设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
数据库
›
mysql(一)爪哇笔记
返回列表
发帖
查看:
161
|
回复:
1
mysql(一)爪哇笔记
[复制链接]
暖暖海风
暖暖海风
当前离线
积分
28
4
主题
13
帖子
28
积分
新手上路
新手上路, 积分 28, 距离下一级还需 22 积分
新手上路, 积分 28, 距离下一级还需 22 积分
积分
28
发消息
发表于 2023-1-17 19:33:05
|
显示全部楼层
|
阅读模式
事务
事物就是一种原子性的SQL查询,或者说是一个独立的工作单元。
ACID
原子性(atomicity)
:一个事物必须被视为一个并不不可分割的最小工作单元。整个事物中所有的操作要么是全部提交成功,要么是全部失败回滚。对于一个事物来说,不可能只执行其中的一部分操作,这就是事务的原子性。
一致性(consistency)
:数据库总是从一个一致性的状态转换到另外一个一致性的状态。
隔离性(isolation)
:一个事务所做的修改在最终提交之前,对其他事务是不可见的。
持久性(durability)
:一旦事务提交,所做的修改就会永久保存到数据库中。这里的持久性是个有点模糊的概念,实际上持久性也分很多不同的级别。
事务并发中所出现的隔离的问题:
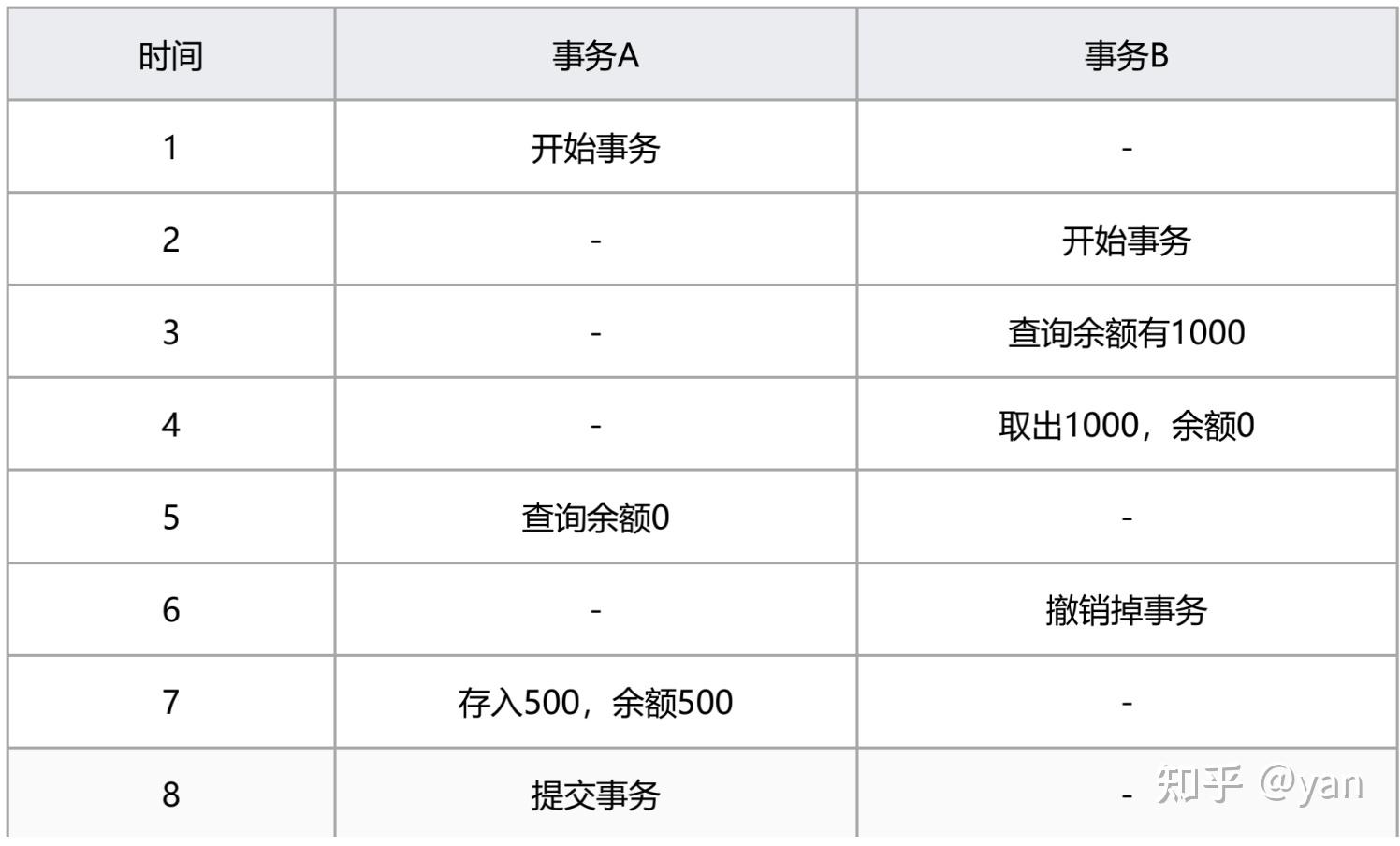
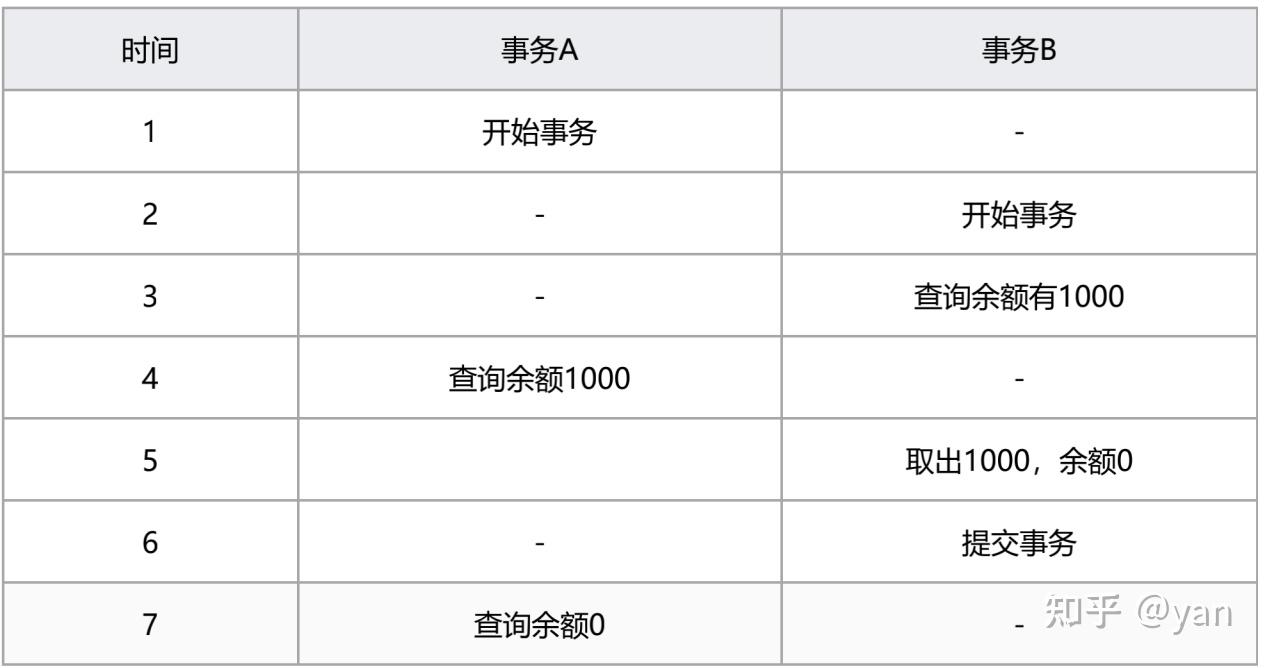
脏读/未提交读(read uncommitted)
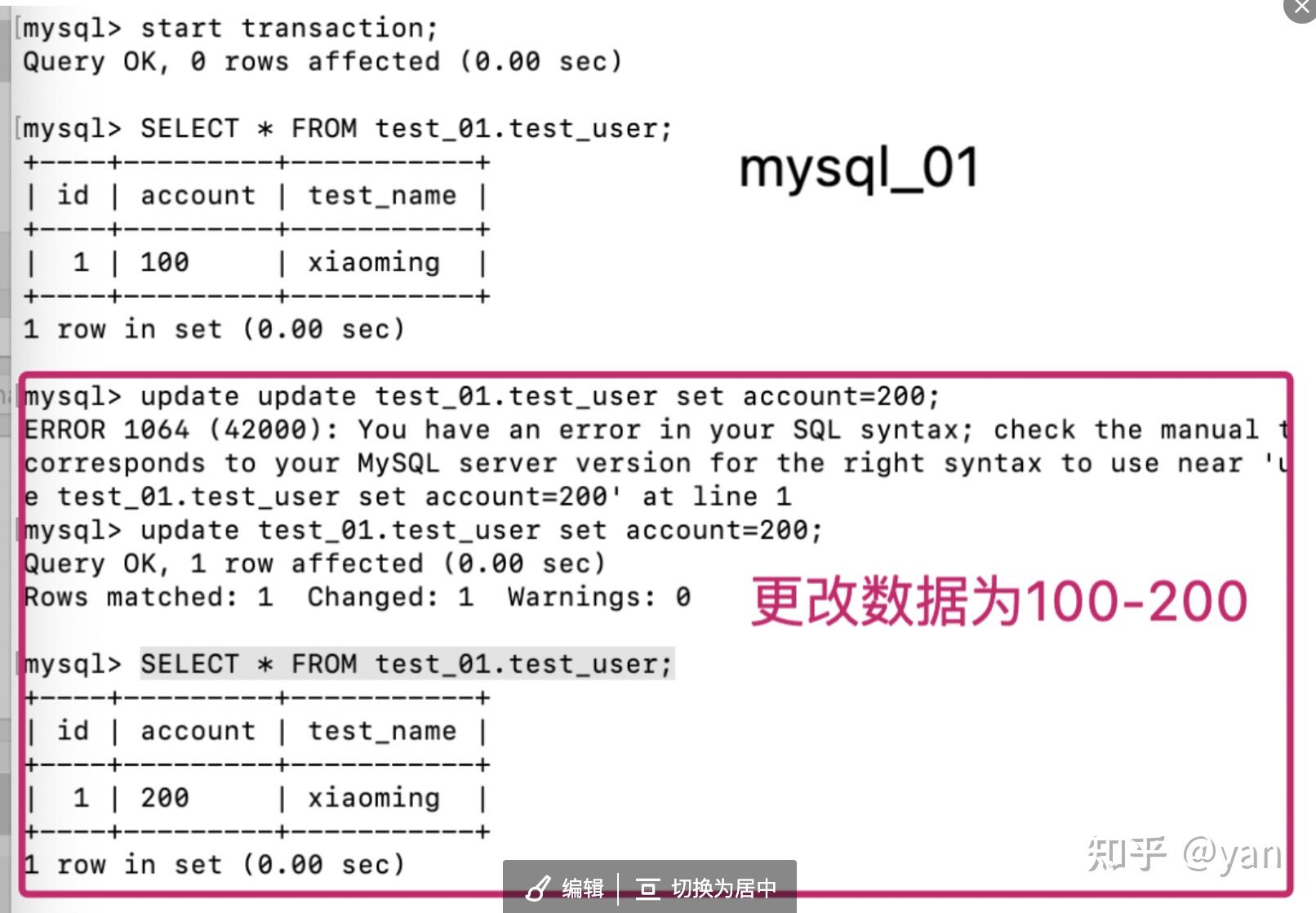
:在read uncommitted级别里,即使没有提交对其他书屋也都是可见的。事物可以读取未提交的数据。(图1)
图1(read uncommitted)
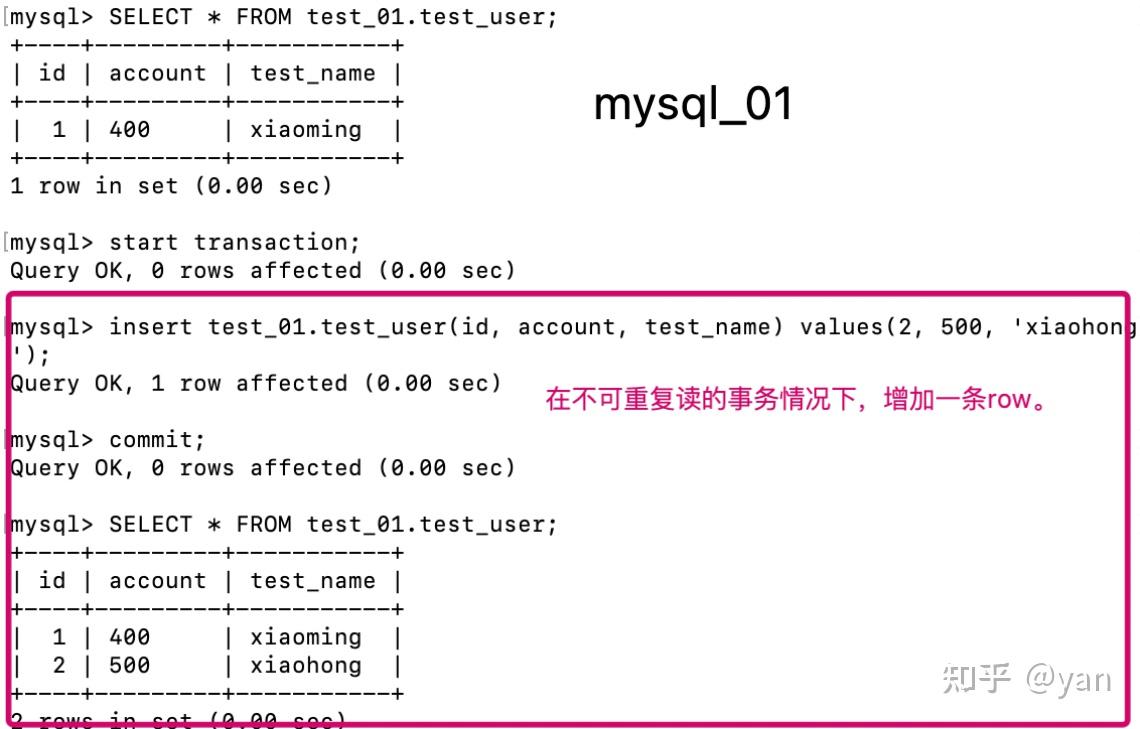
