上一篇AI Day 2021的解读文章 EatElephant:超长延迟的特斯拉AI Day解析:讲明白FSD车端感知 被我自嘲为超长延迟的AI Day解读实在是因为平时工作繁忙,做细致的AI Day解读又需要花不少心思研究分析,不得已一拖再拖。不过AI Day II的时间的特别好,恰好赶在了十一假期的第一天,所以这次决定不再拖延,把这个信息量巨大,整个观看过程震撼连连的技术分享,做一个细致的解析,以帮助感兴趣的朋友更好地了解自动驾驶技/人工智能领域最前沿的技术进展,更深入地体会科技进化的大趋势。然而AI Day 2022所涉及的领域实在是太广泛,从机器人到自动驾驶,从算法创新到数据闭环,从AI编译软件优化,通讯优化,到底层推理训练芯片硬件设计理念,即使作为自动驾驶行业从业者也很难做到对每一个部分都了解的面面俱到,因此本文着重解析AI Day自动驾驶方面内容,类人机器方面其实目前看来还比较初级,离产品商业化还有距离,技术分享本身也不够深入,因此只会在文末对Tesla bot做简单的评述和展望。此外AI Day II技术分享广度十分惊人,但某些部分不够细节,因此本文也会加入一定的自己的理解,因此少量的错误以及与实际有所出入也在所难免,欢迎有对某些模块更了解的朋友理性讨论,纠正指出。
概况
