(7)C++ Ecosystem International Standard
C++ 标准委员会的核心产出是一份说明 C++ 核心语言与 C++ 标准库定义的文档。除此之外的事情,原则上都不归委员会管了。虽然 C++ 程序员们谈起 C++ 标准时往往会带着敬畏的态度,但 C++ 今日的成功决不只取决于 C++ 语言本身,更取决于 C++ 的生态。
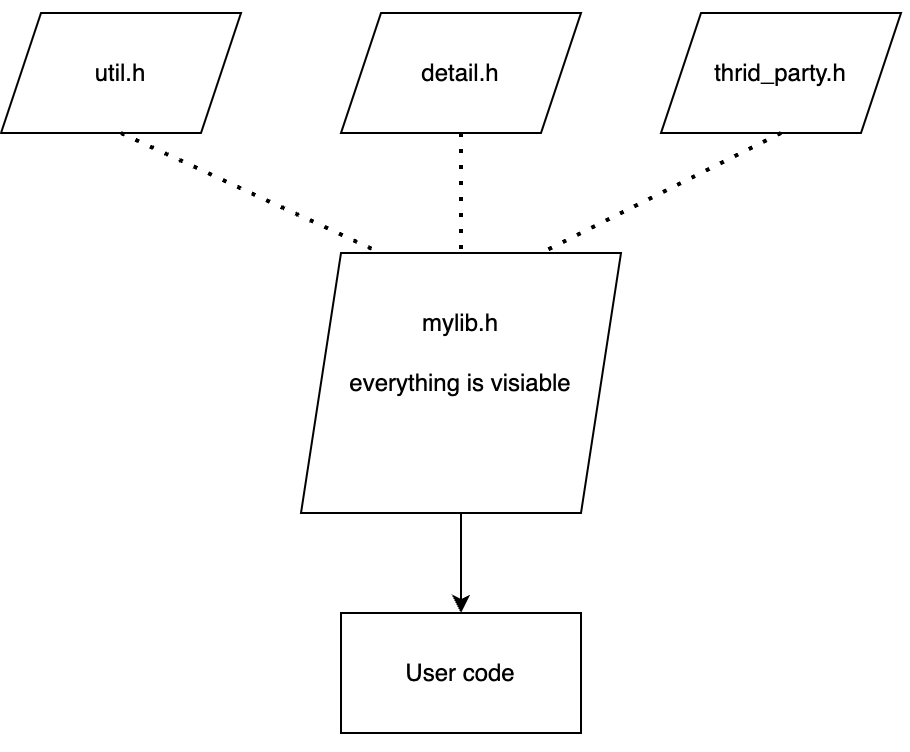
例如,对于绝大多数 C++ 程序员来说,他们阅读标准的时间应该是远小于他们与编译器、链接器、构建系统、包管理器、调试器、静态分析工具与动态分析工具等等工具打交道的时间的。这里我们暂且将 C++ 生态的概念限制为 C++ 工具的生态。然而与有着统一标准 C++ 语言规范不同,C++ 工具间的交互能力(interoperability)的规范只能说是经验主义、约定俗成的。这对于现有 C++ 工具的维护者来说是个不小的负担。而对于新 C++ 工具的开发者而言,更是要花上大量的时间去关注非规范的 C++ 工具生态,这给新 C++ 工具的开发带来了非常重的、额外的、其实本不必要的负担。
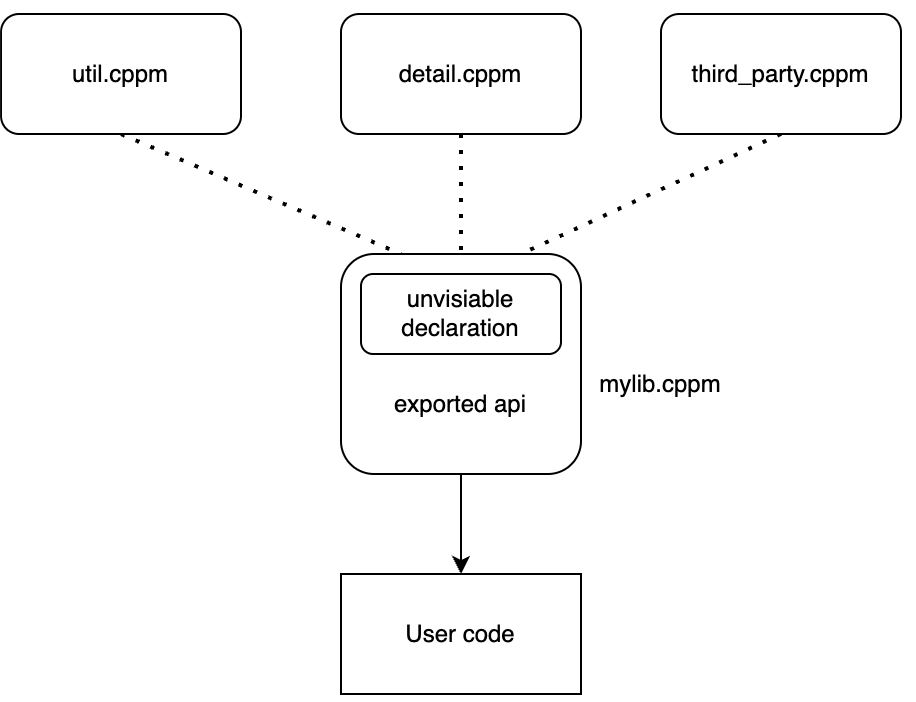