图二(mysql_01)
图三(mysql_01)
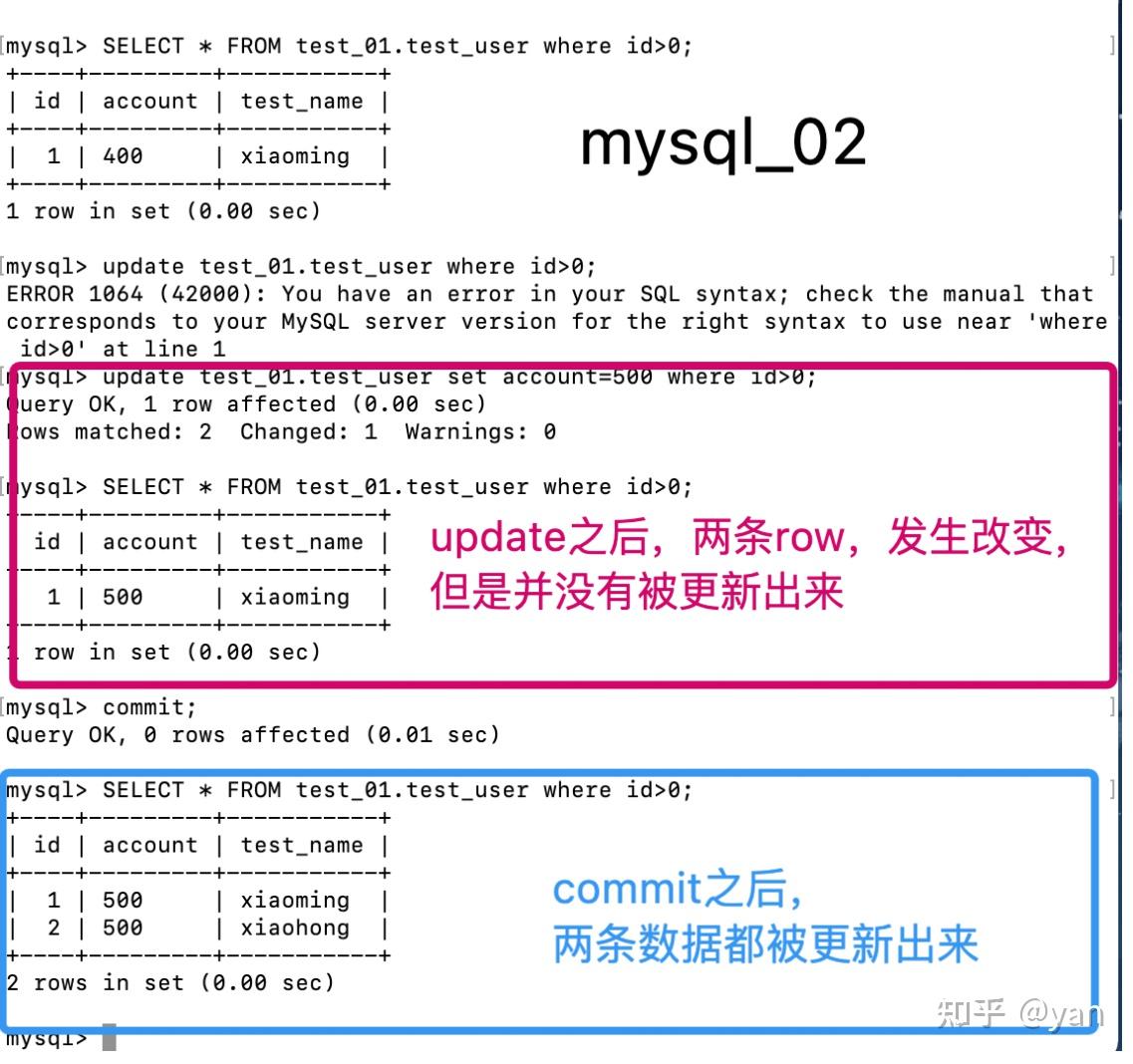
图四(mysql_02)
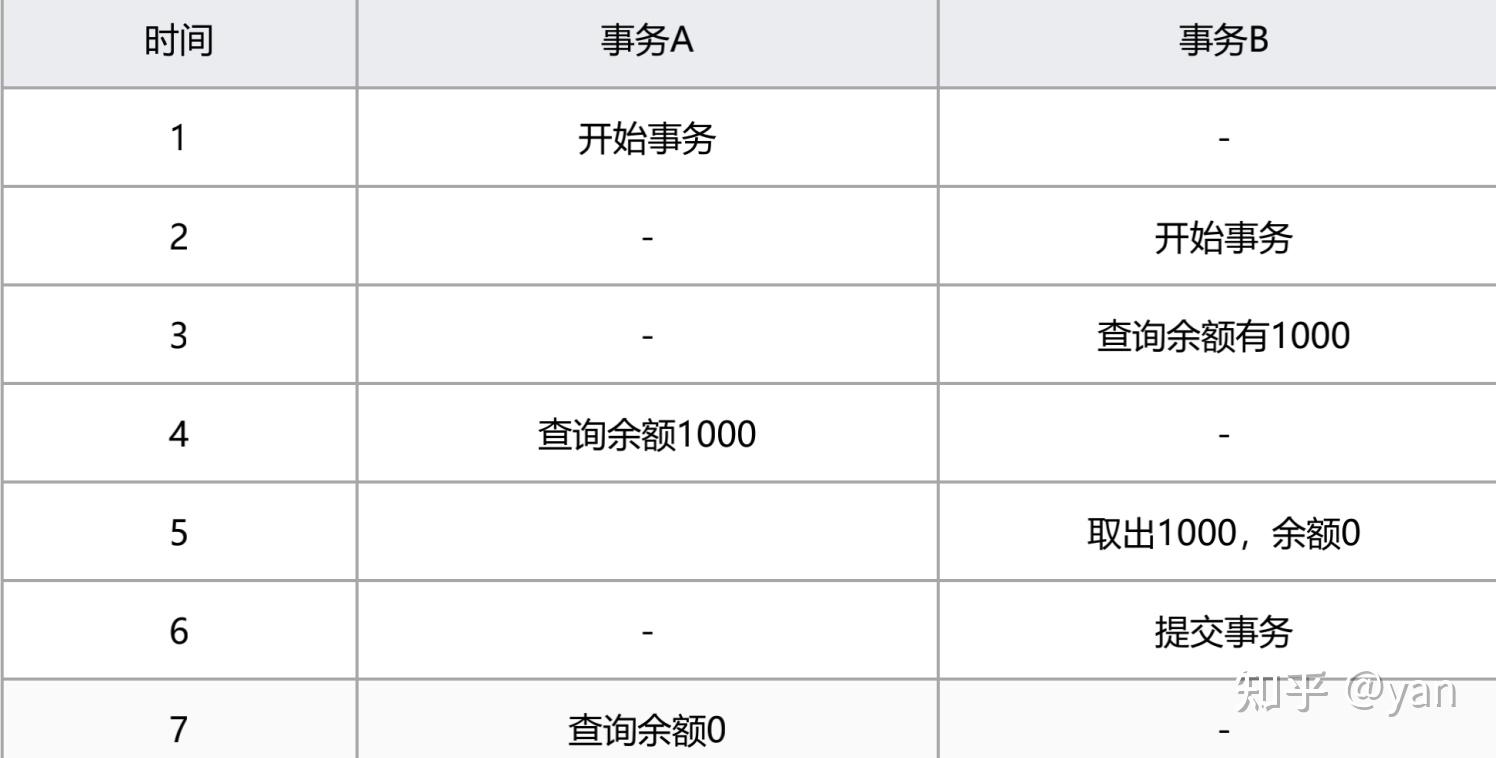
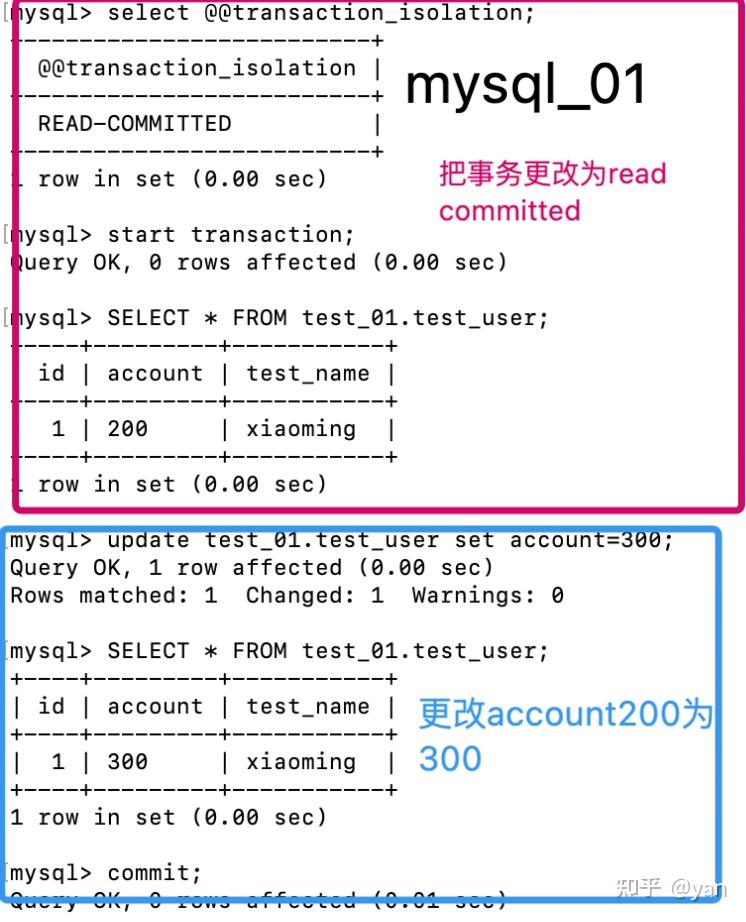
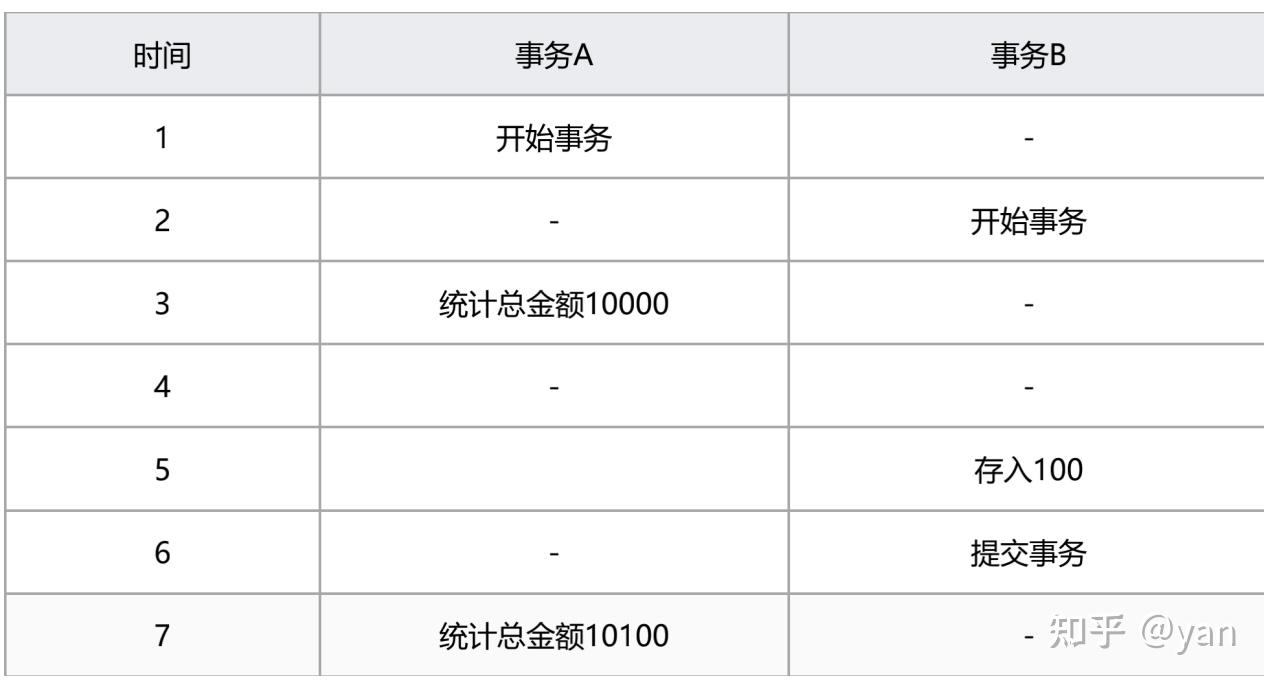
不可重复读/提交读(read committed)
:大多数数据库系统默认的隔离级别是read committed(但MySql不是),一个事务从开始到提交之前,所做的任何修改对其他事物都是不可见的。
图四(read committed)
图五(mysql_01)
图六(mysql_02)
可重复读(repeatable read)
:解决了脏读的问题。该级别保证了在同一事务中多次读取同样的记录的结果是一致的。但无法解决幻读(Phantom read)的问题,所谓幻读,指的是当某个事务在读取某个范围内的记录时,会产生幻行。InnoDB和XtraDB存储引擎通过多版本并发控制MVCC解决了幻读的问题。
图七(mysql_01)
图八(mysql_02)
幻读(phantom read):
两个事务正在并发的执⾏,事务A第⼀次统计和第⼆统计的结果不⼀样,是因为 事务B新增了⼀条数 据,和不可重复读⼀样,都是读取了另外⼀个事务的数据, 不同的是不可重复读查询的是同⼀条数据, ⽽幻读则是针对批量的数据,或者说不可重复读是A读取了B的更新数据,幻读是A读取了B的新增数 据。
图九(幻读)
图十(mysql_01)
图十一(mysql_02)
串行化(serializable)
:serializable是最高的隔离级别。他通过强制事物串行执行,避免了幻读的问题。serializable会在读取的每一行数据上都会加锁,所以可能导致大量的超时和锁争用的问题。