2022 AI Day Tesla所展示的其在自动驾驶和人工智能方面研发的创新和广度是前所未有的,虽然近几年来通过不断的技术分享,Tesla独特的技术方案已经逐渐为业界所熟知,但今年所分享的很多最新的理念和创新,包括彻底贯彻端到端的数据驱动方法到技术方案的各个部分,以及从底层硬件到顶层算法的高度纵向集成优化带来的性能飞跃等,仍旧令人瞠目与震撼,因此我觉得把Tesla AI Day称作自动驾驶领域的春晚也一点也不为过。下面我会尽量用通俗易懂的方式来分享一下我对于Tesla AI Day的解读。
自动驾驶FSD部分
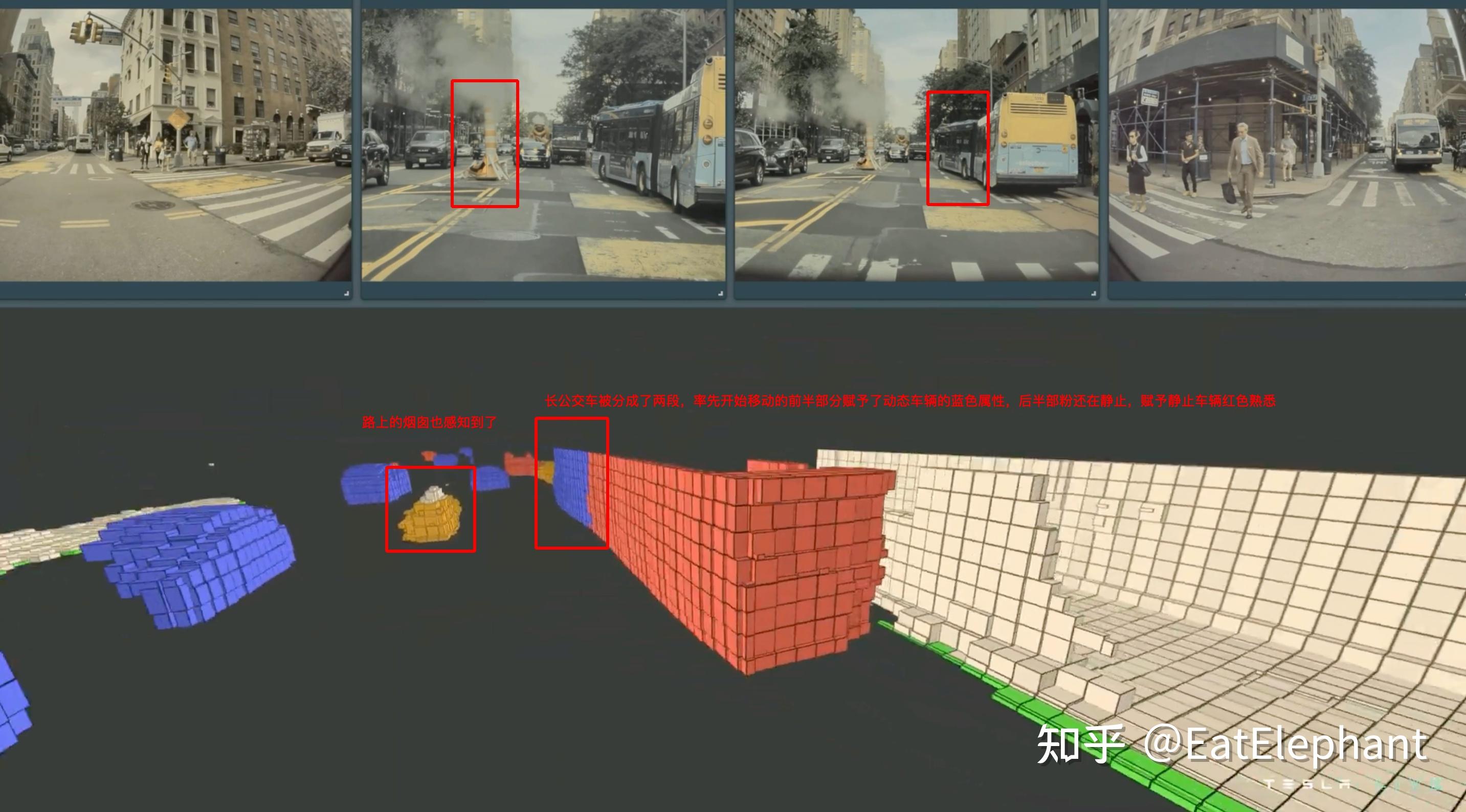
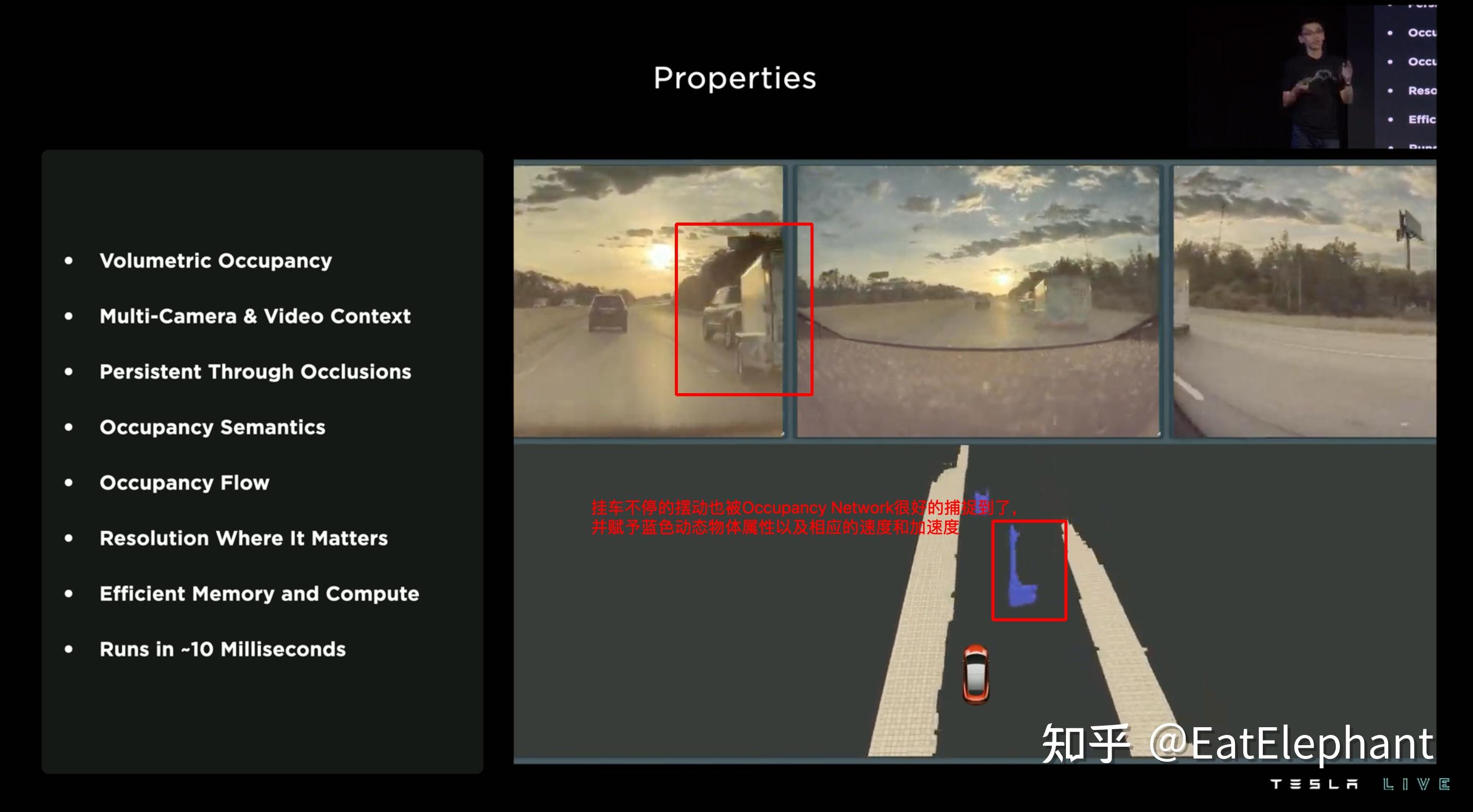
上图高速上行驶的挂车,尾部发生摆动,其形态不断变化,也被Occupancy Network正确感知且赋予了正确的蓝色动态物体属性和相应的速度和加速度。
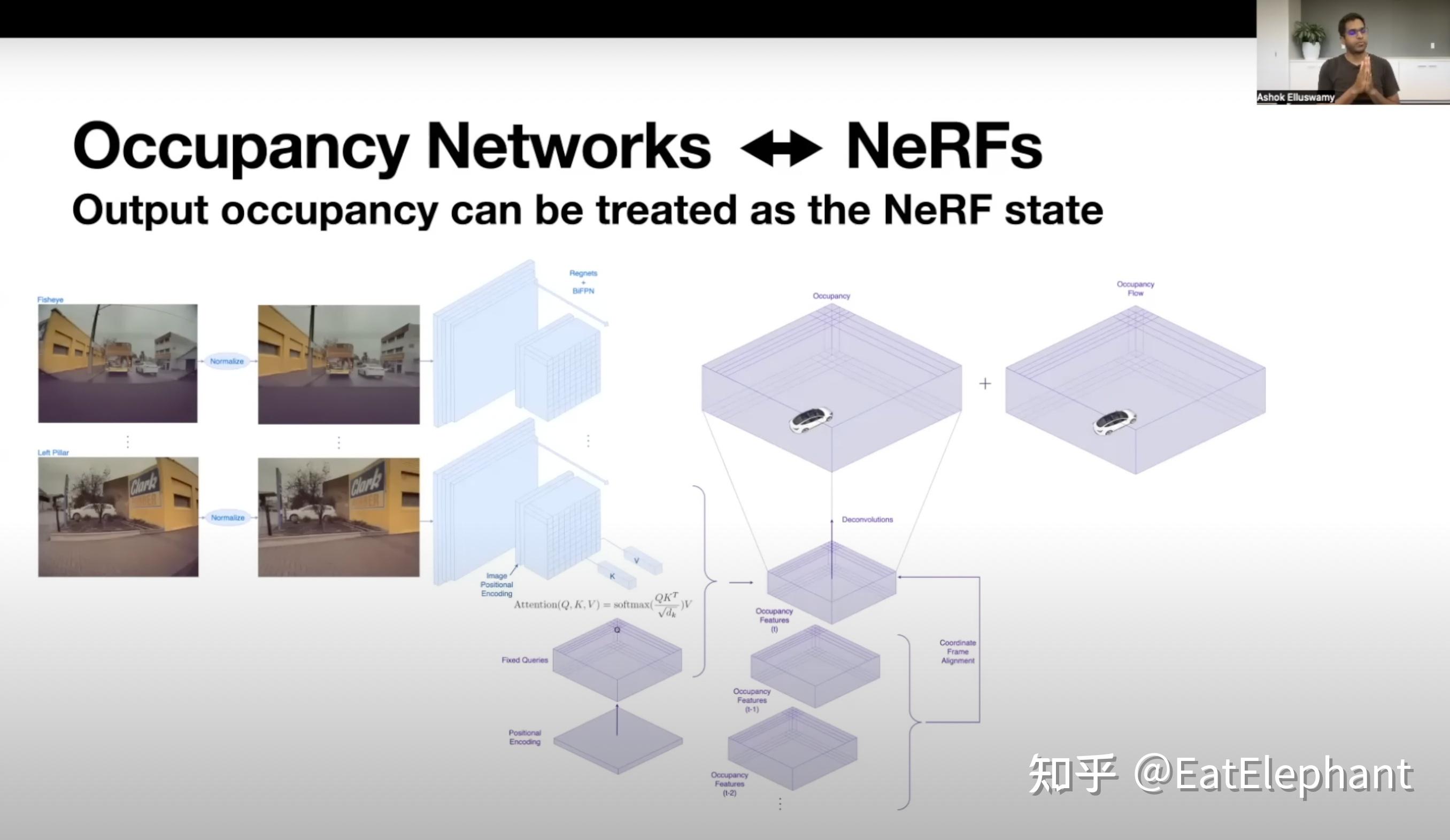
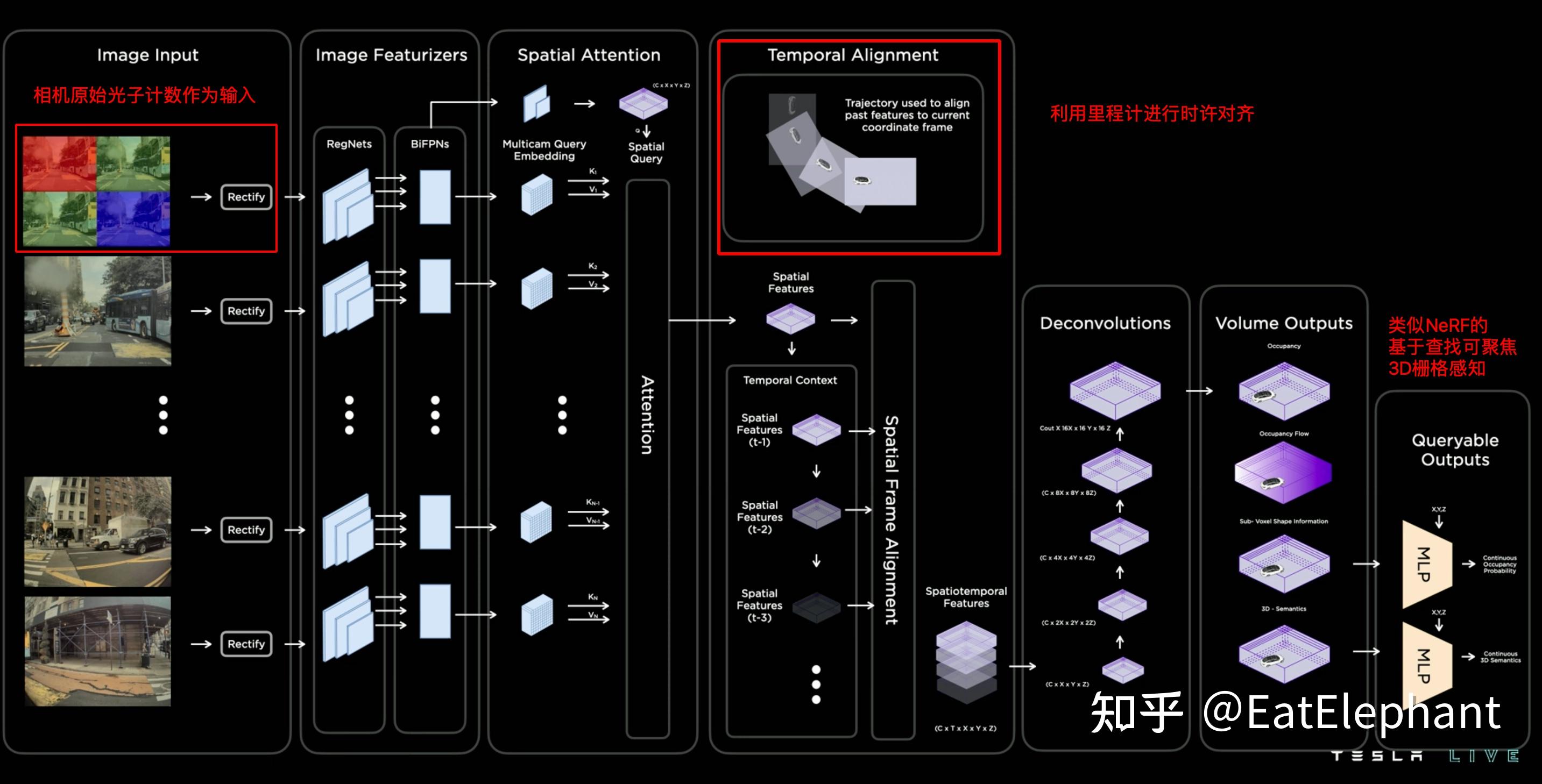
而这样复杂的Occupancy Network可以在10毫秒中计算完毕,也就是说Tesla Occupancy Network的输出可以达到跟相机同样的36Hz,而目前绝大多数Lidar的采集频率只有10Hz,因此在高速环境或者对快速移动的物体感知方面,纯视觉的Occupancy Network甚至可能做到比Lidar更强。
车道线及障碍物感知 Lane & Object Perception
