|
|
大家好,我是老坛。
Elasticsearch是一个分布式的RESTful 风格的搜索和数据分析引擎,它使用方便,查询速度快,因此也被越来越多的开发人员使用。
在Java项目中,使用ES的场景也十分常见。除了作为某些特定资源的存储之外也可以作为像ELK这样的日志收集系统里的存储引擎。总之,对于非关系型而查找需求较多的场景,ES的表现还是非常不错的。
那今天老坛就带大家看一看如何使用Java API来操作ES。
注:本篇文章只对应ES版本在7.x及其以下的情况,对于ES版本在8.x的场景请阅读我的另一篇文章:
1.准备工作
在真正使用es api之前,还有一些准备工作要去做,分别是引入依赖和写好配置文件
1.1引入依赖
对于7.x及其以下的版本,spring data这边是支持的,所以可以根据自己ES的具体版本来引入匹配版本的spring data starter,具体如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>1.2配置文件
接下来就是去写配置文件了。我们要连接ES所要用到的ip和port,用户名和密码这些信息建议大家都写在自己的yml里,方便维护:
es:
address: 127.0.0.1
port: 9200
scheme: http
username: admin
password: admin接下来我们要写一个config文件来使用这些配置,具体代码如下:
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Value(&#34;${es.address}&#34;)
String address;
@Value(&#34;${es.port}&#34;)
Integer port;
@Value(&#34;${es.scheme}&#34;)
String scheme;
@Value(&#34;${es.username}&#34;)
String username;
@Value(&#34;${es.password}&#34;)
String password;
@Bean
public RestHighLevelClient esRestClient(){
RestClientBuilder builder = null;
builder = RestClient.builder(new HttpHost(address, port, scheme));
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}这个是无用户名和密码版本的配置文件,大家可以直接拿走使用。
下面贴一下需要配置用户名和密码的config文件:
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Value(&#34;${es.address}&#34;)
String address;
@Value(&#34;${es.port}&#34;)
Integer port;
@Value(&#34;${es.scheme}&#34;)
String scheme;
@Value(&#34;${es.username}&#34;)
String username;
@Value(&#34;${es.password}&#34;)
String password;
@Bean
public RestHighLevelClient esRestClientWithCred(){
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(address, port, scheme))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) {
return httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
RestHighLevelClient esClient = new RestHighLevelClient(restClientBuilder);
return esClient;
}
}按需来取即可。
2. 简单操作
也就是最基本的CRUD了,但是这部分介绍的都是只针对一条数据的CRUD操作,都是通过id来去进行的,比较简单。而操作这些所使用到的类也比较有规律,这里我给大家画一张图方便理解:
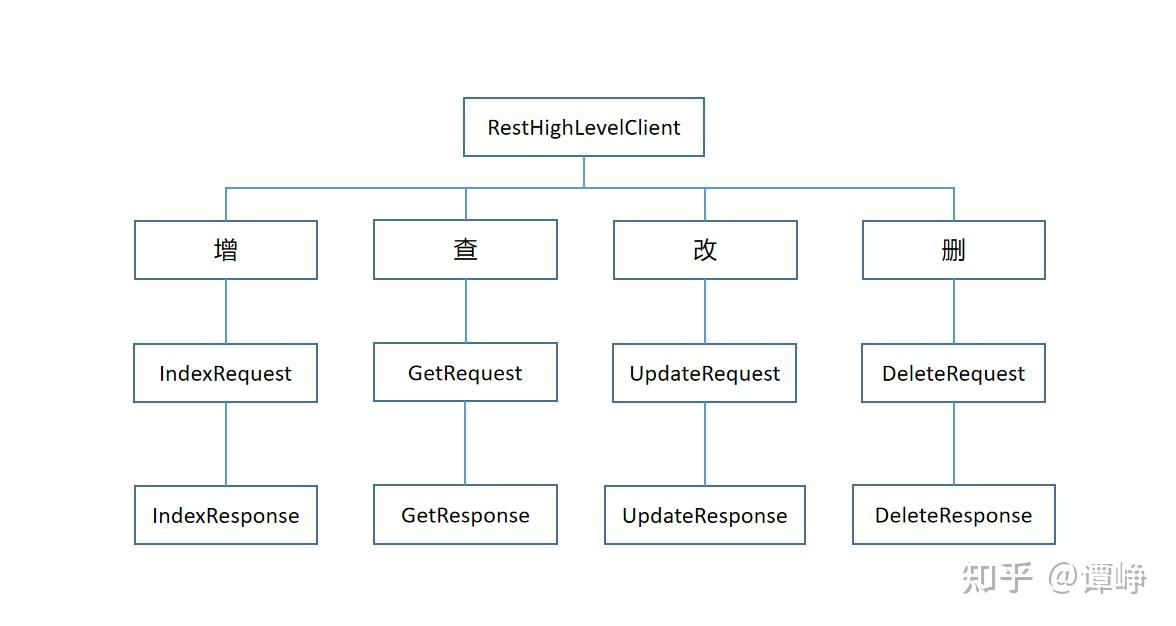
RestHighLevelClient是我们所有操作的核心,它也是在我们config里面写好的,等着被注入就可以了。对于每一种操作都有其相应的request和response,我们在request里面填充需要做的操作,用response接收结果。下面举例来介绍这些操作。
先介绍一下我用到的实体对象:
@Data
public class TextBook {
String bookName;
String author;
Integer num;
}对应的索引数据为:
{
&#34;_index&#34;: &#34;textbook&#34;,
&#34;_id&#34;: &#34;kIwXeYQB8iTYJNkI986Y&#34;,
&#34;_source&#34;: {
&#34;bookName&#34;: &#34;This is a test doc&#34;,
&#34;author&#34;: &#34;老坛&#34;,
&#34;num&#34;: 20
}
}2.1 插入数据
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESTest {
@Resource
RestHighLevelClient restHighLevelClient;
String index = &#34;index&#34;;
