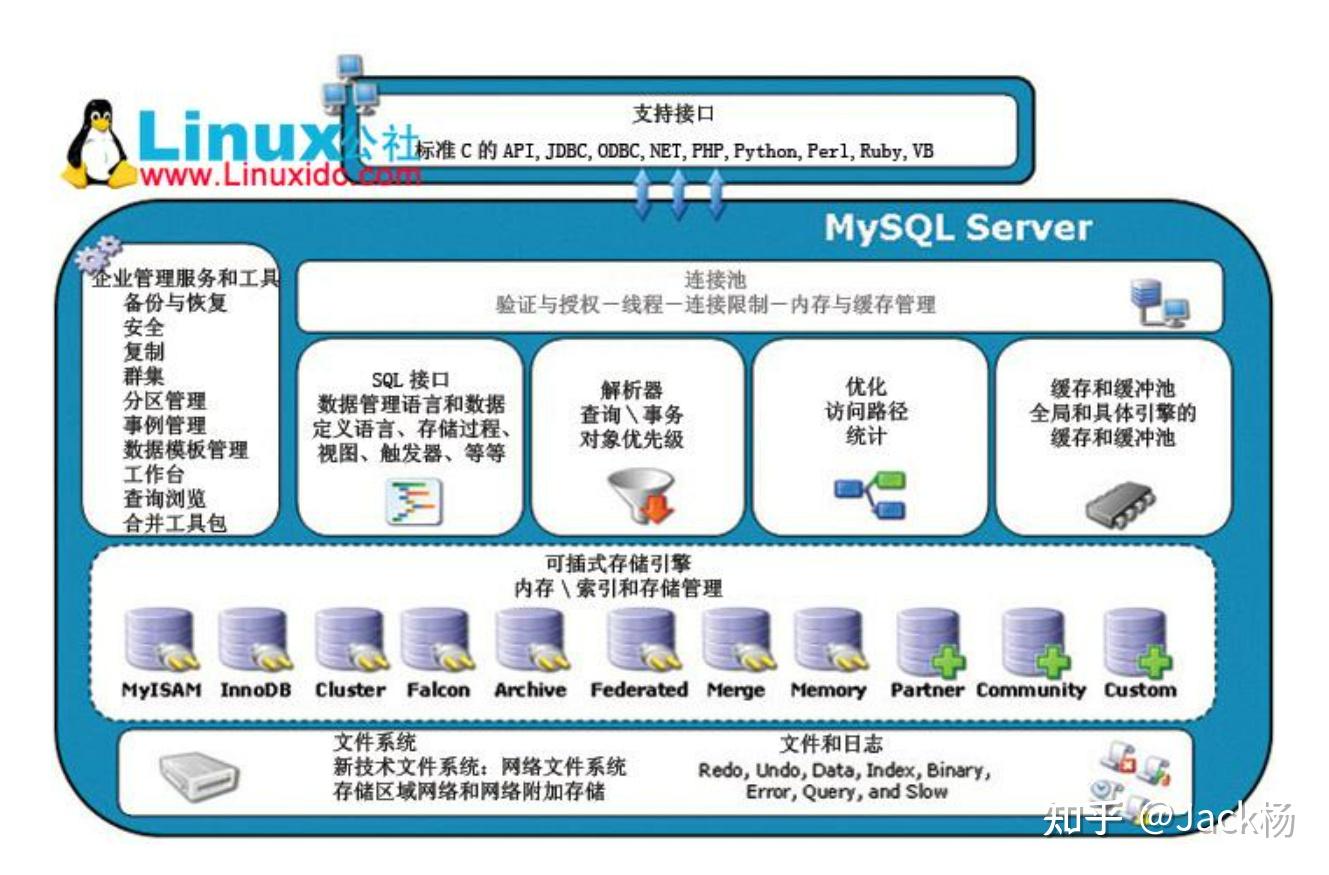
存储引擎
存储引擎就是我们的数据真正存放的地方,在 MySQL 里面支持不同的存储引擎。再往下就是内存或者磁盘。
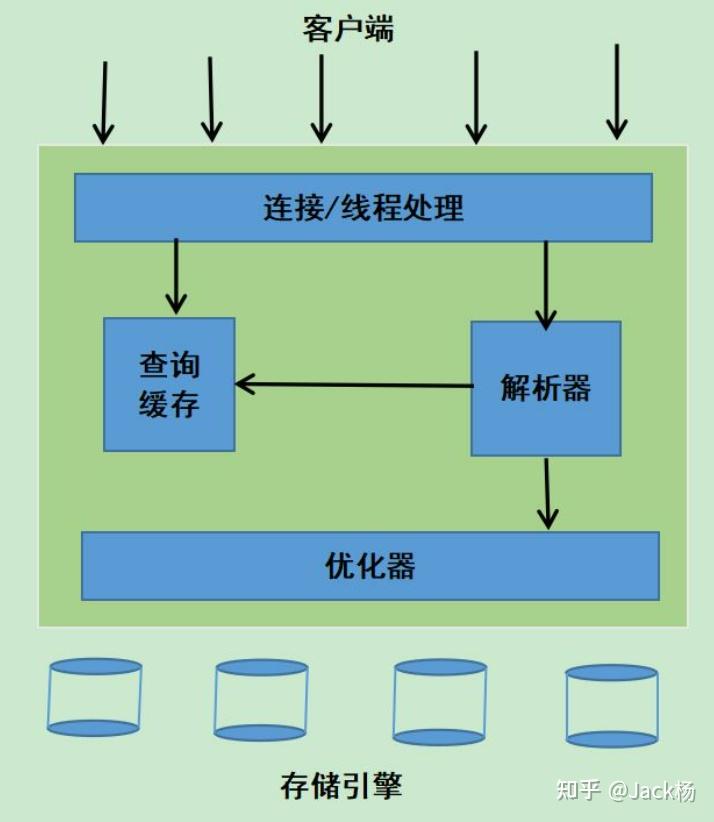
SQL的执行流程
以一条查询语句为例,我们来看下 MySQL 的工作流程是什么样的。
select name from user where id=1 and age>20; 连接
程序或者工具要操作数据库,第一步要跟数据库建立连接。在数据库中有两种连接:
短连接:短连接就是操作完毕以后,马上 close 掉。
长连接:长连接可以保持打开,减少服务端创建和释放连接的消耗,后面的程序访问的时候还可以使用这个连接。
建立连接是比较麻烦的,首先要发送请求,发送了请求要去验证账号密码,验证完了要去看你所拥有的权限,所以在使用过程中,尽量使用长连接。保持长连接会消耗内存。长时间不活动的连接,MySQL 服务器会断开。可以使用sql语句查看默认时间:
show global variables like 'wait_timeout'; 这个时间是由 wait_timeout 来控制的,默认都是 28800 秒,8 小时。 查询缓存
