设为首页
收藏本站
切换到窄版
登录
立即注册
找回密码
搜索
搜索
本版
帖子
用户
快捷导航
论坛
BBS
C语言
C++
NET
JAVA
PHP
易语言
数据库
IE盒子
»
论坛
›
IE盒子
›
数据库
›
让你薪资过万的MySQL进阶教程01
返回列表
发帖
查看:
148
|
回复:
2
让你薪资过万的MySQL进阶教程01
[复制链接]
可乐先森
可乐先森
当前离线
积分
15
3
主题
9
帖子
15
积分
新手上路
新手上路, 积分 15, 距离下一级还需 35 积分
新手上路, 积分 15, 距离下一级还需 35 积分
积分
15
发消息
发表于 2022-11-30 11:42:04
|
显示全部楼层
|
阅读模式
关注我,了解java知识
前几天看到一个大佬写的文章,提到高阶程序员必须掌握的技能,其中他明确指出了“精通MySQL”。
为啥MySQL对开发人员如此重要?
1.不管去面试哪家公司,数据库是必问项,而MySQL使用的范围很广泛,无论如何是避不开的;
2.你对MySQL掌握的越深入,意味着你能做的事情越多。
实现业务功能,要懂基本的SQL语句;
性能优化,那么索引、引擎就要摸透;
想分库分表,主从同步机制、读写分离你就得了解;
安全方面,你得知道权限、备份、日志等等;
一、调优
1.选择合适的存储引擎: InnoDB
除非你的数据表使用来做只读或者全文检索 (相信现在提到全文检索,没人会用 MYSQL 了),你应该默认选择 InnoDB 。
你自己在测试的时候可能会发现 MyISAM 比 InnoDB 速度快,这是因为: MyISAM 只缓存索引,而 InnoDB 缓存数据和索引,MyISAM 不支持事务。
但是 如果你使用 innodb_flush_log_at_trx_commit = 2 可以获得接近的读取性能 (相差百倍) 。
1.1 如何将现有的 MyISAM 数据库转换为 InnoDB:
1.2 为每个表分别创建 InnoDB FILE:
innodb_file_per_table=1
这样可以保证 ibdata1 文件不会过大,失去控制。尤其是在执行 mysqlcheck -o –all-databases 的时候。
2. 保证从内存中读取数据,讲数据保存在内存中
2.1足够大的 innodb_buffer_pool_size
将数据完全保存在 innodb_buffer_pool_size ,即按存储量规划 innodb_buffer_pool_size 的容量。这样你可以完全从内存中读取数据,最大限度减少磁盘操作。
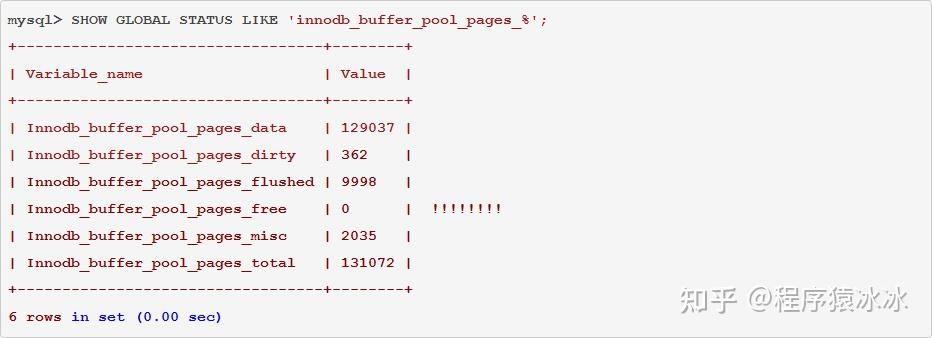
如何确定 innodb_buffer_pool_size 足够大,数据是从内存读取而不是硬盘?