@Test
public void insertSingle(String id) throws IOException {
IndexRequest request = new IndexRequest(index);
request.id(id);
// 要插入的实体
TextBook textBook = new TextBook();
textBook.setBookName(&#34;老坛聊开发&#34;);
textBook.setAuthor(&#34;老坛&#34;);
textBook.setNum(20);
request.source(JSON.toJSONString(textBook), XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
log.info(&#34;返回状态:&#34; + indexResponse.status().getStatus());
}
}我们需要将RestHighLevelClient注入进来,然后就可以操作了。
2.2 查询数据
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESTest {
@Resource
RestHighLevelClient restHighLevelClient;
String index = &#34;index&#34;;
@Test
public void grepSingle(String id) throws IOException {
GetRequest getRequest = new GetRequest(index);
getRequest.id(id);
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
String json = getResponse.getSourceAsString();
TextBook textBook = JSONObject.parseObject(json, TextBook.class);
log.info(&#34;返回结果为:&#34; + JSON.toJSONString(textBook));
}
}这里是使用id查询单条数据,相当于sql的getByPrimaryKey。
2.3 修改数据
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESTest {
@Resource
RestHighLevelClient restHighLevelClient;
String index = &#34;index&#34;;
@Test
public void updateSingle(String id) throws IOException {
GetRequest getRequest = new GetRequest(index);
getRequest.id(id);
// 先查看是否包含该数据,以防报错
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if(exists) {
UpdateRequest updateRequest = new UpdateRequest(index, id);
TextBook textBook = new TextBook();
// 要更新的实体
textBook.setBookName(&#34;老坛聊开发&#34;);
textBook.setAuthor(&#34;老坛&#34;);
updateRequest.doc(JSON.toJSONString(textBook), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info(&#34;返回状态:&#34; + updateResponse.status().getStatus());
}
}
}这里先用exist方法查询了一下该条数据是否存在,存在的话再去修改数据。
2.4 删除数据
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESTest {
@Resource
RestHighLevelClient restHighLevelClient;
String index = &#34;index&#34;;
@Test
public void deleteSingle(String id) throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(index);
deleteRequest.id(id);
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info(&#34;返回状态:&#34; + deleteResponse.status().getStatus());
}
}3 复杂查询
3.1 整体介绍
下面介绍复杂查询,也是我们比较常用的ES查询方式,这里如果大家有一定的ES语法基础会更方便的理解下面的内容。想了解ES基础语法可以去看我的这篇文章:
老规矩,先上图:
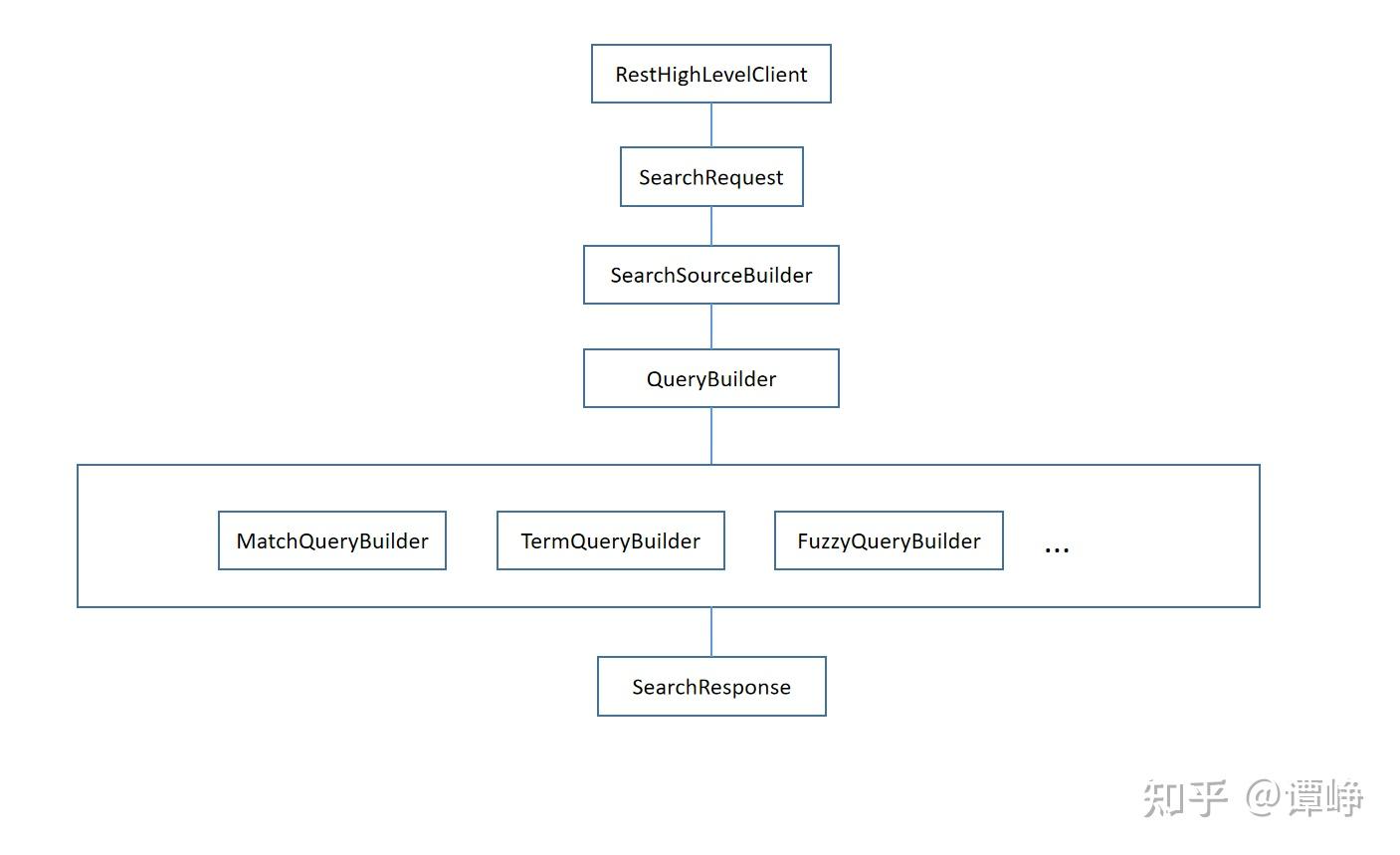
该图描绘了我们在复杂查询时会涉及到的类:一样是使用RestHighLevelClient,然后通过SearchRequest进行操作,SearchRequest又需要SearchSourceBuilder,而SearchSourceBuilder需要通过QueryBuilder完成构建,图中最下面一行列出了几种常用的QueryBuilder,基本上和我们ES查询的语法是直接相关的。最后SearchResponse返回结果。
下面给出查询的模板代码:
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESTest {
@Resource
RestHighLevelClient restHighLevelClient;
String index = &#34;index&#34;;
@Test
public List<TextBook> grepTextBook() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(&#34;author&#34;, &#34;老坛&#34;);
searchSourceBuilder.query(matchQueryBuilder);
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(index);
searchRequest.source(searchSourceBuilder);
List<TextBook> textBookList = new ArrayList<>();
//执行操作
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (Objects.nonNull(searchResponse)) {
SearchHits searchHits = searchResponse.getHits();
for (int i = 0; i < searchHits.getHits().length; i++) {
String str = searchHits.getHits().getSourceAsString();
System.out.println(str);
textBookList.add(JSON.parseObject(str, TextBook.class));
}
}
return textBookList;
}
}整个查询代码的核心实际上只有这一行:
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(&#34;author&#34;, &#34;老坛&#34;);因为只有QueryBuilder决定了你要怎么去进行查询,其它的都是模板,可以不动。
3.2 QueryBuilder说明
下面我们来一一介绍几种常用的QueryBuilder:
3.2.1 MatchQueryBuilder
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(&#34;author&#34;, &#34;老坛&#34;);对应了ES的match查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;: {
&#34;match&#34;: {
&#34;author&#34;:&#34;老坛&#34;
}
}
}3.2.2 MatchPhraseQueryBuilder
MatchPhraseQueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery(&#34;bookName&#34;, &#34;老坛&#34;);对应了ES的match_phrase查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;: {
&#34;match_phrase&#34;: {
&#34;bookName&#34;:&#34;老坛&#34;
}
}
}3.2.3 MultiMatchQueryBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(&#34;老坛&#34;, &#34;author&#34;,&#34;bookName&#34;);对应了ES的multi_match查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;: {
&#34;multi_match&#34;: {
&#34;query&#34;: &#34;老坛&#34;,
&#34;fields&#34;: [&#34;author&#34;,&#34;bookName&#34;]
}
}
}3.2.4 TermQueryBuilder
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery(&#34;author&#34;, &#34;老坛&#34;);对应了ES的term查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;: {
&#34;term&#34;: {
&#34;author&#34;: {
&#34;value&#34;: &#34;老坛&#34;
}
}
}
}3.2.5 TermsQueryBuilder
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery(&#34;author&#34;, &#34;老&#34;,&#34;坛&#34;);对应了ES的terms查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;: {
&#34;terms&#34;: {
&#34;author&#34;: [&#34;老&#34;,&#34;坛&#34;]
}
}
}3.2.6 FuzzyQueryBuilder
FuzzyQueryBuilder fuzzyQueryBuilder = QueryBuilders.fuzzyQuery(&#34;bookName&#34;, &#34;老坛&#34;);对应了ES的fuzzy查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;:{
&#34;fuzzy&#34;:{