隔离级别
read uncommitted
read committed
phantom read
读未提交
可能
可能
可能
读提交
不可能
可能
可能
可重复读
不可能
不可能
可能
串行化
不可能
不可能
不可能
索引
索引的概念:
一个非常恰当的比喻就是书的征文和书的目录,为了快速查找内容,通过对内容建立索引也就是目录。索引是一个文件,需要占用物理空间。
索引是按照特定的数据结构把数据表中的数据放在索引文件中,以便快速查找。
索引存在于磁盘中,会占据物理空间。
索引的类型:
fulltext
hash:
hash索引可以一次定位,效率极高。但是只能在“=” 和“in”的情况下保持高效,对于范围查询,排序及技术组合索引仍然效率不高。
btree
: betree索引是一种将索引值按一定的算法,存入一个树形的数据结构中,每次都是从树的入口root开始,依次遍历node,获取leaf,这是mysql里默认和最常用的索引类型。
索引的种类:
主键索引
:mysql中主键必须唯一且不能为空值,因此在主键上的索引也是唯一索引。一个表上的唯一索引可能有多个,但是主键只有一个。
唯一索引
:唯一索引必须唯一,且唯一索引中可能有空值出现。
普通索引
组合索引
:index(a,b,c)
存储引擎中索引的实现:
在mysql中,索引是在存储引擎中实现的。
不同的存储引擎可能支持不同的索引类型。
不同的存储引擎可能对同一种索引类型有不同的实现方式。
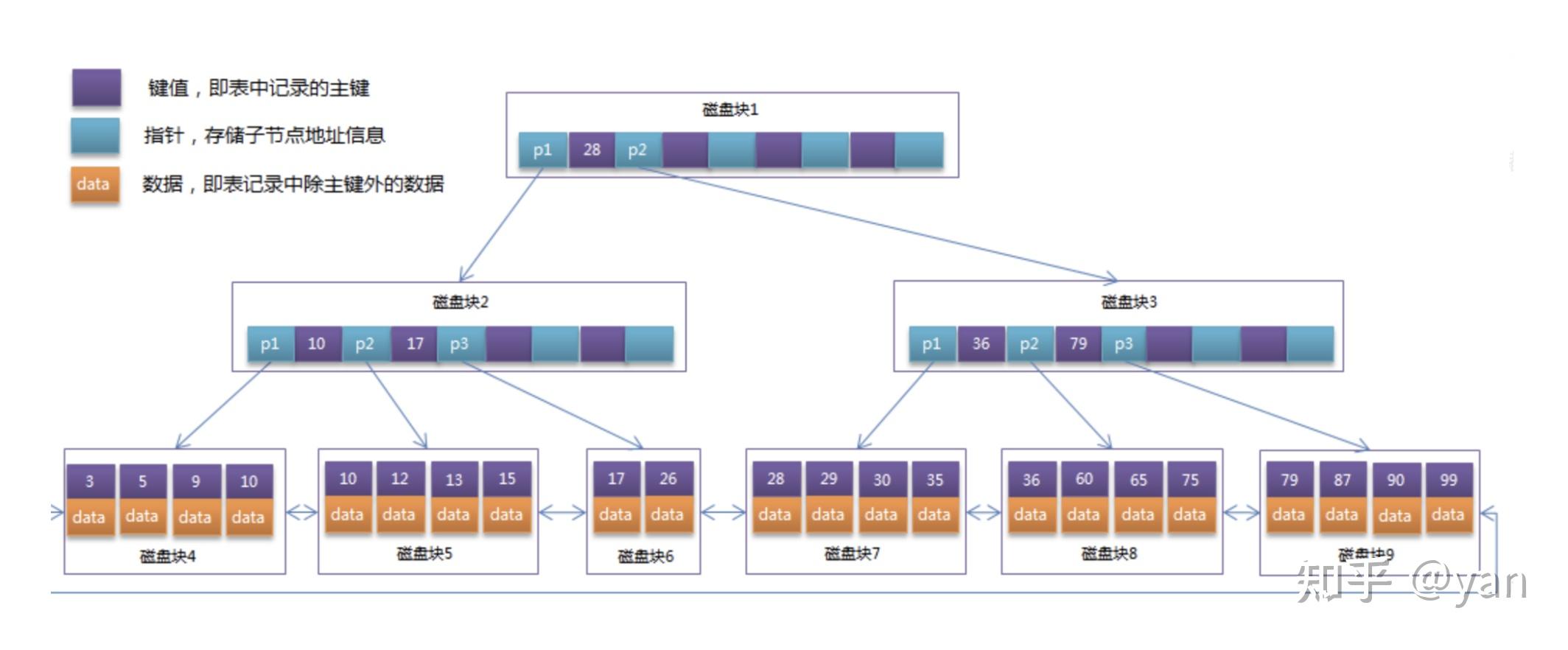
InnoDB存储引擎:(图12)
图12
特点:
非叶子结点,不保存真实数据;有切只有叶子结点存数据。
叶子节点的数据是有序的,双向链表。
数据查询泗洪根磁盘通过二分法向下查找数据。
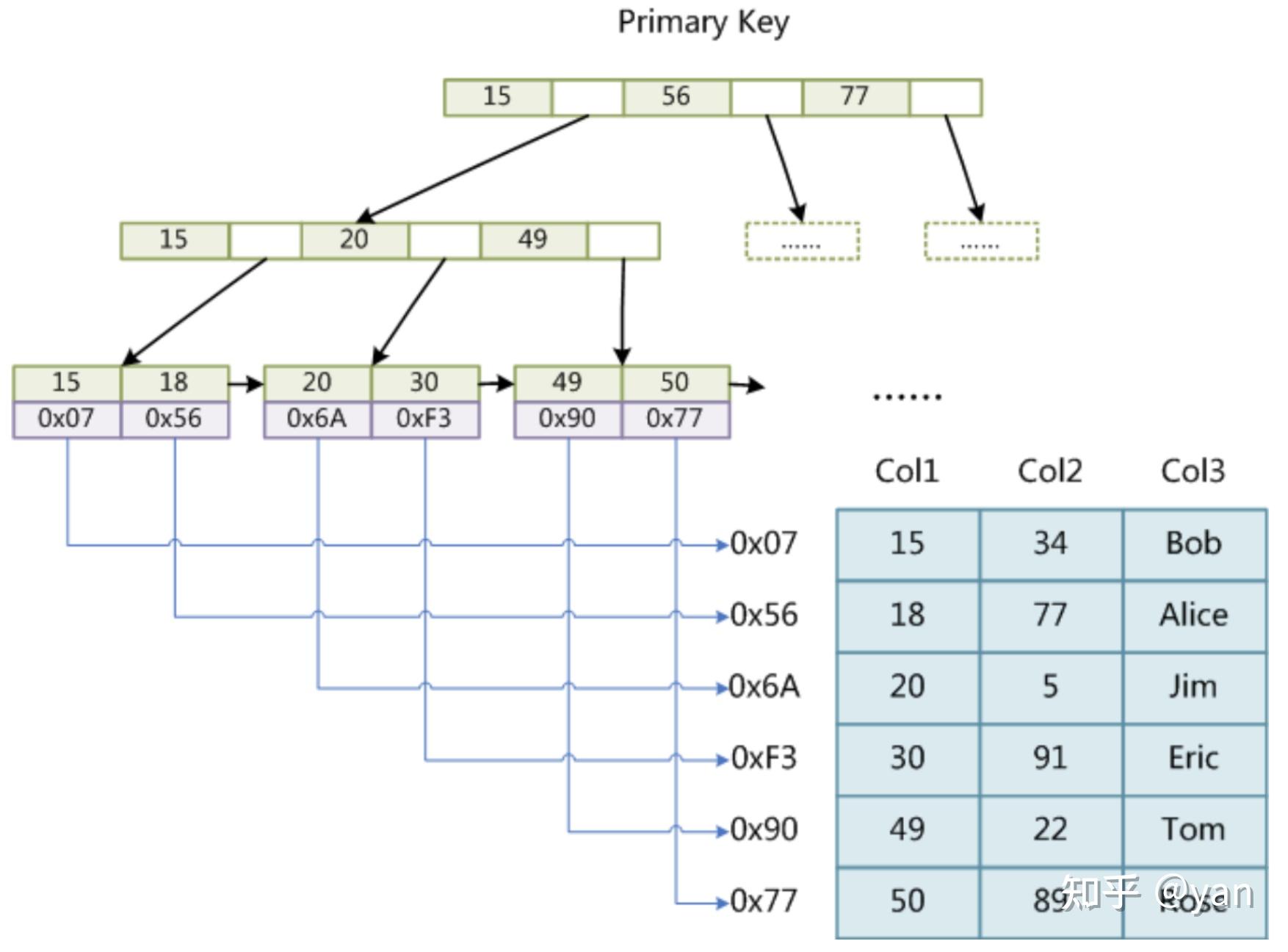
B+索引类型:(根据图13来解释)
