设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
数据库
›
MySQL中日志机制
返回列表
发帖
查看:
148
|
回复:
3
MySQL中日志机制
[复制链接]
铁头宏
铁头宏
当前离线
积分
47
5
主题
23
帖子
47
积分
新手上路
新手上路, 积分 47, 距离下一级还需 3 积分
新手上路, 积分 47, 距离下一级还需 3 积分
积分
47
发消息
发表于 2023-3-5 03:32:48
|
显示全部楼层
|
阅读模式
1、
WAL机制
在MySQL中,为了提高数据库的性能,MySQL采用了WAL(Write-Ahead Logging)机制,即客户端在修改数据的过程后,并不会立马对硬盘中的数据进行更新。
这样做的原因在于,如果每次客户端进行数据更改后,立马对磁盘中的数据进行更改的话,那么磁盘的压力是非常大的。
想想看,MySQL改数据之前要先定位数据,那么定位数据的过程可能会是磁盘的随机读,随机读的过程是非常慢的。
数据库在并发的情况下,大量的随机读盘会造成数据库在某一时刻的性能将变得很低很低。所以,MySQL要引入WAL机制来减少这种情况的发生。
WAL机制,主要的操作是先写日志,先在一个日志中记录了MySQL要对硬盘中的存储MySQL数据的数据页中的数据进行什么样的更改,等到Mysql空闲的时候再进行同步操作到硬盘中。
举个例子,就是我们作为开发人员,同一时间不可能处理10个需求,而是需要通过协同工具,处理完一个再到另外一个,这样我们的就不会感到那么累。
当然,在数据库并没有累这一说,WAL机制意义就在于
“削峰”
,这也是我们在处理高并发场景下的一个解决思路。
可能有人会很疑惑,同样是操作磁盘,为什么写日志比直接改数据会更加高效?
答案在于写日志是顺序写,直接改磁盘是随机写。所以同样是写,它们写的速度有着天壤之别。这也是WAL的另外一个好处。
接下来我们就具体介绍一下WAL中涉及到的2个主要的日志redolog、binlog。从而了解修改语句在MySQL的处理过程中的处理方式和一些技巧。
2、
redolog
redo log我们也称为重做日志,我们上面所说到数据库先写日志再写磁盘的这个特点中的“日志”,说的就是redolog。
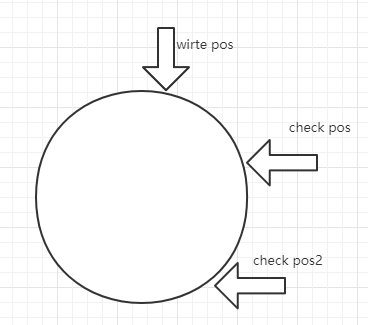
redo log写日志是循环写的,它有2个对象,writepos 和 checkpos。
writepos 和 checkpos
数据每次写入redo log,writepos就会往前移动,当writepos到达checkpos的时候,checkpos就会往后移动。
在这个移动的过程中(
比如图中pos 到 pos2的距离,图中所表达的意思是check pos移动到check pos2的距离,不是说redo log有多个checkpos
)所涉及的对MySQL硬盘数据页的更改全部实施到响应的页中,这样writepos才有新的空间继续写。
这个时候的数据库的表现就是处理突然变低,如果你发现你的数据库运行在某一时刻突然性能变低了,可以考虑一下是否是这种情况。
redo log的大小由2个参数控制:
innodb_log_files_in_group #redolog文件的个数
innodb_log_file_size #每个redolog文件的大小
