|
|
大家好,我是 @明人只说暗话。
本文为大家介绍MySQL数据库中各个开窗函数的用法。
创作不易,禁止白嫖哦!
点赞、评论、关注,选一个呗! 准备
建表脚本
CREATE TABLE `test`.`staffs` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`staff_id` INT(11) NULL,
`first_name` VARCHAR(32) NULL,
`last_name` VARCHAR(32) NULL,
`email` VARCHAR(32) NULL,
`phone_number` VARCHAR(11) NULL,
`hire_date` DATE NULL,
`employment_id` VARCHAR(32) NULL,
`salary` NUMERIC(8,2) UNSIGNED NULL,
`commission_pct` NUMERIC(2,2) UNSIGNED NULL,
`manage_id` NUMERIC(6) UNSIGNED NULL,
`section_id` NUMERIC(6) UNSIGNED NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_general_ci;测试数据
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(198,'Donald','OConnel','1@163.com','13611223344','19900101','SH_CLERK',2200.00,NULL,124,50);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(198,'Donald','OConnel','1@163.com','13611223344','19900101','SH_CLERK',2400.00,NULL,124,50);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(198,'Donald','OConnel','1@163.com','13611223344','19900101','SH_CLERK',2600.00,NULL,124,50);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(199,'Douglas','Grant','2@163.com','13611223344','19910102','SH_CLERK',4000.00,NULL,124,50);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(199,'Douglas','Grant','2@163.com','13611223344','19910102','SH_CLERK',4200.00,NULL,124,50);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(200,'Jennie','Grant','3@163.com','15611223344','19950202','HZ_CLERK',5000.00,NULL,124,51);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(200,'Jennie','Grant','3@163.com','15611223344','19950202','HZ_CLERK',5000.00,NULL,124,51);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(200,'Jennie','Grant','3@163.com','15611223344','19950202','HZ_CLERK',5100.00,NULL,124,51);
INSERT INTO staffs(staff_id,first_name ,last_name ,email, phone_number,hire_date ,
employment_id ,salary ,commission_pct ,manage_id ,section_id )
values(200,'Jennie','Grant','3@163.com','15611223344','19950202','HZ_CLERK',5200.00,NULL,124,51);CUME_DIST()
语法
CUME_DIST() OVER (
PARTITION BY expr, ...
ORDER BY expr [ASC | DESC], ...
) PARTITION BY子句将FROM子句返回的结果集划分为CUME_DIST()函数适用的分区。