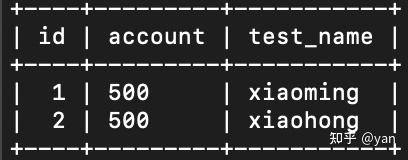
聚簇索引:也就是主键索引,会根据主键来查询,只用查询一次。id是主键,也就是磁盘块1,然后通过id,查找到最后磁盘块4,account和test_name的数据情况。
非聚簇索引:查询两次,通过account来查询,来找到主键,再返回到磁盘块1来找出其他数据。
图13
MYISAM存储引擎:(图14)
图14
存储引擎是hash,利用主键做二分法查询,但数据不是挂在叶子结点。而是hash到一个物理空间。通过物理地址来找寻数据。
慢sql
为什么要对慢sql进行治理:
从数据库角度看:每条sql的执行都需要占用I/O资源,sql执行时间的快慢,决定了资源被占用的时间的长短。
从应用的角度看:sql执行时间长,意味着用户体验差。
mysql执行原理:
解析:词法解析 ->语法解析 -> 逻辑计划 -> 查询优化 -> 物理执行
执行:检查用户/表权限 ->表上加共享读锁 -> 取数据到query cache->取消共享读锁
慢sql问题操作层面:
分析整体实例情况。
定位到sql之后,用expain分析具体sql执行情况。
sql调优(主要就是围绕索引来做)
不使用子查询
避免函数索引:因为mysql不像orcal那么支持函数索引。
用 in 来代替 or:因为in和btree习性比较相合,能较快查找
like双百分号无法使用到索引:
select * from t where name like '%de%';
select * from t where name like 'de%';
读取适当的记录LIMIT M,N:limit跨度比较大可能设计跨盘操作,影响性能。
分组统计禁止排序:如果有需求在内存里面排,在java代码里面。
禁止不必要的order by排序
正确使用组合索引:向左原则, index(age,name,addr). a [ a, b [ a, b, c]]
