|
|
1.背景
Apache Hive 是基于 Apache Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并且提供了 Hive SQL 进行查询和分析,在离线数仓中被广泛使用。
Hive Metastore 是 Hive 的元信息管理工具,它提供了操作元数据的一系列接口,其后端存储一般选用关系型数据库如 Derby、 MySQL 等。现在很多除了 Hive 之外计算框架都支持以 Hive Metastore 为元数据中心来查询底层 Hadoop 生态的数据,比如 Presto, Spark, Flink 等等。
在知乎,我们是将元信息存储在 MySQL 内的,随着业务数据的不断增长,MySQL 内已经出现单表数据量两千多万的情况,当用户的任务出现 Metastore 密集操作的情况时,往往会出现缓慢甚至超时的现象,极大影响了任务的稳定性。长此以往,MySQL 在未来的某一天一定会不堪重负,因此优化 Hive 的元数据库势在必行。
在去年,我们做过数据治理,Hive 表生命周期管理,定期去删除元数据,期望能够减少 MySQL 的数据量,缓解元数据库的压力。但是经过实践,发现该方案有以下缺点:
- 数据的增长远比删除的要快,治标不治本;
- 在删除超大分区表(分区数上百万)的分区时,会对 MySQL 造成一定的压力,只能单线程去做,否则会影响其他正常的 Hive 查询,效率极其低下;
- 在知乎,元信息删除是伴随数据一起删除的(删除 HDFS 过期数据,节约成本),Hive 的用户可能存在建表不规范的情况,将分区路径挂错,导致误删数据。
因此,我们需要寻找新的技术方案来解决这个问题。
2.技术选型
2.1 已有方案
业内目前有两种方案可供借鉴:
- 对 MySQL 进行分库分表处理,将一台 MySQL 的压力分摊到 MySQL 集群;
- 对 Hive Metastore 进行 Federation,采用多套 Hive Metastore + MySQL 的架构,在 Metastore 前方设置代理,按照一定的规则,对请求进行分发。
但是经过调研,我们发现两种方案都有一定的缺陷:
- 对 MySQL 进行分库分表,首先面临的直接问题就是需要修改 Metastore 操作 MySQL 的接口,涉及到大量高风险的改动,后续对 Hive 的升级也会更加复杂;
- 对 Hive Metastore 进行 Federation,尽管不需要对 Metastore 进行任何改动,但是需要额外维护一套路由组件,并且对路由规则的设置需要精心设计,切分现有的 MySQL 存储到不同的 MySQL 上,并且可能存在切分不均匀,导致各个子集群的负载不均衡的情况;
- 我们每天都会同步一份 MySQL 的数据到 Hive,用作数据治理,生命周期管理等,同步是利用内部的数据同步平台,如果采用上面两种方案,数据同步平台也需要对同步逻辑做额外的处理。
2.2 最终方案
其实问题主要在于,当数据量增加时,MySQL 受限于单机性能,很难有较好的表现,而将单台 MySQL 扩展为集群,复杂度将会呈指数上升。如果能够找到一款兼容 MySQL 协议的分布式数据库,就能完美解决这个问题。因此,我们选择了 TiDB.
TiDB 是 PingCAP 开源的分布式 NewSQL 数据库,它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适 OLAP 场景的混合数据库。
选用 TiDB 的理由如下:
- TiDB 完全兼容 MySQL 的协议,经过测试,TiDB 支持 Hive Metastore 对元数据库的所有增删改查操作, 使用起来不存在兼容性相关的问题。因此,除了将 MySQL 的数据原样 dump 到 TiDB,几乎没有其他工作需要做;
- TiDB 由于其分布式的架构,在大数据集的表现远远优于 MySQL;
- TiDB 的可扩展性十分优秀,支持水平弹性扩展,不管是选用分库分表还是 Federation,都可能会再次遇到瓶颈,届时需要二次切分和扩容,TiDB 从根本上解决了这个问题;
- TiDB 在知乎已经得到了十分广泛的应用,相关技术相对来说比较成熟,因此迁移风险可控。
3. Hive 架构
3.1 迁移前
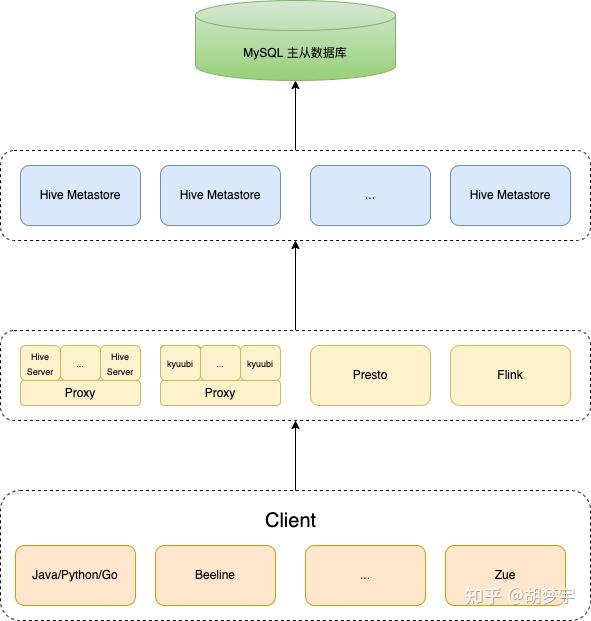
其中,Zue 是知乎内部使用的可视化查询界面。
3.2 迁移后
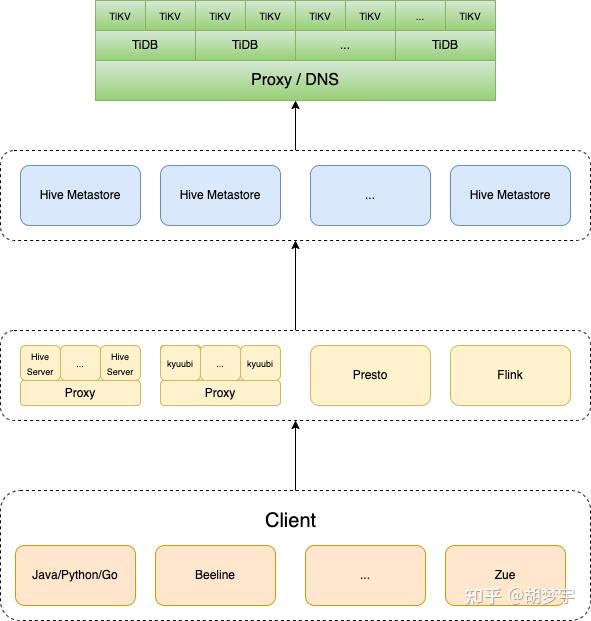
在 Hive 的元数据库迁移到 TiDB 了以后,架构几乎没有任何变化,只不过查询的压力由单台 MySQL 节点分摊到了整个 TiDB 集群,集群越大,查询效率越高,性能提升越明显。
4. 迁移流程
- 将 TiDB 作为 MySQL 的从库,实时同步数据,这一步可以借助 TiDB 社区提供的同步工具来做;