ORDER BY子句指定每个分区中行的逻辑顺序,或者在PARTITION BY省略的情况下指定整个结果集。
CUME_DIST()函数根据分区中的顺序计算每行的累积分布值。
作用
返回一组值中值的累积分布。
它表示值小于或等于行的值除以总行数的行数。
CUME_DIST()函数的返回值大于零且小于或等于1(0 < CUME_DIST() <= 1)。
重复的列值接收相同的CUME_DIST()值。
SQL示例
SELECT id,staff_id,salary,CUME_DIST() over(partition by staff_id order by salary )
as rank_staff FROM staffs ;
结果
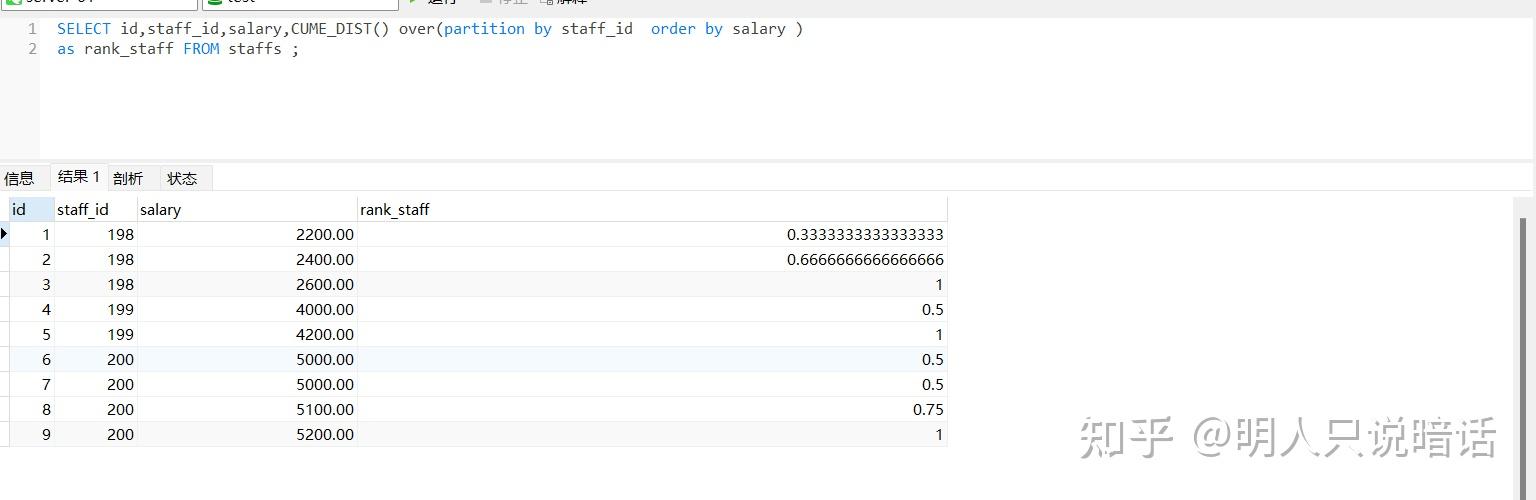
分析
如上所示。
数据记录总数是9。
在staff_id = 198的这一组数据中,共有3条数据,其中:
对于id = 1这条记录来说,salary 小于等于 2200.00的记录有1条(id = 1),因此,其CUME_DIST值= 1 / 3 = 0.333333333333;
对于id = 2这条记录来说,salary 小于等于 2400.00的记录有2条(id = 1 和 2),因此,其CUME_DIST值= 2 / 3 = 0.66666666666;
对于id = 3这条记录来说,salary 小于等于 2600.00的记录有3条(id = 1 、 2 、 3),因此,其CUME_DIST值= 3 / 3 = 1。
在staff_id = 199的这一组数据中,共有2条数据,其中:
对于id = 4这条记录来说,salary 小于等于 4000.00的记录有1条(id = 4),因此,其CUME_DIST值= 1 / 2 = 0.5;
对于id = 5这条记录来说,salary 小于等于 4200.00的记录有2条(id = 4 、 5),因此,其CUME_DIST值= 2 / 2 = 1。
在staff_id = 200的这一组数据中,共有4条数据,其中:
对于id = 6这条记录来说,salary 小于等于 5000.00的记录有2条(id = 6和7),因此,这两条记录的CUME_DIST值 = 2 / 4 = 0.5;
对于id = 7这条记录来说,salary 小于等于 5000.00的记录有2条(id = 6和7),因此,这两条记录的CUME_DIST值 = 2 / 4 = 0.5;
对于id = 8这条记录来说,salary 小于等于 5100.00的记录有3条(id = 6、7、8),因此,其CUME_DIST值= 3 / 4 = 0.75;
对于id = 9这条记录来说,salary 小于等于 5200.00的记录有4条(id = 6、7、8、9),因此,其CUME_DIST值= 4 / 4 = 1。
DENSE_RANK()
语法
DENSE_RANK() OVER (
PARTITION BY <expression>[{,<expression>...}]
ORDER BY <expression> [ASC|DESC], [{,<expression>...}]
) PARTITION BY子句将FROM子句生成的结果集划分为分区,DENSE_RANK()函数应用于每个分区。
ORDER BY 子句指定DENSE_RANK()函数操作的每个分区中的行顺序。
作用
为分区或结果集中的每一行分配排名,而排名值没有间隙,即相同的值具有相同的序号。
每组的序号都从1开始递增。
SQL示例
SELECT id,staff_id,salary,DENSE_RANK() over(partition by staff_id order by salary )
as rank_staff FROM staffs ;
结果
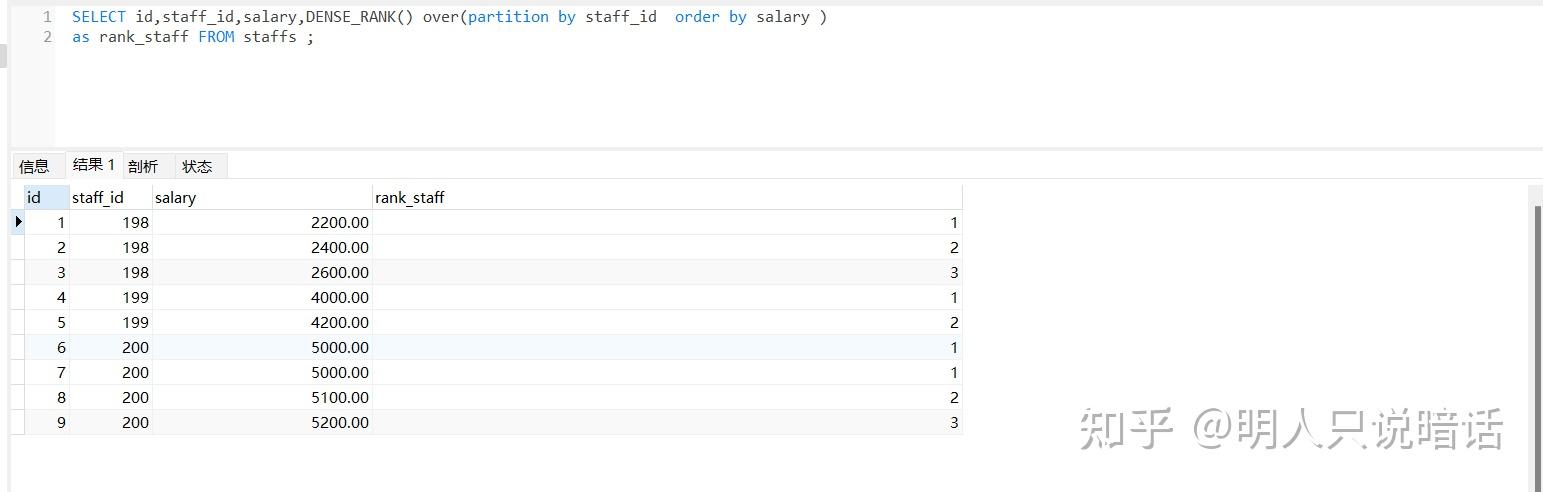
分析
如上图所示。
数据记录总数是9。
在staff_id = 198的这一组数据中,共有3条数据,这3条数据的序号分别从1开始递增,由于没有salary相同的记录,因此各个序号都不相同。
在staff_id = 199的这一组数据中,共有2条数据,这2条数据的序号分别从1开始递增,由于没有salary相同的记录,因此各个序号都不相同。
在staff_id = 200的这一组数据中,共有4条数据,其中id = 6和7的记录的salary相同,因此这两条记录的序号也相同,都是1。
而id = 8和9的记录的salary和其他记录都不相同,序号本应该从3开始递增的,但是由于上面已经出现了2个1,因此要从3开始。
现实中的场景:
考试排名时,如果有两个人并列第一名(都是100分),那么在光荣榜上,分数是99的同学(不管是有一个还是多个)的名次则是第三名。 PERCENT_RANK()
语法
PERCENT_RANK()
OVER (
PARTITION BY expr,...