在 MySQL 8.0 中,查询缓存已经被移除了。
语法解析和预处理
这一步主要做的事情是对语句基于 SQL 语法进行词法和语法分析和语义的解析。
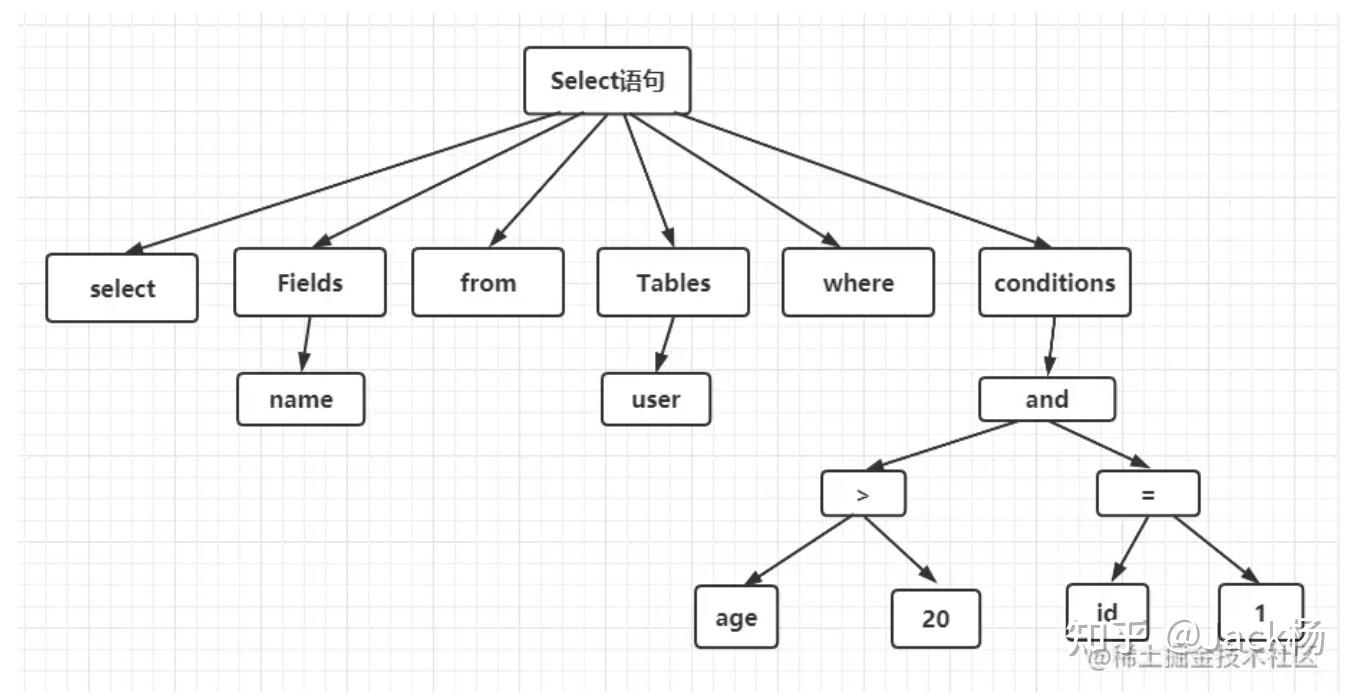
词法解析
词法分析就是把一个完整的 SQL 语句打碎成一个个的单词。
比如一个简单的 SQL 语句:select name from user where id = 1 and age >20;
查询优化器
一条 SQL 语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的,这个就是 MySQL 的查询优化器的模块(Optimizer)。 查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选 择一种最优的执行计划,MySQL 里面使用的是基于开销(cost)的优化器,那种执行计划开销最小,就用哪种。可以使用这个命令查看查询的开销:
show status like'Last_query_cost';执行计划