redolog总大小=innodb_log_files_in_group*innodb_log_file_size一般我们设置innodb_log_files_in_group的个数为4个,每个的大小为1个G。
在MySQL中,除了redo log还有一个也很重要的日志——bin log,它与redo log相互配合,一块来保证数据的一致性
3、
binlog
binlog也成为二进制日志,它记录了Mysql中数据的更改,它一共有3种格式,分别为:
statement #binlog中记录SQL日志。
rows #rows格式记录每一个行的每一个字段的具体改动
mixed #默认记录sql, 由MySQL判断,可能会造成数据不一致的情况便会使用rows格式进行记录。在性能上statement>mixed>rows, 在数据一致性上rows>mixed>statement,很显然数据的一致性是数据库中的重中之重,所以大家很愿意牺牲一点性能来换取数据的可靠性。
到这里我们已经对bin log,redo log有了一个鸡蛋的了解,接下来我们再来看看,在MySQL中redo log和bin log是如何相互配合一起工作的。
4、
数据是如何保证不会丢失的
MySQL中不管是redo log还是bin log,语句从执行到写到磁盘的过程中,都是先要写到cache(redolog称之为buffer)中然后再写到磁盘,换言之就是先写内存再写磁盘。
而写到磁盘也分2种状态,1是数据在硬盘的paga cache中,这个过程称之为
write
,2是数据真正持久化到磁盘这个过程称之为
fsync
。
数据写cache很快,写到硬盘的page cahe也快,真正慢且消耗IO的地方再持久化的过程,也就是fsync。
内存空间划分上,redolog buffer是所有事务共用的,binlog cache是每个线程分配一个。可以通过
binlog_cache_size
来控制它的大小,如果事务的binlog日志大小超出了binlog_cache_size的定义的大小,多出来的部分会存到硬盘中。
事务执行的过程中,更改(update、delete、insert)语句只要执行就会生成redolog buffer。
事务在执行的过程中,只有事务commit了binlog_cache中的数据才会被写到硬盘上,这是为了保证事务的完整性。
硬盘空间划分上,redolog只有一个且所有事务共用,binlog也是一个且所有事务共用。
(注意:这里的一个是指一个对象,实现上mysql可能会分成多个文件去存储)
我们先通过2张图来了解2个日志的从写内存到写硬盘的过程。
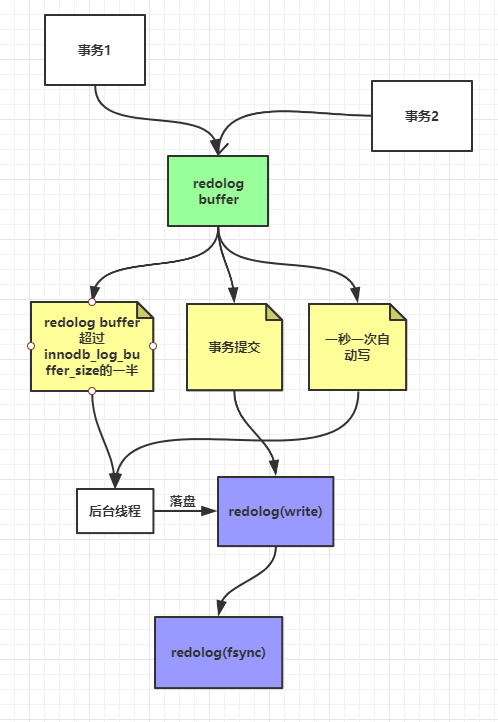
redolog写入过程:
redolog写入过程
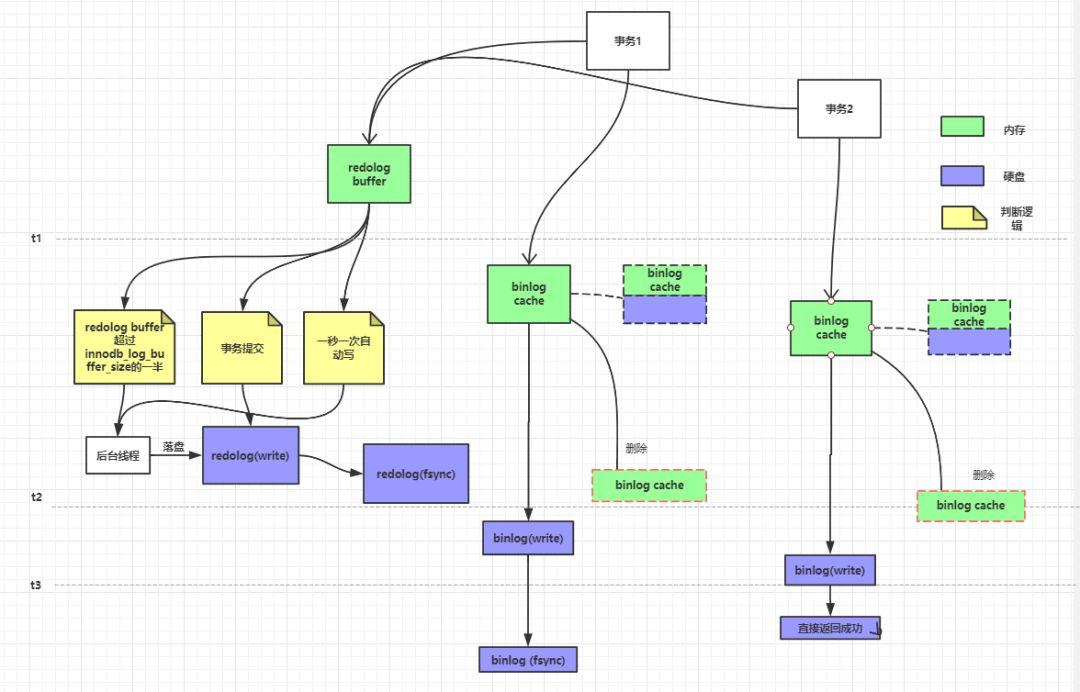
事务任何改变数据的操作都会被记录到redolog buffer中,不管事务有没有提交都会写redolog,然后redolog buffer中的数据会写到硬盘,也就是追加写到硬盘的redo log文件。
这里有3种情况redolog buffer会写到硬盘:
redolog buffer是否超过
innodb_log_buffer_size
(redolog buffer的总大小)的一半。
事务是否提交
一秒一次自动写