这个问题在 C++ 引入 Modules 后变得更严峻了,因为 Modules 会给现有的几乎所有 C++ 工具带来全新的挑战。为了解决以上提到的这些问题,委员会提出有必要制订 C++ Ecosystem International Standard[1]来为 C++ 生态制订明确的规范。
虽然目前距离第一版规范的面世还遥遥无期,或者说 C++ Ecosystem International Standard 应该包含那些部分都还没有完全确定下来。但我们相信,这一定是 C++ 发展历史上极为重要的一步。 Modules
Header files are a major source of complexity, errors caused by dependencies, and slow compilation. Modules address all three problems.
头文件是复杂性、依赖错误、编译太慢的主要根源,而 Modules 则能够解决了这三个问题。
—— Bjarne Stroustrup,C++ 之父
Modules 被很多人认为是 C++20 中最重要的特性,同时也是对 C++未来影响最大的特性。原因之一可能是因为只能使用文本替换以引入依赖的 C++ 看起来确实很不 Modern。在笔者所知的所有主流高级语言中,除了 C++ 之外,唯一还使用 Modules 的语言是 C 语言,就连 Fortran 也都早就用上了 Modules。
但与之相对应的,Modules 也是 C++20 四大特性(Modules、Coroutines、Concepts 和 Ranges)中被各个编译器支持地最慢、最不完善的一个特性。我们在本节中会先对 Modules 语法做一个简单的介绍、之后会介绍 Modules 在编译器、构建系统及其他工具中的支持情况,再对 Modules 的未来做一个展望。 (1)语法简介
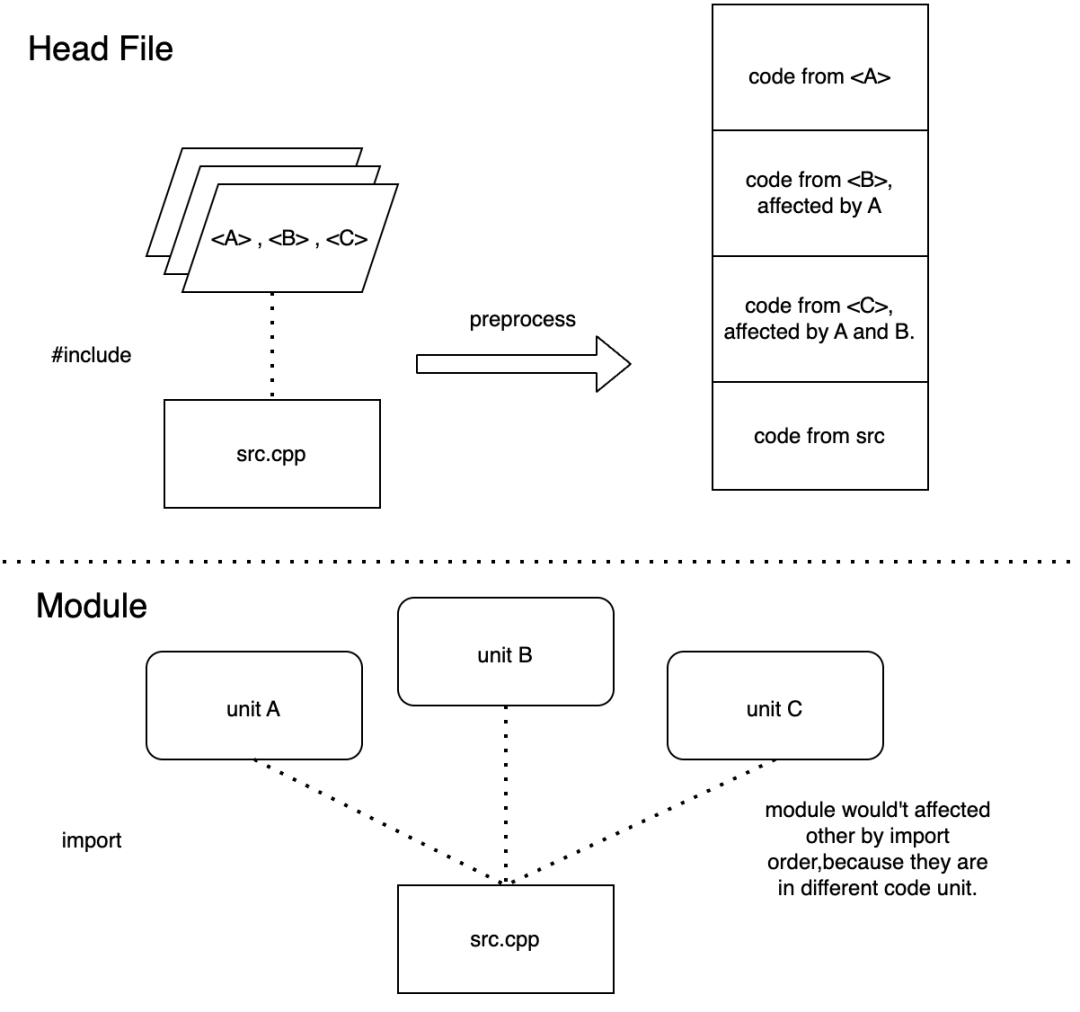
Modules 可简单分类为 Named Modules 和 Header Units。对文字比较敏感的朋友看到这句话肯定会觉得很难受。为什么 Units 和 Modules 是并列的呢?这里指的其实是 import 关键字后可接的内容。import后可接 module-name(及 partition-name)和 header-name。
