|
|
MVCC 机制
本文承接自前文:中间件 - MySQL 知识梳理 - 1:事务隔离
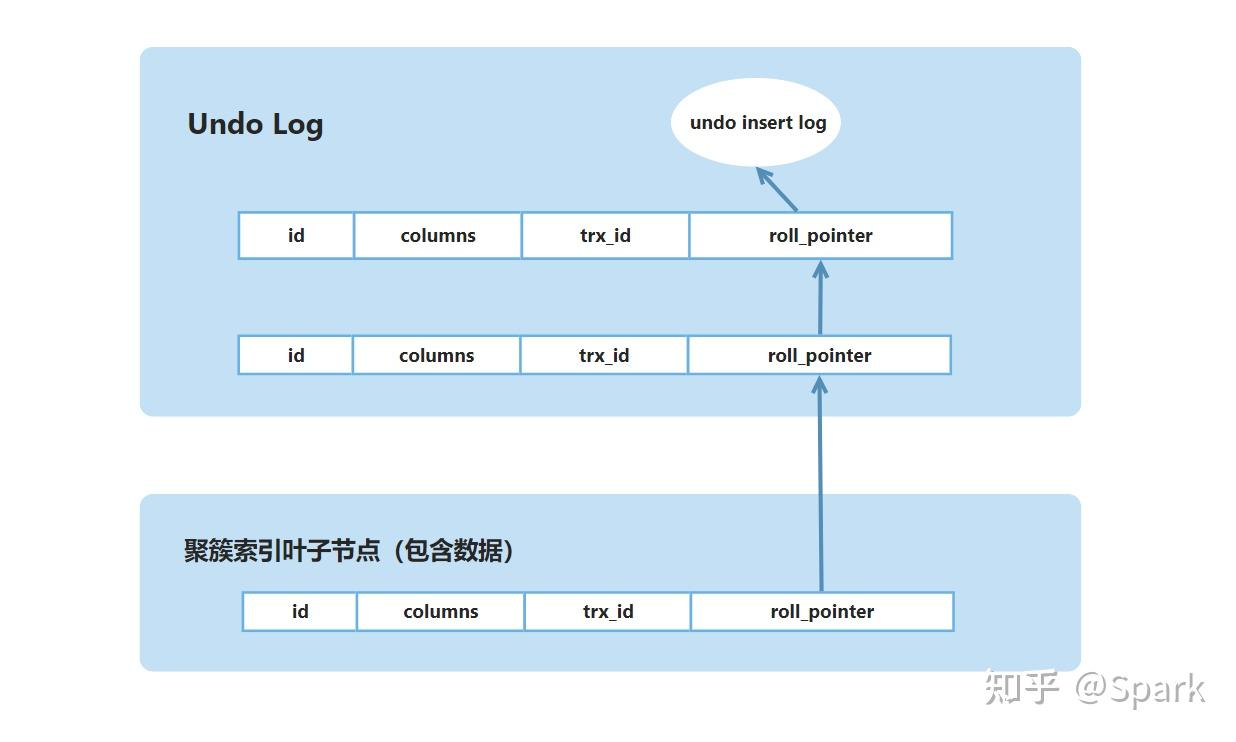
MySQL 为每一条记录会新增 2 个隐藏列:事务 ID (trx_id) 和回滚指针 (roll_pointer),并且维护 undo log,执行写操作时,会默认进行加锁,在读操作时,利用 undo log 设计了 MVCC(Multi-Version Concurrency Control,多版本并发控制)机制
一般,都说 MySQL 只在 RC 和 RR 两个隔离级别应用 MVCC,实现快照读(支持不加锁的并发读取数据)。我的理解是,MySQL 并没有区别对待其他 2 个隔离级别,而是他们不需要用到多版本,读操作的时候,只扫描索引中的数据记录就够了,不需要用回滚指针去追溯 undo log 记录
对于 RC 和 RR,MVCC 的查找行为也是相同的,具体逻辑如下:
事务开启后,每个查询语句,会生成一个视图 read-view。这个视图包含两个关键信息:
- 当前时间点所有未提交事务 ID 的集合
- 当前所有事务(无论是否提交)的最大 ID
这里补充一个知识点:事务 ID 是在事务执行第一个修改操作时,才真正生成的,严格递增
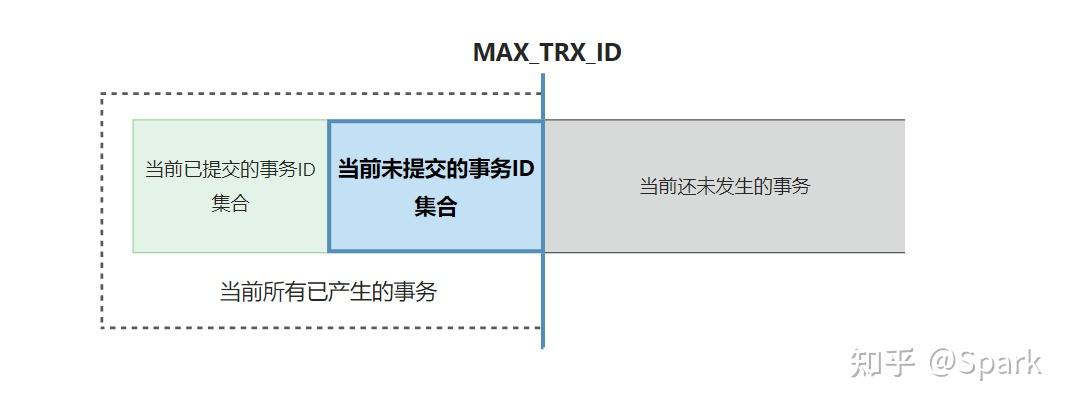
如下图所示,MAX_ID 是区分现状和未来的分界线,相当于标识当前现状的范围区间;所有大于 MAX_ID 的事务,都代表是未来发生的
然后在现状中,事务合集 = 已提交集合 + 未提交集合;如果我知道了未提交的合集(相对已提交会比较少),那已提交的部分作差集也就知道了