如果还有问题应该检查表的数据量是否合理
分析musql实例的机器:磁盘,io,内存等
分库分表
关系型数据库本身比较容易成为系统瓶颈,
单机存储容量、连接数、处理能力都有限。当表单的数据量达到2000万或100g以后。
此时就该考虑对其进行切分,切分的目的就在于减少数据库的负担,缩短查询时间。
数据库分布式核心内容无非就是数据切分,已经切分后对数据的定位、整合。数据切分就是将数据分散存储到多个数据库中,使得单一数据库中的数据量变小,通过扩充主机的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目的。
数据切分根据其切分类型,可以分为两种方式:垂直(纵向)切分和水平(横向)切分
垂直(纵向)切分
垂直切分常见有垂直分库和垂直分表两种。
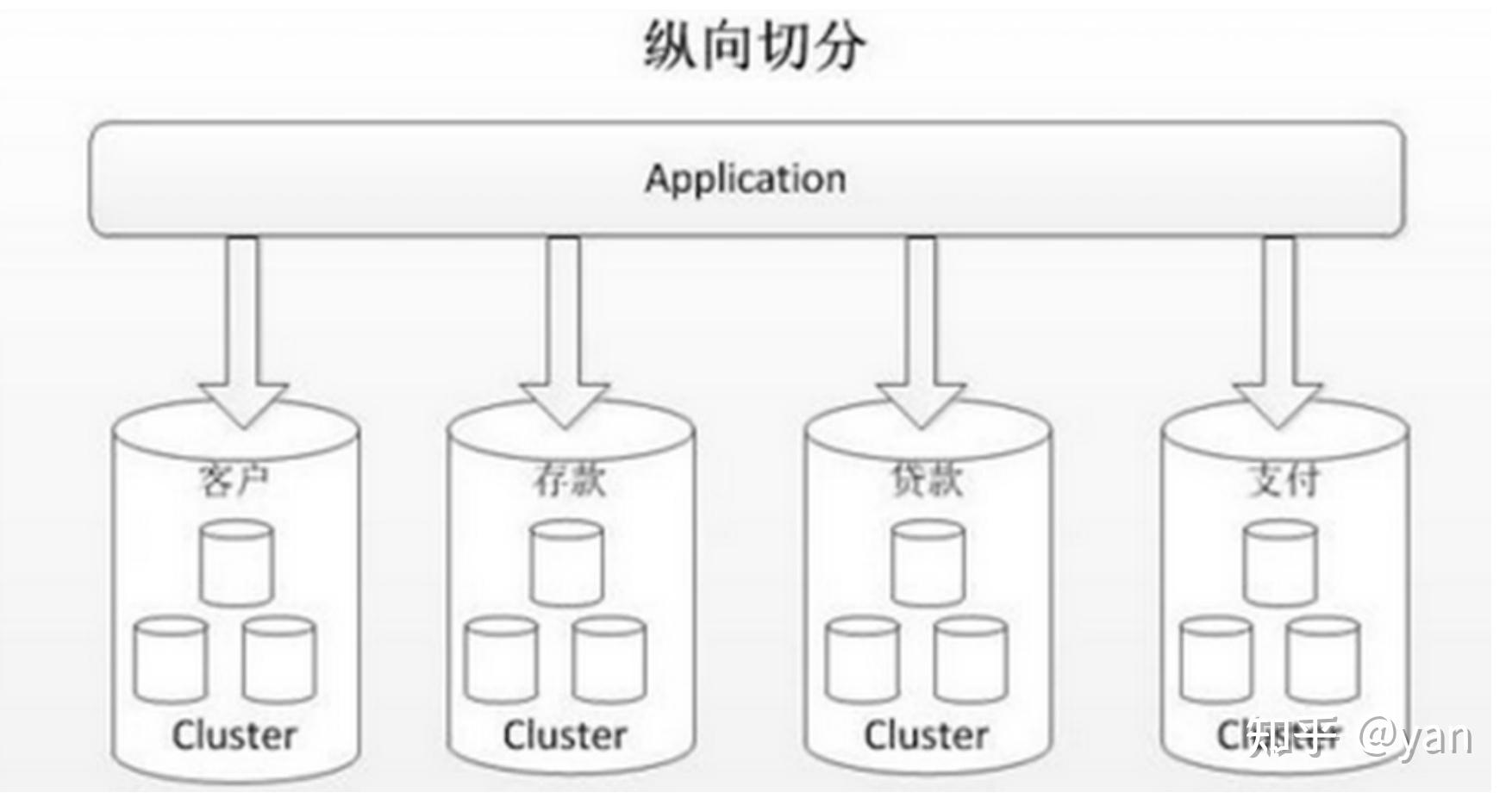
垂直分库
垂直分库就是根据事物的耦合性,将关联度低的表存储在不同的数据库。(图15)
图15
垂直分表
垂直分表是基于数据库中的“列”进行,某个表字段较多,可以新建一张扩建表。将不常用或字段长度较大的字段长度拆分出去到扩展表中。另外数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
垂直切分的优点:
解决业务系统层面的耦合,业务清晰,于微服务的治理类似。也能对不同业务的数据进行分级管理、维护、监控、扩展等。
高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈。
垂直切分的缺点:
部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度。
分布式事务处理复杂
依然存在单表数据量过大的问题(需要水平切分)
水平切分