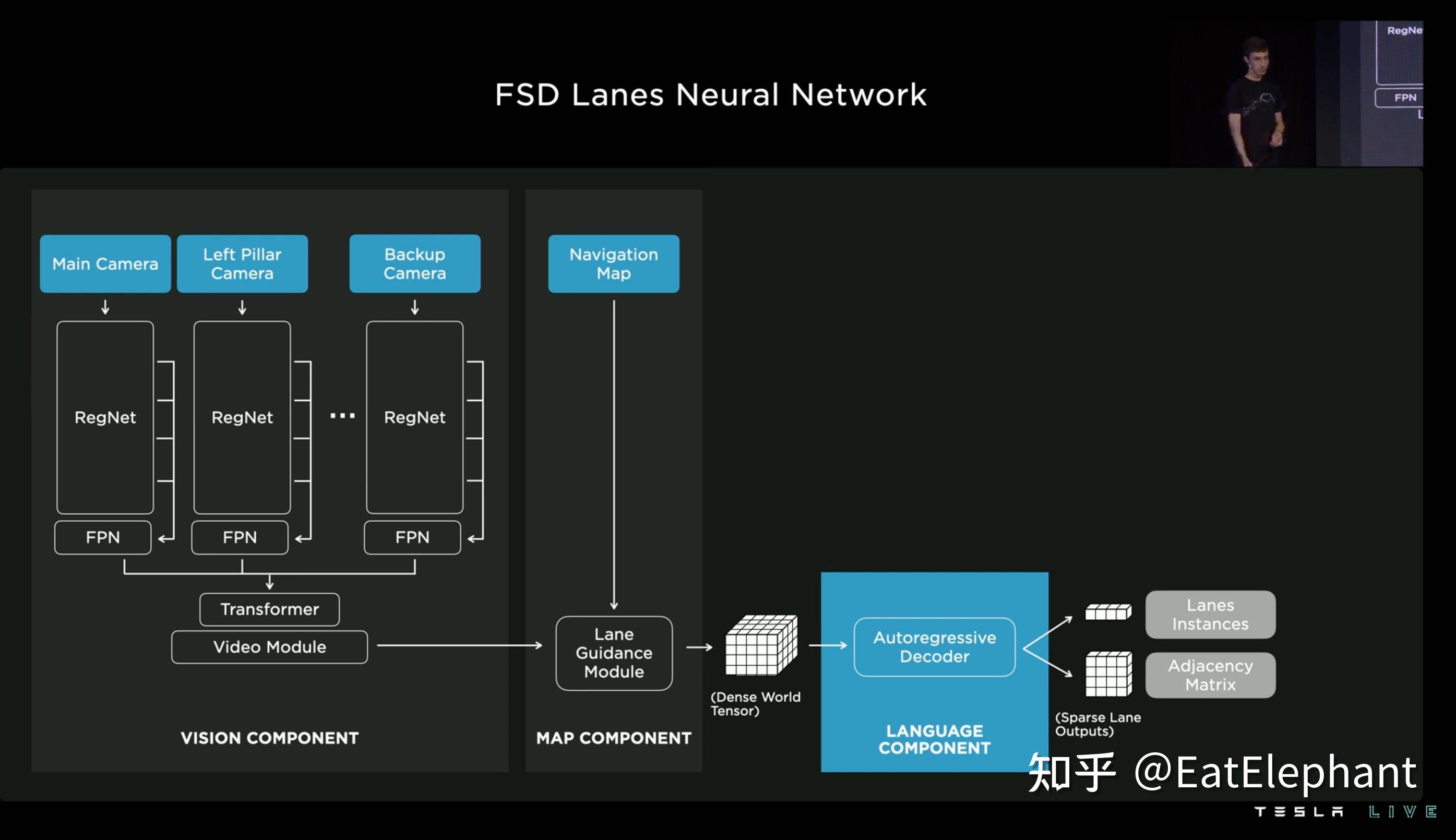
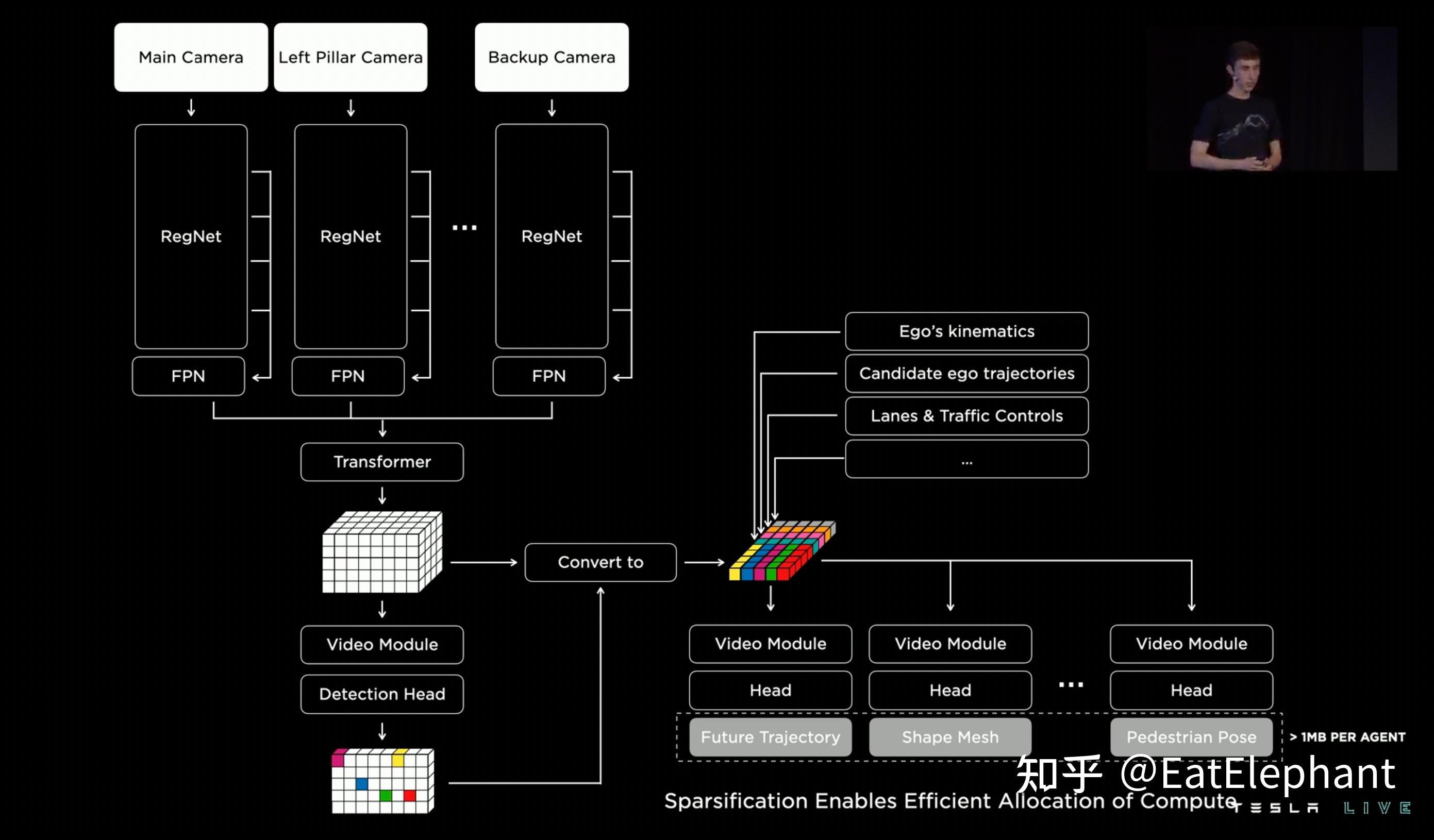
Tesla的车道线感知在BEV时代就已经是业界最强的存在,FSD Beta在2020年10月开始进行公开测试也证实掀起了学术界研究BEV感知的热潮。AI Day II分享了车道线感知的最新进展,包括v10.69后在FSD Beta Release Note中出现的Map Guidance Module以及在v10.11中就出现的端到端Vector Lane感知。
FSD 车道线感知技术框架
从AI Day的分享可以看到FSD的最新车道线感知已经是基于3D Occupancy的感知,而不再是仅仅基于2D BEV,另外之前Occupancy Network也提到了地面曲面感知,可知现在Tesla的车道线感知是具有高低起伏变化的车道线感知。这里第一个与之前版本车道线感知不同的点就是Map Component的引入。Tesla提到他们使用了低精度地图中关于车道线几何/拓扑关系的信息,车道线数量,宽度,以及特殊车道属性等信息,并将这些信息整合起来进行编码,与视觉感知到的特征信息一起生成车道线Dense World Tensor给到后续Vector Lane模块。
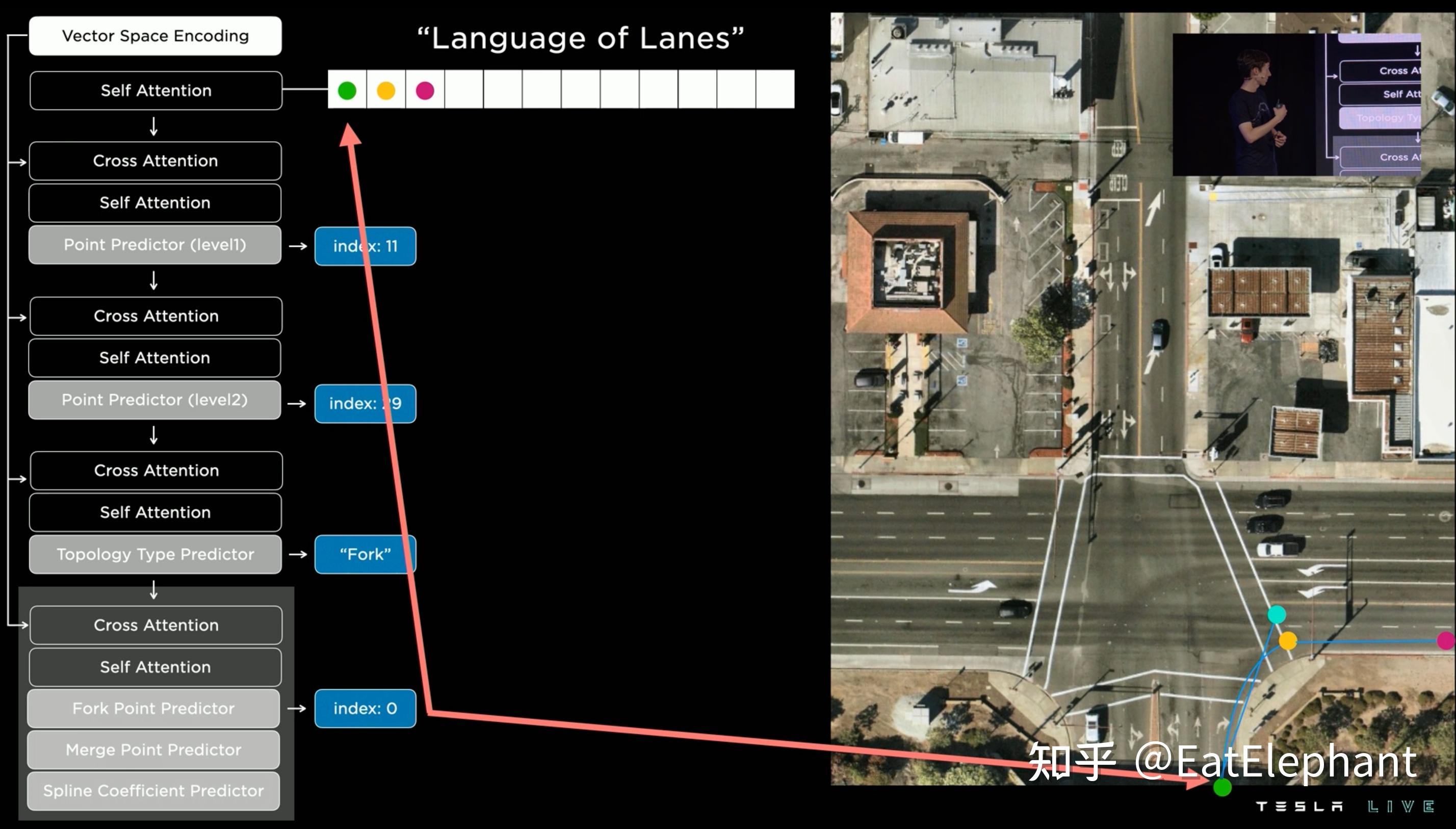
