|
|
MYSQL
- 深入理解MYSQL索引底层数据结构和算法
- 索引的定义:索引是帮助MYSQL高效的获取排好序的数据的数据结构。
- 索引的数据结构
- 二叉树
- 红黑树
- 二叉平衡树,树高度logn+1.以20000000条数据为例,h=log20000000=25
- Hash表
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+Tree更高效
- 仅能满足=、in,不支持范围查询
- hash冲突问题(数组+链表)
- B-Tree
- 叶子节点具有相同的深度,叶节点的指针为空。
- 所有索引的元素不重复
- 节点中的数据索引从左到右递增排列
- B+Tree
- 非叶子节点不存储data,只存储索引(冗余),索引空白部分指向其他页的地址,可以放更多的索引,
- 查看页大小:show global status like 'innodb_page_size';
- 存储引擎
- MyISAM:索引文件和数据文件是分离的,属于非聚集索引
- test.frm 存放表结构等信息
- test.MYD 存放数据
- test.MYI 存放索引
- InnoDB:索引文件和数据文件是不分离的,属于聚集索引
- 表结构文件本身就是按B+Tree组织的一个索引结构文件。
- 叶子节点包含了完整的数据记录。
- 建议InnoDB表必须建主键,并且推荐使用整型的自增主键。
- 非主键索引(二级索引)结构中的叶子节点存储的是主键值。
- 保持一致性,若修改记录内容,只需要改一次主键索引中的数据,再更新非主键索引即可。
- 节省空间,只用保留一份数据即可,若索引中全都要有完整数据,浪费硬盘。
- 联合索引底层数据结构:多个字段组成的联合索引,按字段顺序进行排序
- 遵循索引最左前缀原理
- 如果第一个字段是范围查询需要单独建一个索引;
- 在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边;
- Explain详解与索引最佳实践
- explain工具介绍
- 模拟优化器执行SQL语句
- 分析你的查询语句或是结构的性能瓶颈
- 执行查询会返回执行计划的信息
- from 中包含子查询,仍会执行该子查询,将结果放入临时表中
- explain 两个变种,MySQL5.7以后不用了
- explain extended
- explain partitions
- explain中的列
- id
- select_type
- simple:简单查询。查询不包含子查询和union
- primary:复杂查询中最外层的 select
- subquery:子查询,包含在 select 中的子查询(不在 from 子句中)
- derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义:衍生)
- union:在 union 中的第二个和随后的 select
- table
- 表示 explain 的一行正在访问哪个表,当 from 子句中有子查询时,table列是 <derivenN> 格式,
- 有 union 时,UNION RESULT 的 table 列的值为<union1,2
- type
- system
- const
- eq_ref
- primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
- ref
- 相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行
- range
- 范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行
- index
- all
- possible_keys
- key
- NULL
- force index
- ignore index
- key_len
- 列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列
- 字符串
- char(n):如果存汉字长度就是 3n 字节
- varchar(n):如果存汉字则长度是 3n + 2 字节
- 数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
- 时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
- ref
- 这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
- row
- 是mysql估计要读取并检测的行数,并非最终结果集的条数
- extra
- Using index:使用覆盖索引
- Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖
- Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围
- Using temporary:mysql需要创建一张临时表来处理查询
- Using filesort:将用外部排序而不是索引排序
- Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段
- 索引最佳实践
- 全值匹配
- 最左前缀法则
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句
- mysql在使用不等于(!=或者<>),not in ,not exists 的时候无法使用索引会导致全表扫描< 小于、 > 大于、 <=、>= 这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
- is null,is not null 一般情况下也无法使用索引
- like以通配符开头(&#39;$abc...&#39;)mysql索引失效会变成全表扫描操作
- 字符串不加单引号索引失效
- 少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
- 范围查询优化
- SQL底层执行原理详解
- 客户端层
- 命令行连接,linux或者windows下安装的mysql客户端,通过命令行连接。
- JDBC,java通过jdbc连接数据库。
- navicat等连接工具,可视化。