ORDER BY expr [ASC|DESC],...
) 作用
PERCENT_RANK是秩分析函数。
行 R 的百分比秩是指将在OVER子句中指定的组中的某个行的秩减去一,再除以在OVER子句中指定的组中的总行数减去一得出的值。
计算方法为 (RANK - 1) / (N- 1),其中,RANK是记录行在组中的位置(从1开始),N是每组的记录数。
PERCENT_RANK()函数返回一个从0到1的数字。
PERCENT_RANK()对于分区或结果集中的第一行,函数始终返回零。
重复的列值将接收相同的PERCENT_RANK()值。
SQL示例
SELECT id,staff_id,salary,PERCENT_RANK() over(partition by staff_id order by salary )
as rank_staff FROM staffs ;
结果
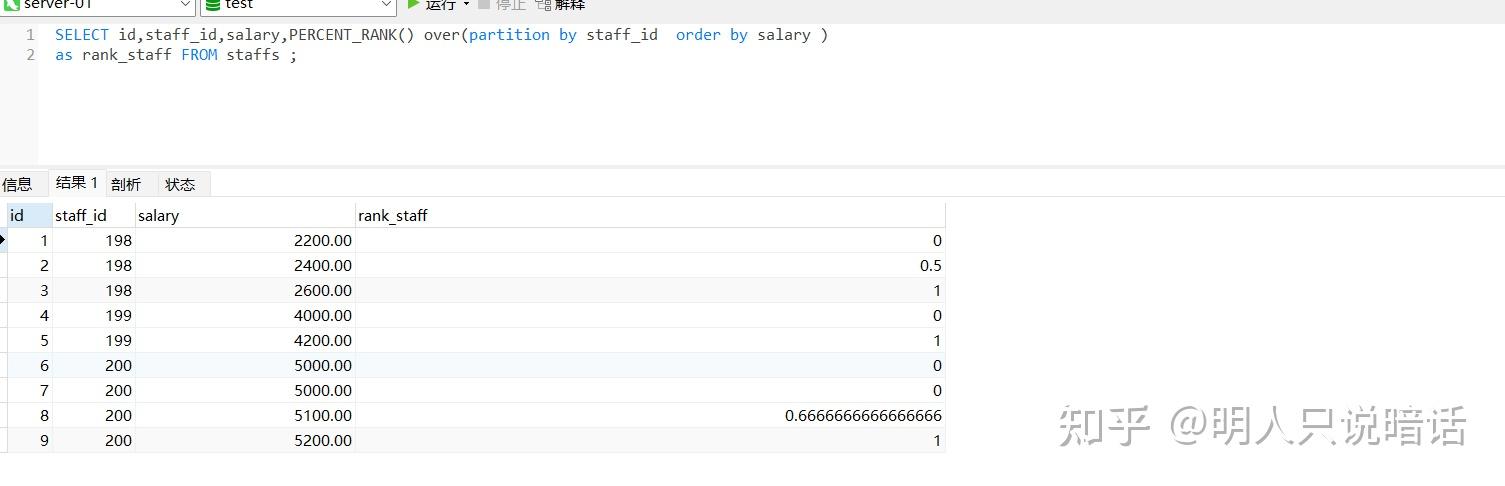
分析
如上图所示。
数据记录总数是9。
在staff_id = 198的这一组数据中,共有3条数据,其中:
根据计算公式 (RANK - 1) / (N- 1),id = 1的数据的PERCENT_RANK = (1-1) / (3-1) = 0。
根据计算公式 (RANK - 1) / (N- 1),id = 2的数据的PERCENT_RANK = (2-1) / (3-1) = 0.5。
根据计算公式 (RANK - 1) / (N- 1),id = 3的数据的PERCENT_RANK = (3-1) / (3-1) = 1。
在staff_id = 199的这一组数据中,共有2条数据,其中:
根据计算公式 (RANK - 1) / (N- 1),id = 4的数据的PERCENT_RANK = (1-1) / (2-1) = 0。
根据计算公式 (RANK - 1) / (N- 1),id = 5的数据的PERCENT_RANK = (2-1) / (2-1) = 1。
在staff_id = 200的这一组数据中,共有4条数据,其中:
根据计算公式 (RANK - 1) / (N- 1),id = 6和7的数据的salary值相同,因此两者的PERCENT_RANK也相同,即 PERCENT_RANK= (1-1) / (4-1) = 0。
根据计算公式 (RANK - 1) / (N- 1),id = 8的数据的PERCENT_RANK = (3-1) / (4-1) = 0.6666666666。
根据计算公式 (RANK - 1) / (N- 1),id = 9的数据的PERCENT_RANK = (4-1) / (4-1) = 1。
RANK()
语法
rank() over(partition by xxx order by yyy)
