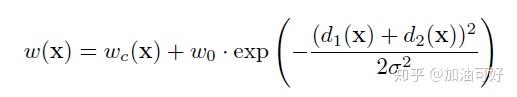|
|
 发表于 2023-1-12 13:08:20
|
显示全部楼层
发表于 2023-1-12 13:08:20
|
显示全部楼层
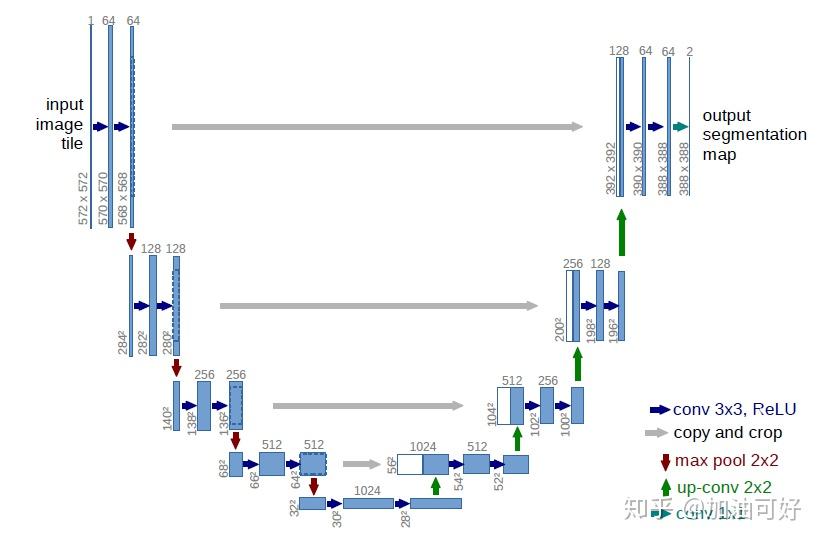
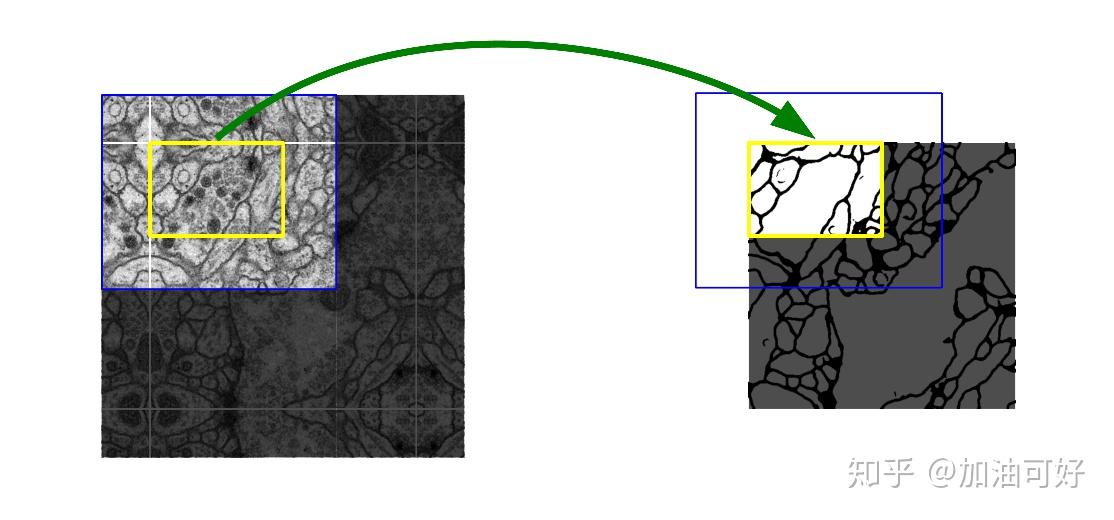
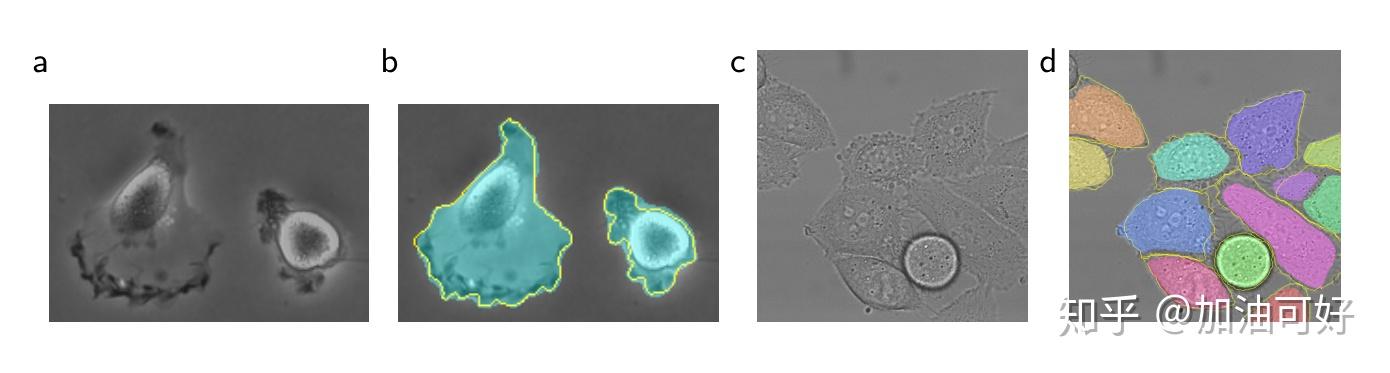
是处理过的原图(例如用了overlap-tile策略做了数据增强),不是很小的那种区域块。
原句:To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image.我翻译的时候把tile翻译成图块了,可能产生了歧义,实际上可以理解为图像。论文中Fig.1.结构图中就管输入图像叫input image tile。 |
|