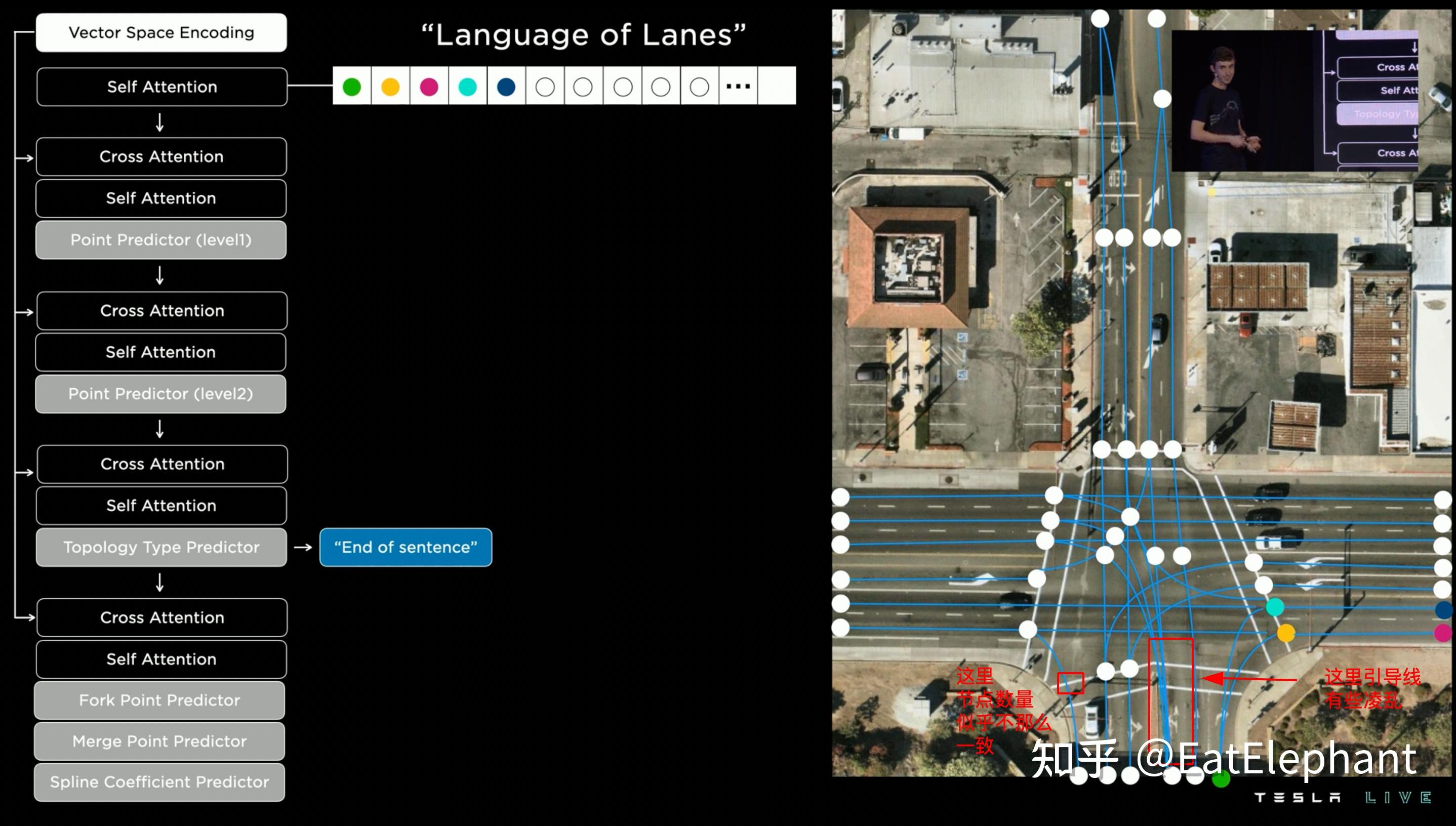
借鉴语言类模型的Vector Lane模块
后续的重头戏其实是借鉴语言模型开发的Vector Lane模块。这里Vector Space Encoding即上图的Dense World Tensor,而整个模块的思路是把车道线相关信息包括车道线节点位置,车道线节点属性(起点,中间点,终点等),分叉点,汇合点,以及车道线样条曲线几何参数进行编码,做成类似语言模型中单词token的编码,然后利用时序处理办法进行处理。这里框架看起来非常像Transformer中的Decoder,前序车道线token作为decoder的输入进行Self Attention,再在Cross Attention步骤里生成Query,而Vector Space Encoding则整体生成Value和Key来与前序Token结合生成最新的token。
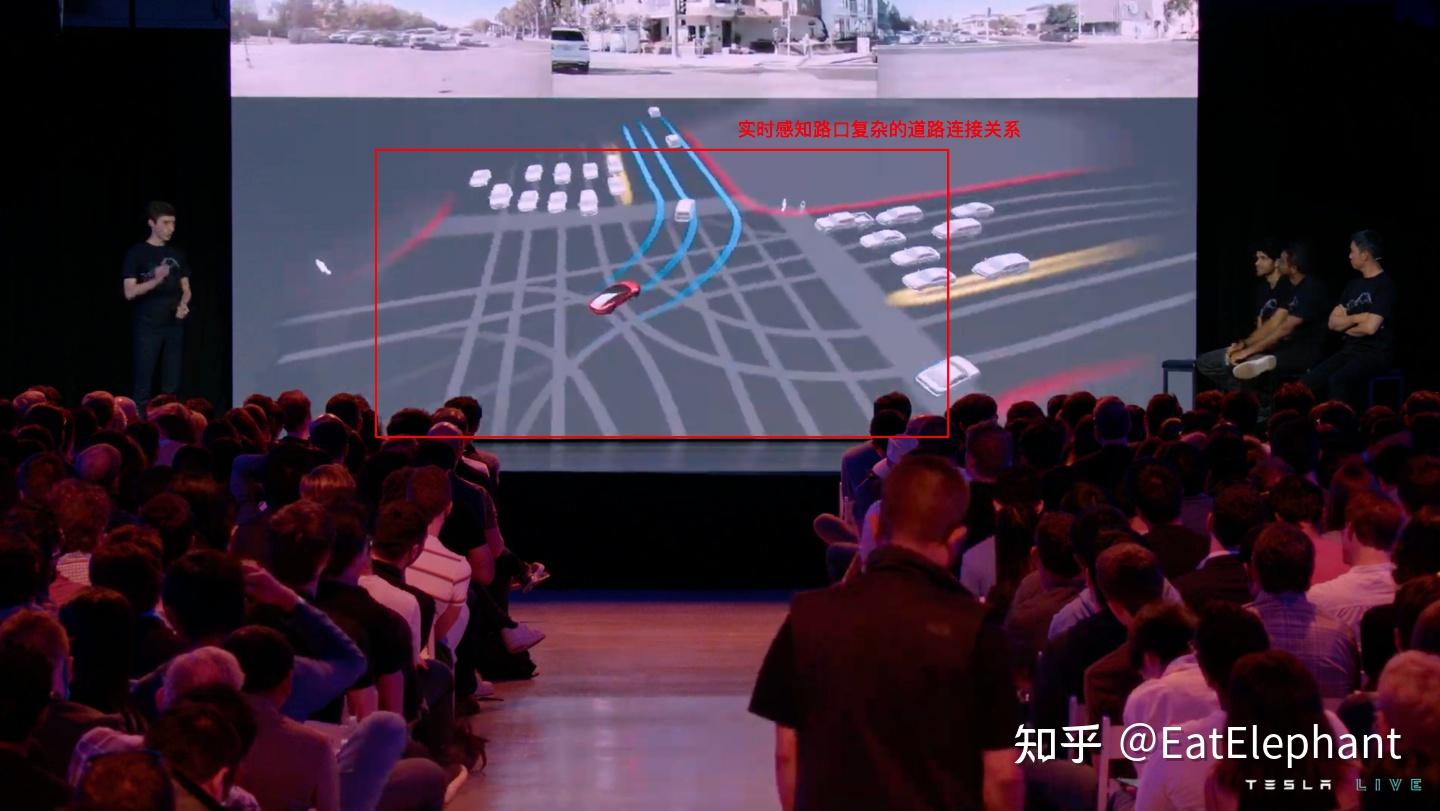
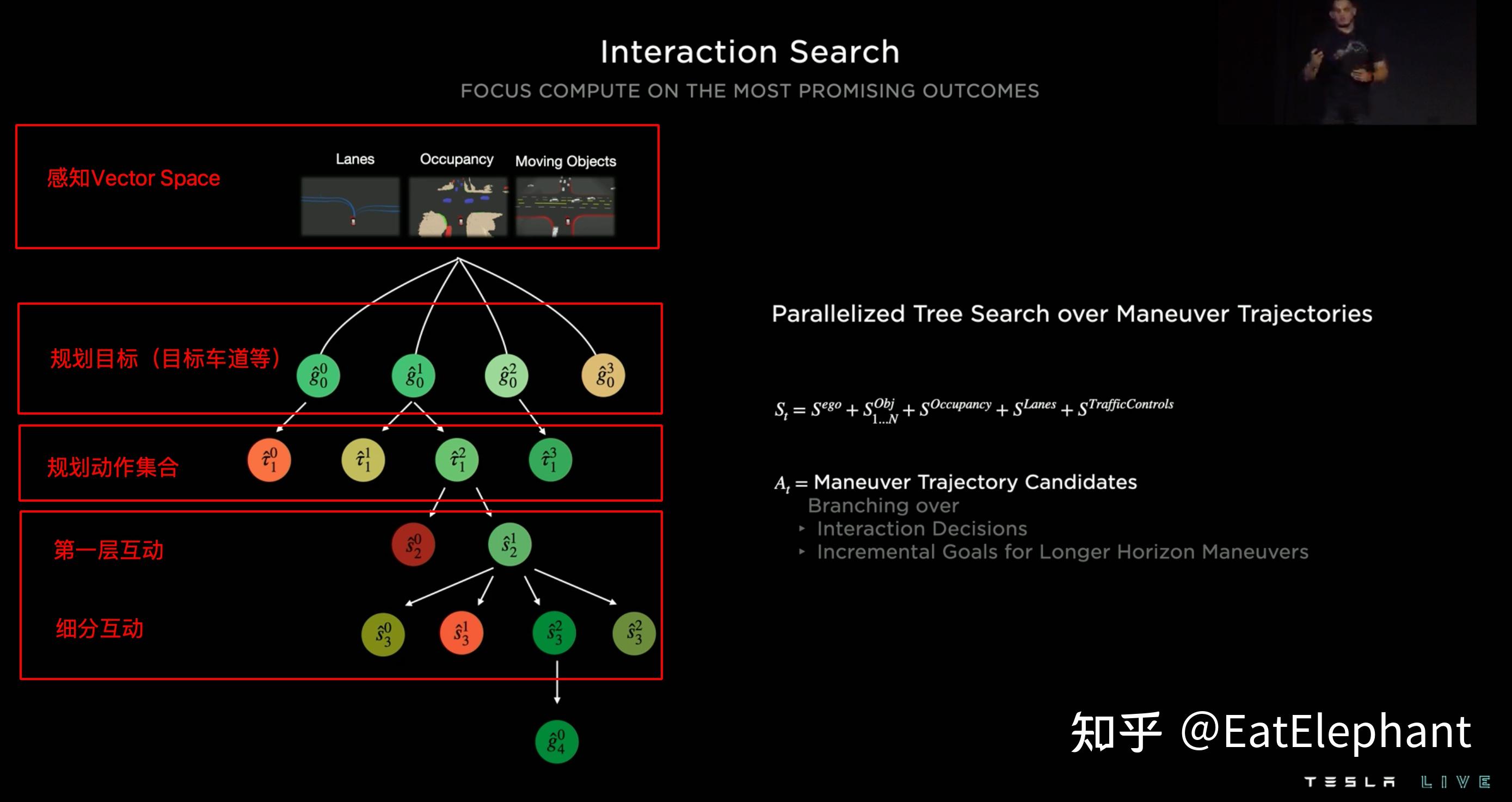
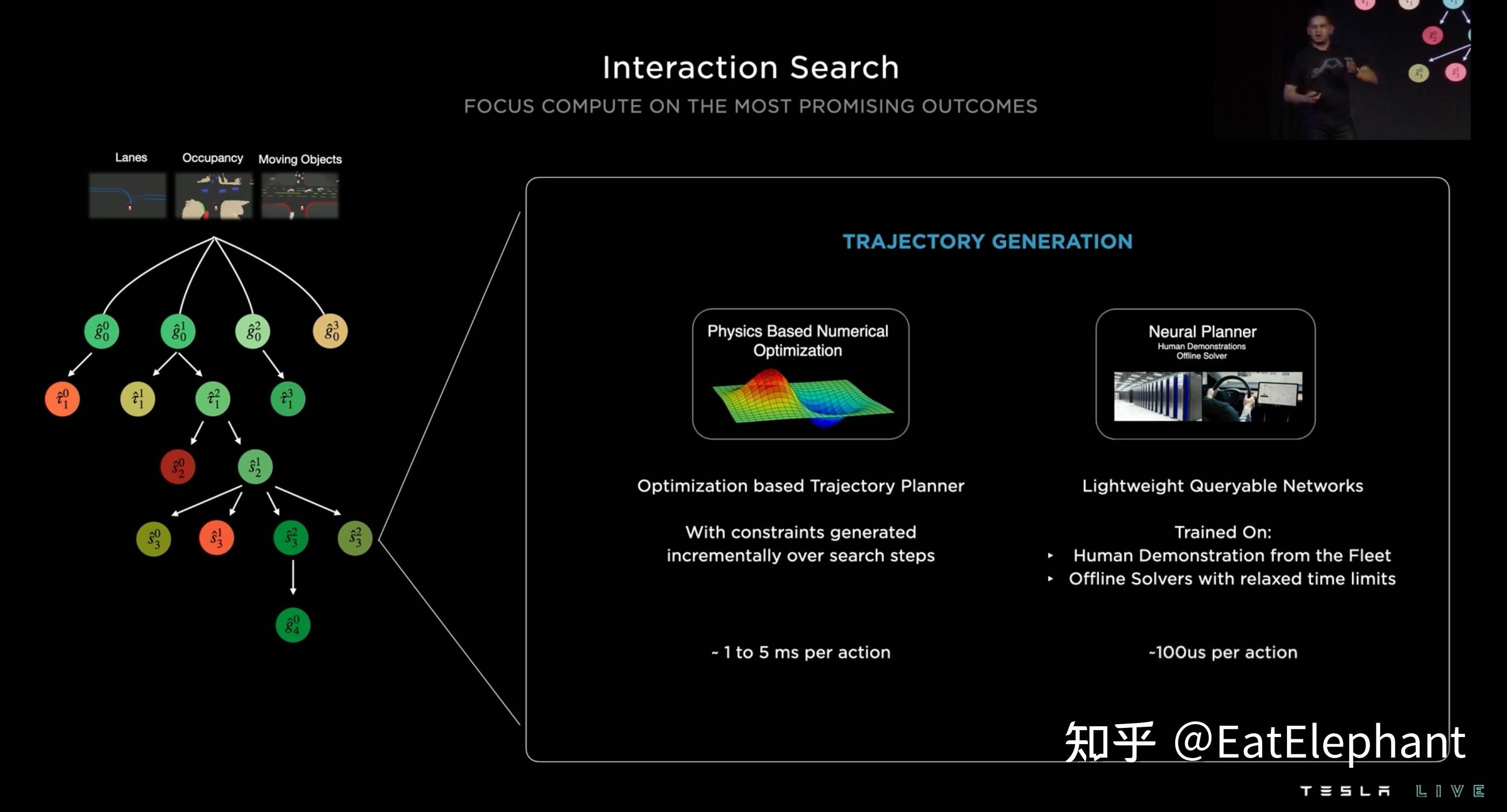
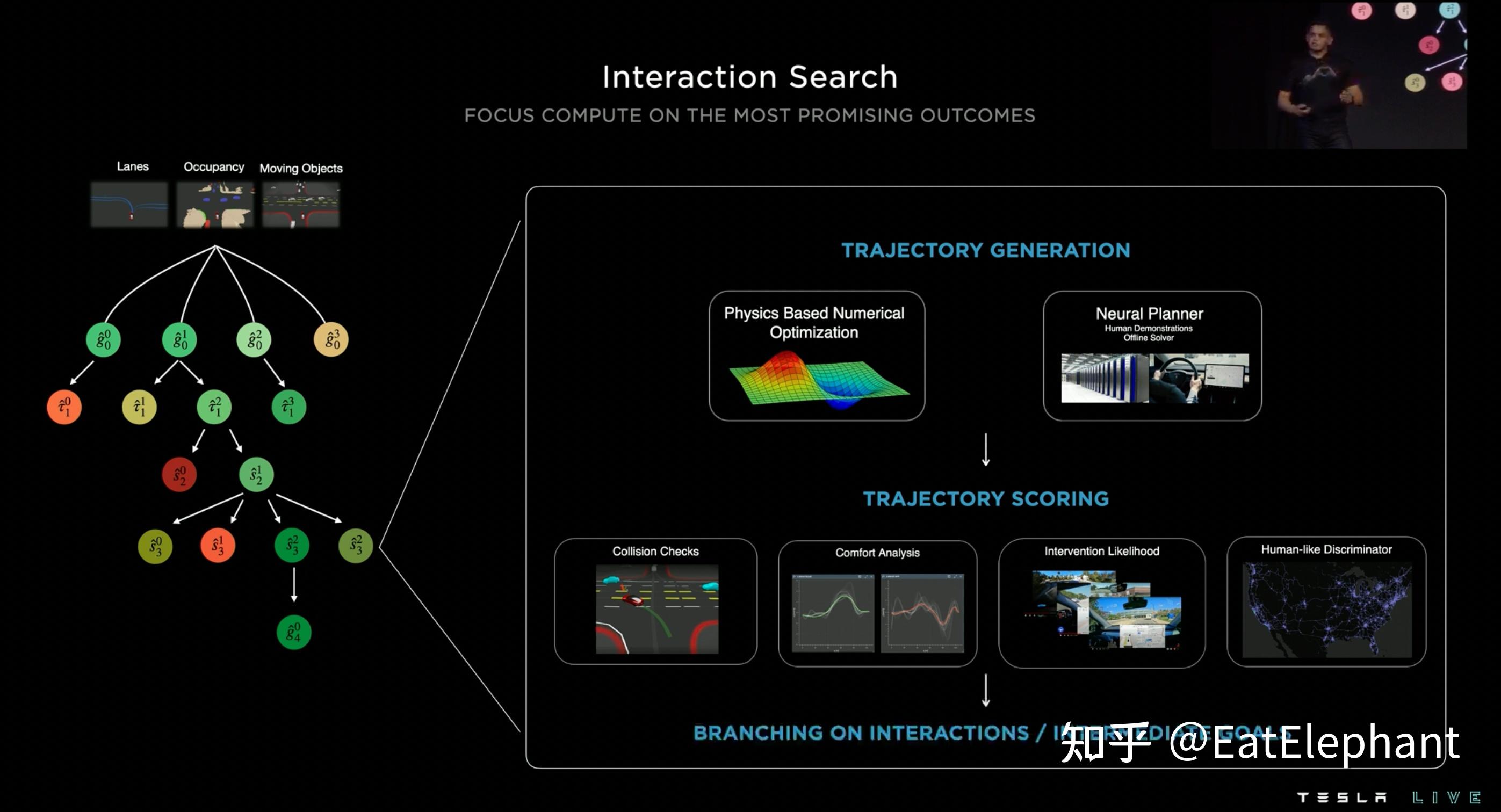