数据从内存写到硬盘的过程中是否能到write或fsync由参数
innodb_flush_log_at_trx_commit
控制,它有三种可能取值:
0 :表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 。
1 :表示每次事务提交时都将 redo log 直接持久化到磁盘。
2 :表示每次事务提交时都只是把 redo log 写到 page cache。
一般这个参数设置为1
这里有个特点就是由于事务提交就会写硬盘,那么写硬盘的时候有可能会使还未提交的事务也可能会被写进去redolog文件中去。
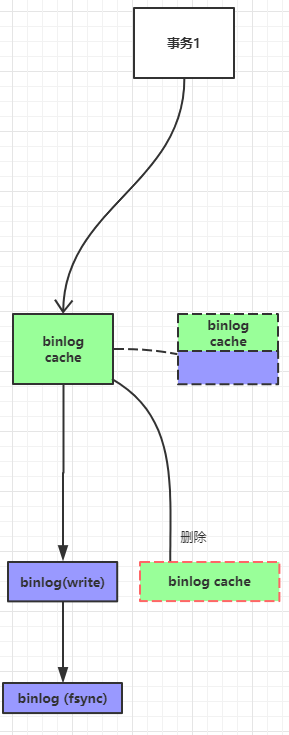
下面是binlog 写入过程:
事务执行,产生binlog cache,直到事务提交,binlog cache中的日志数据会全部写进硬盘binlog中,这个时候数据处于硬盘的page cache中。
是否fsync由参数
sync_binlog
控制,它的值也有3中可能的状态:
0:表示每次提交事务都只 write,不 fsync。
1:表示每次提交事务都会执行 fsync。
N:表示每次提交事务都 write,但累积 N 个事务后才 fsync。
sync_binlog
这个参数一般设置为1,与上面
innodb_flush_log_at_trx_commit
设置为1一起被DBA称为"双1模式"
在了解了它们的落盘过程后我们在来看看它们在事务提交后是如何配合来保护数据不会丢失的。
在事务提交后MySQL是先写redolog,再写binlog。
这个过程再细分后的步骤为,先写redolog这个时候redolog先处于一个prepare状态,然后mysql写binlog,最后再让redlog处于commit状态。这个事务就算真正写到磁盘上了。
为什么需要这样做?原因是2个日志需要保持一致,并且奔溃恢复的逻辑也需要这一过程。如MySQL异常重启后,怎么样判断事务有没有生效?
MySQL的处理方式是如果redo log处于prepare状态,bin log处于commit状态,且2个日志中的数据完整,这个情况下的事务是有效的,否则事务就会被回滚。
这个过程称之为
两阶段提交。
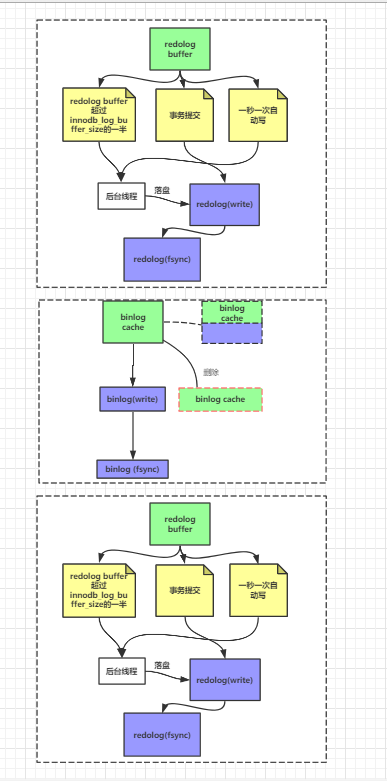
用上面redolog和binlog的写入过程组合起来的话就如下图所示:
第一次redo log提交,数据处于prepare状态,然后提交bin log,最后redolog再发送commit表示,则代表整个事务被持久化到硬盘。
由图可知,一次数据写入的过程可能会有3次fsync,对应3三次IO操作。
这样看来,一次事务可能会照成3次fsync,你可能会觉得这样弄得话MySQL的性能不就会很烂?实际上,MySQL做了优化,用了组提交机制来减少IO的消耗。
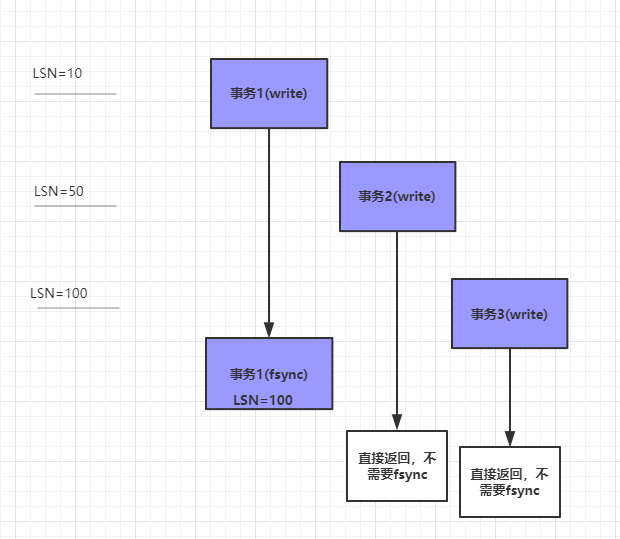
MySQL的具体做法是:每个事务在写入log都会有一个日志逻辑序列号(log sequence number)称之为LSN。
数据在fsync的过程中,LSN会随着其他事务的提交而增长,日志fsync完成的时候会提交最新的LSN。
其他LSN为小于最新提交的LSN的事务就就不需要fsync了,直接返fsync成功,原因就是已经被较前fsync的事务提交了。