发现 Innodb_buffer_pool_pages_free 为 0,则说明 buffer pool 已经被用光,需要增大 innodb_buffer_pool_size
InnoDB 的其他几个参数:
innodb_additional_mem_pool_size = 1/200 of buffer_poolinnodb_max_dirty_pages_pct 80%
3. 减少磁盘写入操作
3.1使用足够大的写入缓存 innodb_log_file_size
如果用 1G 的 innodb_log_file_size ,假如服务器宕机,需要 10 分钟来恢复。
推荐innodb_log_file_size 设置为 0.25 * innodb_buffer_pool_size
3.2innodb_flush_log_at_trx_commit
这个和写磁盘操作密切相关:
innodb_flush_log_at_trx_commit = 1 则每次修改写入磁盘
innodb_flush_log_at_trx_commit = 0/2 每秒写入磁盘
如果你的应用不涉及很高的安全性 (金融系统),或者基础架构足够安全,或者 事务都很小,都可以用 0 或者 2 来降低磁盘操作。
4.调优当然少不了索引
4.1添加必要的索引
索引是提高查询速度的唯一方法,比如搜索引擎用的倒排索引是一样的原理。
索引的添加需要根据查询来确定,比如通过慢查询日志或者查询日志,或者通过 EXPLAIN 命令分析查询。
ADD UNIQUE INDEX
ADD INDEX
4.2.使用自动加索引的框架或者自动拆分表结构的框架
比如,Rails 这样的框架,会自动添加索引,Drupal 这样的框架会自动拆分表结构。会在你开发的初期指明正确的方向。所以,经验不太丰富的人一开始就追求从 0 开始构建,实际是不好的做法。
5.使用合适的字段属性
mysql在创建数据库的时候首先考虑数据库中的表越小越好,这样才能提高查询的速度。如果数据量过大,就需要考虑在建表时的字段长度。
6.使用连接查询(join)代替子查询
子查询的优点是可以使用简单的SELECT语句就可以完成逻辑较为复杂的查询动作,而且还能避免死锁的情况产生。但是有时也可以考虑使用连接查询来完成,毕竟连接查询不需要像子查询一样在内存中创建临时表,再从临时表中过滤数据,从而加快查询速度。
7.通过事务来管理
事务是数据库调优时的一个老生常谈的概念,由于其4大特性,事务是不可避免的调优方式之一,它可以保证数据的完整性、一致性。可以用一句话来总结“去不了终点,那就回到原点。”
8.锁定表
尽管事务能够保证数据库的完整性和一致性,但是它本身其实也存在一些弊端。因为它本身具有一定的独占性,当事务没有执行完毕以前,用户发出的其他操作就只能等待,一直等到所有的事务都结束了才能继续执行。如果用户访问量特别大的时候,这会造成系统的严重延迟问题。
所以可以通过锁定表的方法,保证在没有执行到UNLOCKTABLES指令之前所有被LOCKTABLE修饰地表的查询语句不会被插入、删除和修改。
9.合理使用外键
外键本身存在的作用就是保证表与表之间的参照完整性,使用外键可以有效地增加数据之间的关联性。
二、索引
索引是Mysql的一块硬骨头,但是对于程序猿来说又是十分重要的基础技能。在平常的项目开发中,它是重要的SQL优化手段。在求职面试中,它是面试官常常用来考察求职者数据库性能优化方面的重要考量。
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
创建索引时,你需要确保该索引是应用在SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
缺点:
1. 索引会占据额外的存储空间(毕竟它是数据结构),包括磁盘和内存;2. 由于对数据需要排序,自然会影响到数据更新(插入、更新、删除)的速度
索引的实现原理
对于 MySQL 来说,服务器层并不会实现索引,而是交给了存储引擎。所以,你应该知道了,不同的存储引擎自然也就会有各自不同的实现。对于 InnoDB 而言,它的内部实现使用的是 B+ 树;
B+树的优势:
io次数少: b+树中间节点只存索引,不存在实际的数据(一页能够有更多索引)