严格来说,Modules 可分为 Named Modules 和 Unnamed Modules(也叫 Global Modules)。Named Modules 是由 module-unit 声明的。module-unit 是一类特殊的 translation-unit。而 header-unit 则是在 import header-name; 时合成(Synthesized)的一种特殊 translation-unit,同时 header-unit 中的声明均视为位于 Global Module 中。这样一来,大家也就能理解为什么 Modules 会被分类为 Named Modules 和 Header Units 了。
接下来我们会简单介绍下 Modules 的语法,但不会引入所有细节,只是希望大家通过这一小节能对 Modules 有个直观的感受。大家感兴趣的话可以再找更进阶的材料学习。 Header Units
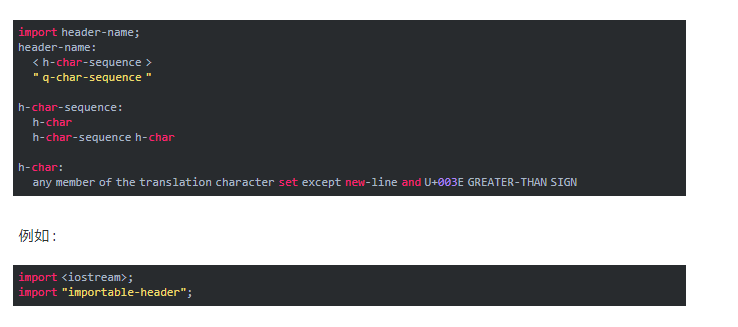
Header Units 的语法为:
看上去很简单,似乎只需要把 #include 换成 import 再加个分号就好了。但事实远没这么简单。观察例子的第二行,这里写的是 import "importable-header"; 即 Header Units 只能 import 所谓的 importable-header。