所以,read-view 中记录的 2 个信息,就足够帮助我们判断任意一个事务是属于图中三个类别中的哪个类别
接下来,读操作就会根据对应的 read-view,从 undo log 链(包括当前行)按照指针的方向进行遍历,目标是当前已提交的最新数据(上图中绿色部分)
因为整个链表是按照时间追加的,所以第一个符合要求的记录就是最新的期望结果
在逐条遍历的过程中,遵循以下逻辑:
- 如果条目记录的 trx_id 就是自己,说明是自己修改的,直接返回结果:对事务来说,自己修改的数据,是在别人已提交的基础上更新的,优先级更高
- 如果条目记录的 trx_id > MAX_ID,表示这个版本是未来的事务提交的(图中灰色部分),不符合,继续遍历
- 如果 trx_id < MAX_ID,但在 read-view 记录的未提交事务集合中(图中蓝色部分),也不符合,继续遍历
- 剩下的,必然是当前已提交的事务(图中绿色部分),返回结果
RC 和 RR 的区别,在于 read-view 的组成:
- RC 是基于当前时间点实时生成最新的 read-view:视图在整个事务过程中,会不断动态变化
- RR 在第一次查询生成 read-view 后,在整个事务过程中,不会再发生变化
MVCC 机制主要就是理解 2 个关键点:
- read-view
- 遍历 undo log 的查找逻辑
补充问答
为什么 MVCC 不通过直接记录快照所对应的版本来查找?
MySQL 会为每条记录都维护 undo log,而且快照读生效的范围是整个数据库,所以要每个记录都去记下快照所对应的版本,开销过大,并不是好的做法 |
|


 发表于 2023-2-7 14:23:24
发表于 2023-2-7 14:23:24