- 服务端层
- 连接器:管理连接与权限校验。
- mysql -h 数据库地址 -u 用户 -p 密码 -P 端口
- show processlist;
- kill Id;
- show global variables like &#34;wait_timeout&#34;;
- set global wait_timeout=28800;
- 查询缓存
- 词法分析器:词法分析,语法分析
- 词法分析
- 语法分析
- 语义分析
- 构造执行树
- 生产执行计划
- 计划的执行
- 优化器:执行计划生成索引选择
- 执行器:调用引擎接口获取查询结果
- 存储引擎层
- Innodb:最常用,从 MySQL 5.5.5 版本开始成为了默认存储引擎。
- MyISAM
- memory:不常用
- bin-log归档
- 开启binlog功能,配置my.cnf
- log-bin=/usr/local/mysql/data/binlog/mysql-bin
- server-id=123454
- binlog-format=ROW(有3种statement,row,mixed),推荐row
- sync-binlog=1
- #表示每1次执行写入就与硬盘同步,会影响性能,为0时表示,事务提交时mysql不做刷盘操作,由系统决定
- binlog命令
- show variables like &#39;%log_bin%&#39;; 查看bin-log是否开启
- flush logs; 会多一个最新的bin-log日志
- show master status; 查看最后一个bin-log日志的相关信息
- reset master; 清空所有的bin-log日志
- 查看binlog内容
- /usr/local/mysql/bin/mysqlbinlog --no-defaults /usr/local/mysql/data/binlog/mysql-bin.000001
- 寻找begin,commit这种关键词信息,只要在binlog当中看到了,你就可以理解为begin-commit之间的信息是一个完整的事务逻辑,然后再根据位置position判断恢复即可
- Mysql索引优化实战1
- 综合例子
- 联合索引第一个字段用范围不会走索引
- explain select name,age,position from employeeswhere name > &#39;LiLei&#39; and age = 22 and position = &#39;manager&#39;;
- 强制走索引
- explain select * from employeesforce index(idx_name_age_position)where name > &#39;LiLei&#39; and age = 22 and position = &#39;manager&#39;;
- 覆盖索引优化
- explain select name,age,position from employees where name > &#39;LiLei&#39; and age = 22 and position = &#39;manager&#39;;
- in和or在表数据比较大的情况会走索引,在表记录不多的情况下会选择全表扫描,MySQL8,记录不多也会走索引
- like KK% 一般情况都会走索引
- explain select * from employees where name like &#39;LiLei%&#39; and age = 22 and position = &#39;manager&#39;;
- 索引下推(Index Condition Pushdown,ICP),like用到了索引下推优化。
- MySQL5.6以前,先以LiLei为头,查出所有索引,拿这个索引对应主键逐个回表,找出数据后再对比age和position.
- MySQL5.6以后,先拿到索引判断三个字段是否匹配,找到符合的索引,再回表,减少了回表的次数。
- 针对二级索引有效,如果是主键索引,无效。
- trace工具(追踪工具)
- 开启: set session optimizer_trace=&#34;enabled=on&#34;,end_markers_in_json=on;
- select * from employees where name > &#39;a&#39; order by position;
- SELECT * FROM information_schema.OPTIMIZER_TRACE;
- 关闭:set session optimizer_trace=&#34;enabled=off&#34;;
- 常见SQL深入优化
- 1、MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
- 2、order by满足两种情况会使用Using index。1) order by语句使用索引最左前列。2) 使用where子句与order by子句条件列组合满足索引最左前列。
- 3、尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最左前缀法则。
- 4、如果order by的条件不在索引列上,就会产生Using filesort。
- 5、能用覆盖索引尽量用覆盖索引
- 6、group by与order by很类似,其实质是先排序后分组,遵照索引创建顺序的最左前缀法则。对于group by的优化如果不需要排序的可以加上order by null禁止排序。注意,where高于having,能写在where中的限定条件就不要去having限定了。
- filesort文件排序
- max_length_for_sort_data 系统变量 1024字节,1K
- 单路排序:单条记录字段的总长度小于1K,一次性将所有字段取出进行排序。
- 双路排序: 单条记录字段的总长度大于1K,只将排序字段和主键取出,排序后再回表。
- 索引设计原则
- 代码先行,索引后上
- 联合索引尽量覆盖条件
- 不要在小基数数字段上建立索引
- 长字符串可以采用前缀索引: key index(name(20),age,position),研究表明再长的字符串,前20位基本可以进行排序了。
- where和order by冲突时,优先优化where.