这次AI Day 2022比上次AI Day分享了更多一点的决策规划内容,这两次分享对决策规划的讨论都比较简单,远不如感知部分细致详尽,然而Tesla的决策规划控制算法在行业中毫无疑问是极强的,简单到我日常使用免费版Autopilot车道保持在几乎任何高速弯道都能无障碍通过无愧弯道王者的称号,复杂到在北美地区不使用高精地图的FSD就可以在无车道道路,旧金山九曲花街这样鬼畜连续急弯,高低起伏的山路,复杂快速车流无保护路口借中间分隔带左转(aka Chunk弯)等等,有兴趣的朋友可以看我之前的视频和Youtube一些较新的测试视频:
这些基于占据栅格的可视区域建模,Ghost动态物体等方法不是Tesla首创,早在几年前就有学术研究在使用Lidar的L4车型上提出这些规划方法,然而使用纯视觉的方法实现这一切显然是一大创举,另外从最新的FSD Beta实测视频可以看出,FSD开始懂得利用向前小步挪移开视野,同时在遮挡比较多的人形道,横穿马路时候进行保护性驾驶的策略都确认了AI Day分享的内容就在实车上运行着,这些比较前沿的规划研究都实实在在用在了Tesla FSD的产品中,可见FSD规划算法的先进性以及整个系统的完整性和复杂性,确实处于行业最顶尖行列。
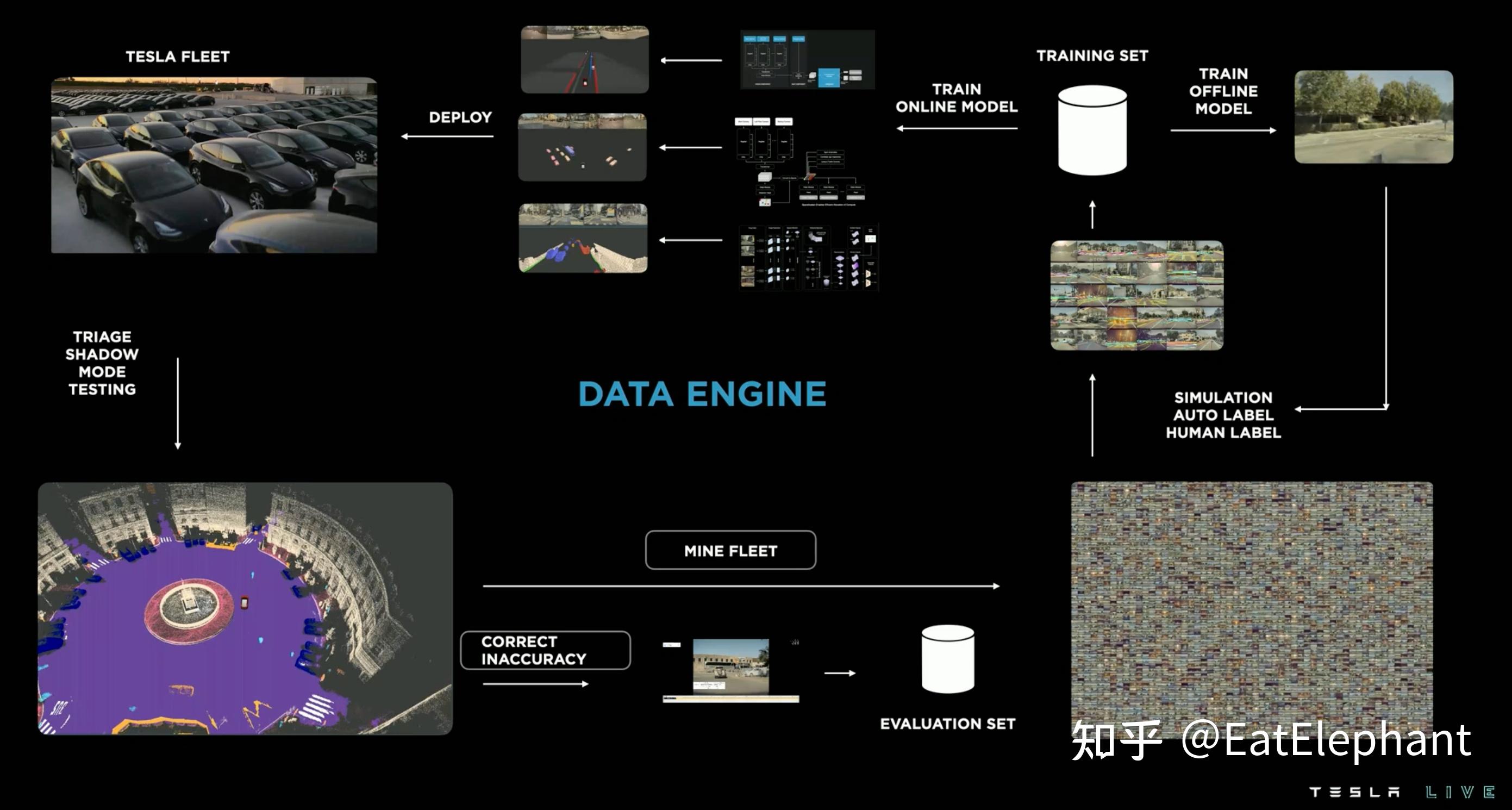
自动标注和数据引擎 AutoLabeler & Data Engine
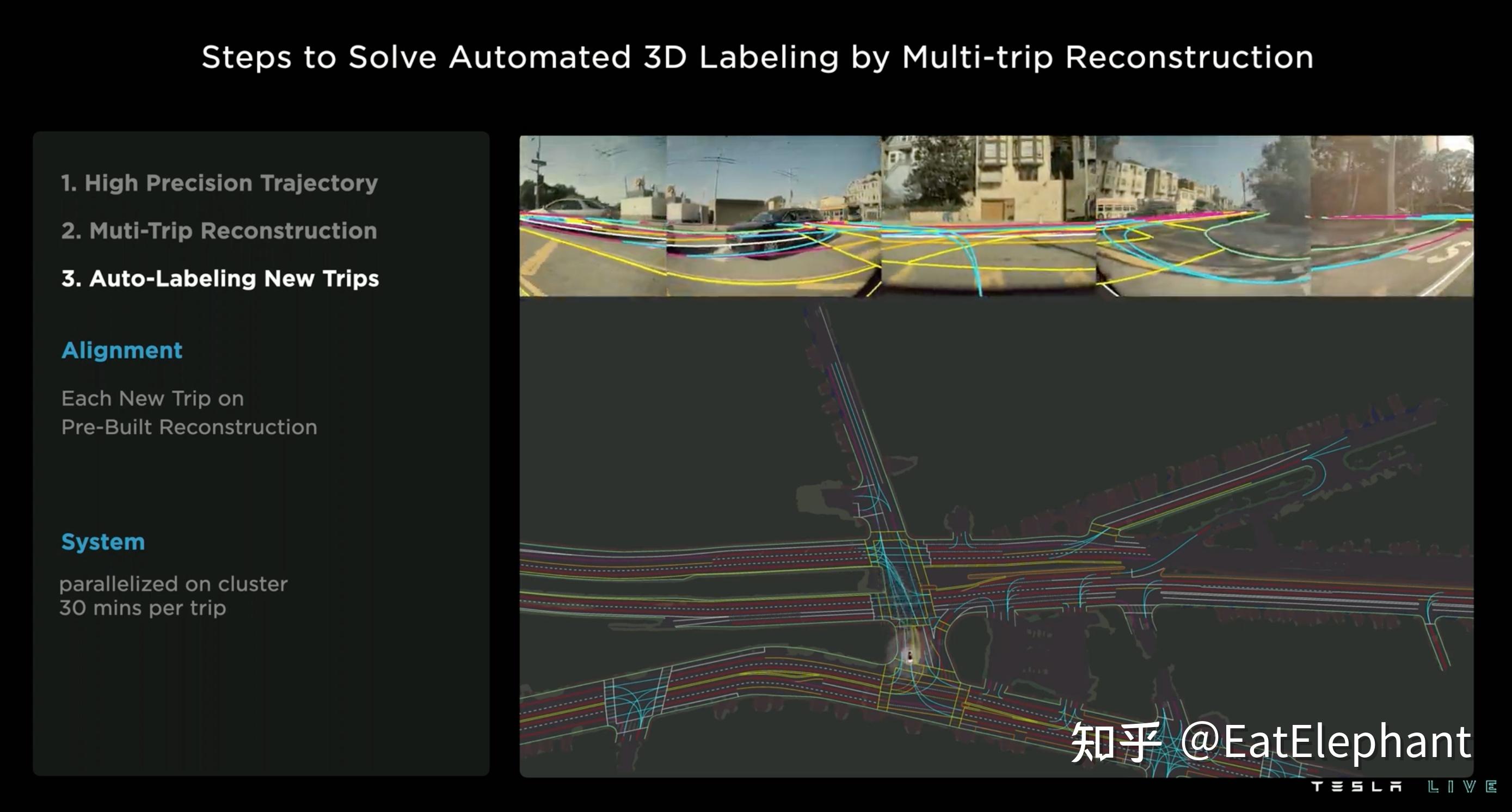