&#34;bookName&#34;:&#34;老坛&#34;
}
}
}我们只要根据自己需要选择不同的builder去查询就可以了
3.2.7 RangeQueryBuilder&#39;
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery(&#34;num&#34;)
.gt(10)
.lt(20);对应了ES的range查询,它等价的ES语法就是:
GET textbook/_search
{
&#34;query&#34;:{
&#34;range&#34;:{
&#34;num&#34;:{
&#34;lt&#34;:20,
&#34;gt&#34;:10
}
}
}
}3.3 bool查询
bool查询也是我们使用es中比较常见的,当我们需要查询多个条件时,就会需要:
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(&#34;bookName&#34;, &#34;老坛&#34;);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery(&#34;author&#34;, &#34;老坛&#34;);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.must(matchQueryBuilder)
.should(termQueryBuilder);所对应的ES语法为:
GET textbook/_search
{
&#34;query&#34;:{
&#34;bool&#34;:{
&#34;must&#34;:{
&#34;match&#34;:{
&#34;bookName&#34;:&#34;老坛&#34;
}
},
&#34;should&#34;:{
&#34;term&#34;:{
&#34;author&#34;:&#34;老坛&#34;
}
}
}
}
}3.4 排序和分页
还用最开始的match举例,这里在此基础上添加了排序和分页两个限制:
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESTest {
@Resource
RestHighLevelClient restHighLevelClient;
String index = &#34;index&#34;;
@Test
public List<TextBook> grepTextBook() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(&#34;bookName&#34;, &#34;老坛&#34;);
searchSourceBuilder.query(matchQueryBuilder);
// 分页参数
searchSourceBuilder.sort(&#34;num&#34;, SortOrder.DESC);
searchSourceBuilder.from(1);
searchSourceBuilder.size(100);
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(index);
searchRequest.source(searchSourceBuilder);
List<TextBook> textBookList = new ArrayList<>();
//执行操作
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (Objects.nonNull(searchResponse)) {
SearchHits searchHits = searchResponse.getHits();
for (int i = 0; i < searchHits.getHits().length; i++) {
String str = searchHits.getHits().getSourceAsString();
System.out.println(str);
textBookList.add(JSON.parseObject(str, TextBook.class));
}
}
return textBookList;
}
}排序和分页主要体现在这几行:
// 分页参数
searchSourceBuilder.sort(&#34;num&#34;, SortOrder.DESC);
searchSourceBuilder.from(1);
searchSourceBuilder.size(100);可以看到这是一个按照num字段的降序搜索,并且是按照页容量为100进行分页,取第二页。
所对应的ES语法为:
GET textbook/_search
{
&#34;query&#34;:{
&#34;match&#34;:{
&#34;bookName&#34;:&#34;老坛&#34;
}
},
&#34;from&#34;:0,
&#34;size&#34;:100,
&#34;sort&#34;:{
&#34;num&#34;:{
&#34;order&#34;:&#34;desc&#34;
}
}
}4. 总结
到这里Java对ES的操作基本上聊的差不多了,题主这里介绍的未必详尽,只是一些我们通常会用到的操作,如果还想详细了解更多的内容请阅读官方文档:
https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/7.17/java-client-javadoc.html
另外,题主这里只是为了给大家讲明白如何使用举了几个例子,并不一定效率最高或者使用常见最为恰当,还是需要大家学习一下ES的语法根据自己的实际业务场景去选用,谢谢大家~
|
|


 发表于 2023-1-17 12:56:40
发表于 2023-1-17 12:56:40