但什么是 importable-header 呢?C++ 标准的说法是 implementation-defined。只有标准库中的头文件需要是 importable-header。这给包括工具链开发者在内的广泛用户带来了非常深的困扰。意味着我们无法确定任何使用了 Header Units 的代码是否是符合标准的、跨编译器与跨平台兼容的。
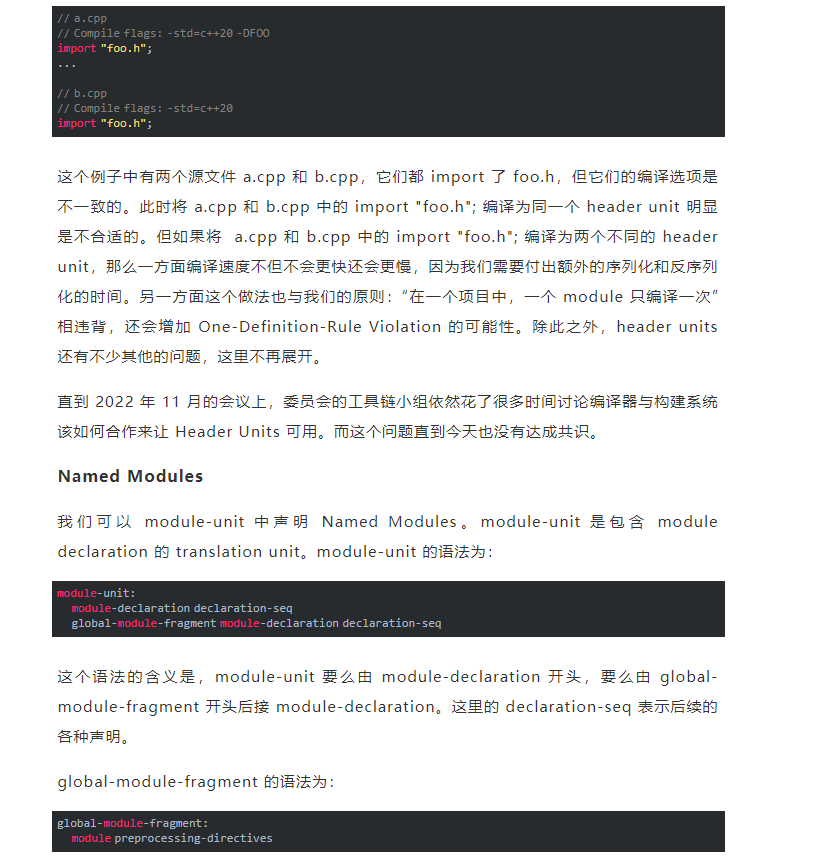
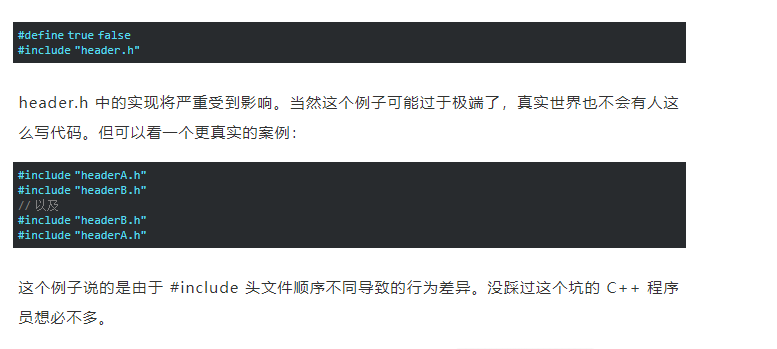
Header Units 的问题还不止于此,来看下面这个例子:
而在使用 Modules 之后,不会再受到外界定义的宏的影响,同时 import modules; 的顺序也不会改变程序的行为。 更强的一致性检查
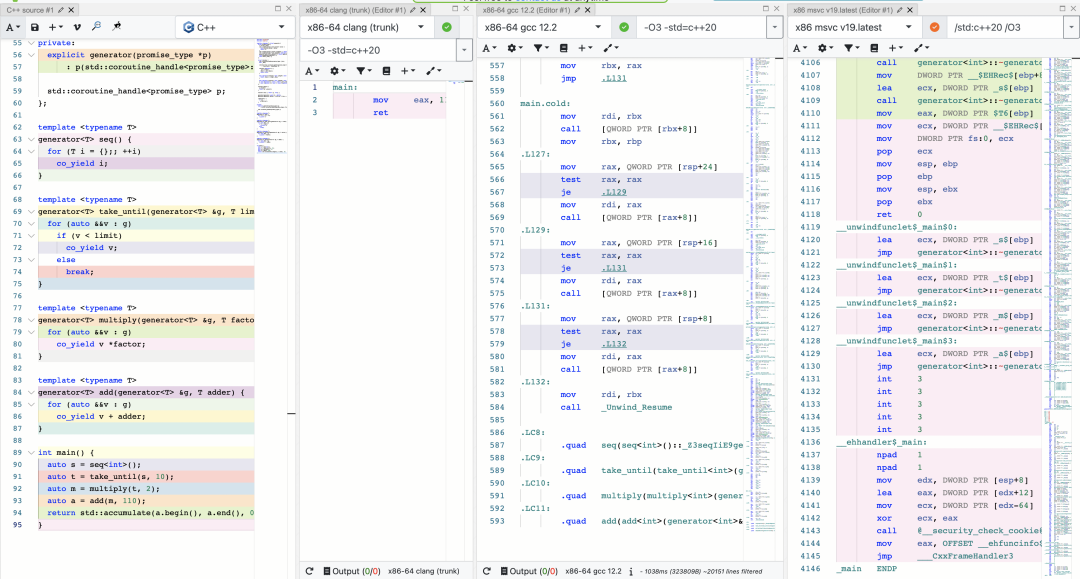
One Definition Rule(ODR)是 C++ 的重要规则。ODR 可以简单理解为在一个程序中一个 Entity 只应该拥有一个定义。违反 ODR 可能给 C++ 程序带来很严重同时很难查的 bug。