在自动标注方面这次非常难得的给出了通过道路重建作为车道线感知真值进行4D标注的方案,其本质上是一个基于Tesla强大视觉感知能力的众包建图,然而不同之处在于Tesla并没有显示使用这些构建的“低精”地图,而是将这些地图作为真值,内化到感知模型中,避免了对于拥有详尽信息的高精地图的依赖。
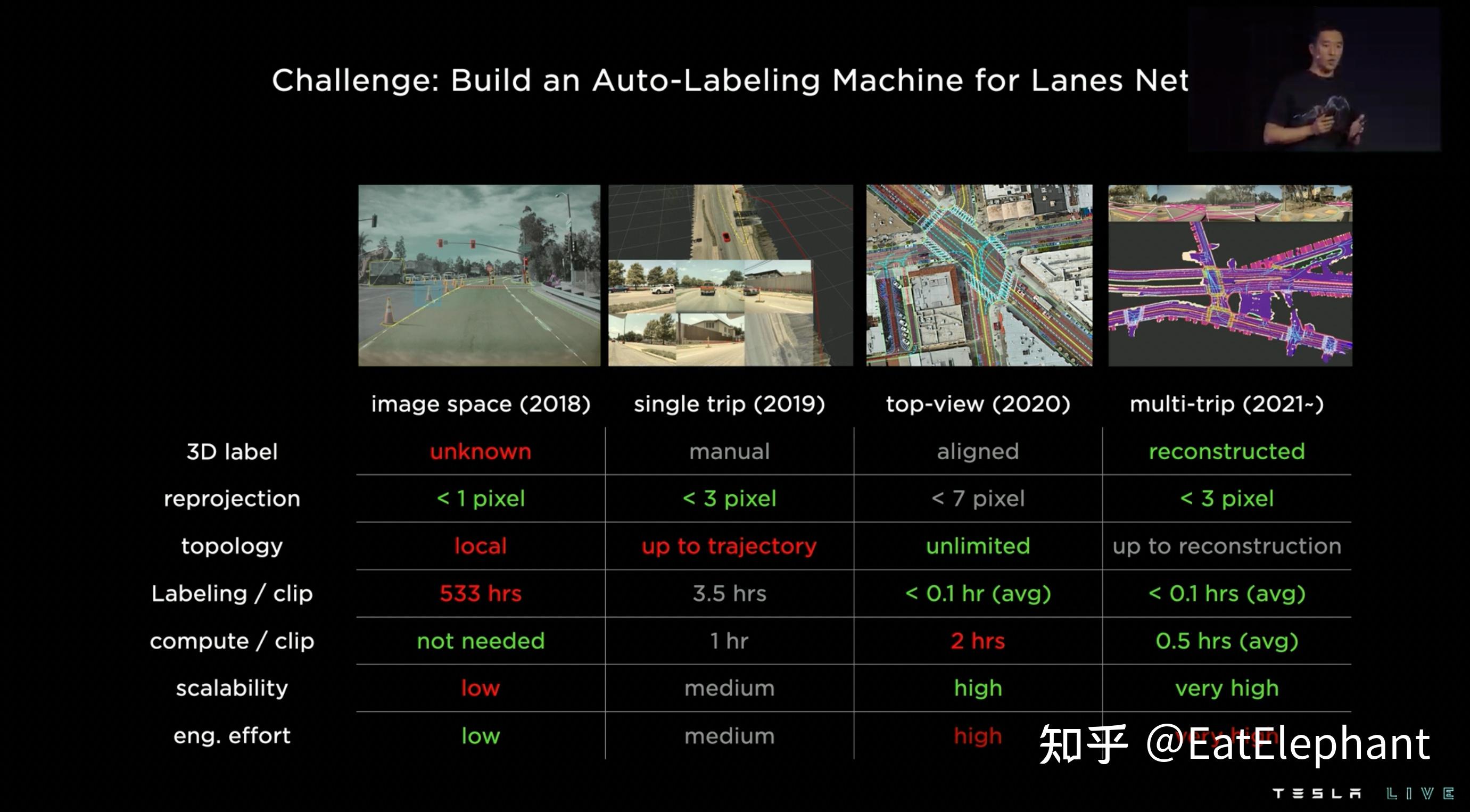
关于4D标注,早在19年Autonomous Day上Karpathy就做过了介绍,当时Tesla使用的是SfM的方式进行周围场景重建,然后再在重建的点云上进行4D标注,跟据2022 AI Day分享的Autolabeler演进过程可以看到当时拓扑只是基于单趟轨迹,重投影误差<3像素,整个标注还比较依赖人工,需要3.5小时进行一个clip标注。2020年由于引入了BEV感知,这里建图已经是基于BEV感知进行的建图,重投影精度<7像素,人工标注耗时小于0.1小时,已经基本上可以实现自动标注了。而2021年至今自动标注开始使用3D特征进行多趟采集轨迹的聚合重建,获得了<3像素的冲投影精度,人工标注耗时与2020相当,但计算效率显著提高,可扩展性也变得非常强。
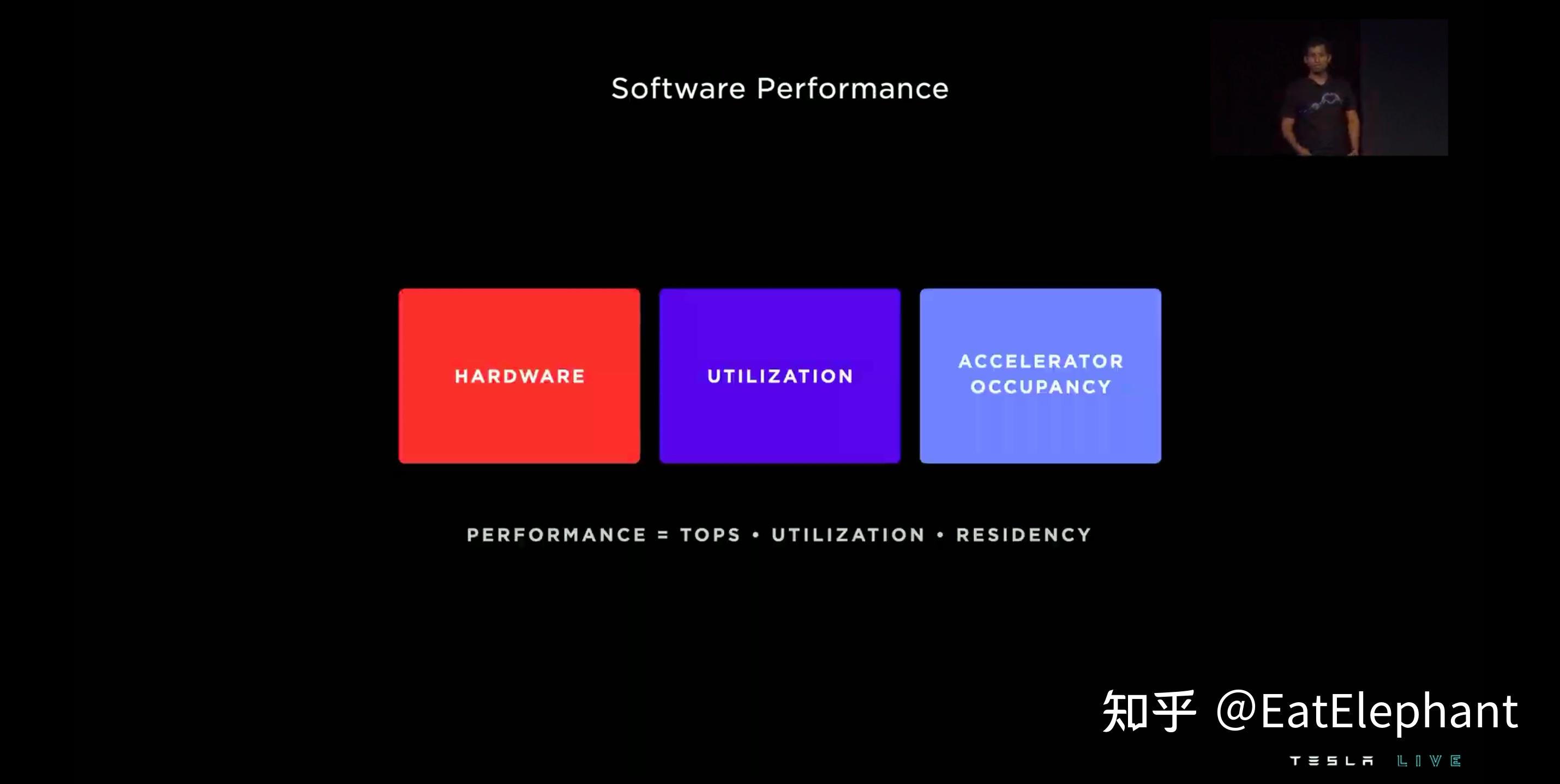