作用
为各组内的值生成跳跃的排序序号,其中相同的值有相同的序号。
如上语法所示,是以partition by 后的字段分组的。
SQL示例
SELECT staff_id,salary,rank() over(partition by staff_id order by salary )
as rank_staff FROM staffs ;
结果
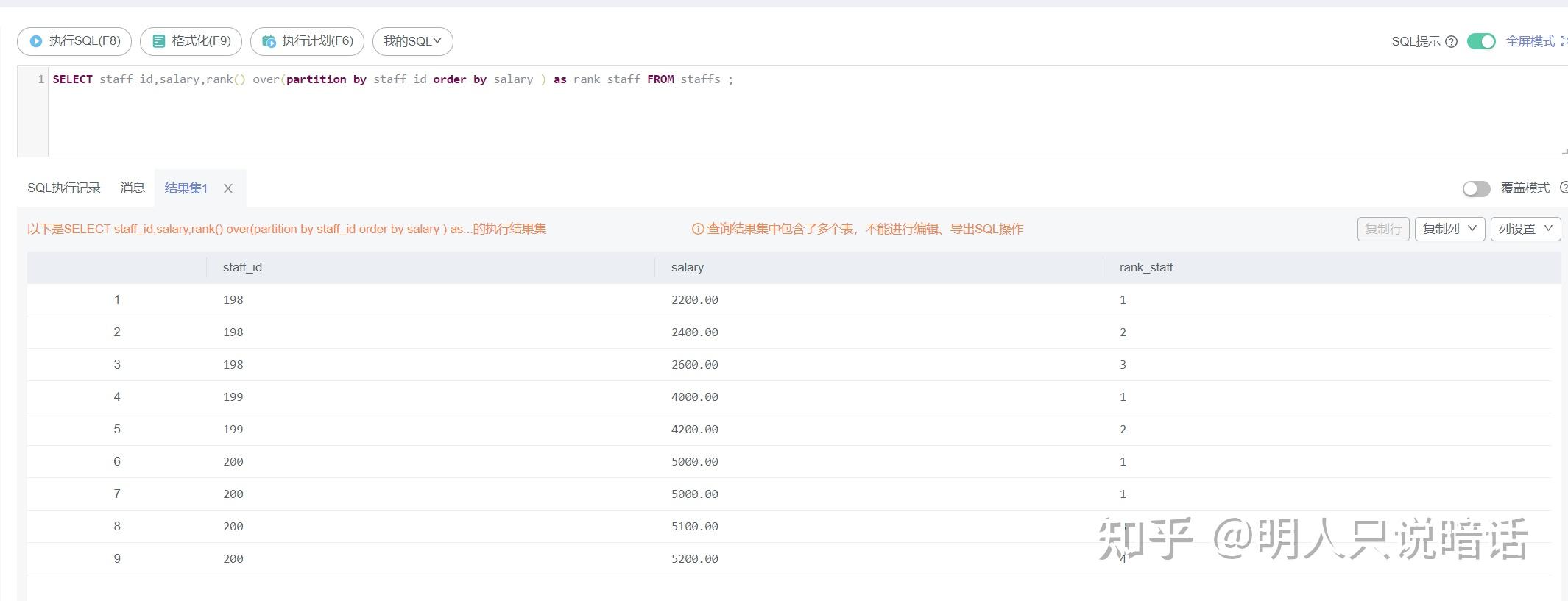
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条是一组,在本组内由于salary 值各不相同,因此生成的序号是从1递增的。
staff_id 为199的数据有2条,这2条是一组,在本组内由于salary 值各不相同,因此生成的序号是从1递增的。
staff_id 为200的数据有4条,这4条是一组,在本组内,由于salary 为5000的数据有2条,因此这2条记录的序号是相同的,都是1。
另外两条数据的salary 值和其他记录都不相同,因此序号递增,由于前面两条记录的序号都是1,因此序号从3开始递增。
ROW_NUMBER()
语法
ROW_NUMBER() OVER (<partition_definition> <order_definition>) 作用
为各组内的值生成跳跃的排序序号,其中相同的值的序号不同。
SQL示例
SELECT id,staff_id,salary,row_number() over(partition by staff_id order by salary )
as rank_staff FROM staffs ;
结果
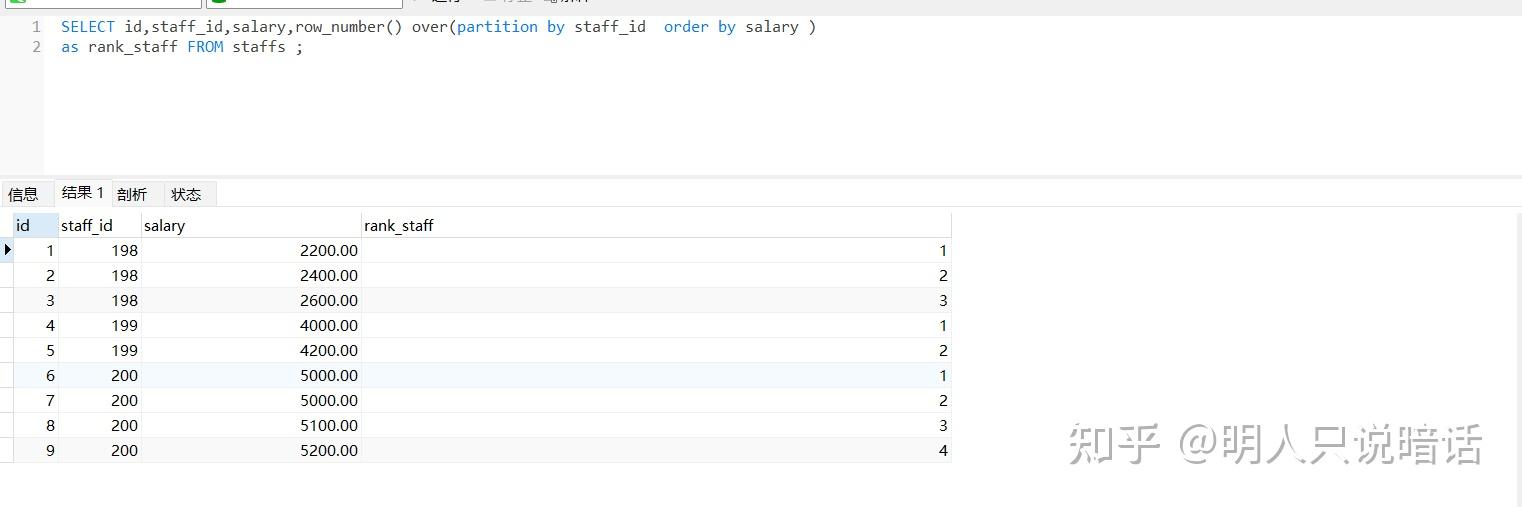
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条是一组,在本组内序号递增,即使salary 值相同序号也不相同,分别是1、2、3。
同理,staff_id 为199的数据有2条,这2条是一组,在本组内序号递增,即使salary 值相同序号也不相同,分别是1、2。
staff_id 为200的数据有4条,这4条是一组,在本组内序号递增,即使salary 值相同序号也不相同,分别是1、2、3和4。
FIRST_VALUE()
语法
FIRST_VALUE(expression) OVER (
[partition_clause]
[order_clause]
[frame_clause]
) FIRST_VALUE()函数返回expression窗口框架第一行的值。
OVER条款由三个可选表达式:partition_clause,order_clause,和frame_clause。
partition_clause子句将结果集的行划分为函数独立应用的分区;
