|
|
原来我也只知道C++中有左值和右值,通过今天的学习才知道,C++中不光有左值和右值。
C++中有5种值类别,lvalue, rvalue, glvalue, xvalue, prvalue
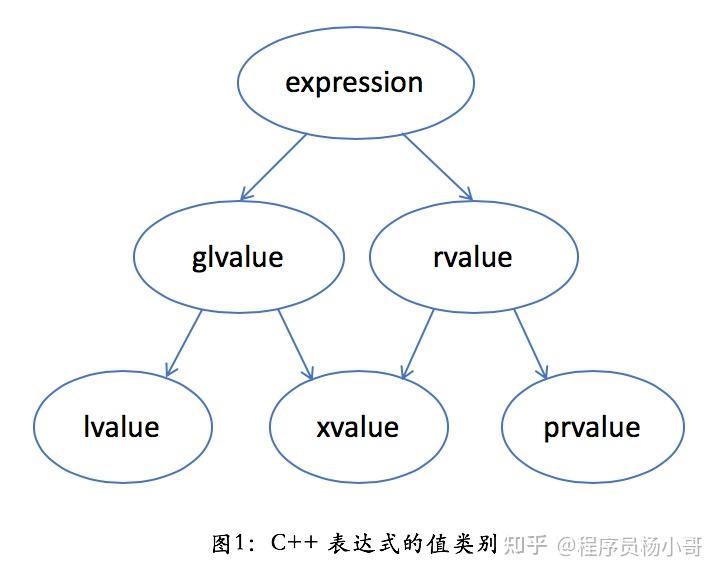
- lvalue: 左值
- rvalue: 右值
- glvalue: generalized lvalue, 广义左值
- xvalue: expiring lvalue, 将亡值
- prvalue: prue rvalue, 纯右值
看到这些不要害怕,我们一点点来。
首先我们看下最熟悉的lvalue.
lvalue
左值是有标识符,可以取地址的表达式。 比如说:
- 变量,函数名,类的数据成员名
这些都是变量名嘛
- 返回左值引用的表达式,如 ++x, x = 1, cout << &#34; &#34;
- 字符串字面值,如&#34;hello world&#34;
值得注意的是,&, reference 其实是左值引用,我们在调用函数时,传递的参数是左值,编译器就会匹配函数参数是左值的那一个函数。
一个常量只能绑定到常左值引用,比如:
const int a = 1;
// int& b = a; // 编译不过
const int& c = a;
prvalue
纯右值,是没有标识符,不可取地址的表达式,一般称之为临时对象
- 非引用类型的表达式,如x++, x+1, make_shared(42)
- 除字符串字面值之外的字面值,如 42, true
在C++11之前,右值可以绑定到常左值引用的参数,但是不可以绑定到非 常左值引用。 如:
// int& a = 1; // 编译不过
const int& a = 1;
在C++11,引入了右值引用,&&。这时我们就可以右值绑定到常右值引用,或者是非常右值引用了。
int&& a = 1;
const int&& b = 1;
引入一种额外的引用类型当然增加了语言的复杂性,但也带来了很多优化的可能性。由于 C++ 有重载,我们就可以根据不同的引用类型,来选择不同的重载函数,来完成不同的行为。
void f(int& a) {
cout << &#34;int&&#34; << endl;
}
void f(int&& a) {
cout << &#34;int&&&#34; << endl;
}
int main(int argc, char const* argv[])
{
int a = 1;
f(a); // a 是一个左值,变量名
f(1); // 数字1是一个右值
return 0;
}
输出:
int&
int&&
那f内的a是左值还是右值呢? 都是左值,因为他们都是一个变量名。类型右值引用的变量是一个左值
xvalue
将亡值,也是一个右值
标准库里有一个move函数,std::move,它的作用是把一个左值引用强制转换成一个右值引用,并不改变其内容。
我们可以把move的返回值看成一个有名字的右值,为了跟无名的纯右值相区别,C++就把这种表达式叫做xvalue,xvalue也是不能取地址的。
<hr/>插播一个生命周期
一个变量的生命周期在超出作用域时结束。如果一个变量代表一个对象,当然这个对象的生命周期也在那时结束。
那临时对象(prvalue)呢?
C++ 的规则是:一个临时对象会在包含这个临时对象的完整表达式估值完成后、按生成顺序的逆序被销毁,除非有生命周期延长发生。
我们先看一个没有生命周期延长的基本情况:
class shape {
public:
virtual ~shape() {}
};
class circle : public shape {
public:
circle() { cout << &#34;circle()&#34; << endl; }
~circle() { cout << &#34;~circle()&#34; << endl; }
};
class triangle : public shape {
public:
triangle() { cout << &#34;triangle()&#34; << endl; }
~triangle() { cout << &#34;~triangle()&#34; << endl; }
};
class result {
public:
result() { cout << &#34;result()&#34; << endl; }
~result() { cout << &#34;~result()&#34; << endl; }
};
result
process_shape(const shape& shape1,
const shape& shape2)
{
return result();
}
process_shape(circle(), triangle());
输出:
triangle()
circle()
result()
~result()
~circle()
~triangle()
运行之后你可以看到,result 临时对象最后生成,最先被析构。
下面,我们用右值引用接收一下返回值,result&& r = process_shape(circle(), triangle());
triangle()
circle()
result()
~circle()
~triangle()
~result()
你会发现,result的生成还在原来的位置,但是析构被延迟到了最后。
我们在上一步的基础上在加上move, result&& r = move(process_shape(circle(), triangle()));
triangle()
circle()
result()
~result()
~circle()
~triangle()
输出又变回了原来的样子。
需要注意的是: 右值引用的声明周期延长只对 prvalue 有效,而对 xvalue无效。 如果由于某种原因,prvalue 在绑定到引用以前已经变成了 xvalue,那生命期就不会延长。不注意这点的话,代码就可能会产生隐秘的 bug。
<hr/>移动
C++出现移动的意义是什么?