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要水平切分了。水平切分分为库内分表和仓库分表。是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得耽搁表的数据量变小,达到分布式效果。
水平切分的优点:
不不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
应用端改造较小,不需要拆分业务模块
水平切分的缺点:
跨分片的事务一致性难以保证跨库的join关联查询性能较差
数据多次扩展难度和维护量极大
分片规则:
根据数值范围:
按照时间区间和id区间来切分。
优点:
当表大小可控
天然便于水平扩展,后期如果相对整个分片集群扩容时,只需添加节点即可,无需对其他分片的数据进行迁移
使用分片阶段进行范围查找时,连续分⽚可快速定位分⽚进⾏快速查询,有效避免跨分⽚查询的问题
缺点:
热点数据成为性能瓶颈。连续分⽚可能存在数据热点,例如按时间字段分⽚,有些分⽚存储最近时 间段内的数据,可能会被频繁的读写,⽽有些分⽚存储的历史数据,则很少被查询。
分库分表的问题:
事物一致性问题
跨界点关联查询join问题:
切分之前,系统中很多列表和详情页所需的数据可以通过sql join来完成。但是切分之后,数据可能分布在不同的节点上,此时join带来的问题就比较麻烦。下面是解决方案:
全局表:
全局表,也可看作是“数据字典表”,就是系统中所有模块都可能以来的一些表,为了避免跨库join查询,可以将这类表在每个数据库中都保留一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。
字段冗余
:一种典型的反泛式设计,利用空间换时间,为了性能而避免join查询。例如:订单表保存userid时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询“买家user表”了。
数据组装