举个例子:事务1的LSN为10,它处于write阶段准备调用fsync,在fsync的过程中事务2事务3也提交了等待去fsync,导致事务1携带的LSN增长为了100,那么他fsync的时候顺便会把事务2事务3的数据fsync。这个过程如下图所示:
这里MySQL充分利用了IO的等待时间来减少了IO的消耗。
并且,mysql还做了优化,让binlog的fsync在redolog的fsync之后,这样redo log和binlog fsync都有一定的时间让LSN增长,所以都能使用组提交的优化。
如果你想人为控制这个过程可以使用
binlog_group_commit_sync_delay
与
binlog_group_commit_sync_no_delay_count
参数来控制
最后我们再将上面步骤串联起来,从而整理成了下图的流程:
5、
总结
到这里,redolog与binlog的介绍就结束了,读完这篇文章,相信你应该知道。
什么是redolog
什么是binlog
redolog和binlog是怎么高效配合的。
如果有什么不解之处,或者错误的地方,欢迎评论
回复
使用道具
举报
繁华落尽平淡是真
繁华落尽平淡是真
当前离线
积分
47
7
主题
24
帖子
47
积分
新手上路
新手上路, 积分 47, 距离下一级还需 3 积分
新手上路, 积分 47, 距离下一级还需 3 积分
积分
47
发消息
发表于 2023-3-5 03:33:30
|
显示全部楼层
请问prepare状态时的redolog有没有写入磁盘
回复
使用道具
举报
詹密都是死了妈
詹密都是死了妈
当前离线
积分
37
5
主题
16
帖子
37
积分
新手上路
新手上路, 积分 37, 距离下一级还需 13 积分
新手上路, 积分 37, 距离下一级还需 13 积分
积分
37
发消息
发表于 2025-7-13 03:04:40
|
显示全部楼层
佩服佩服!
回复
使用道具
举报
南方刺
南方刺
当前离线
积分
27
2
主题
13
帖子
27
积分
新手上路
新手上路, 积分 27, 距离下一级还需 23 积分
新手上路, 积分 27, 距离下一级还需 23 积分
积分
27
发消息
发表于 2025-8-25 08:52:24
|
显示全部楼层
顶
回复
使用道具
举报
广西百色李祥贵
广西百色李祥贵
当前离线
积分
37
5
主题
19
帖子
37
积分
新手上路
新手上路, 积分 37, 距离下一级还需 13 积分
新手上路, 积分 37, 距离下一级还需 13 积分
积分
37
发消息
发表于 2025-12-15 23:42:27
|
显示全部楼层
报告!别开枪,我就是路过来看看的。。。
回复
使用道具
举报
用户生子
用户生子
当前离线
积分
22
2
主题
11
帖子
22
积分
新手上路
新手上路, 积分 22, 距离下一级还需 28 积分
新手上路, 积分 22, 距离下一级还需 28 积分
积分
22
发消息
发表于 2025-12-22 04:34:26
|
显示全部楼层
前排支持下了哦~
回复
使用道具
举报
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
快速回复
返回顶部
返回列表


 发表于 2023-3-5 03:32:48
发表于 2023-3-5 03:32:48