- 基于慢SQL查询优化
- http://note.youdao.com/noteshare?id=c71f1e66b7f91dab989a9d3a7c8ceb8e&sub=0B91DF863FB846AA9A1CDDF431402C7B
- Mysql索引优化实战2
- 分页查询优化
- 根据自增且连续的主键排序的分页查询
- 根据非主键字段排序的分页查询
- Join关联查询优化
- 嵌套循环连接 Nested-Loop Join(NLJ) 算法
- 循环读取驱动表,根据关联条件,取出被驱动表数据,组成结果集
- 基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
- 把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比
- 对于关联sql的优化
- 关联字段加索引
- 小表驱动大表
- in和exsits优化
- where中时小表则in
- from中小表,则exsits
- count(*)查询优化
- 字段有索引
- count(*)≈count(1)>count(字段)>count(主键 id)
- 字段无索引
- count(*)≈count(1)>count(主键 id)>count(字段)
- 常用优化方式
- 查询mysql自己维护的总行数
- show table status
- 将总数维护到Redis里
- 增加数据库计数表
- 阿里巴巴Mysql规范解读
- 数值类型
- 如果整形数据没有负数,如ID号,建议指定为UNSIGNED无符号类型,容量可以扩大一倍。
- 建议使用TINYINT代替ENUM、BITENUM、SET。
- 避免使用整数的显示宽度(参看文档最后),也就是说,不要用INT(10)类似的方法指定字段显示宽度,直接用INT
- DECIMAL最适合保存准确度要求高,而且用于计算的数据,比如价格。但是在使用DECIMAL类型的时候,注意长度设置
- 建议使用整形类型来运算和存储实数,方法是,实数乘以相应的倍数后再操作
- 整数通常是最佳的数据类型,因为它速度快,并且能使用AUTO_INCREMENT
- 日期和时间
- MySQL能存储的最小时间粒度为秒
- 建议用DATE数据类型来保存日期。MySQL中默认的日期格式是yyyy-mm-dd
- 用MySQL的内建类型DATE、TIME、DATETIME来存储时间,而不是使用字符串
- 当数据格式为TIMESTAMP和DATETIME时,可以用CURRENT_TIMESTAMP作为默认(MySQL5.6以后),MySQL会自动返回记录插入的确切时间
- TIMESTAMP是UTC时间戳,与时区相关
- DATETIME的存储格式是一个YYYYMMDD HH:MM:SS的整数,与时区无关,你存了什么,读出来就是什么
- 除非有特殊需求,一般的公司建议使用TIMESTAMP,它比DATETIME更节约空间,但是像阿里这样的公司一般会用DATETIME,因为不用考虑TIMESTAMP将来的时间上限问题
- 有时人们把Unix的时间戳保存为整数值,但是这通常没有任何好处,这种格式处理起来不太方便,我们并不推荐它
- 字符串
- 字符串的长度相差较大用VARCHAR;字符串短,且所有值都接近一个长度用CHAR
- CHAR和VARCHAR适用于包括人名、邮政编码、电话号码和不超过255个字符长度的任意字母数字组合。那些要用来计算的数字不要用VARCHAR类型保存,因为可能会导致一些与计算相关的问题。换句话说,可能影响到计算的准确性和完整性
- 尽量少用BLOB和TEXT,如果实在要用可以考虑将BLOB和TEXT字段单独存一张表,用id关联
- BLOB系列存储二进制字符串,与字符集无关。TEXT系列存储非二进制字符串,与字符集相关
- BLOB和TEXT都不能有默认值
- 深入理解Mysql事务隔离级别与锁机制
- 事务及其ACID属性
- 原子性(Atomicity) :事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性。
- 隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
- 并发事务处理带来的问题
- 更新丢失(Lost Update)或脏写
- 脏读(Dirty Reads)
- 不可重复读(Non-Repeatable Reads)
- 事务A内部的相同查询语句在不同时刻读出的结果不一致,不符合隔离性
- 幻读(Phantom Reads)
- 事务隔离级别
- 读未提交(Read uncommitted)
- 读已提交(Read committed)
- 可重复读(Repeatable read)
- 可串行化(Serializable)
- 锁分类
- 从性能上
- 操作类型上
- 数据操作粒度上
- 间隙锁
- 临键锁
- 死锁
- 锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