:在系统层面,分两次查询。第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后获得的数据进行字段拼接。
跨界点分页、排序、函数问题
全局主键比重问题:
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使⽤的⾃增⻓将⽆⽤武之 地,某个分区数据库⾃⽣成的ID⽆法保证全局唯⼀。因此需要单独设计全局主键,以避免跨库主键 重复问题。有⼀些常⻅的主键⽣成策略:
UUID
(不用)
结合数据库维护主键ID表
:这⼀⽅案的整体思想是:建⽴2个以上的全局ID⽣成的服务器,每个服务器上只部署⼀个数据 库,每个库有⼀张sequence表⽤于记录当前全局ID。表中ID增⻓的步⻓是库的数量, 起始值 依次错开,这样能将ID的⽣成散列到各个数据库上。第一台机器生成的id是奇数(1,3,5...),第二台机器生成的id是偶数(2,4,6...)(很少)
Snowflake分布式⾃增ID算法
:Twitter的snowflake算法解决了分布式系统⽣成全局ID的需求,⽣成64位的Long型数字。(经常)
数据迁移、扩容问题
什么时候考虑切分:
能不切分就不并且分。并不是所有表都需要进行切分,主要还是看数据的增长速度。
数据量过大、增长过快,正常运维影响业务访问。
随着业务发展,需要对某些字段垂直拆分。
安全性和可用性
回复
使用道具
举报
旋叶弄舞
旋叶弄舞
当前离线
积分
32
4
主题
15
帖子
32
积分
新手上路
新手上路, 积分 32, 距离下一级还需 18 积分
新手上路, 积分 32, 距离下一级还需 18 积分
积分
32
发消息
发表于 2025-6-14 18:12:17
|
显示全部楼层
前排,哇咔咔
回复
使用道具
举报
梓陌繁槿
梓陌繁槿
当前离线
积分
21
1
主题
11
帖子
21
积分
新手上路
新手上路, 积分 21, 距离下一级还需 29 积分
新手上路, 积分 21, 距离下一级还需 29 积分