order_clause子句指定FIRST_VALUE()函数操作的每个分区中行的逻辑顺序。
frame_clause定义当前分区的子集(或帧)。
作用
取各组内第一条数据作为返回值。
SQL示例
SELECT id,staff_id,salary,first_value(salary) over(partition by staff_id order by salary )
as rank_staff FROM staffs ;
结果
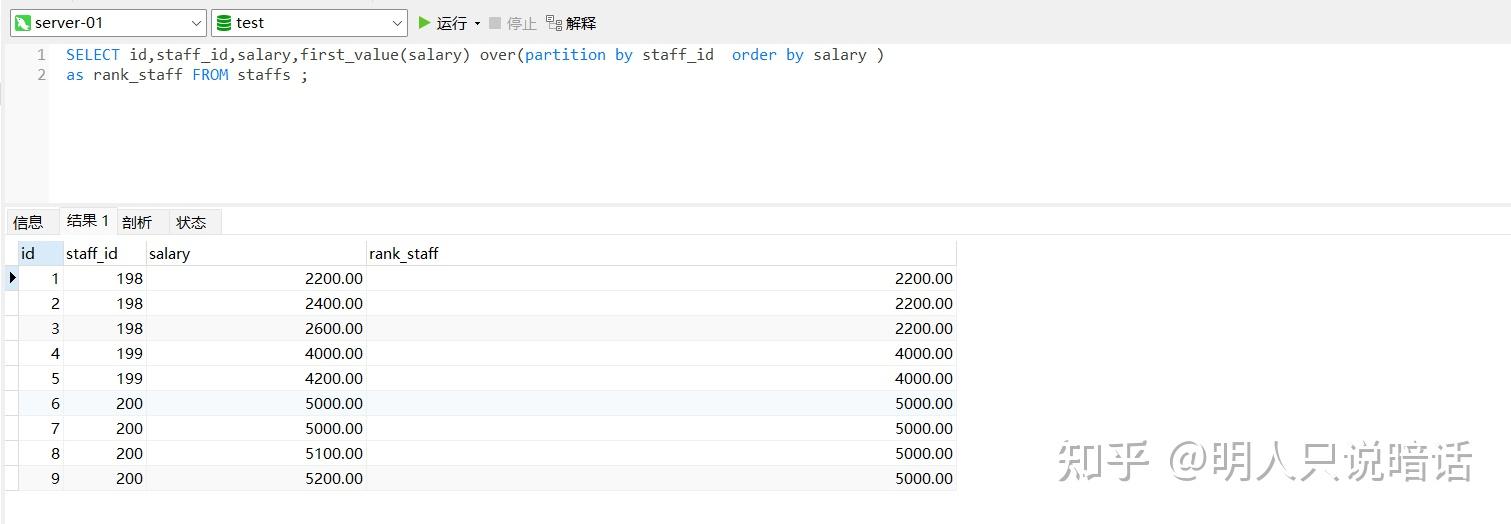
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条数据是一组,在本组内第一条数据的salary是2200.00,因此,这3条记录的first_value 都是2200.00。
同理,staff_id 为199的数据有2条,这2条数据是一组,在本组内第一条数据的salary是4000.00,因此,这2条记录的first_value 都是4000.00。
staff_id 为200的数据有4条,这4条数据是一组,在本组内第一条数据的salary是5000.00,因此,这4条记录的first_value 都是4000.00。
LAST_VALUE()
语法
LAST_VALUE (expression) OVER (
[partition_clause]
[order_clause]
[frame_clause]
) LAST_VALUE()函数返回expression有序行集的最后一行的值。
OVER有三个子句:partition_clause,order_clause,和frame_clause。
partition_clause子句将结果集的行划分为函数独立应用的分区;
order_clause子句指定FIRST_VALUE()函数操作的每个分区中行的逻辑顺序。
frame_clause定义当前分区的子集(或帧)。
作用
取各组内最后一条数据作为返回值。
SQL示例
SELECT id,staff_id,salary,last_value(salary) over(partition by staff_id order by salary
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
as rank_staff FROM staffs ;
结果
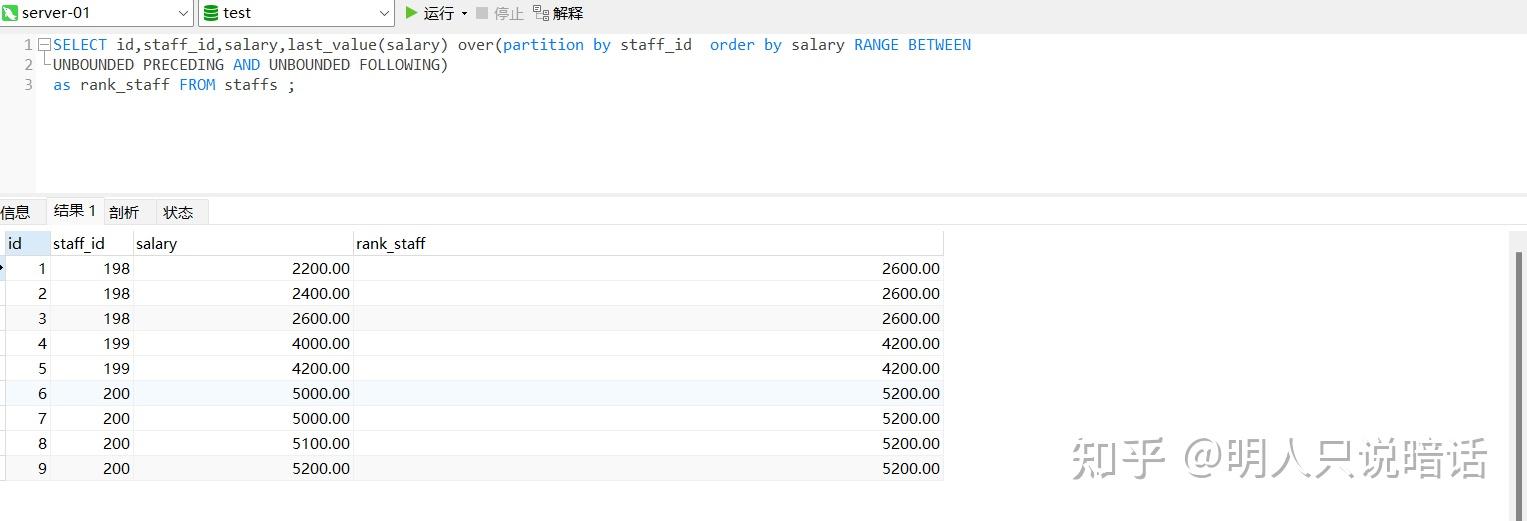
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条数据是一组,在本组内最后一条数据的salary是2600.00,因此,这3条记录的first_value 都是2600.00。