AI Day上还有谈到硬件中最贵的核心部件就是神经网络加速器单元,因此为了提高系统的单位成本整体性能,最经济的方法就是保证神经网络加速器的最高效利用,而神经网络加速器主要由并行排列的乘加运算单元组成,我们平时所谓的TOPS,也就是理论上当所有这些乘加单元全部满负荷工作的时候一秒钟可以完成的万亿次整型运算次数。然而想要保持乘加运算单元一支高效运行绝非易事,有着高TOPS的AI芯片就好比有一门超高射速的速射机关炮,而要想保持这门机关炮饱和火力输出,显然传统的手工填弹方法是绝对不行的,如果由送弹手一发一发的人工装载,那你机关炮射速再快,实际能发挥出来的也就是填弹手填弹速度。在AI芯片中,将存储的计算任务所需的张量传给乘加运算单元的存储单元就可以看做是这个填弹手,而AI编译器是否能够对神经网络进行合理的流水线编排,并行化处理,算子融合等优化并生成高效的指令,并通过大带宽的存储硬件传递进神经网络加速器,就是决定填弹手能否高效填弹的流程和机制。
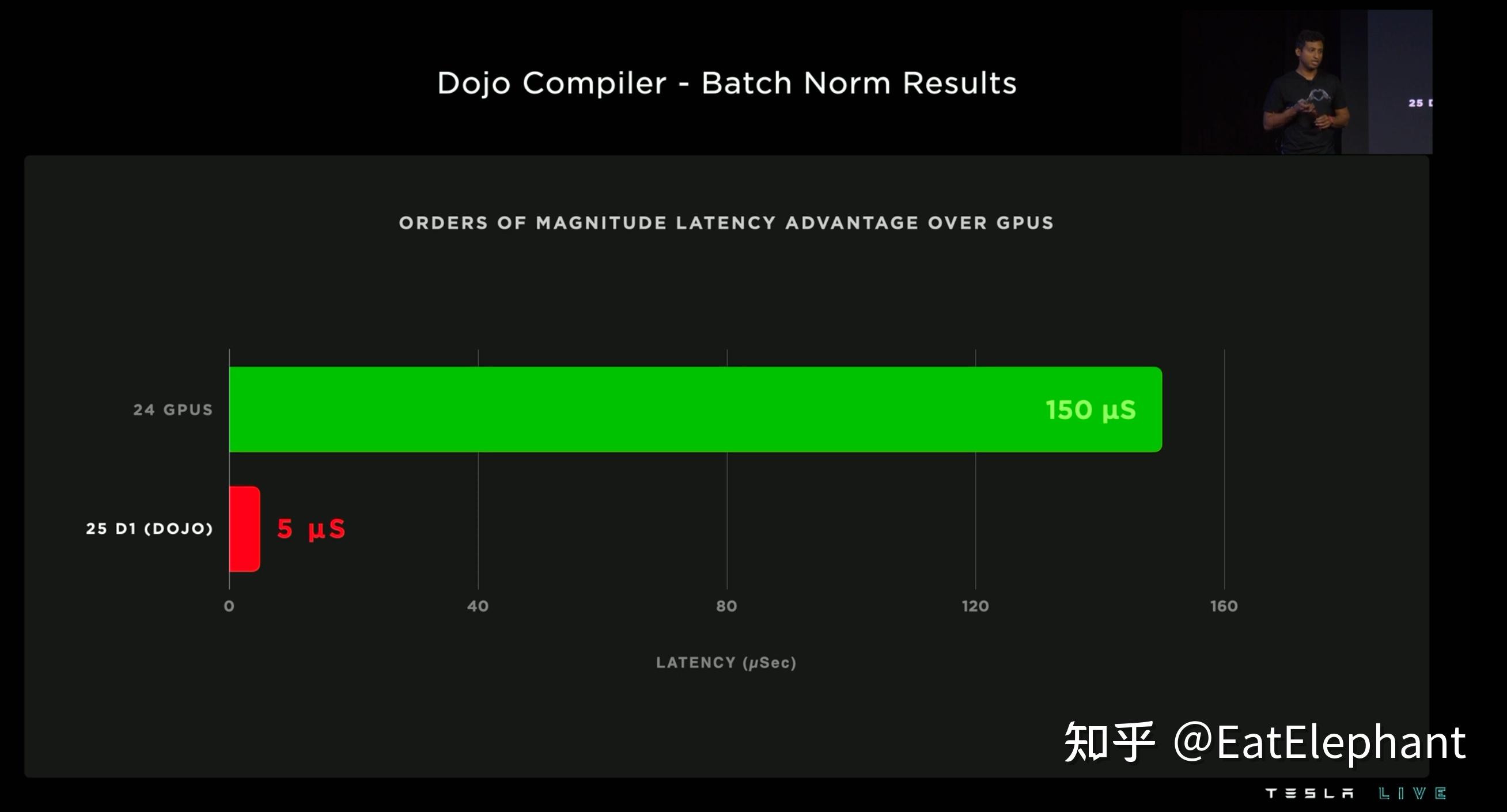
基于DOJO的训练服务器也已经取得了不错的进展,AI Day透漏预计2023年Q1将会开始交付用以进行AutoLabeler训练的DOJO服务器。DOJO的设计上也沿用了同样的设计理念,比如使用专门针对视频的硬件解码器来加速Tesla常用的视频片段数据的解码,强调对于片上SRAM和高速内存HRM的使用,强调最短的片上信息传输链路设计,以最大程度保证运算单元的满负荷运行。而Tesla分布式训练框架采用了模型并行而不是常见的数据并行策略,而为了进行模型并行,还涉及到优化片间梯度的同步效率,这里使用了Tesla自研的通讯协议Tesla Transport Protocol(TTP)来保证高效。
