo核心是解决分布式服务间通信问题框架。spring cloud是基于解决通信,更侧重于解决“简单构建分布式系统”的框架。
通信协议的选择是个学问:推荐个文章既然有HTTP协议,为什么还要有RPC
协议的本质是对数据包的解读,通信协议的制定是根据对于不同数据包的特点,以及效率等方面来制定的。比如
hadoop客户端与namenode通信通过RPC协议, 但是client 与datanode通信并没有使用RPC, 而是直接使用socket。
spring framework并没有针对模块间跨服务器的通信进行特别的封装,或者说限定。 如果说有,也是针对特定模块 SpringMVC进行过http的封装。
因为协议太底层了,一般的公司没能力也没必要去搞这个。打个比方 协议像砖,普通人盖个房子,甚至开发商开发个小区,都没必要自己建个砖场去研究生产“专用砖”。但当项目足够大,需求足够特殊就有必要,比如建核电站。
spring是开源,面向的是整个市场中小企业的需求,不限制协议,中小企业可以用现成的http协议解决大多数需求。
但对淘宝,项目足够大,电商的高并发和复杂足够对“效率”有更特殊的需求,http就不是第一选择了,用EJB对阿里来说太束手束脚,协议不能自己优化,而且RMI不支持多语言客户端。虽然支持EJB的webservice 比如WebSphere之类的可以支持,但对阿里这种体量,完全没必要受限在语言的框架里去发展自己的实现路线,所以阿里开发了自己的分布式框架Dubbo。
Dubbo(基于rpc)2012年发布,spring cloud (远程调用http)也是2012年在这之后发布。
Dobbo开源了2年,2014年停止维护。根本原因也是阿里不像spring,开源Dobbo的时候,并不指望基于它挣钱,只是扩大一些自己的影响力而已,但本身内部的技术路线一直在更新,相比于只是扩大影响力的收益,而去承担维护它的日渐增长支出显然是没必要的。何况Dobbo在内部的发展本来也不是全部业务线都用。
也正因为这些原因,当内部统一到Dubbo和HSF的Dubbo3.0的时候,主动维护它只是顺便,且阿里云本身也有影响力扩大的足够需求的时候,Dubbo又重启了维护。
而spring cloud的发展,因为http协议在远程调用中的先天效率不足,越来越多大用户更倾向于开发自己的分布式框架,而因为多了Dubbo等分布式框架的选择, 后来成长起来的相对大的用户会有很多不再紧跟spring。何况Dubbo提供的中文文档,对于英语水平平均水平并没有那么高的广大程序员,选择Dubbo更是一个非常重要的理由。
各大云厂商那么热衷于基于spring cloud开发自己的体系,核心也只是让使用spring cloud的用户使用自己的云服务而已。 对于云厂商来说,最好的当然还是用户直接用自己提供的框架。
spring cloud自身的声音相比之前正在越来越小
1.使用Spring Cloud Netflix 的用户正在持续被各大厂商切走
2.随着Doker的发展,随着K8S的横空出世,市场需求正在加速从低级分布式进入高级分布式-微服务架构时代。新用户更倾向直接用微服务。
3.因为组件停止维护,Spring Cloud Netflix 停止维护,自己也要演变为另一个版本的子项目。
Dubbo和HSF
他们核心的区别就是对RPC协议不同的封装,调用效率不同HSF比Dubbo。只是在早期的时候,这种调用效率的差距不足以让Dubbo放弃自己路线去重构。这也能解释为啥Dubbo开源,HSF没开源,在那个以淘宝为主,阿里云起步的阶段,HSF是自己的核心竞争力,自然是不可能开源的。
但这种调用效率的天生差距,必然导致内部对HSF的发展倾斜更多能量。当HSF发展到3.0的时候,内部使用统一了,外部云服务的扩大市场需求声音足够响亮了,于是HSF多做一点,把原来的Dubbo RPC协议额外封装进来,再把自己改个名字成Dubbo3.0,让原来使用Dubbo的用户心理上更容易接受。
EDAS
分布式框架是个通信中心,本来在本地部署肯定就是单独的,现在你各种服务都上云了,自然通信中心也得部署在云上。 EDAS就是个更大的托管框架,像个大货架一样,分成多个模块,核心模块是托管“分布式框架,比如Dubbo,HSF,spring cloud alibab&#34;,还有托管业务逻辑程序的框架(底层可以直接部署各种容器和解释器来支持各种语言程序的部署),再基于“简单构建分布式系统“提供各种解决扩展,安全,微服务治理等框架的部署方案。
EDAS可以支持基于服务器(ECS)和K8S的部署。
要理解基于K8S的微服务架构,从逻辑上完全能替代spring的,但K8s的定位是个“操作系统”,本身就是“框架级的操作系统”,只是目前的发展阶段,基于这个“框架级的操作系统” 要解决的分布式应用各部分的“原生微服务”生态还没那么完善。
所以在实际应用中,K8S更多是作为生态能解决部分的底座存在, 应用足够复杂时,用户有时不得不把spring和K8S结合起来使用。
“springcloud里面的概念k8s里大部分都有可以替换的方案了,比如配置中心,注册中心,客户端调用服务的时候负载均衡等。
痛点:
如果在springcloud的项目中,配置中心,注册中心等都去用k8s的,那实际工作对于我们会有一些问题
开始过程中调试问题,因为用了k8s,服务与服务之间的调用都依赖了k8s,所以如果开发者想自己在本地测试,那么必须自己在本地搭建k8s环境来进行相关的测试。给开发者带来了不方便。
用了k8s后,springcloud里面的网关就没法用了,k8s的ingress跟springcloud里面的网关比功能还是弱,springcloud里面的网关是可以自己写代码实现相关功能的,比如统一鉴权,统一日志,统一加解密等,k8s的ingress只是数据流量的入口,实现不了这些功能。
springcloud alibaba有个组件sentinel,流量控制,熔断降级都很好用,k8s里面没有这个功能,istio虽然有这个功能,但是第一它的这个功能没有目前sentinel好用成熟,第二它的这块代码直接在平台层实现了,对于我们是个黑盒子不可控,所以istio也不敢用。
总的来说,k8s里面微服务相关的功能都不够成熟而且也不易用,开发阶段调试困难,导致我们在配合k8s的时候比较谨慎,那k8s怎么和springcloud配合呢?
————————————————
原文链接:k8s部署springcloud_k8s部署springcloud实际落地操作_weixin_39707851的博客-CSDN博客 |
|


 发表于 2023-4-15 10:07:06
发表于 2023-4-15 10:07:06