同理,staff_id 为199的数据有2条,这2条数据是一组,在本组内最后一条数据的salary是4200.00,因此,这2条记录的first_value 都是4200.00。
staff_id 为200的数据有4条,这4条数据是一组,在本组内最后一条数据的salary是5200.00,因此,这4条记录的first_value 都是5200.00。
LAG()
语法
LAG(<expression>[,offset[, default_value]]) OVER (
PARTITION BY expr,...
ORDER BY expr [ASC|DESC],...
) LAG()函数返回expression当前行之前的行的值,其值为offset 其分区或结果集中的行数。
offset是从当前行返回的行数,以获取值。offset必须是零或文字正整数。
如果offset为零,则LAG()函数计算expression当前行的值。
如果未指定offset,则LAG()默认情况下函数使用一个。
如果没有前一行,则LAG()函数返回default_value。
例如,如果offset为2,则第一行的返回值为default_value。如果省略default_value,则默认LAG()返回函数NULL。
PARTITION BY子句将结果集中的行划分LAG()为应用函数的分区。
ORDER BY子句指定在LAG()应用函数之前每个分区中的行的顺序。
作用
从同一结果集中的当前行访问上一行的数据,用于计算当前行和上一行之间的差异。
SQL示例
SELECT id,staff_id,salary,lag(salary,1,0) over(partition by staff_id order by staff_id )
as rank_staff FROM staffs ;
结果
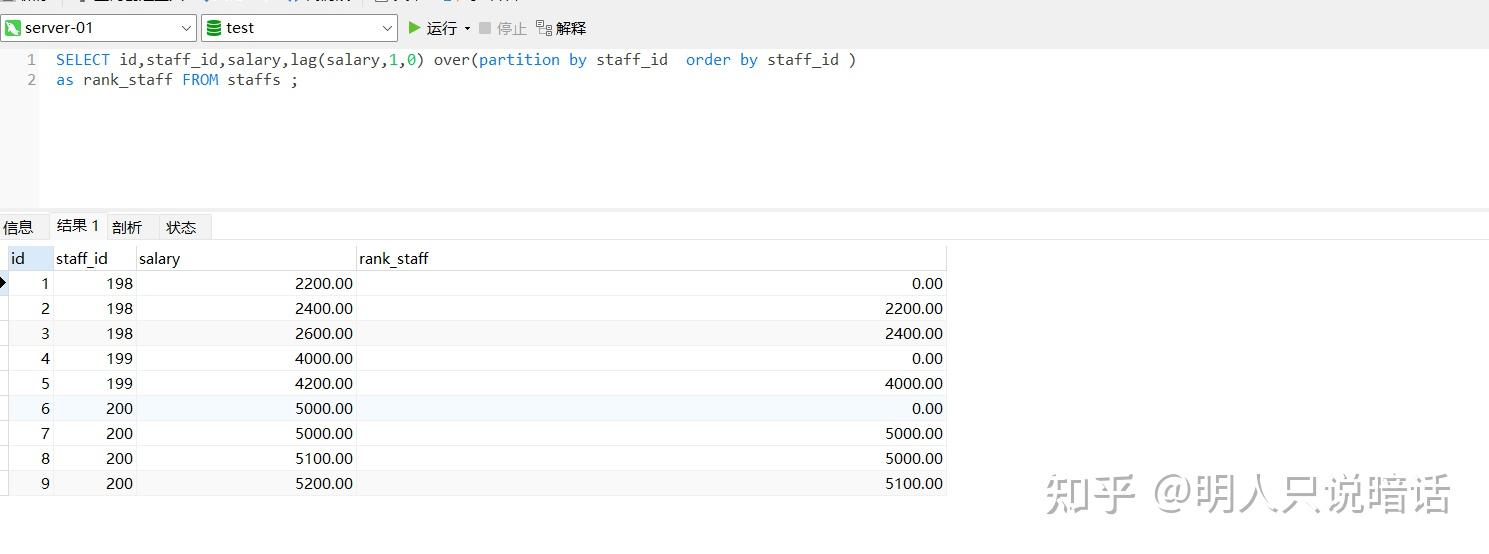
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条数据是一组,其中:
id = 1的记录是本组的第1条数据,它没有上一行,因此,lag 等于我们指定的 默认值0。
id = 2的记录是本组的第2条数据,它的上一行是id = 1的记录,因此,lag 等于 id = 1的记录的salary的值(2200.00)。
id = 3的记录是本组的第3条数据,它的上一行是id = 2的记录,因此,lag 等于 id = 2的记录的salary的值(2400.00)。
staff_id 为199的数据有2条,这2条数据是一组,其中:
id = 4的记录是本组的第1条数据,它没有上一行,因此,lag 等于我们指定的 默认值0。
id = 5的记录是本组的第2条数据,它的上一行是id = 4的记录,因此,lag 等于 id = 4的记录的salary的值(4000.00)。