优化器最终会把解析树变成一个执行计划(execution_plans),执行计划是一个数据结构。当然,这个执行计划不一定是最优的执行计划,因为 MySQL 也有可能覆盖不到所有的执行计划。
MySQL 提供了一个执行计划的工具。我们在 SQL 语句前面加上 EXPLAIN,就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;存储引擎
在关系型数据库里面,数据是放在表 Table 里面的。我们可以把这个表理解成 Excel 电子表格的形式。所以我们的表在存储数据的同时,还要组织数据的存储结构,这个存储结构就是由我们的存储引擎决定的,所以我们也可以把存储引擎叫做表类型。
在 MySQL 里面,支持多种存储引擎,他们是可以替换的,所以叫做插件式的存储引擎。
在 MySQL 里面,每一张表都可以指定它的存储引擎,而不是一个数据库只能使用一个存储引擎。存储引擎的使用是以表为单位的。而且,创建表之后还可以修改存储引擎。
如果对数据一致性要求比较高,需要事务支持,可以选择 InnoDB。
如果数据查询多更新少,对查询性能要求比较高,可以选择 MyISAM。
如果需要一个用于查询的临时表,可以选择 Memory。
执行引擎
谁使用执行计划去操作存储引擎呢?这就是执行引擎(执行器),它利用存储引擎提供的相应的 API 来完成操作。为什么我们修改了表的存储引擎,不同功能的存储引擎实现的 API 是相同的。最后把数据返回给客户端,即使没有结果也要返回。
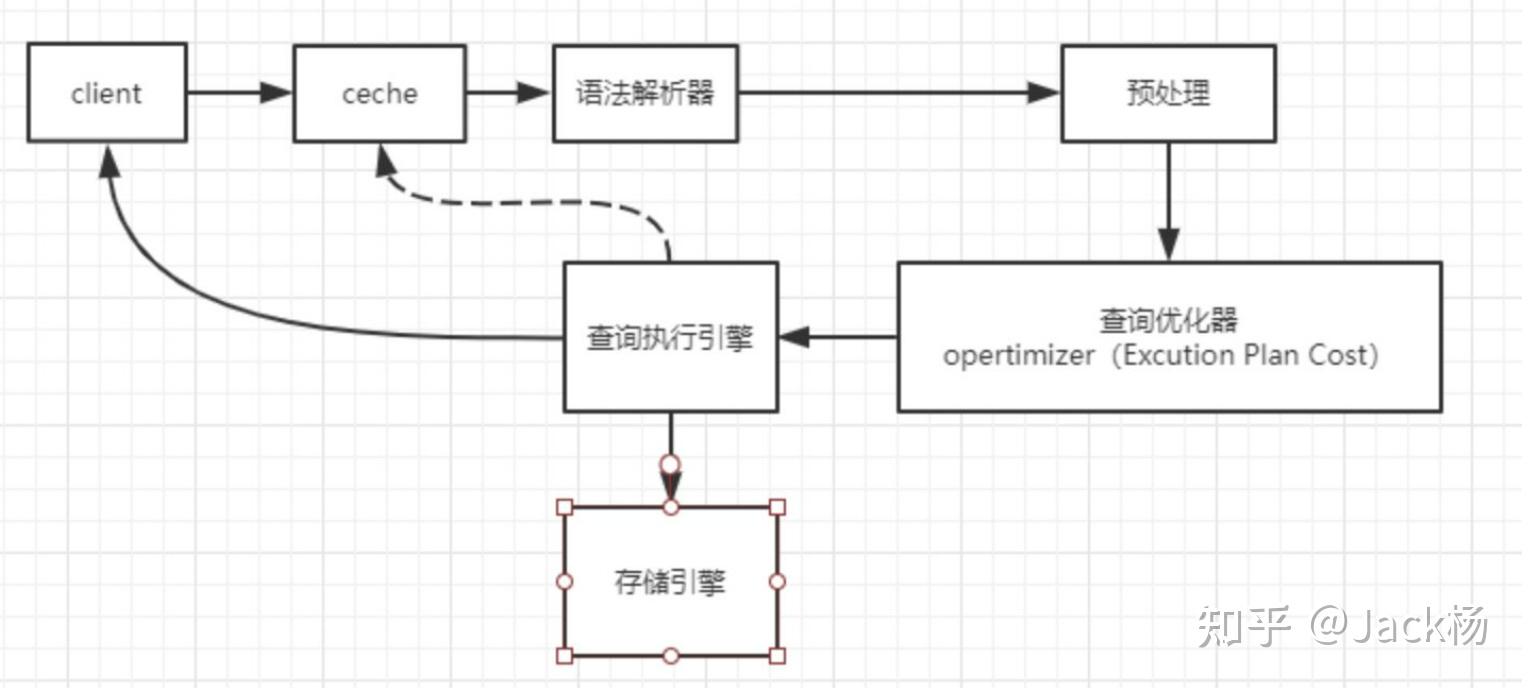
以上面的sql语句为例,再来梳理一下整个sql执行流程。
select name fromuserwhere id =1and age >20;1.通过连接器查询当前执行者的角色是否有权限,进行查询。如果有的话,就继续往下走,如果没有的话,就会被拒绝掉,同时报出 Access denied for user 的错误信息;
2. 接下来就是去查询缓存,首先看缓存里面有没有,如果有呢,那就没有必要向下走,直接返回给客户端结果就可以了;如果缓存中没有的话,那就去执行语法解析器和预处理模块。( MySQL 8.0 版本直接将查询缓存的整块功能都给删掉了)


 发表于 2023-1-12 12:06:55
发表于 2023-1-12 12:06:55