- 尽可能低级别事务隔离
- 深入理解MVCC与BufferPool缓存机制
- MVCC多版本并发控制
- undo日志版本链
- 一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志,并且用两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链
- 一致性视图read view机制
- Innodb引擎SQL执行的BufferPool缓存机制
- 在内存中缓存起来,可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件
- InnoDB引擎底层存储和缓存原理以及MySQL8新特性
- InnoDB存储引擎设计了4种不同类型的行格式
- Compact
- 记录的额外信息
- 变长字段长度列表
- NULL值列表
- 每个允许为null字段,1代表为null
- 记录头信息:5字节,40位
- 预留位1 1 没有使用
- 预留位2 1 没有使用
- delete_mask 1 标记该记录是否被删除
- min_rec_mask 1 B+树的每层非叶子节点中的最小记录都会添加该标记
- n_owned 4 表示当前记录拥有的记录数
- heap_no 13 表示当前记录在页的位置信息
- record_type 3 表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录
- next_record 16 表示下一条记录的相对位置
- 隐藏列
- DB_ROW_ID(row_id):非必须,6字节,表示行ID,唯一标识一条记录
- 先使用用户定义的主键,然后使用唯一索引,最后是自增的row_id
- DB_TRX_ID(trx_id):必须,6字节,表示事务ID
- DB_ROLL_PTR(roll_ptr):必须,7字节,表示回滚指针
- 记录的真实信息
- Redundant
- Redundant行格式是MySQL5.0之前用的一种行格式,不予深究。
- Dynamic
- Compressed
- 处理行溢出数据时,会采用压缩算法对页面进行压缩,以节省空间。
- 索引页格式
- File Header 文件头部 38字节 页的一些通用信息
- Page Header 页面头部 56字节 数据页专有的一些信息
- Infimum + Supremum 最小记录和最大记录 26字节 两个虚拟的行记录
- User Records 用户记录 大小不确定 实际存储的行记录内容
- Free Space 空闲空间 大小不确定 页中尚未使用的空间
- Page Directory 页面目录 大小不确定 页中的某些记录的相对位置
- File Trailer 文件尾部 8字节 校验页是否完整
- InnoDB的体系结构
- 内存结构
- Buffer Pool
- 缓冲池,128M,建议给物理内存的60%
- 控制块
- 内存碎片
- 缓存页
- free链表管理
- flush链表管理
- LRU链表管理
- Change Buffer
- Log Buffer
- 磁盘结构
- 系统表空间
- 数据字典
- 双写缓冲区
- Change Buffer
- Undo日志
- 独立表空间
- 页节点段:逻辑上的
- 组
- 256个区
- 区:物理上连续,减少随机I/O
- 64个页
- 页
- 16K,若干记录
- 非页节点段
- 回滚段
- 通用表空间
- 临时表空间
- Undo表空间
- Redo日志
- redo日志:重做日志
- 作用
- 格式
- type:该条redo日志的类型,redo日志设计大约有53种不同的类型日志
- space ID:表空间ID
- page number:页号
- data:该条redo日志的具体内
- redo日志的写入过程
- redo log block和日志缓冲区
- redo日志刷盘时机
- redo日志文件组
- redo日志文件格式
- undo日志:回滚日志
- 事务回滚的需求
- 事务id
- trx_id
- undo日志的格式
- INSERT操作对应的undo日志
- DELETE操作对应的undo日志
- UPDATE操作对应的undo日志
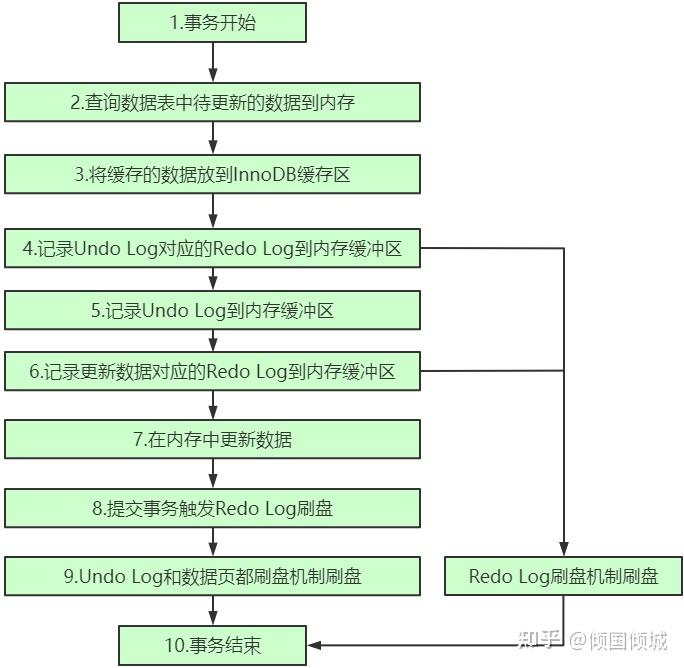
- 事务的流程
- MySQL8新增特性
- 用户的创建与授权
- 密码管理
- 1、password_history 修改密码不允许与最近几次使用或的密码重复,默认是0,即不限制;2、password_reuse_interval 修改密码不允许与最近多少天的使用过的密码重复,默认是0,即不限制;3、password_require_current 修改密码是否需要提供当前的登录密码,默认是OFF,即不需要;如果需要,则设置成ON。
 |
|


 发表于 2023-1-18 09:37:39
发表于 2023-1-18 09:37:39