staff_id 为200的数据有4条,这4条数据是一组,其中:
id = 6的记录是本组的第1条数据,它没有上一行,因此,lag 等于我们指定的 默认值0。
id = 7的记录是本组的第2条数据,它的上一行是id = 6的记录,因此,lag 等于 id = 6的记录的salary的值(5000.00)。
id = 8的记录是本组的第2条数据,它的上一行是id = 7的记录,因此,lag 等于 id = 7的记录的salary的值(5000.00)。
id = 9的记录是本组的第2条数据,它的上一行是id = 8的记录,因此,lag 等于 id = 8的记录的salary的值(5100.00)。
LEAD()
语法
LEAD(<expression>[,offset[, default_value]]) OVER (
PARTITION BY (expr)
ORDER BY (expr)
) LEAD()函数返回的值expression从offset-th有序分区排。
offset是从当前行向前行的行数,以获取值。
offset必须是一个非负整数。如果offset为零,则LEAD()函数计算expression当前行的值。
如果省略 offset,则LEAD()函数默认使用一个。
如果没有后续行,则LEAD()函数返回default_value。例如,如果offset是1,则最后一行的返回值为default_value。
如果您未指定default_value,则函数返回 NULL 。
PARTITION BY子句将结果集中的行划分LEAD()为应用函数的分区。
如果PARTITION BY未指定子句,则结果集中的所有行都将被视为单个分区。
ORDER BY子句确定LEAD()应用函数之前分区中行的顺序。
作用
从同一结果集中的当前行访问后续行的数据,用于计算当前行和下一行之间的差异。
SQL示例
SELECT id,staff_id,salary,lead(salary,1,0) over(partition by staff_id order by staff_id )
as rank_staff FROM staffs ;
结果
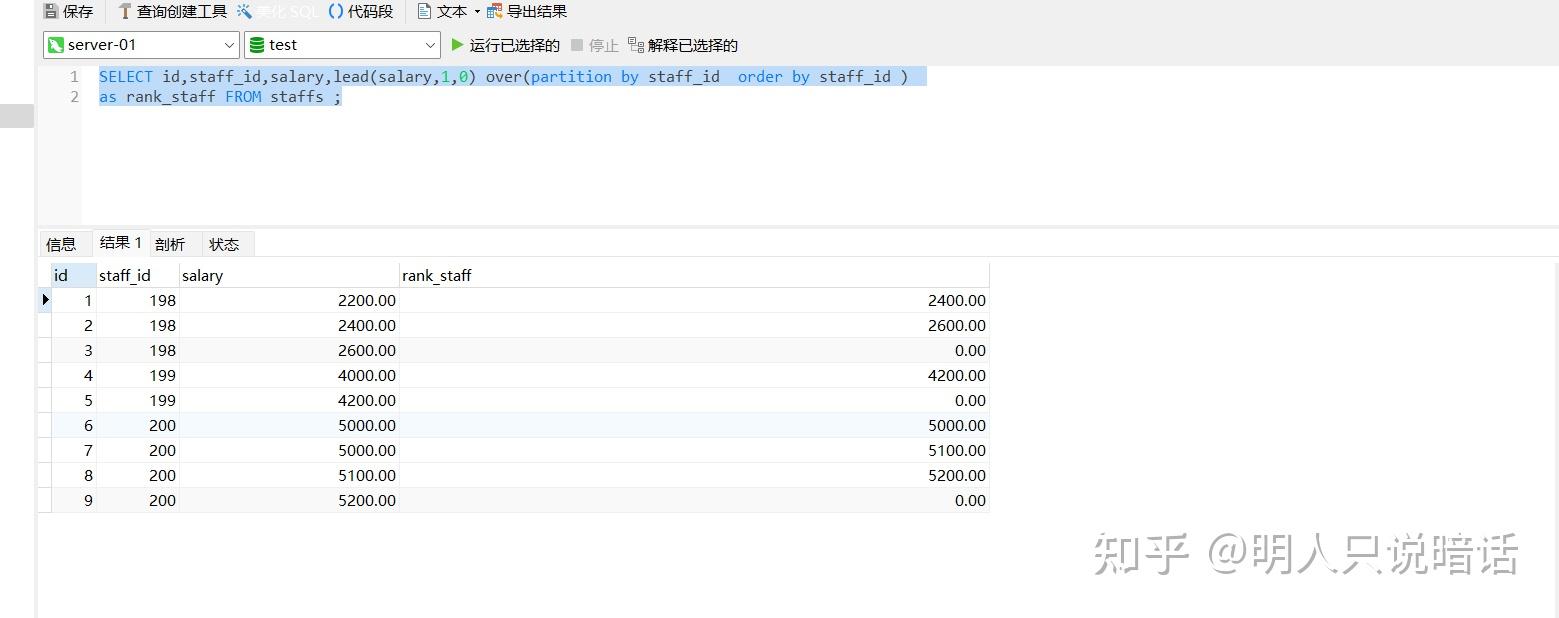
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条数据是一组,其中:
id = 1的记录是本组的第1条数据,它的下一行是id=2的记录,因此,lag 等于id = 2的记录的salary的值(2400.00)。
id = 2的记录是本组的第2条数据,它的下一行是id=3的记录,因此,lag 等于id = 3的记录的salary的值(2600.00)。