性能稳定: b+树数据只存在于叶子节点,查询性能稳定,即每次都到达叶子结点
范围查询简单: b+树不需要中序遍历,遍历链表即可。
索引的分类
普通索引: 针对于单个列创建的索引,它对列值没有什么限制,允许被索引的列包含重复的值;
主键索引:特殊的唯一索引,在一张表中只能定义一个(但不是必须)主键索引;
唯一索引: 正如它的关键字一样,它要求列值是唯一的,这个索引保证了数据记录的唯一性;
联合索引: 也被称为复合索引,它是将多个列值绑定在一起作为索引;
聚簇索引: 实际上并不是一种索引类型,而是一种存储数据的方式,且是将索引和数据存储在一起。InnoDB 规定一个表只能有一个聚簇索引,且会使用主键来创建;
前缀索引: 当表中的数据列是字符型,且大多数长度都比较长时,就可以考虑使用列值的一部分前缀作为索引,这也就被称作是前缀索引;
覆盖索引: 当一个索引包含需要查询的所有字段时,就称之为覆盖索引;
聚簇索引
既然数据表只有一个聚簇索引,那么,所有其他的索引就应该是 “非聚簇索引”,它们的区别又是什么呢 ?对于聚簇索引来说,索引即数据,所以,如果以主键去查询数据,那么只需要一次索引查找即可。对于非聚簇索引而言,实际存储的是记录主键,所以,还需要根据主键再做一次查询才可以获取到数据,这也就是我们通常所说的 “非主键的二次查询”;
联合索引
联合索引会遵循最左前缀匹配原则,也就是常说的 “最左优先原则”。它的表现形式是在检索数据时从联合索引的最左边开始匹配,在检索数据时从联合索引的最左边开始匹配;你需要充分理解它的 “最左原则”,这会让你避免创建冗余的索引;另外,
你还需要知道一些索引失效的条件:
在索引列上执行计算、函数、类型转换等操作;
使用不等于(!= 或 <>);
使用 IS NULL,IS NOT NULL;可以使用exists关键字支持索引;
LIKE 以通配符(%)开头;用全文索引支持索引;
最左前缀匹配原则:索引(A,B,C) --> 索引(A),(A,B),(A,B,C)
星辰大海,永不止步
END
回复
使用道具
举报
宝宝宸
宝宝宸
当前离线
积分
11
0
主题
6
帖子
11
积分
新手上路
新手上路, 积分 11, 距离下一级还需 39 积分
新手上路, 积分 11, 距离下一级还需 39 积分
积分
11
发消息
发表于 2025-4-30 07:43:34
|
显示全部楼层
为毛老子总也抢不到沙发?!!
回复
使用道具
举报
你是可姐姐
你是可姐姐
当前离线
积分
39
3
主题
19
帖子
39
积分
新手上路
新手上路, 积分 39, 距离下一级还需 11 积分
新手上路, 积分 39, 距离下一级还需 11 积分
积分
39
发消息
发表于 2025-12-11 05:17:25
|
显示全部楼层
very good
回复
使用道具
举报
真我的風采
真我的風采
当前离线
积分
29
2
主题
15
帖子
29
积分
新手上路
新手上路, 积分 29, 距离下一级还需 21 积分
新手上路, 积分 29, 距离下一级还需 21 积分
积分
29
发消息
发表于 2025-12-15 04:50:08
|
显示全部楼层
顶起出售广告位
回复
使用道具
举报
李坏不坏
李坏不坏
当前离线
积分
6
0
主题
4
帖子
6
积分
新手上路
新手上路, 积分 6, 距离下一级还需 44 积分
新手上路, 积分 6, 距离下一级还需 44 积分
积分
6
发消息
发表于 2026-3-18 09:23:24
|
显示全部楼层
嘘,低调。
回复
使用道具
举报
经典非流行
经典非流行
当前离线
积分
34
3
主题
18
帖子
34
积分
新手上路
新手上路, 积分 34, 距离下一级还需 16 积分
新手上路, 积分 34, 距离下一级还需 16 积分
积分
34
发消息
发表于
1 分钟前
|
显示全部楼层
路过 帮顶 嘿嘿
回复
使用道具
举报
返回列表
发帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
NET
PHP
C++
易语言
JAVA
C语言
快速回复
返回顶部
返回列表


 发表于 2022-11-30 11:42:04
发表于 2022-11-30 11:42:04