- 修改 Hive Metastore 的元数据库配置为 TiDB;
- 选取业务低峰期,Metastore 缩容至 1 个,防止多个 Metastore 分别向 MySQL 及 TiDB 写入,导致元数据不一致;
- 停止仅剩的 Hive Metastore,TiDB 放弃从 MySQL 同步数据,启动所有 Metastore ,切换完成。
此迁移过程对业务几乎无感,可以平稳上线。
5. 运行概况
- 我们从 Hive 层面对数据库进行了测试,模拟业务高峰期,多并发对百万分区级别的表增删分区,所执行的 Hive SQL 如下:
ALTER TABLE '${table_name}' DROP IF EXISTS PARTITION(...);
ALTER TABLE '${table_name}' ADD IF NOT EXISTS PARTITION(...);花费时间从 45s-75s 降低到了 10s 以下;
2. 我们从元数据库层面测试了一些 MetaStore 提交的 SQL,尤其是那些会造成元数据库压力巨大的 SQL,例如:
SELECT `A0`.`PART_NAME`,`A0`.`PART_NAME` AS `NUCORDER0` FROM `PARTITIONS` `A0` LEFT OUTER JOIN `TBLS` `B0` ON `A0`.`TBL_ID` = `B0`.`TBL_ID` LEFT OUTER JOIN `DBS` `C0` ON `B0`.`DB_ID` = `C0`.`DB_ID` WHERE `C0`.`NAME` = '${database_name}' AND `B0`.`TBL_NAME` = '${table_name}' ORDER BY `NUCORDER0`
当某个 Hive 表的分区数量十分巨大时,这条 SQL 会给元数据库造成相当大的负担。迁移前,此类 SQL 在 MySQL 运行时间约为 30s - 40s,迁移后,在 TiDB 运行仅需 6s - 7s,提升相当明显;
3. 数据同步平台上的 Hive 元数据库内的 SDS 表的同步任务时间从 90s 降低到 15s。
6. 常见问题
6.1 MySQL 外键如何处理
MySQL 外键在 TiDB 里面会直接被忽略,虽然行为有一点不一致,但是去掉了外键后,并没有对 Hive Metastore 的使用造成任何影响。知乎将 Metastore 的元数据库替换成 TiDB 已经两年多了,期间运行稳定,没有出过任何故障。
6.2 事务相关异常处理
在换成 TiDB 时,根据 TiDB 的不同版本,Metastore 可能会抛出如下异常:
MetaException(message:The isolation level 'SERIALIZABLE' is not supported. Set tidb_skip_isolation_level_check=1 to skip this error只需要设置如下属性即可:
set global tidb_skip_isolation_level_check=1;6.3 Hive Metastore 和 TiDB 兼容的版本是什么
Hive Metastore 的版本我们使用过 2.1.1 和 2.3.4 两个版本,其他版本需要测试,但是一般都是兼容的。
TiDB 版本从 4.0 以后的几乎所有版本都兼容。
6.4 Hive Metastore lock 接口不兼容
早期的 TiDB 版本没有支持 savepoint 语法,导致 Metastore 客户端调用 lock 方法时,会报错,这个问题在使用 Iceberg 的 HiveCatalog 时,是致命的。但是 TiDB 的高版本已经支持 savepoint 语法,可以参考 https://docs.pingcap.com/zh/tidb/dev/sql-statement-savepoint。
6.5 推荐的 TiDB 配置
一般来说,TiDB 的配置给的越高,Hive Metastore 的性能越好。但是因为 TiDB 本身有分布式的开销,所以很难达到 1+1=2,而是 1+1≈2。如果是想要性能达到原来的两倍以上,建议给 TiDB 三倍或以上的原 MySQL 的配置。
目前知乎是直接将原来的 MySQL 配置翻了十倍,组成的 TiDB 集群供整个离线业务使用,比如离线调度平台,Flink SQL 平台等,都是和 Hive Metastore 共享整个集群。
离线业务一般情况下只记录任务信息与实例运行状况,很少有大规模的吞吐与锁的开销,它们占用的资源十分少,因此与 Hive Metastore 共享 TiDB 集群基本不会对其有影响。 |
|


 发表于 2023-1-18 14:40:36
发表于 2023-1-18 14:40:36