积分
21
发消息
发表于 2025-12-15 05:43:25
|
显示全部楼层
佩服佩服!
回复
使用道具
举报
如唐诗一样的生活
如唐诗一样的生活
当前离线
积分
26
2
主题
16
帖子
26
积分
新手上路
新手上路, 积分 26, 距离下一级还需 24 积分
新手上路, 积分 26, 距离下一级还需 24 积分
积分
26
发消息
发表于 2025-12-15 19:57:45
|
显示全部楼层
纯粹路过,没任何兴趣,仅仅是看在老用户份上回复一下
回复
使用道具
举报
子清
子清
当前离线
积分
33
5
主题
16
帖子
33
积分
新手上路
新手上路, 积分 33, 距离下一级还需 17 积分
新手上路, 积分 33, 距离下一级还需 17 积分
积分
33
发消息
发表于 2025-12-15 20:47:08
|
显示全部楼层
没人回帖。。。我来个吧
回复
使用道具
举报
长江之水
长江之水
当前离线
积分
32
3
主题
16
帖子
32
积分
新手上路
新手上路, 积分 32, 距离下一级还需 18 积分
新手上路, 积分 32, 距离下一级还需 18 积分
积分
32
发消息
发表于 2026-3-19 14:28:19
|
显示全部楼层
前排支持下
回复
使用道具
举报
威猛之犊
威猛之犊
当前离线
积分
26
5
主题
11
帖子
26
积分
新手上路
新手上路, 积分 26, 距离下一级还需 24 积分
新手上路, 积分 26, 距离下一级还需 24 积分
积分
26
发消息
发表于
5 小时前
|
显示全部楼层
为保住菊花,这个一定得回复!
回复
使用道具
举报
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
快速回复
返回顶部
返回列表


 发表于 2023-1-17 19:33:05
发表于 2023-1-17 19:33:05