AI Day开始前老妈的Twitter以及宣传造势都引发了大家对于Tesla Bot产生了浓厚的兴趣,然而发布会后很多人对Tesla Bot不免心生失望,因为从学术研发角度看,这个机器人确实没有多少能引起学术圈兴趣的亮点,然而要知道人形机器人的研发难度理论上要远高于电动汽车,然而AI Day I上还是个概念,时隔一年就已经由原型机,并且相对各个部分功能完整,这已经是十分令人惊叹的技术成就。另外就跟自动驾驶领域里Tesla的思路与学术界大相径庭一样,Tesla Bot首要目标是成为量产产品,自然研发理念和流程都会与学术界不一样,新颖和创新肯定不是这个阶段的重点。我个人专业是机器人无人车,然而对机器人并没有实际工作经验,所以这部分简单写写我在AI Day看到的有意思的点,其他更详尽的技术分析就留给别人吧。
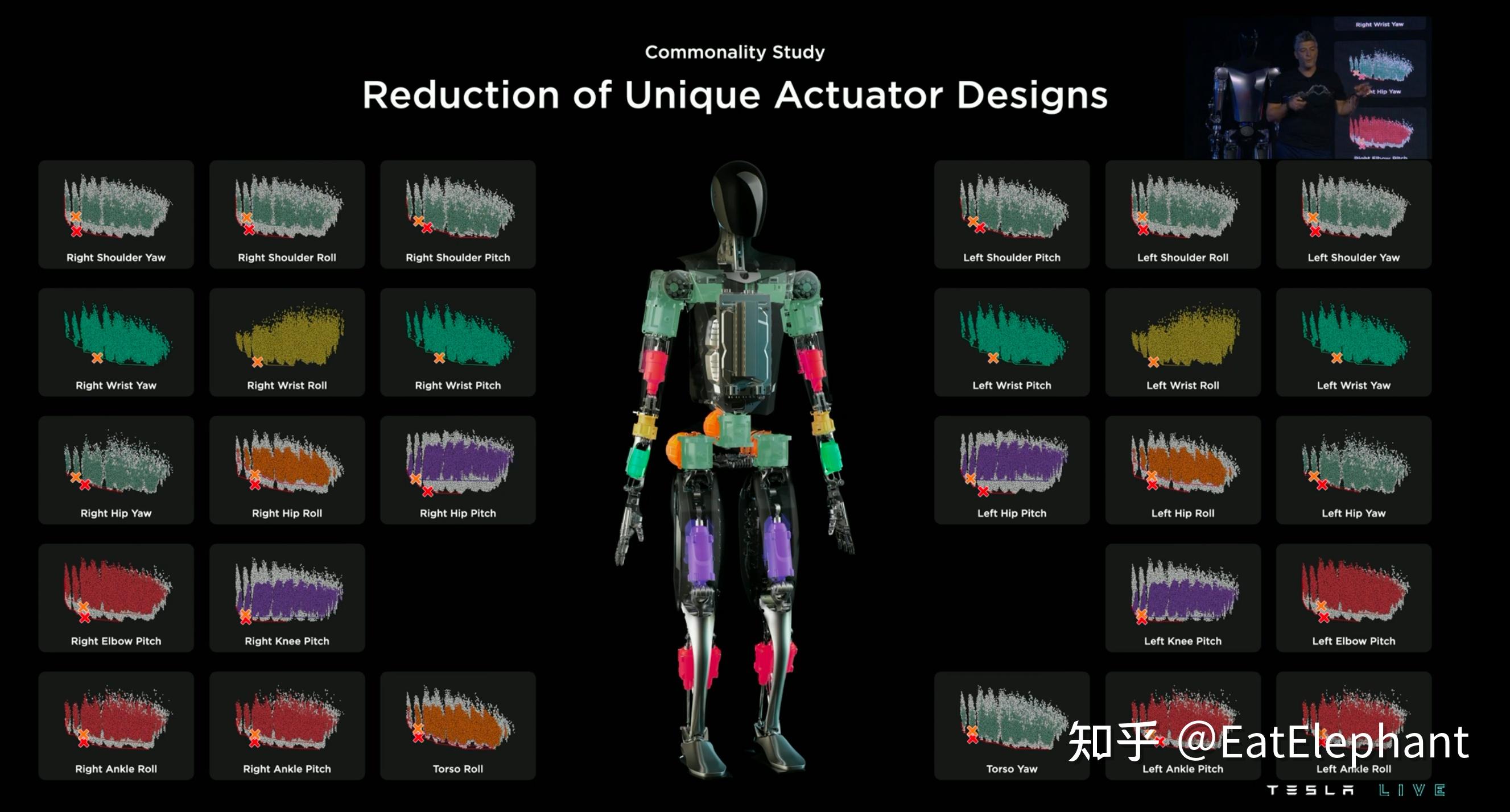
1.材料选型执行器设计都把量产成本放在核心, 利用类似Tesla电动车研发中的有限元分析办法,通过如下图所示的硬件成本和执行器质量曲线,选取最经济的执行器设计,并考虑的执行器的互换性和可制造性,为周身28个执行器选取了6个最终设计。


 发表于 2023-1-8 11:59:36
发表于 2023-1-8 11:59:36