class A {
B b_;
C c_;
};
对于这样的代码,从实际内存布局的角度,很多语言如 Java 和 Python 会在 A 对象里放 B 和 C 的指针(虽然这些语言里本身没有指针的概念)。 而 C++ 则会直接把 B 和 C 对象放在 A 的内存空间里。这种行为既是优点也是缺点。说它是优点,是因为它保证了内存访问的局域性,而局域性在现代处理器架构上是绝对具有性能优势的。说它是缺点,是因为复制对象的开销大大增加:在 Java 类语言里复制的是指针,在 C++ 里是完整的对象。这就是为什么 C++ 需要移动语义这一优化,而 Java 类语言里则根本不需要这个概念。
如何实现移动??
通常需要下面几步:
- 类应该有拷贝构造和移动构造(除非你只打算支持移动,不支持拷贝————如 unique_ptr)
可以参考我的文章 《C++手把手带你实现一个智能指针》
- 应该有 swap 成员函数,支持和另外一个对象快速交换成员
- 在你的对象的命名空间下,应当有一个全局的 swap 函数,调用成员函数 swap 来实现交换。
支持这种用法会方便别人(包括你自己在将来)在其他对象里包含你的对象,并快速实现它们的 swap 函数。
- 实现通用的 operator=
- 上面各个函数如果不抛异常的话,应当标为 noexcept。
我写了一个例子,可以参考一下,如果有问题还请指出来,我也是在学习过程中。
class A
{
public:
A(int a = 1) : m_a(a) {}
~A() {}
private:
int m_a;
};
class B
{
public:
B() {}
B(A a) : m_a(a) {}
~B() {}
void swap(B& rhs) noexcept {
using std::swap;
swap(m_a, rhs.m_a);
}
B(const B& b) noexcept {
m_a = b.m_a;
}
B(B&& rhs) noexcept {
swap(rhs);
}
B& operator=(const B& rhs) noexcept {
m_a = rhs.m_a;
return *this;
}
B& operator=(B&& rhs) noexcept {
swap(rhs);
return *this;
}
private:
A m_a;
};
void swap(B& a, B& b) {
a.swap(b);
}
int main()
{
B b(100);
B b1 = b, b2;
b2 = b;
B b3(move(b));
B b4;
b4 = move(b2);
B b5(200), b6(1000);
swap(b5, b6);
}
不要返回临时变量的引用
刚学C++的时候,我就出现过把函数内的局部变量返回的情况,函数的返回值是一个引用。
比如说:
class A
{
};
A& f() { // 编译不过
return A();
}
因为 f() 函数内返回的A(),这个临时变量在f() 调用结束后就被销毁了,返回一个指向本地对象的引用属于未定义行为。
所以正确的写法应该是把& 去掉,A& f()改为A f(), C++11之前,编译器会自动把这个临时对象拷贝一份作为函数的返回值传递回来。
除非编译器发现可以做返回值优化(named return value optimization,或 NRVO),能把对象直接构造到调用者的栈上。
从 C++11 开始,返回值优化仍可以发生,但在没有返回值优化的情况下,编译器将试图把本地对象移动出去,而不是拷贝出去。
返回值优化不需要我们去改move, 写了move反而弄巧成拙,会取消返回值优化。
class A
{
public:
A() { cout << &#34;A&#34; << endl; }
A(const A& a) { cout << &#34;A&&#34; << endl; }
A(A&& a) { cout << &#34;A&&&#34; << endl; }
};
A f() {
return A();
}
A f2() {
return move(A());
}
int main()
{
f();
cout << &#34;---------------&#34; << endl;
f2();
return 0;
}
输出:
A
---------------
A
A&&
f(),编译器对返回值进行了优化,对象直接被构造到调用者的栈上(没有被拷贝和搬移),
f2(),move 破坏了返回值优化,相对于f(),对象还被多搬移了一次,这个搬移属实没必要。
完美转发
void f2(int& a) {
cout << &#34;f2 int&&#34; << endl;
}
void f2(int&& a) {
cout << &#34;f2 int&&&#34; << endl;
}
void f(int& a) {
cout << &#34;int&&#34; << endl;
}
void f(int&& a) {
cout << &#34;int&&&#34; << endl;
f2(a);
}
int main()
{
int a = 1;
f(move(a));
return 0;
}
输出:
int&&
f2 int&
我们之前有说到,void f(int&& a),a在f的函数体内又变成了左值,因为它是一个变量,那么我们怎么才能保证a原来是右值,进入函数体以后还是一个右值呢?
这就用到了完美转发,std::forward(), 我们把上述代码的
void f(int&& a) {
cout << &#34;int&&&#34; << endl;
f2(a);
}
改成
void f(int&& a) {
cout << &#34;int&&&#34; << endl;
f2(forward<int>(a));
}
输出:
int&&
f2 int&&
完美转发,forward是一个函数模板,我们则需要把类型传递进去,这个例子传递的是一个int类型。
好了,值分类和搬移先说到这里了,如果文章有错误的地方还请给我指出来,大家一起进步嘛。
如果觉得对你有帮助的话请@程序员杨小哥 点个赞,谢谢! |
|


 发表于 2023-2-14 19:17:59
发表于 2023-2-14 19:17:59