但在之前的编译模型当中,每个 TU 都是单独编译的,互不干扰。这使得编译器只能在当前 TU 中检查 ODR,对于跨 TU 的 ODR Violation,之前的编译器是无能为力的。
之前的实践方式都是将跨 TU 的 ODR violation 检查交给链接器来做。但由于从高级语言到链接器之间已经损失了非常多的信息,链接器能检查到的 ODR violation 是有限的。而在 Modules 进入 C++ 之后,我们就拥有了在编译器前端进行跨 TU 检查 ODR violation 的能力,这是一个很大的进步。 编译加速
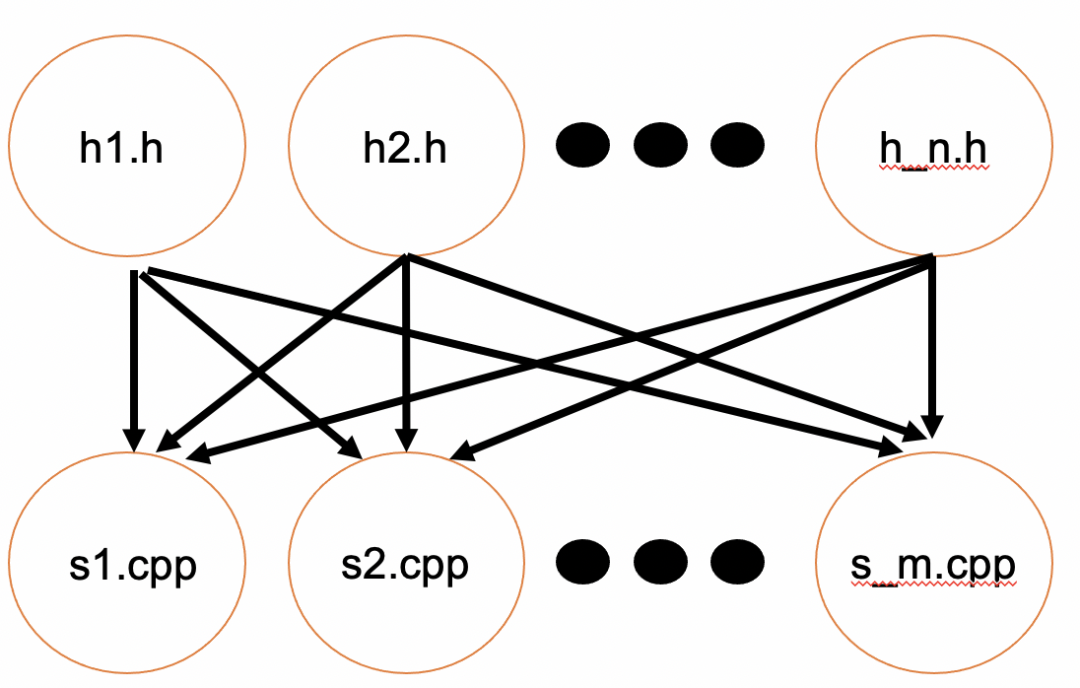
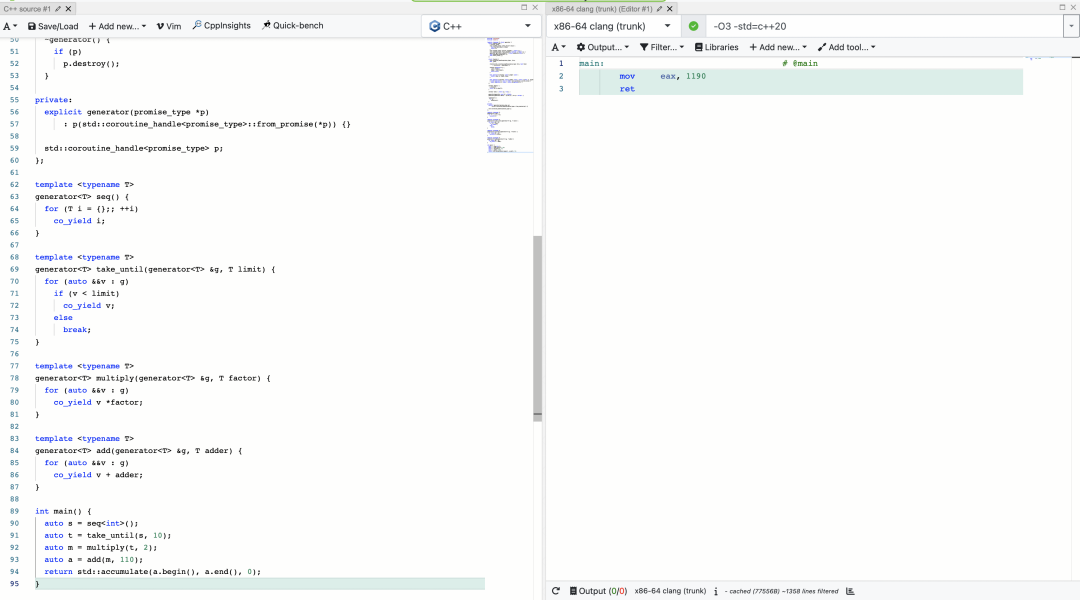
Modules 很吸引 C++ 程序员的一个特性即是 Modules 的编译加速能力。从定性的角度分析 Modules 编译加速能力时,我比较喜欢用这个例子来解释:如果一个项目中存在 N 个头文件与 M 个源文件,每个源文件都 include 了每个头文件,那么这个项目的编译时间复杂度可以表示为 O(N*M)。


 发表于 2023-2-9 22:20:33
发表于 2023-2-9 22:20:33