id = 3的记录是本组的第3条数据,它没有下一行,因此lag 等于我们设置的默认值0。
staff_id 为199的数据有2条,这2条数据是一组,其中:
id = 4的记录是本组的第1条数据,它的下一行是id=5的记录,因此,lag 等于id = 5的记录的salary的值(4200.00)。
id = 5的记录是本组的第2条数据,它没有下一行,因此lag 等于我们设置的默认值0。
staff_id 为200的数据有4条,这4条数据是一组,其中:
id = 6的记录是本组的第1条数据,它的下一行是id=7的记录,因此,lag 等于id = 7的记录的salary的值(5000.00)。
id = 7的记录是本组的第2条数据,它的下一行是id=8的记录,因此,lag 等于id = 8的记录的salary的值(5100.00)。
id = 8的记录是本组的第3条数据,它的下一行是id=9的记录,因此,lag 等于id = 9的记录的salary的值(5200.00)。
id = 9的记录是本组的第4条数据,它没有下一行,因此lag 等于我们设置的默认值0。
NTH_VALUE()
语法
NTH_VALUE(expression, N)
FROM FIRST
OVER (
partition_clause
order_clause
frame_clause
) NTH_VALUE()函数返回expression窗口框架第N行的值。
如果第N行不存在,则函数返回NULL。
N必须是正整数。
FROM FIRST指示NTH_VALUE()功能在窗口帧的第一行开始计算。
作用
从结果集中的第N行获取值。
SQL示例
SELECT id,staff_id,salary,NTH_VALUE(salary,3) over(partition by staff_id order by staff_id )
as rank_staff FROM staffs ;
结果
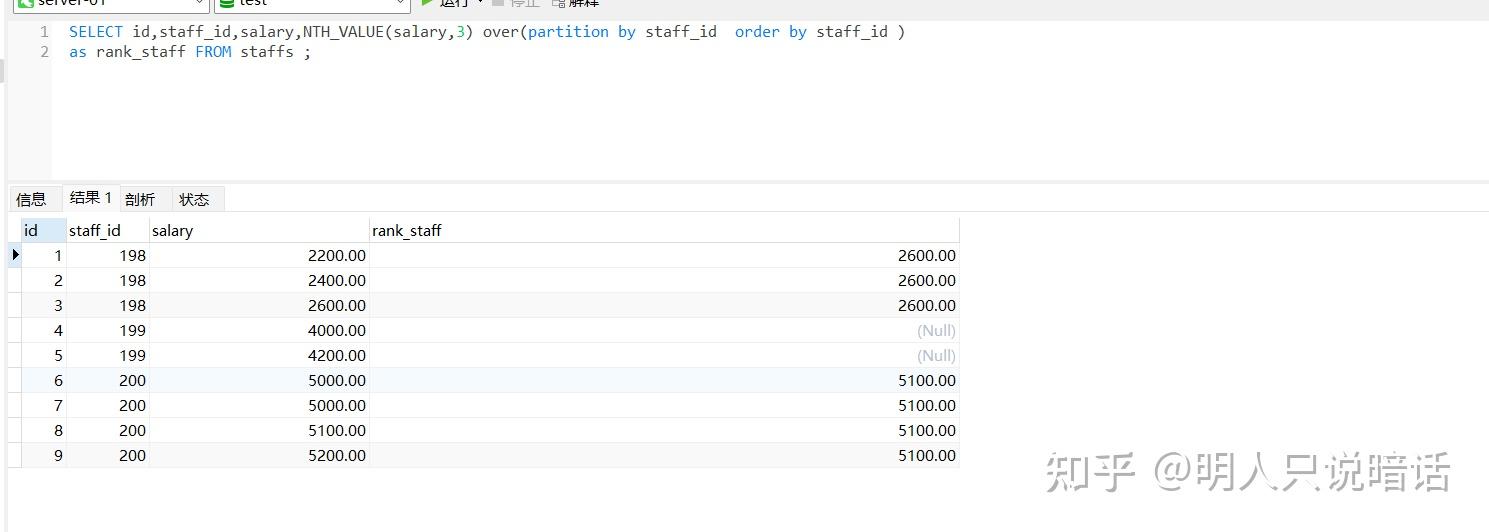
分析
如上图所示。
数据记录总数是9。
staff_id 为198的数据有3条,这3条数据是一组,在这一组中,第3条记录的salary是2600.00,因此这一组的所有记录的NTH_VALUE 都是2600.00。
staff_id 为199的数据有2条,这2条数据是一组,在这一组中,没有第3条记录,因此因此这一组的所有记录的NTH_VALUE 都是空。
staff_id 为200的数据有4条,这4条数据是一组,在这一组中,第3条记录的salary是5100.00,因此这一组的所有记录的NTH_VALUE 都是5100.00。
<hr/>以上就是本文内容。
我是 @明人只说暗话,欢迎点赞、评论、关注。 |
|


 发表于 2023-2-10 13:17:19
发表于 2023-2-10 13:17:19